对抗验证概述

如果您要在Kaggle上研究一些获胜的解决方案,则可能会注意到对“对抗性验证”的引用()。它是什么?
简而言之,我们构建了一个分类器,以尝试预测哪些数据行来自训练集,哪些数据行来自测试集。如果两个数据集来自相同的分布,那应该是不可能的。但是,如果您的训练和测试数据集的特征值存在系统差异,则分类器将能够成功学习以区分它们。您可以学会更好地区分它们的模型越多,问题就越大。
但是,好消息是
学习对抗验证模型
首先,导入一些库:

数据准备
对于本教程,我们将使用Kaggle的。首先,假设您已将训练和测试数据加载到pandas DataFrames中,并将它们分别命名为

对于对抗性验证,我们想学习一个模型,该模型可以预测训练数据集中哪些行以及测试集中哪些行。因此,我们创建一个新的目标列,其中测试样本用1标记,训练样本用0标记,如下所示:

这是我们训练模型进行预测的目标。目前,训练数据集和测试数据集是分开的,每个数据集只有一个目标值标签。如果我们在

新的数据集
对于建模,我将使用Catboost。我通过将DataFrames放入Catboost Pool对象中来完成数据准备。

建模
这部分很简单:我们只需实例化Catboost分类器并将其拟合到我们的数据中:

让我们继续前进,在保留数据集上绘制ROC曲线:
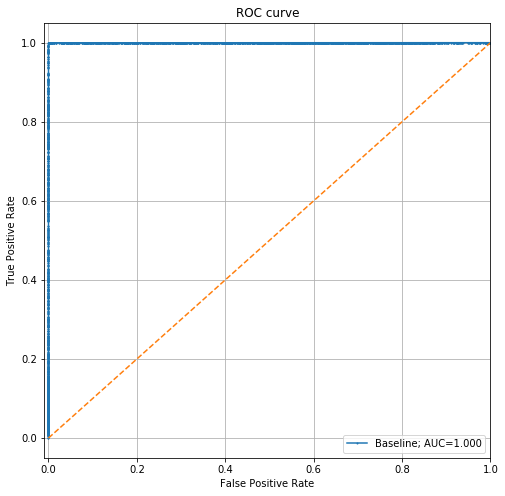
这是一个完美的模型,这意味着有一种明确的方法可以告诉您任何给定的记录是否在训练或测试集中。这违反了我们的训练和测试集分布相同的假设。
诊断问题并进行迭代
为了了解模型如何做到这一点,让我们看一下最重要的特征:
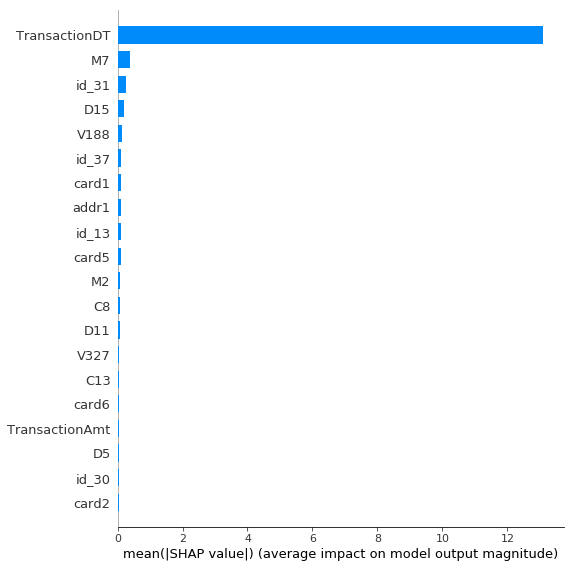
到目前为止,TransactionDT是最重要的特征。鉴于原始的训练和测试数据集来自不同的时期(测试集出现在训练集的未来),这完全合情合理。该模型刚刚了解到,如果TransactionDT大于最后一个训练样本,则它在测试集中。
我之所以包含TransactionDT只是为了说明这一点–通常不建议将原始日期作为模型特征。但是好消息是这项技术以如此戏剧性的方式被发现。这种分析显然可以帮助您识别这种错误。
让我们消除TransactionDT,然后再次运行此分析。

现在,ROC曲线如下所示:
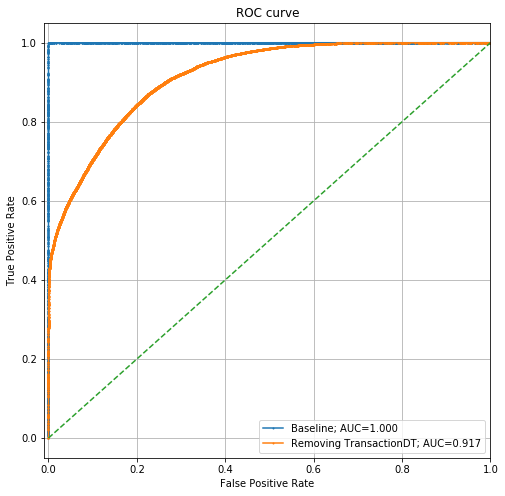
它仍然是一个相当强大的模型,AUC> 0.91,但是比以前弱得多。让我们看一下此模型的特征重要性:
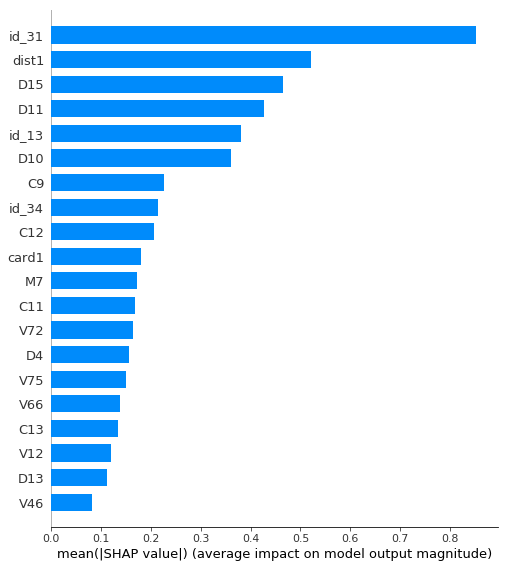
现在,

此列包含软件版本号。显然,这在概念上与包含原始日期类似,因为特定软件版本的首次出现将与其发布日期相对应。
让我们通过删除列中所有不是字母的字符来解决此问题:

现在,我们的列的值如下所示:

让我们使用此清除列来训练新的对抗验证模型:
现在,ROC图如下所示:
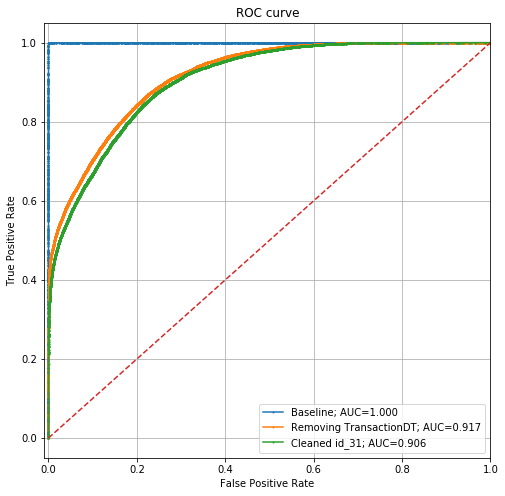
性能已从0.917的AUC下降到0.906。这意味着我们已经很难让模型区分我们的训练数据集和测试数据集,但是它仍然很强大。
结论
此方法用来评价训练集与测试集分布是否一致,以防止新的测试集出现,导致崩盘的现象。
如果你喜欢本文的话,欢迎点赞转发!谢谢。
看完别走还有惊喜!
我精心整理了计算机/Python/机器学习/深度学习相关的2TB视频课与书籍,价值1W元。关注微信公众号“计算机与AI”,点击下方菜单即可获取网盘链接。
