Elasticsearch 写入流程 Making Changes Persistent
Elasticsearch 写入流程 Making Changes Persistent(translog、flush),内容来自 B 站中华石杉 Elasticsearch 顶尖高手系列课程核心知识篇,英文内容来自 Elasticsearch: The Definitive Guide [2.x]
之前的写入流程,如果遇到服务器宕机,那么 OS Cache、index segment 和 内存 buffer 中的数据都会丢失,可靠性很差。
看图说话
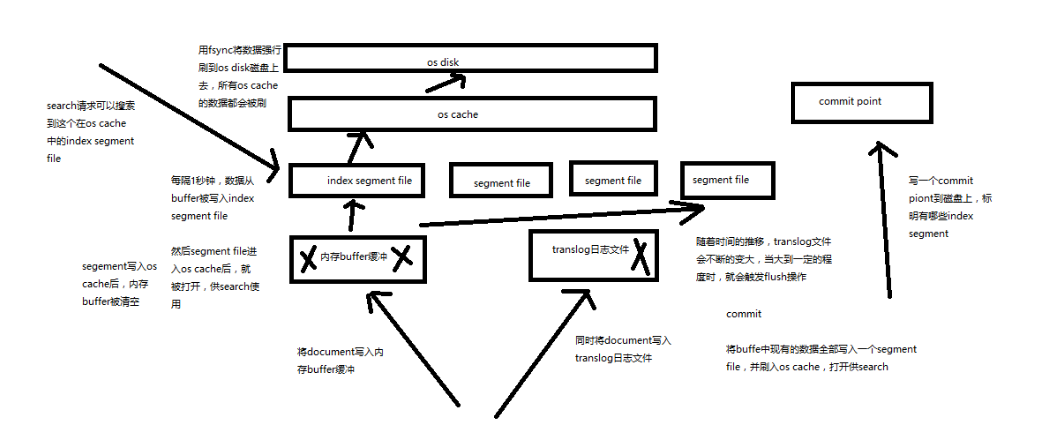
再次优化的写入流程
基于 translog 和 commit point,如何进行数据恢复

fsync + 清空 translog,就是 flush,默认每隔 30 分钟 flush 一次;或者当 translog 过大的时候,也会 flush
POST /my_index/_flush一般来说别手动 flush,让它自动执行就可以了
translog,每隔 5 秒被 fsync 一次到磁盘上。在一次增删改操作之后,当 fsync 在 primary shard 和 replica shard 都成功之后,那次增删改操作才会成功
但是这种在一次增删改时强行 fsync translog可能会导致部分操作比较耗时,也可以允许部分数据丢失,设置异步 fsync translog
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}Making Changes Persistent
a full commit point, which lists all known segments. Elasticsearch uses this commit point during startup or when reopening an index to decide which segments belong to the current shard.
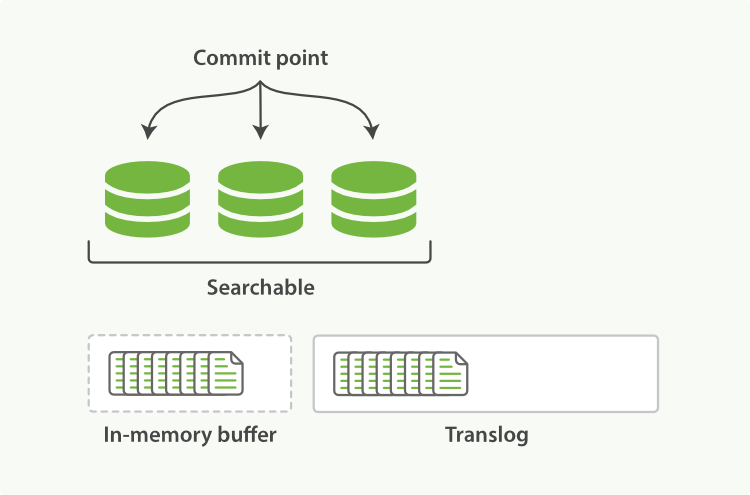
New documents are added to the in-memory buffer and appended to the translog
The docs in the in-memory buffer are written to a new segment, without an fsync
The segment is opened to make it visible to search
The in-memory buffer is cleared.
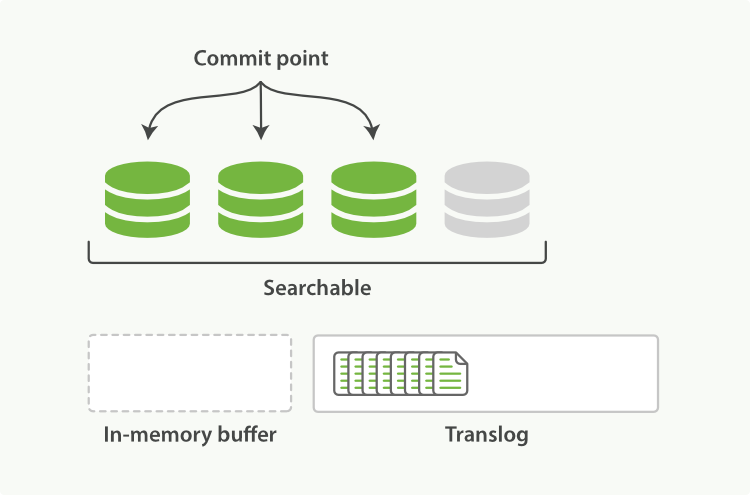
After a refresh, the buffer is cleared but the transaction log is not
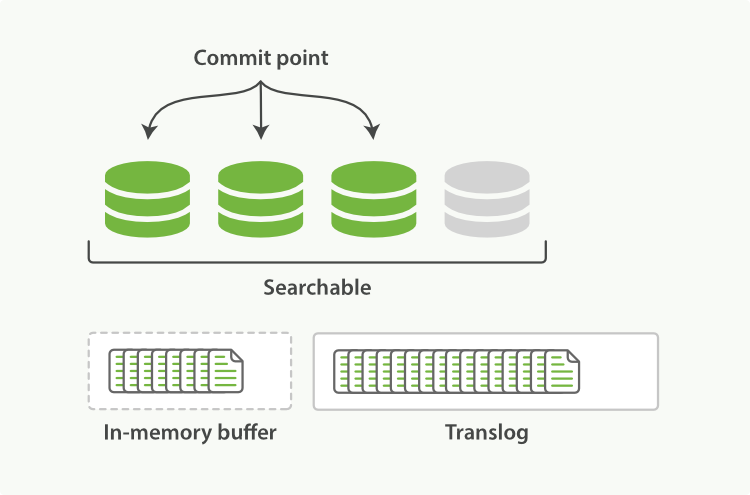
The transaction log keeps accumulating documents
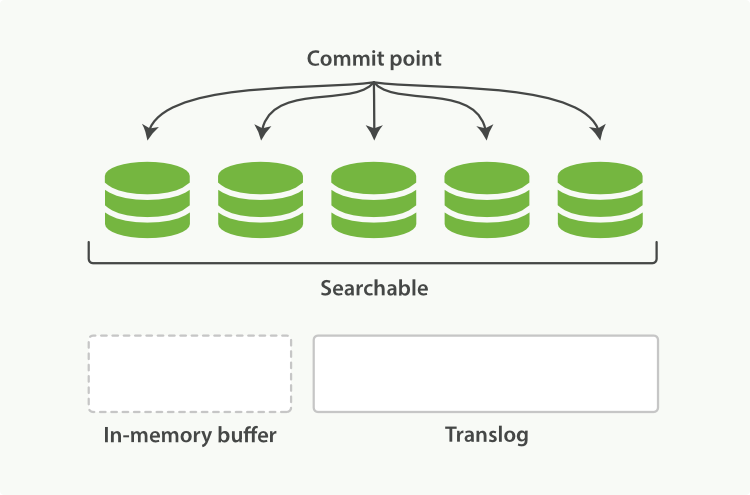
After a flush, the segments are fully committed and the transaction log is cleared.
The translog provides a persistent record of all operations that have not yet been flushed to disk.
The translog is also used to provide real-time CRUD. When you try to retrieve, update, or delete a document by ID, it first checks the translog for any recent changes before trying to retrieve the document from the relevant segment. This means that it always has access to the latest known version of the document, in real-time.
flush API
the action of performing a commit and truncating the translog
Shards are flushed automatically every 30 minutes, or when the translog becomes too big.
// Flush the blogs index
POST /blogs/_flush
// Flush all indices and wait until all flushes have completed before returning
POST /_flush?wait_for_ongoingYou seldom need to issue a manual flush yourself; usually, automatic flushing is all that is required.
it is beneficial to flush your indices before restarting a node or closing an index.
How Safe Is the Translog?
The purpose of the translog is to ensure that operations are not lost.
Writes to a file will not survive a reboot until the file has been fsync'ed to disk. By default, the translog is fsync'ed every 5 seconds and after a write request completes....your client won't receive a 200 OK response until the entire request has been fsync'ed in the translog of the primary and all replicas.
for some high-volume clusters where losing a few seconds of data is not critical, it can be advantageous to fsync asynchronously.
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}This setting can be configured per-index and is dynamically updatable.
// default
"index.translog.durability": "request"