攻克MySQL—索引优化
0. 引子
在上一篇文章中,我们学习了索引的概念、使用场景、常用的数据结构、InnoDB引擎的数据结构——B+树,以及MySQL中的各种索引的分类,例如主键索引、二级索引、普通索引、唯一索引等等。
仅仅了解这些概念,还不足以让我们在工作或面试中游刃有余,原因在于有几个点我们没有讨论:
本文会针对上面这些问题,做进一步的总结。
1. 索引的代价
1.1 维护代价
每张MySQL的表都会有一个主键索引(没有指定主键的话,引擎本身也会默认用rowId作为主键),因此在一张MySQL的表中至少有一棵B+树。如果开发者再创建 N 个二级索引,就需要再创建N棵B+树,新增数据时不仅要修改主键索引,还需要修改这N个二级索引。这会导致INSERT、UPDATE、DELETE等操作的速度变慢。
1.2 空间代价
虽然二级索引不保存原始数据,但要保存索引列的数据,所以会占用更多的空间。
创建一个tuser表并插入3条语句:
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`)
) ENGINE=InnoDB;
insert into tuser values(1,'78967ydydyd','阿杜',18,1);
insert into tuser values(2,'789kdkdkdkdkydydyd','哈哈',20,0);
insert into tuser values(3,'789kdkdkdkdkjdjdjdjdjj','测试'17,1);通过下面的命令可以看出,原始的数据大小只有16384,但是索引空间用了32768。
SELECT DATA_LENGTH, INDEX_LENGTH FROM information_schema.TABLES WHERE TABLE_NAME='tuser'
2. 合理使用索引
2.1 主键索引
在非KV场景下,最好创建一个代理键作为主键,这种主键的数据应该和应用业务无关(业务数据一般很难保障顺序插入),最简单的方式就是使用AUTO_INCREMENT自增列。这样可以保障数据行是案顺序插入的,可以极大减少页的分裂和碎片。
从性能方面考虑,使用UUID作为主键,有下面这些缺点
随机IO:写入的目标页可能已经刷到磁盘上,并从缓存中删除,或者还没有被加载到缓存中,在写入之前需要先将目标页读取到缓存中;
分裂次数增加:因为写入是乱序的,InnoDB不得不为新插入的行挪动空间,移动的时候需要不断调整B+树的结构
由于频繁的的页分裂,页的空间使用率会比较差,充满碎片
从存储空间方面考虑,UUID的字段长度长于自增ID,导致本身的主键索引空间变大,另外二级索引的叶子节点中存放的也是主键索引的ID,因此二级索引的占用空间也会变大。
相关技巧
2.2 覆盖索引
创建二级索引之后,可以通过索引快速查找到需要的数据,但是我们不可能为每个列都创建索引,因此会存在“回表”的情况。在InnoDB中的存储方式是聚簇索引,二级索引在叶子节点中存放了行的主键,如果二级索引的查询可以查到SQL中所需要的全部字段,就避免了回表。当发起一个被索引覆盖的查询时,在EXPLAIN的Extra列可以看到“Using index”的信息。
使用SQL语句:查询,可以看出产生了回表操作;

使用SQL语句:查询,可以看出这次只使用了二级索引就完成了查询。

相关技巧
2.3 最左前缀
B+ 树这种索引结构,可以利用索引的“最左前缀”,来定位记录。最左前缀原则在字段之间和字段内部都生效:如果有多个字段联合组成的组合索引,则先比较左边字段的值,如果是单个字符串列的普通索引,则比较的时候也符合最左前缀匹配原则。
使用SQL语句:符合最左前缀原则,可用上name_age索引。

使用SQL语句:符合最左前缀原则,可用上name_age索引。

相关技巧
2.4 索引下推
MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
无索引下推的执行流程如下:
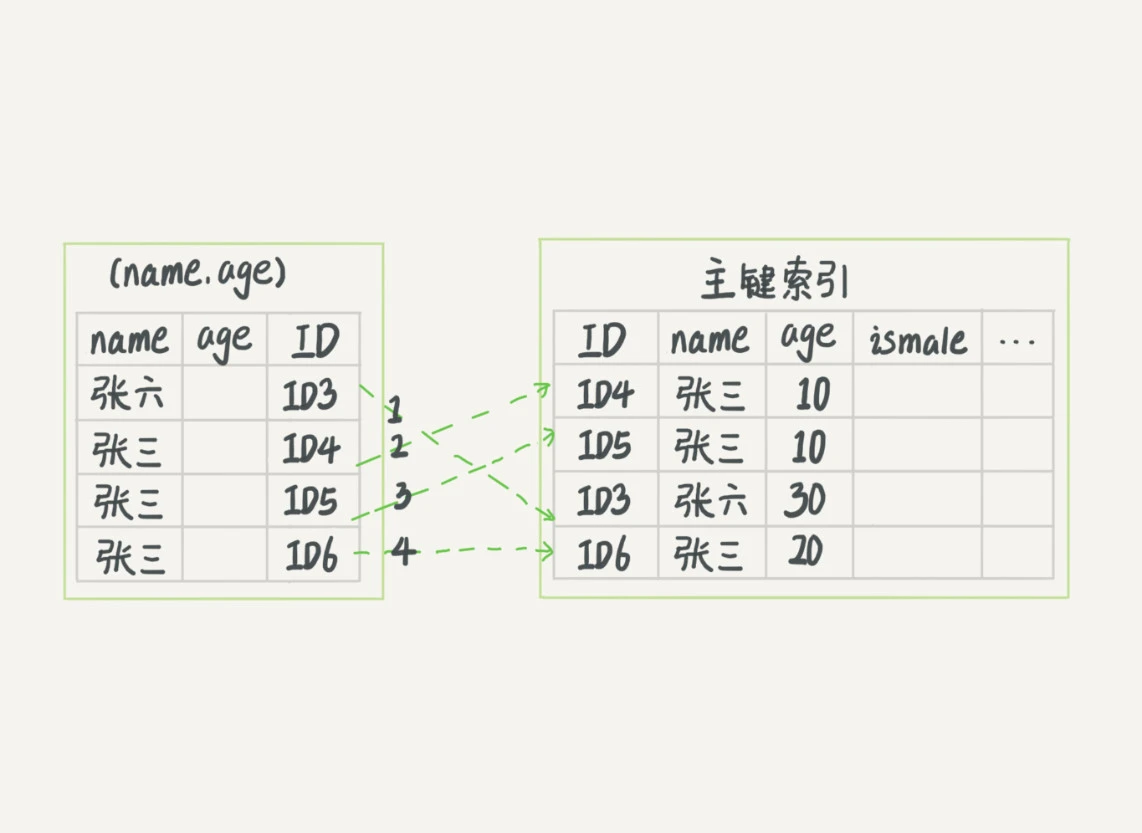
有索引下推的执行流程如下:
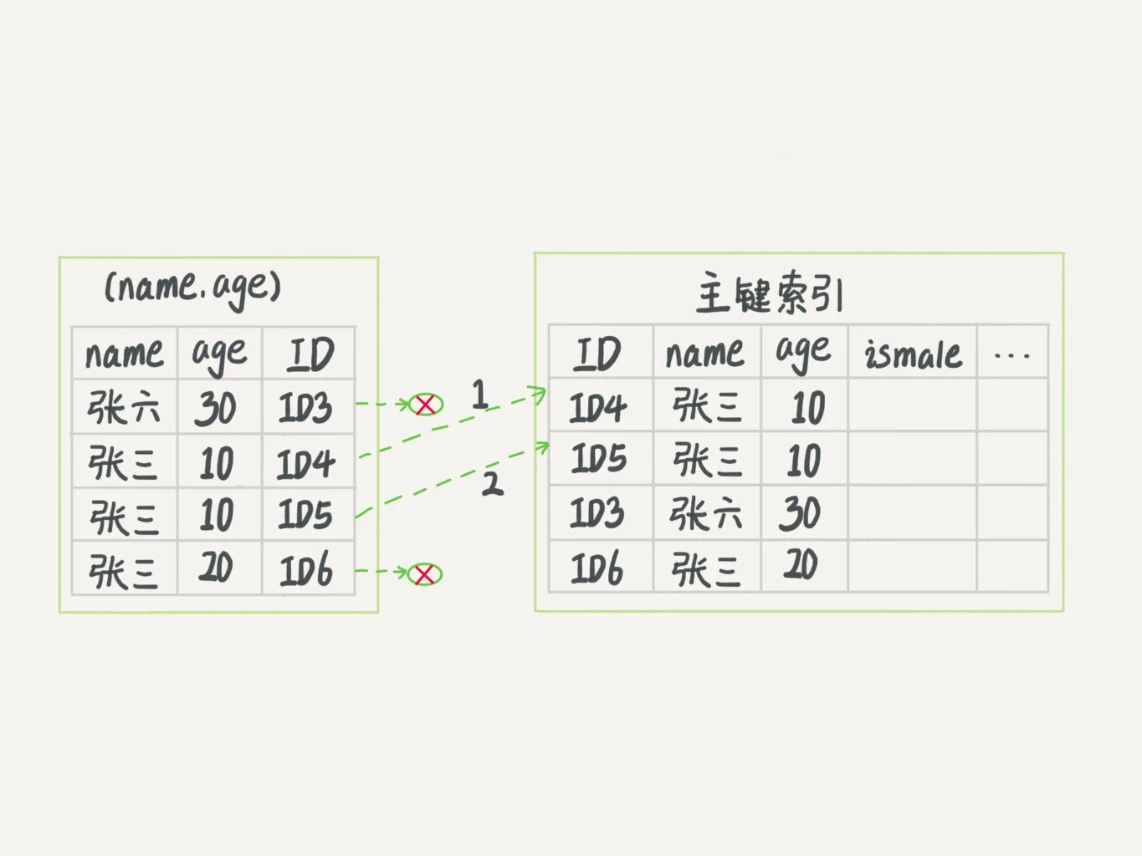
使用SQL语句:触发了索引下推
