恒源云(GPUSHARE)_社区大佬的论文小记(Flooding-X)
原文作者 | Mathor
所谓大佬,就是只要你肯挖,总有你不知道的知识点在某个地方等着你来学习!
往下看,这不就来了吗!
正文开始:
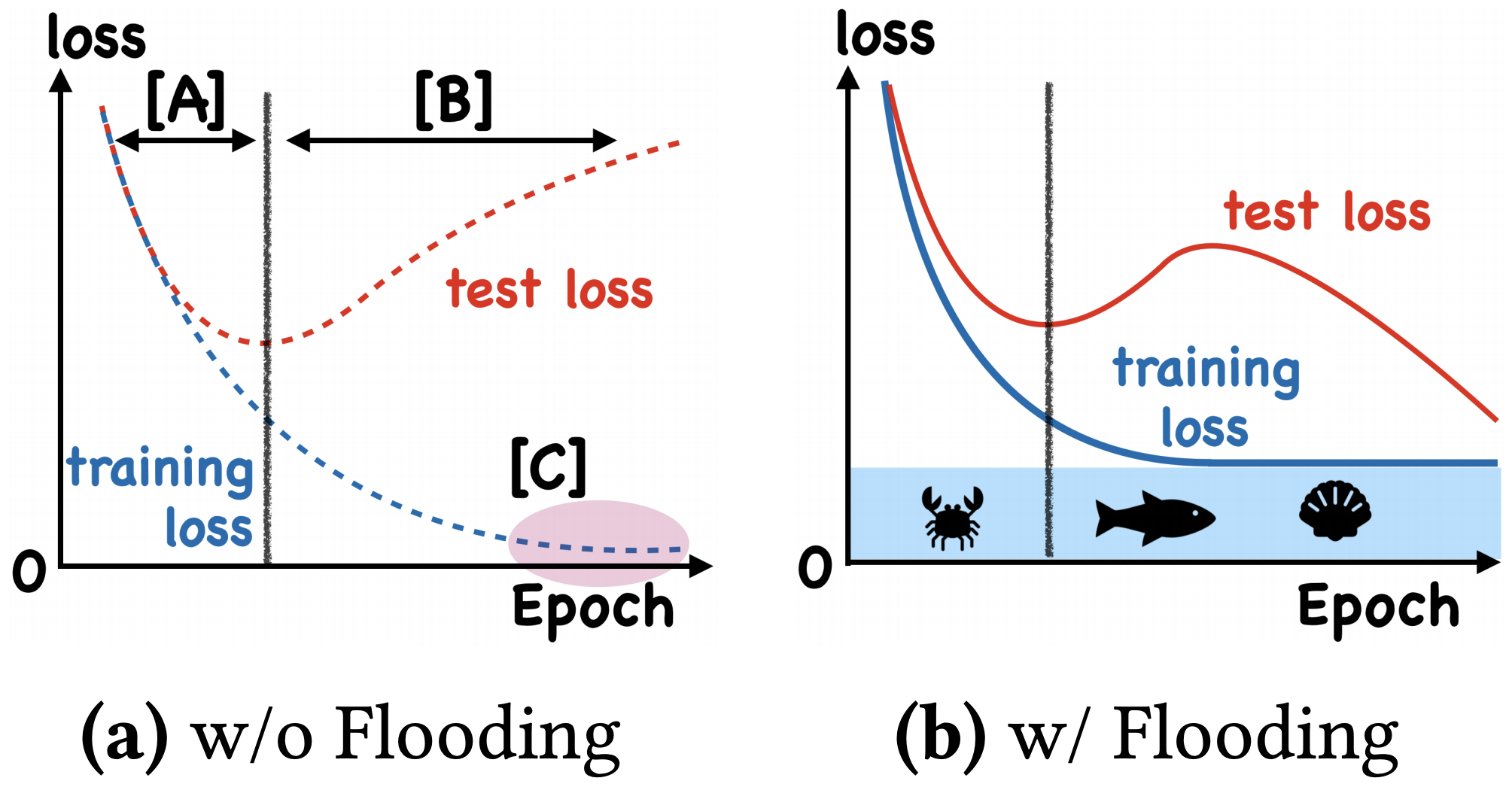
ICML2020的论文提出了一种Flooding方法,用于缓解模型过拟合,详情可以看我的文章。这里简单过一下,论文提出了一个超参数,并将损失函数改写为

其中,是预先设定的阈值,当 > 时,这时就是执行普通的梯度下降;而<时=2-,注意到损失函数变号了,所以这时候是梯度上升。因此,总的来说就是以为阈值,低于阈值时反而希望损失函数变大。论文把这个改动称为Flooding
这样做有什么效果呢?论文显示,在某些任务中,训练集的损失函数经过这样处理后,验证集的损失能出现 “二次下降(Double Descent)”,如下图
我们可以假设梯度先下降一步后上升一步,学习率为,通过泰勒展开可以得到
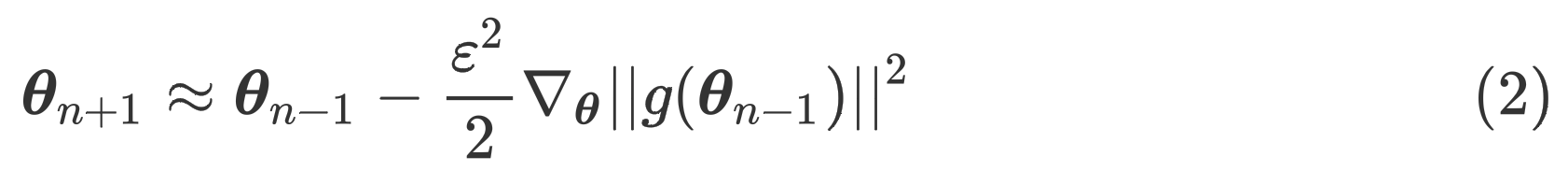
其中,n 的梯度下降
ACHILLES’ HEEL OF FLOODING
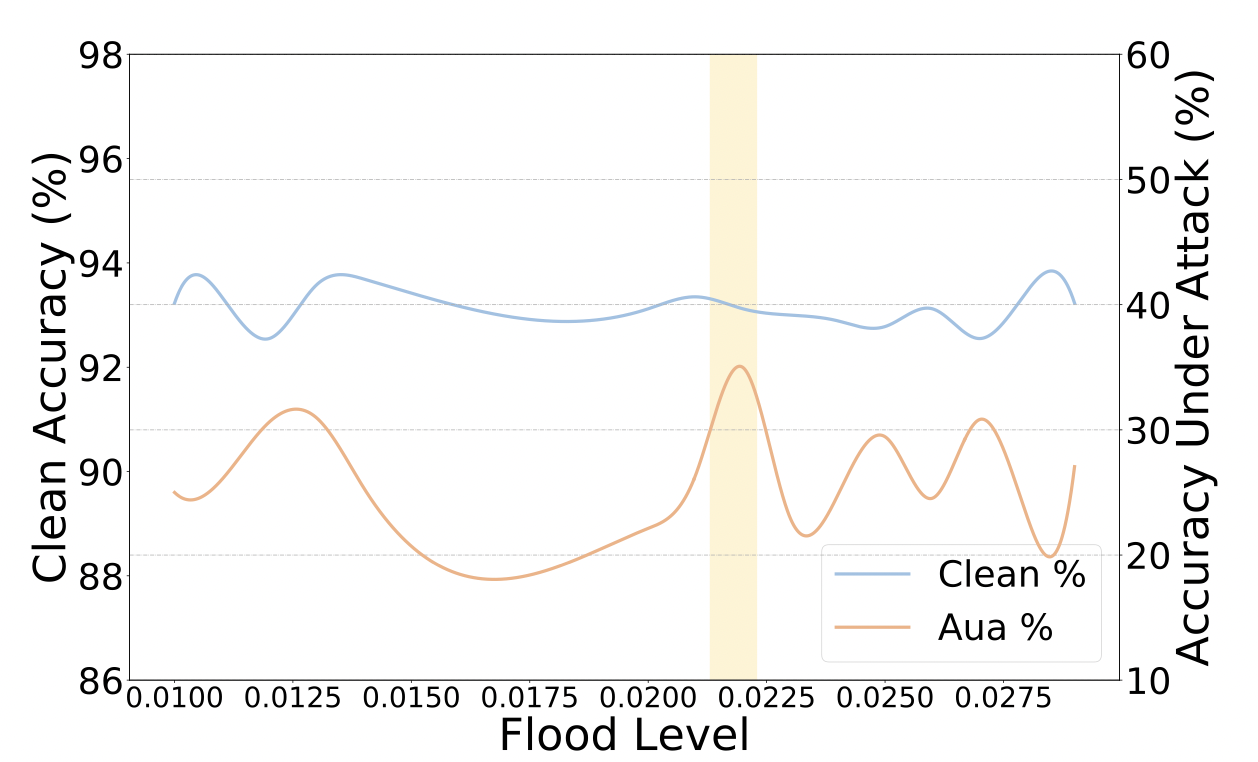
Flooding的阿喀琉斯之踵在于超参数,我们需要花非常多的时间寻找最佳的阈值,这并不是一件容易的事
Achilles’ Heel(阿喀琉斯之踵)阿喀琉斯是古希腊神话故事中的英雄人物,刀枪不入,唯一的弱点是脚后跟(踵)。后用于来比喻某东西的致命缺陷
下图展示了使用BERT在SST-2数据集上不同的阈值对结果的影响(黄色区域是最佳结果)。可以看出,的设置对结果的影响非常大
GRADIENT ACCORDANCE
ACL2022的投稿有一篇名为的文章,以"梯度一致性"作为开启Flooding的"阀门",而不再采用超参数。具体来说,我们首先定义包含参数的模型,考虑一个样本以及真实标签,它们的损失为,损失关于参数的梯度为

其中,式(3)的负值就是参数更新的方向。现在我们考虑两个样本的情况,根据上述定义,样本1的梯度为
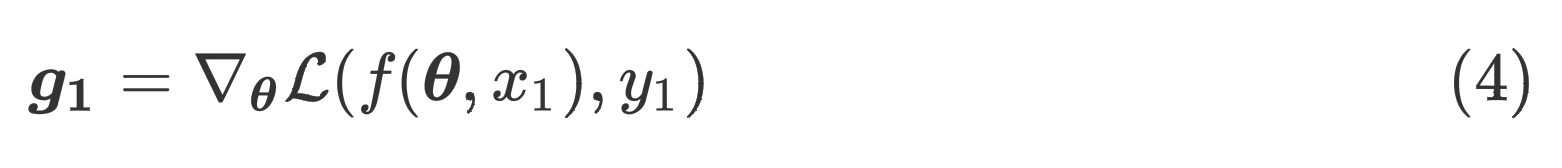
对于样本1来说,参数更新所导致的损失变化为
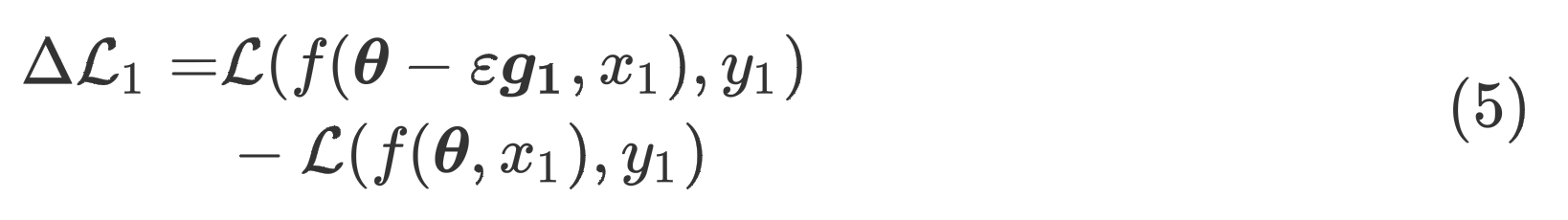
将通过泰勒展开变形得
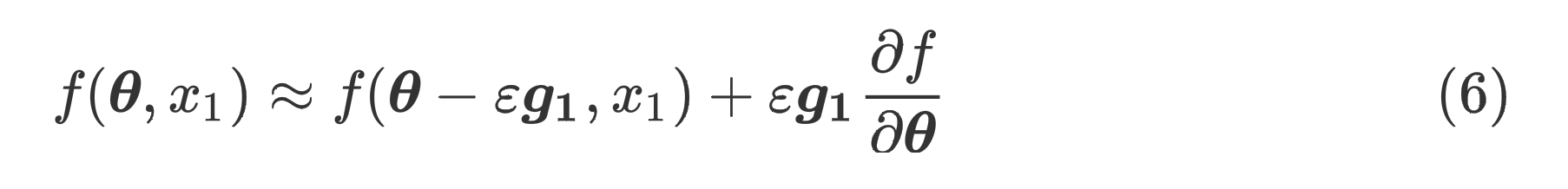
我们将记作,并对做类似的泰勒展开得
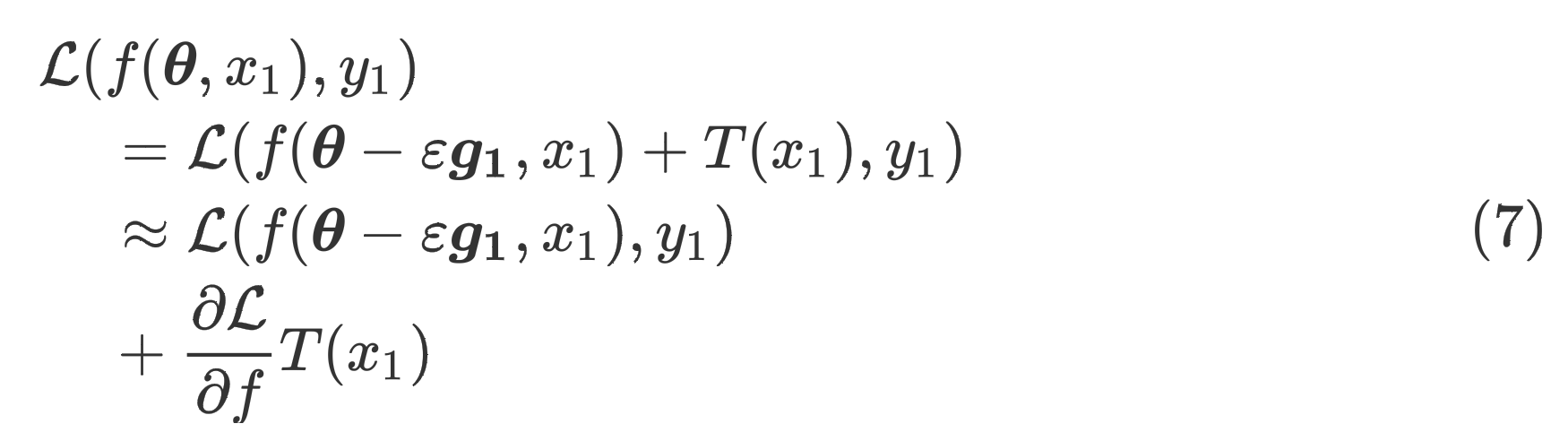
根据式(6)可以推出第一个等号,约等于是从泰勒展开推导的,具体来说
将式(7)带入式(5)得
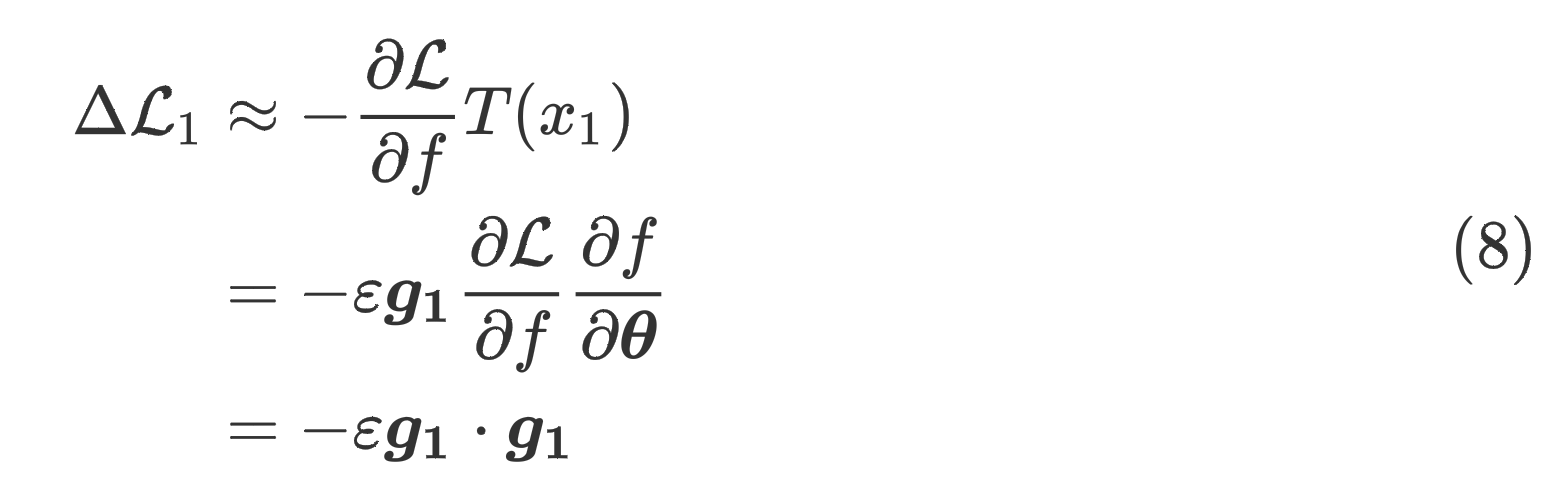
类似的,参数根据样本更新后,在样本上的损失差为=
值得注意的是,根据定义,是负的,因为模型是对于更新的,自然就会导致其损失的降低。如果也是负的,那么在上更新的模型被认为对有积极的影响。上面的等式表明,这种共同关系相当于两个样本的梯度之间的乘积,我们称其为梯度一致性(Gradient Accordance)
COARSE-GRAINED GRADIENT ACCORDANCE
上面提到的可以看作是样本级别的梯度一致性,由于其粒度太细,计算起来非常复杂,因此我们将其应用到batch级别的粗粒度上进行计算
考虑训练过程中包含个样本的mini-batch ,其中样本,标签,其中,即有个类别。这些样本可以根据它们的标签拆分成组(每组内的样本标签是一样的)
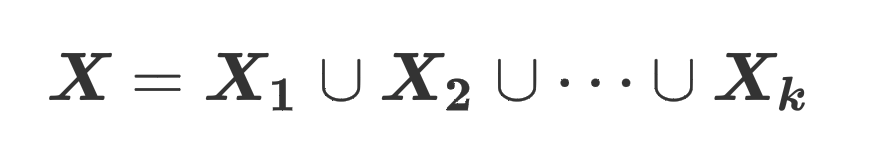
由此可以将拆分成多个子batch的并集,。我们定义两个子batch 和的类一致性分数为
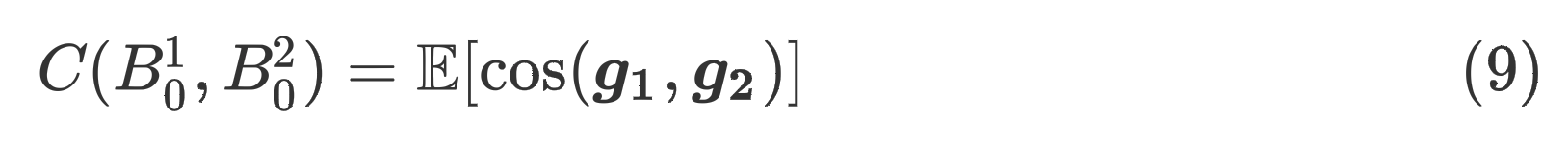
其中,是模型在样本集上的损失对参数的梯度,类一致性可以用于判断:对类别的样本集进行梯度下降是否也会减少类别所对应的样本集的损失
假设一个Epoch中有个batch,那么与的批一致性分数定义如下:
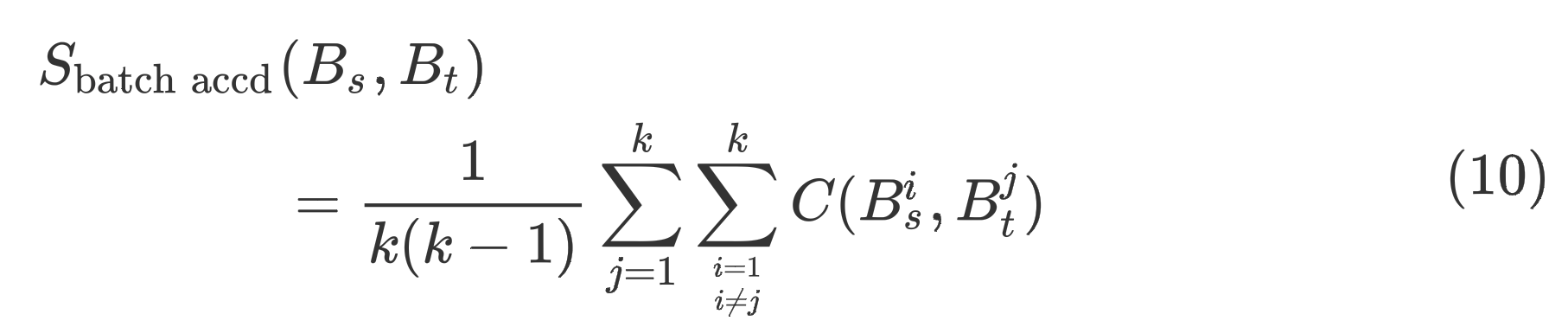
批一致性可以通过评估一个批次的参数更新对另一个批次的影响,量化两个批次的学习一致性。更具体地说,如果是正的,表示这两个批次处于相同的学习节奏下,每个批次更新的模型对它们都有好处
任意一个Epoch的梯度一致性最终定义为
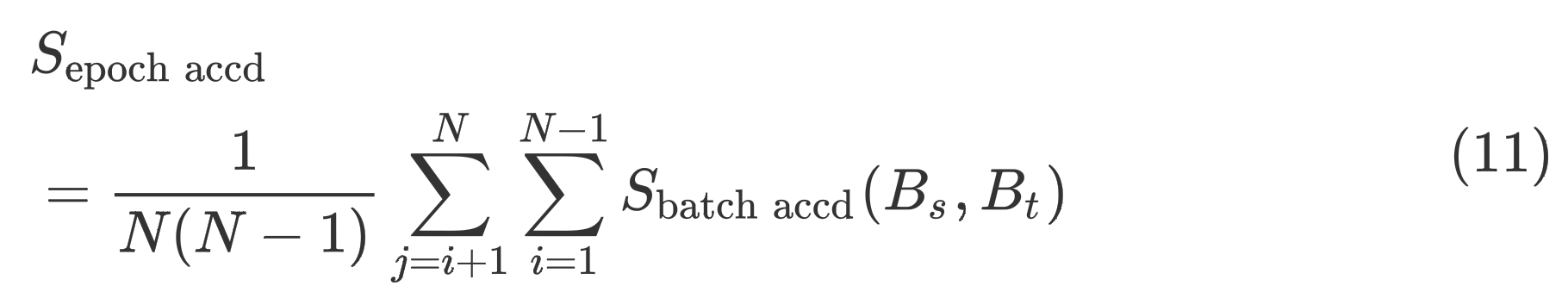
ANALYSIS AND DISCUSSION
实验结果这里就不放了,简单说一下就是作者使用了TextFooler、BERT-Attack、TextBugger三种攻击手段,以PGD、FreeLB、TAVAT等方法为Baseline进行对比,结果表明使用Flooding-X效果很好
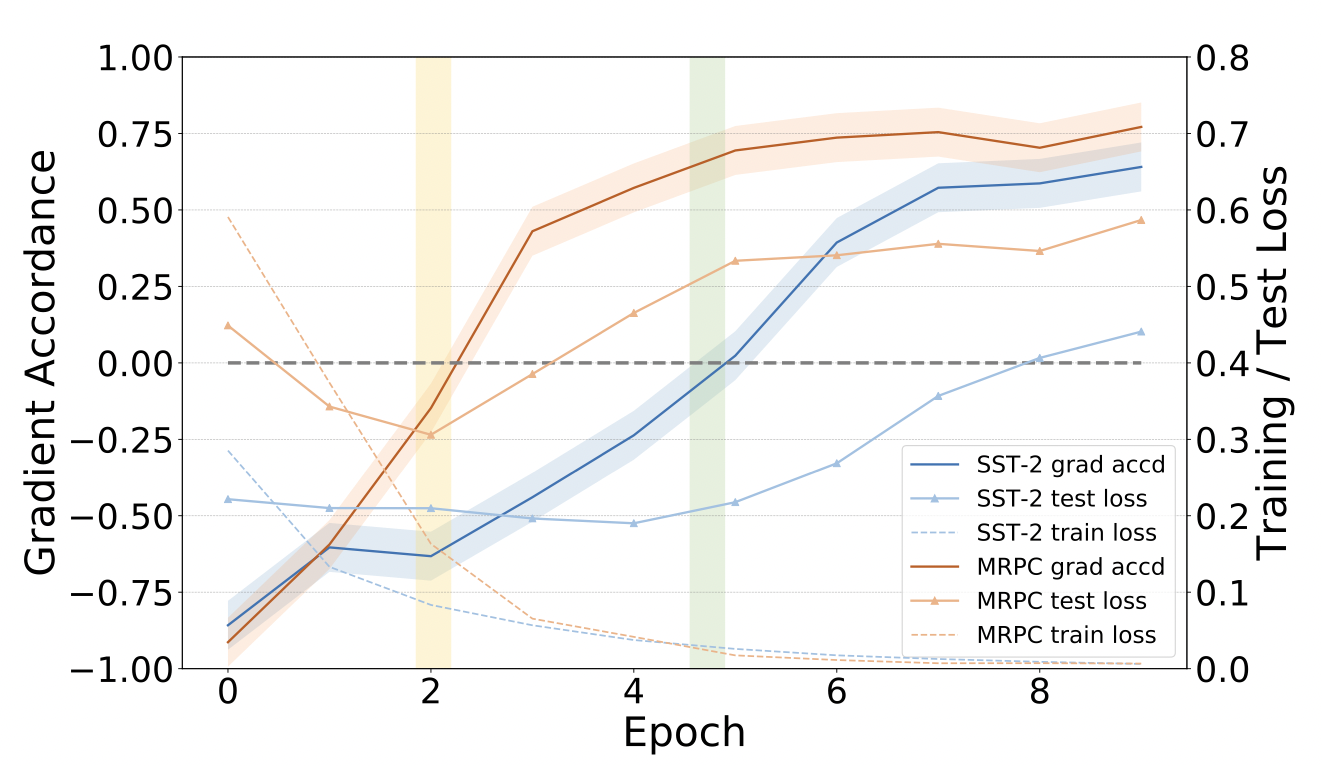
从下图可以看出,当梯度一致性指标从负数变为正数时,测试集损失也开始上升,说明梯度一致性这个指标可以很好的当作是过拟合的信号
个人总结
2020年提出的Flooding本身就是一个非常有意思的Trick,可惜原论文作者也苦于超参数的选择,因此其应用不算广泛。ACL2022这篇论文提出了梯度一致性的概念,让模型自己感知什么时候该进行Flooding,避免了超参数的选择问题