Spark 核心详解
1. RDD 详解
1) 为什么要有 RDD?
在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,之前的 MapReduce 框架采用非循环式的数据流模型,把中间结果写入到 HDFS 中,带来了大量的数据复制、磁盘 IO 和序列化开销。且这些框架只能支持一些特定的计算模式(map/reduce),并没有提供一种通用的数据抽象。
AMP 实验室发表的一篇关于 RDD 的论文:《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》就是为了解决这些问题的。
RDD 提供了一个抽象的数据模型,让我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同 RDD 之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销,并且还提供了更多的 API(map/reduec/filter/groupBy...)。
2) RDD 是什么?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。单词拆解:
Resilient :它是弹性的,RDD 里面的中的数据可以保存在内存中或者磁盘里面;
Distributed :它里面的元素是分布式存储的,可以用于分布式计算;
Dataset: 它是一个集合,可以存放很多元素。
3) RDD 主要属性
进入 RDD 的源码中看下:
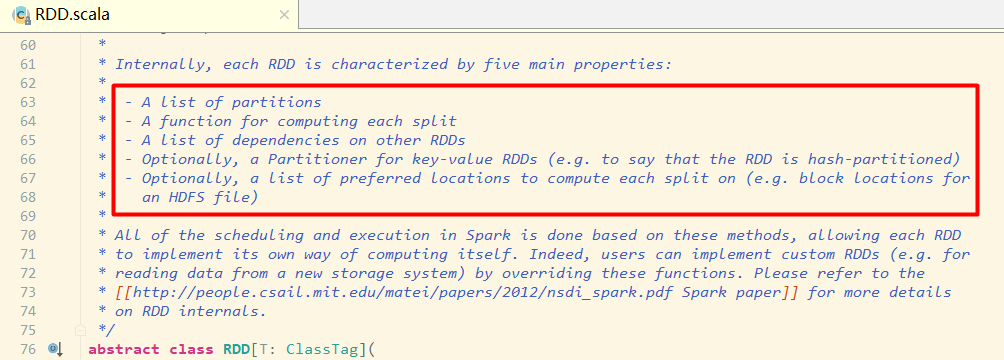
在源码中可以看到有对 RDD 介绍的注释,我们来翻译下:
总结
RDD 是一个数据集的表示,不仅表示了数据集,还表示了这个数据集从哪来,如何计算,主要属性包括:
分区列表、分区函数、最佳位置,这三个属性其实说的就是数据集在哪,在哪计算更合适,如何分区;
计算函数、依赖关系,这两个属性其实说的是数据集怎么来的。
2. RDD-API
1) RDD 的创建方式
makeRDD 方法底层调用了 parallelize 方法
2) RDD 的算子分类
RDD 的算子分为两类:
❣️ 注意:
1、RDD 不实际存储真正要计算的数据,而是记录了数据的位置在哪里,数据的转换关系(调用了什么方法,传入什么函数)。
2、RDD 中的所有转换都是惰性求值/延迟执行的,也就是说并不会直接计算。只有当发生一个要求返回结果给 Driver 的 Action 动作时,这些转换才会真正运行。
3、之所以使用惰性求值/延迟执行,是因为这样可以在 Action 时对 RDD 操作形成 DAG 有向无环图进行 Stage 的划分和并行优化,这种设计让 Spark 更加有效率地运行。
3) Transformation 转换算子
4) Action 动作算子
4) RDD 算子练习
需求:
给定一个键值对 RDD:
val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
key 表示图书名称,value 表示某天图书销量
请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
最终结果:("spark",4),("hadoop",5)。
答案 1:
val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
val rdd2 = rdd.groupByKey()
rdd2.collect
//Array[(String, Iterable[Int])] = Array((spark,CompactBuffer(2, 6)), (hadoop,CompactBuffer(6, 4)))
rdd2.mapValues(v=>v.sum/v.size).collect
Array[(String, Int)] = Array((spark,4), (hadoop,5))
答案 2:
val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
val rdd2 = rdd.groupByKey()
rdd2.collect
//Array[(String, Iterable[Int])] = Array((spark,CompactBuffer(2, 6)), (hadoop,CompactBuffer(6, 4)))
val rdd3 = rdd2.map(t=>(t._1,t._2.sum /t._2.size))
rdd3.collect
//Array[(String, Int)] = Array((spark,4), (hadoop,5))
3. RDD 的持久化/缓存
在实际开发中某些 RDD 的计算或转换可能会比较耗费时间,如果这些 RDD 后续还会频繁的被使用到,那么可以将这些 RDD 进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
val rdd1 = sc.textFile("hdfs://node01:8020/words.txt")
val rdd2 = rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_)
rdd2.cache //缓存/持久化
rdd2.sortBy(_._2,false).collect//触发action,会去读取HDFS的文件,rdd2会真正执行持久化
rdd2.sortBy(_._2,false).collect//触发action,会去读缓存中的数据,执行速度会比之前快,因为rdd2已经持久化到内存中了
持久化/缓存 API 详解
ersist 方法和 cache 方法
RDD 通过 persist 或 cache 方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
通过查看 RDD 的源码发现 cache 最终也是调用了 persist 无参方法(默认存储只存在内存中):

存储级别
默认的存储级别都是仅在内存存储一份,Spark 的存储级别还有好多种,存储级别在 object StorageLevel 中定义的。
总结:
4. RDD 容错机制 Checkpoint
持久化的局限:
持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
问题解决:
Checkpoint 的产生就是为了更加可靠的数据持久化,在 Checkpoint 的时候一般把数据放在在 HDFS 上,这就天然的借助了 HDFS 天生的高容错、高可靠来实现数据最大程度上的安全,实现了 RDD 的容错和高可用。
SparkContext.setCheckpointDir("目录") //HDFS的目录
RDD.checkpoint
总结:
开发中如何保证数据的安全性性及读取效率: 可以对频繁使用且重要的数据,先做缓存/持久化,再做 checkpint 操作。持久化和 Checkpoint 的区别:
5. RDD 依赖关系
1) 宽窄依赖
两种依赖关系类型 :RDD 和它依赖的父 RDD 的关系有两种不同的类型,即宽依赖(wide dependency/shuffle dependency)窄依赖(narrow dependency)

图解:
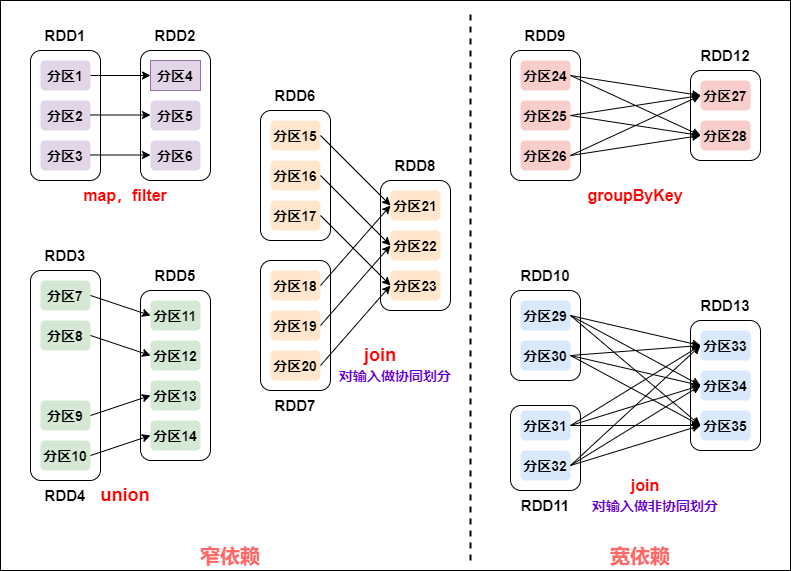
如何区分宽窄依赖:
窄依赖:父 RDD 的一个分区只会被子 RDD 的一个分区依赖;
宽依赖:父 RDD 的一个分区会被子 RDD 的多个分区依赖(涉及到 shuffle)。
2) 为什么要设计宽窄依赖
窄依赖的多个分区可以并行计算;
窄依赖的一个分区的数据如果丢失只需要重新计算对应的分区的数据就可以了。
划分 Stage(阶段)的依据:对于宽依赖,必须等到上一阶段计算完成才能计算下一阶段。
6. DAG 的生成和划分 Stage
1) DAG 介绍
DAG 是什么:
DAG(Directed Acyclic Graph 有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是 RDD 执行的流程);
原始的 RDD 通过一系列的转换操作就形成了 DAG 有向无环图,任务执行时,可以按照 DAG 的描述,执行真正的计算(数据被操作的一个过程)。
DAG 的边界
开始:通过 SparkContext 创建的 RDD;
结束:触发 Action,一旦触发 Action 就形成了一个完整的 DAG。
2) DAG 划分 Stage
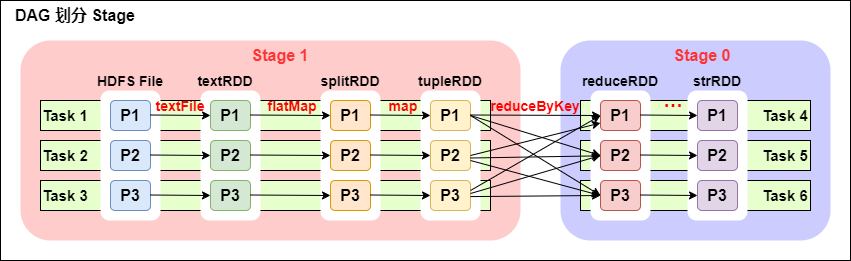
一个 Spark 程序可以有多个 DAG(有几个 Action,就有几个 DAG,上图最后只有一个 Action(图中未表现),那么就是一个 DAG)。
一个 DAG 可以有多个 Stage(根据宽依赖/shuffle 进行划分)。
同一个 Stage 可以有多个 Task 并行执行(task 数=分区数,如上图,Stage1 中有三个分区 P1、P2、P3,对应的也有三个 Task)。
可以看到这个 DAG 中只 reduceByKey 操作是一个宽依赖,Spark 内核会以此为边界将其前后划分成不同的 Stage。
同时我们可以注意到,在图中 Stage1 中,从 textFile 到 flatMap 到 map 都是窄依赖,这几步操作可以形成一个流水线操作,通过 flatMap 操作生成的 partition 可以不用等待整个 RDD 计算结束,而是继续进行 map 操作,这样大大提高了计算的效率。
为什么要划分 Stage? --并行计算
一个复杂的业务逻辑如果有 shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照 shuffle 进行划分(也就是按照宽依赖就行划分),就可以将一个 DAG 划分成多个 Stage/阶段,在同一个 Stage 中,会有多个算子操作,可以形成一个 pipeline 流水线,流水线内的多个平行的分区可以并行执行。
如何划分 DAG 的 stage?
对于窄依赖,partition 的转换处理在 stage 中完成计算,不划分(将窄依赖尽量放在在同一个 stage 中,可以实现流水线计算)。
对于宽依赖,由于有 shuffle 的存在,只能在父 RDD 处理完成后,才能开始接下来的计算,也就是说需要要划分 stage。
总结:
Spark 会根据 shuffle/宽依赖使用回溯算法来对 DAG 进行 Stage 划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的 stage/阶段中
具体的划分算法请参见 AMP 实验室发表的论文:《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》
7. RDD 累加器和广播变量
在默认情况下,当 Spark 在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark 提供了两种类型的变量:
1) 累加器
1. 不使用累加器
var counter = 0
val data = Seq(1, 2, 3)
data.foreach(x => counter += x)
println("Counter value: "+ counter)
运行结果:
Counter value: 6
如果我们将 data 转换成 RDD,再来重新计算:
var counter = 0
val data = Seq(1, 2, 3)
var rdd = sc.parallelize(data)
rdd.foreach(x => counter += x)
println("Counter value: "+ counter)
运行结果:
Counter value: 0
2. 使用累加器
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。这时使用累加器就可以实现我们想要的效果:
val xx: Accumulator[Int] = sc.accumulator(0)
3. 代码示例:
import org.apache.spark.rdd.RDD
import org.apache.spark.{Accumulator, SparkConf, SparkContext}
object AccumulatorTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//使用scala集合完成累加
var counter1: Int = 0;
var data = Seq(1,2,3)
data.foreach(x => counter1 += x )
println(counter1)//6
println("+++++++++++++++++++++++++")
//使用RDD进行累加
var counter2: Int = 0;
val dataRDD: RDD[Int] = sc.parallelize(data) //分布式集合的[1,2,3]
dataRDD.foreach(x => counter2 += x)
println(counter2)//0
//注意:上面的RDD操作运行结果是0
//因为foreach中的函数是传递给Worker中的Executor执行,用到了counter2变量
//而counter2变量在Driver端定义的,在传递给Executor的时候,各个Executor都有了一份counter2
//最后各个Executor将各自个x加到自己的counter2上面了,和Driver端的counter2没有关系
//那这个问题得解决啊!不能因为使用了Spark连累加都做不了了啊!
//如果解决?---使用累加器
val counter3: Accumulator[Int] = sc.accumulator(0)
dataRDD.foreach(x => counter3 += x)
println(counter3)//6
}
}
2) 广播变量
1. 不使用广播变量
2. 使用广播变量
3. 代码示例:
关键词:sc.broadcast()
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object BroadcastVariablesTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//不使用广播变量
val kvFruit: RDD[(Int, String)] = sc.parallelize(List((1,"apple"),(2,"orange"),(3,"banana"),(4,"grape")))
val fruitMap: collection.Map[Int, String] =kvFruit.collectAsMap
//scala.collection.Map[Int,String] = Map(2 -> orange, 4 -> grape, 1 -> apple, 3 -> banana)
val fruitIds: RDD[Int] = sc.parallelize(List(2,4,1,3))
//根据水果编号取水果名称
val fruitNames: RDD[String] = fruitIds.map(x=>fruitMap(x))
fruitNames.foreach(println)
//注意:以上代码看似一点问题没有,但是考虑到数据量如果较大,且Task数较多,
//那么会导致,被各个Task共用到的fruitMap会被多次传输
//应该要减少fruitMap的传输,一台机器上一个,被该台机器中的Task共用即可
//如何做到?---使用广播变量
//注意:广播变量的值不能被修改,如需修改可以将数据存到外部数据源,如MySQL、Redis
println("=====================")
val BroadcastFruitMap: Broadcast[collection.Map[Int, String]] = sc.broadcast(fruitMap)
val fruitNames2: RDD[String] = fruitIds.map(x=>BroadcastFruitMap.value(x))
fruitNames2.foreach(println)
}
}