Spark地基之RDD
RDD是Spark 的基本数据抽象,相较于 Hadoop/MapReduce 的数据模型而言,各方面都有很大的提升。
Spark的开山之作《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》提出了RDD数据结构:
We present Resilient Distributed Datasets (RDDs), a distributed memory abstraction that lets programmers perform in-memory computations on large clusters in a fault-tolerant manner.
RDD数据结构是一种分布式的内存抽象,可以容错方式在大型的集群中进行内存运算。
To achieve fault tolerance effificiently, RDDs provide a restricted form of shared memory, based on coarse-grained transformations rather than fifine-grained updates to shared state.
为了提供更有效的容错机制(Fault Tolerance),RDD采用了粗粒度的(coarse-grained)转换,而不是细粒度(fine-grained)的更新一个可变状态。
在以往的设计中,会将内存进行集群抽象,比如分布式共享内存、键值存储(Redis)和数据库等,这种方式是细粒度更新一个可变状态,相应的容错方式也需要进行机器间的数据复制和日志传输,这会加大网络开销和机器负担。
而RDD则使用了粗粒度转换,即对于很多相同的数据项使用同一种操作(如map、filter、join等)。这种方式能够通过记录RDD之间的转换从而刻画RDD的继承关系(lineage),而不是真实的数据,最终构成一个DAG(有向无环图),这种结构使得当发生RDD丢失时,能够利用上下图中的信息从其祖辈RDD中重新计算得到。
RDD定义
an RDD is a read-only, partitioned collection of records
在RDD的论文中,对于RDD给出的定义:RDD是一组只读的,可分区的数据集。
RDD具有如下特性:
分区
分区代表同一个 RDD 包含的数据被存储在系统的不同节点中,这也是它可以被并行处理的前提。
逻辑上,可以认为 RDD 是一个大的数组。数组中的每个元素代表一个分区(Partition)。
在物理存储中,每个分区指向一个存放在内存或者硬盘中的数据块(Block),而这些数据块是独立的,它们可以被存放在系统中的不同节点。
RDD 只是抽象意义的数据集合。
RDD 中的每个分区存有它在该 RDD 中的 index。通过 RDD 的 ID 和分区的 index 可以唯一确定对应数据块的编号,从而通过底层存储层的接口中提取到数据进行处理。
在集群中,各个节点上的数据块会尽可能地存放在内存中,只有当内存没有空间时才会存入硬盘,最大化地减少硬盘读写的开销。
不可变
每个RDD分区都是只读的,其内部包含的分区信息是不可更改的,创建RDD只能通过如下两种方式:
这样的属性使得:
提升了Spark的计算效率,更易于错误恢复。对于代表中间结果的 RDD,我们需要记录它是通过哪个 RDD 进行哪些转换操作得来,即依赖关系,而不用立刻去具体存储计算出的数据本身。
系统启动一个新的任务(Backup Task)可以对执行慢的任务备份运行,类似于MapReduce的推测执行。
虽然RDD是不可变的,但是允许用户修改两方面的属性:
持久化(persistence):用户可以指定数据的存储策略,例如,数据存储在内存、磁盘等。程序员可以通过接口指定将来可能会重复使用的RDD,默认存储在内存中,也可以在内存不足时,存放在磁盘中。也可以指定存储优先级来指定哪部分内存中的数据优先刷新到磁盘。
分区(partitioning):用户可以修改分区数量,实现修改并行计算单元的划分结构,这对于数据存放位置优化十分有用,例如,确保两个dataset以相同的Hash方式进行Hash分区,从而进行。
并行操作
RDD的分区特性使得它天然支持并发操作,可以在不同的节点的数据分别进行处理产生新的RDD。
RDD数据结构
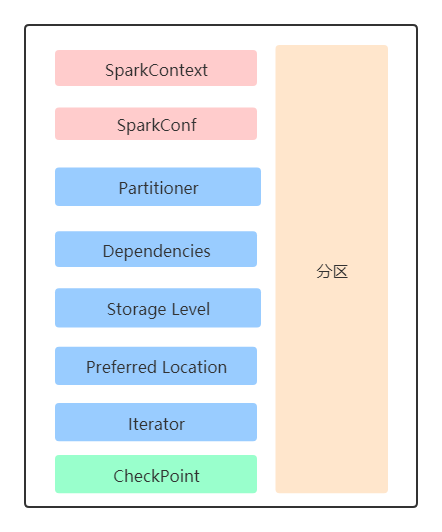
其中,SparkContext 是所有 Spark 功能的入口,它代表了与 Spark 节点的连接,可以用来创建 RDD 对象以及在节点中的广播变量等。一个线程只有一个 SparkContext。SparkConf 则是一些参数配置信息。
RDD数据结构公开5部分的公共接口:
:分区优先存放的节点位置。
:依赖列表
:Compute the elements of partition p given iterators for its parent partitions(不理解,这部分应该是应该是基于分区进行数据计算的)。
:表明RDD分区方式是Hash或Range。
内存管理
Spark提供了三种对RDD持久化的管理方式:
LRU逐出策略
为了管理有限的可用内存,我们在RDD级别使用LRU逐出策略。当计算了一个新的RDD分区,但没有足够的空间存储,如果最近访问最少的RDD分区和这个刚计算出的新RDD分区不在同一个RDD中,将会从最近访问最少的RDD中逐出一个分区。否则,会将旧分区保存在内存中,来防止频繁地从相同的RDD中进出,因为大多数操作都运行在整个RDD上,导致在未来有极大可能需要使用已经在内存中的旧分区。同时Spark还为每个RDD为用户提供了设置“持久化优先级”的进一步控制选项。
关于Spark内存管理的进一步优化,在RDD的论文中,指出目前集群上的每个Spark实例目前都有自己单独的内存空间,之后计划研究通过统一的内存管理器跨Spark实例共享RDD。
RDD依赖关系
从抽象的角度看,RDD间存在着血统继承关系,而真正实现时,其本质是RDD间依(Dependency)关系。依赖关系是RDD重要的组件,它记录了从哪个RDD经过哪个转换得到新的RDD,使得Spark不需要对中间结果进行复制以防止数据丢失的目的。
从图的角度看,RDD为节点,在一次转换操作中,创建得到的新RDD称为子RDD,同时会产生新的边,即依赖关系,子RDD依赖向上依赖的RDD便是父RDD,可能会存在多个父RDD。我们可以将这种依赖关系进一步分为两类,分别是窄依赖(Narrow Dependency)和宽依赖(Wide Dependency),也称之为Shuffle依赖。
narrow dependencies, where each partition of the parent RDD is used by at most one partition of the child RDD,wide dependencies, where multiple child partitions may depend on it. For example,map leads to a narrow dependency, whilejoin leads to to wide dependencies (unless the parents are hash-partitioned).
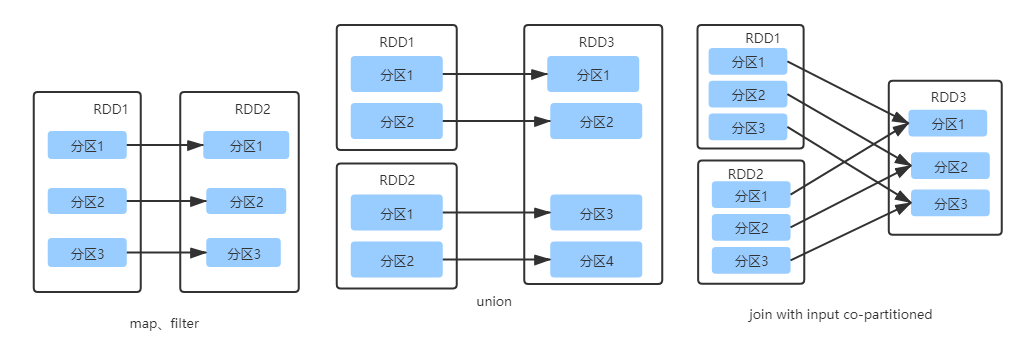
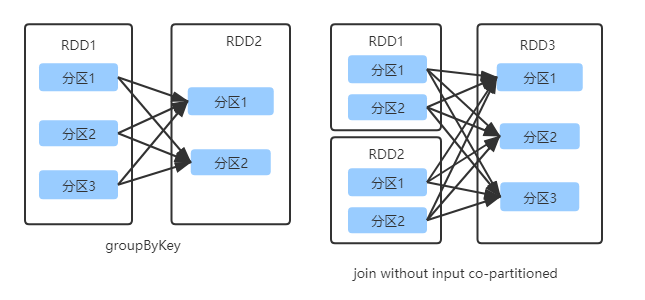
窄依赖就是父 RDD 的分区可以一一对应到子 RDD 的分区,例如,宽依赖就是父 RDD 的每个分区可以被多个子 RDD 的分区使用,例如。
为什么将将依赖关系划分为窄依赖和宽依赖?
窄依赖可以在一个节点上对多个分区以Pipeline方式计算所有的父分区,例如,可以在执行操作后,紧接着进行。而宽依赖要求先计算好所有的父分区的数据,保证所有的父分区数据都是可用的,并且还可能需要执行类似于MapReduce的操作在节点间进行数据的混洗(Shuffle)。
从节点故障后恢复的角度,对于窄依赖,只需要对丢失的父分区重新计算,并且可以在不同的节点并行地重新计算;而对于宽依赖,涉及到RDD各级的多个父分区,单个失败的节点可能会导致RDD所有祖先的某些分区的丢失,需要完全重新执行。
窄依赖
当子RDD分区依赖的父RDD分区不被其他的子RDD分区依赖,就是窄依赖。
宽依赖
父RDD分区被多个子RDD分区依赖,就是宽依赖。
任务调度
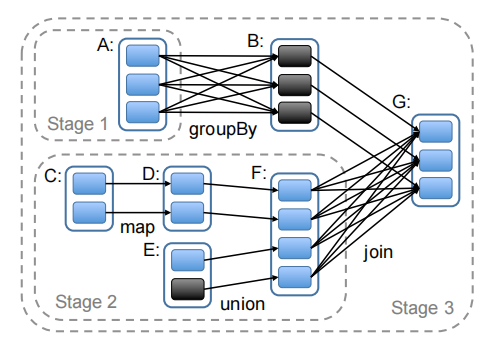
Spark调度器和Dryad类似,不过综合考虑了缓存在内存中的RDD分区。当执行Action操作时,调度器检查RDD的继承关系图(Lineage)以构建Stage的DAG来执行。每个Stage内部尽可能多地包含一组具有窄依赖关系的转换,并将它们流水线并行化。Stage的边界有两种情况:
调度器另外加载一组任务计算每个Stage中丢失的分区,直到完成目标RDD。
调度器给机器分配任务采用基于数据位置的延迟调度(Delay Scheduling)策略。
如果要处理的分区位于节点内存中,那么将任务分配给该节点。
否则,如果要处理的分区含有Preferred Location例如HDFS文件,那么将任务分配给这组节点。
对于宽依赖,在拥有父RDD分区的节点上将中间结果物化,来简化容错处理,这一点的处理方式和MapReduce物化map处理输出类似。
如果某个任务失败,只要Stage中父RDD分区依然可用,只需要在另外一个节点重新运行,如果某些Stage不可用(例如,Shuffle时某个map输出丢失),重新提交任务来并行地对丢失分区计算。在原论文中,尽管只需要只需要直接备份RDD继承图,Spark无法接受调度器失效。
CheckPoint
RDD的Lineage可以用于故障恢复,但是对于Lineage链很长的RDD来说,数据恢复需要花费很长的时间。对一些RDD设置检查点很有用。一般而言,将一些Lineage链很长、包含宽依赖的RDD设置检查点十分有用。Spark为RDD提供了设置检查点的API。