CRLF、CSRF、SSRF攻击与利用
前言
本文叙述了crlf、csrf和ssrf的原理、攻击利用和一些绕过方法,作为个人笔记,内容可能不全面,日后有接触新的方法会更新。
CRLF
原理
这个漏洞名词来源于打印机,在计算机中表示一行的结束:
回车=CR=\r=%0d=Ascii(13)=Ascii_16(0D)换行=LF=\n=%0aAscii(10)=Ascii_16(0A)
在不同操作系统中表示行结束的方法也不相同:
Windows:CRLFLinux/Unix:LFMac:老版本用CR,新版用LF
在http头的规范中是以CRLF表示一行的结束,因此无论是请求头还是响应头,每行的末尾都有一个。
GET http://example.com/skipto?u=http://other.com HTTP/1.1\r\n
Host:example.com\r\n
User-Agent:Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:89.0) Gecko/20100101 Firefox/89.0\r\n
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8\r\n
Accept-Encoding:gzip, deflate, br\r\n
Accept-Language:zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2\r\n
Connection:keep-alive\r\n
上面代码是一个普通的页面跳转请求头,我们很容易发现的值是用户可控的,正常运行的话返回的会是第2页的内容,那么现在重新发送请求,将请求截下来,把改成再提交,假如服务器没有对参数进行检查并过滤,在响应头中直接将用户输入拼接到Location的值里面,响应头就会变成像下面那样的代码:
HTTP/1.1 302 Found\r\n
Date: Sun, 08 Aug 2021 07:01:25 GMT\r\n
Location:http://other.com\r\n
SetCookie:crlf\r\n
Content-Length:0\r\n
Content-Type: text/html; charset=utf-8\r\n
Connection: keep-alive\r\n
在拼接http响应头的过程中,服务器检测到的时候会按照http规范认为已经到达一行的末尾,后面的数据输出到下一行。在对文件进行io读写的时候也经常会以或者作为判断行末尾的依据,后面的数据换行后再输出,这两个的原理是一样的。CRLF这种攻击本质和sql注入、xss一样,都是由于没有对用户输入进行完全检查与过滤导致的漏洞,区别在于sql注入作用在数据库,xss的效果体现在网页主体,clrf则会将恶意代码输出在响应头中。
攻击&利用
这种漏洞属于客户端漏洞,经常会出现在有重定向或者页面跳转的地方。攻击的方法很简单,观察输入是否在响应头中,然后提交,记得编码,查看服务器是否响应,最后一步根据需要将漏洞转换成会话固定、xss等。至于利用的方式,大致有以下几种:会话固定上面的例子就是一个典型的会话固定,通过插入请求头的方式实现给访问者设置一个session,当然除了cookie也能插入其他请求头。
#部分请求头:
GET http://example.com/skipto?u=http://other.com\r\nSet-Cookie:mycookie HTTP/1.1\r\n
...
#对应的响应头:
HTTP/1.1 302 Found\r\n
Location:http://other.com\r\n
SetCookie:mycookie\r\n
...
xss在http规范中,响应头和正文之间是用两个CRLF进行区分的,也就是,我们可以利用这个特性往正文里写入xss:
#部分请求头
GET http://example.com/skipto?u=\r\n HTTP/1.1\r\n
...
#对应的响应头,利用xss直接将cookie发送到攻击者的服务器
HTTP/1.1 302 Found\r\n
Location:\r\n
HTTP/1.1\r\n
...
#对应的响应头,利用xss直接将cookie发送到攻击者的服务器
HTTP/1.1 302 Found\r\n
Location:\r\n
缓存中毒这种攻击方式需要服务端有CDN、负载均衡或者反向代理等缓存设备。利用方式如下:
#直接在请求头中插入X-Forwarded-Host,观察响应包中是否有回显
GET http://example.com/skipto?u=\r\nX-Forwarded-Host:http://fishing.com HTTP/1.1\r\n
...
另一个名字相近但完全不同的攻击方式叫缓存欺骗,利用前要满足下列条件:
Web缓存功能设置为通过URL的扩展名来判断是否进行缓存文件,且忽略任何缓存头;
当访问一个不存在资源时返回一个页面而不是显示页面不存在;
诱使访问URL时,受害者必须已经通过身份验证;
其攻击的过程如下:
通过钓鱼/xss等方法诱使已经登录的用户访问攻击者服务器上的一个资源(http://hack.com/attack/1.png);请求到达代理/CDN,代理不熟悉这个文件,于是向web服务器发起请求;web服务器返回受害者的用户页面内容和200状态码,这里对应了上面第二点和第三点条件,没有返回页面不存在并且是用户已登录状态;缓存机制收到响应同时发现url以资源文件扩展名(.png)结尾,并且由于缓存机制忽略响应头,这个资源会被保存在新建的attack目录下,被缓存的文件名为1.png,这里对应了第一个条件;然后受害者接收到他的账户页面;攻击者访问http://hack.com/attack/1.png,请求到达代理服务器,代理直接将受害的缓存账户页面返回给攻击者。
绕过
对于CRLF来讲核心就是,服务器防止CRLF大部分也是通过过滤器限制这两个字符,绕过的方法大致有以下几种:
url单/双层编码;更改http版本到1.0,不发送Host头,并将请求分片构建特殊请求;将\r\n转换成ascii码;
另外在发送给客户端xss语句的时候可能会被浏览器过滤掉,这个时候只需要在前面再插入一个请求头即可绕过。
CSRF
原理
CSRF的中文翻译叫跨站请求伪造,和XSS利用方式有点像,但是XSS利用的是站点内信任的用户,而CSRF是通过伪装成被信任的用户请求受信任网站。攻击原理如图:
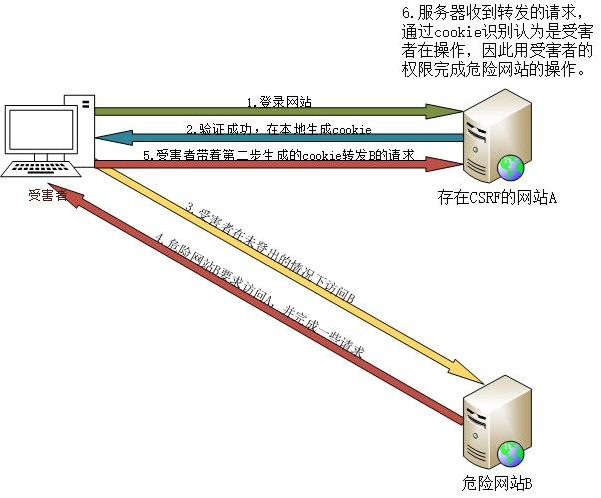
由此可以看出来,要利用这个漏洞必须满足下面两个条件:
登录存在漏洞的网站,并在本地生成cookie;
在不登出的情况下访问攻击者的服务器;
攻击&利用
这种漏洞会出现在用户操作中的增、删、改功能的位置,比如用户修改密码的地方,如果网站在上述三种功能中没有用到Referer/Token技术,那么肯定存在csrf,如果存在,可以绕过,那也一样有漏洞。类型分为GET、POST两种,他们攻击方式的区别就是GET型只需要构造url,然后诱导受害者访问即可,POST型则要构造自动提交的表单,再诱导受害者访问。整个攻击流程如下:
制作伪装页面->诱导用户访问->触发非法操作
不管是哪种类型,漏洞利用的核心就是根据需要构造页面,然后诱导受害者点击,可以通过钓鱼,也可以利用xss等。GET
404 not found
404 not found
POSTpost模式通常是构造一个自动提交的隐藏表单:
404 not found
404 not found
绕过
对于CSRF的保护通常是使用Referer和Token,因此为了达到攻击的目的,这两种防护措施就是需要绕过的对象。Referer1.利用伪协议:http://、https://、ftp://、file://、data:、javascript:,这时候referer置空就能绕过了。