分布式事务与分布式系统
一. 概述
在我们讲解了spring事务的管理,只涉及到单数据源的问题,无论业务系统发生了任何异常,数据库都能有效的保证数据的一致性。然而现在微服务盛行的时代,业务系统不单单只与一个数据源打交道,还会和其他业务系统打交道,其他业务系统可以理解为另外一套数据库。
我们将"业务系统"为协调者,数据库以及其他业务系统为"参与者"。当协调者在整个事务过程中,将参与者A提交了事务,然而参与者B提交事务失败。这时协调者需要将参与者A需要回滚,然而回滚失败,协调者该如何去处理该异常场景。例如,协调者向参与者B提交事务超时,参与者是否已经提交了事务,还是未提交事务;这个就是微服务常见的分布式事务问题。
在数据量暴增,访问量很大的情况下,往往一个单机服务器是无法有效的提供服务的;以及当服务器宕机后无法提供服务。这时就提出了这么分布式系统这个概念,在《分布式系统概念与设计》一书中,对分布式系统做了如下定义:分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。基于该分布式系统,衍生出了分布式事务这个专业术语。
二. CAP理论
CAP理论有三个特性
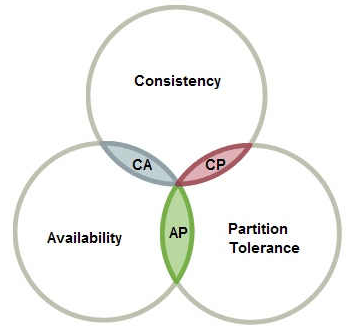
Consistency 数据一致性:副本中的数据一致性;
Availability 可用性:当某个节点宕机后,其他节点依然可以提供服务
Partition Tolerance 分区容错性:当网络出现抖动,节点之间短时间出现通信中断。
三. Base 理论
基于无法满足CAP条件,提出了最终一致性解决方案。其摒弃短暂的不可用。
基本可用(Basically Available)
软状态(Soft State)
最终一致性(Eventually Consistent)
四. 分布式事务
分布式事务的解决方案。
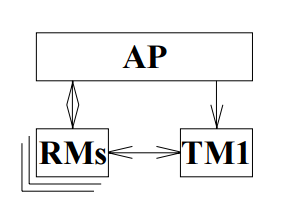
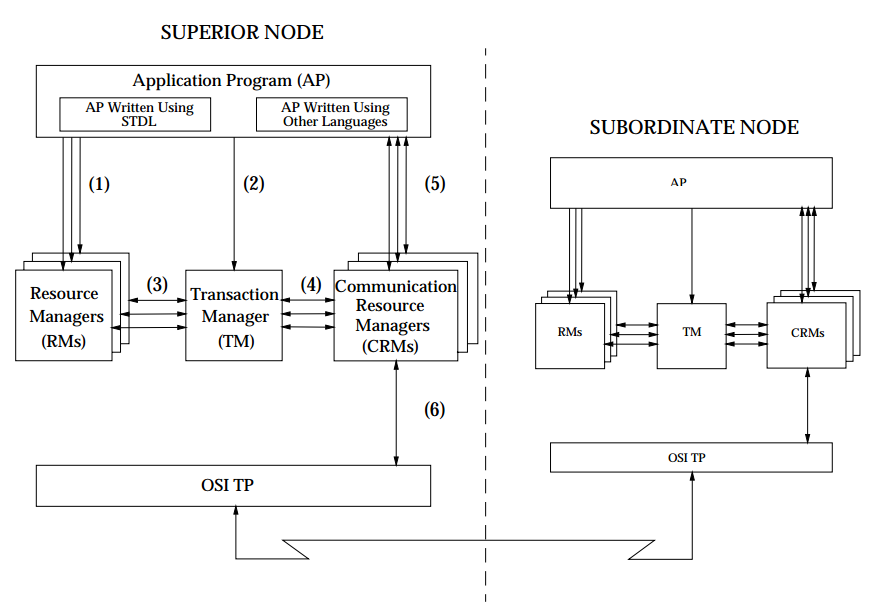
分布式事务中涉及到几个关键的概念,X/Open 组织(即现在的 Open Group )定义了分布式事务处理模型。 X/Open DTP 模型( 1994 )包括应用程序( AP )、事务管理器( TM )、资源管理器( RM )、通信资源管理器( CRM )四部分。一般,常见的事务管理器( TM )是交易中间件,常见的资源管理器( RM )是数据库,常见的通信资源管理器( CRM )是消息中间件。
1. 两阶段提交协议
两阶段提交协议分为两个阶段进行,第一阶段是预处理阶段,也就是发送SQL语句,业务系统校验数据库返回的响应进行校验。第二阶段是提交阶段,也就是发送commit指令给数据库。
第一阶段 预处理阶段:事务协调者(事务管理器)给每个参与者(资源管理器)发送Prepare消息,每个参与者要么直接返回失败 ,要么在本地执行事务,写本地的redo和undo日志,但不提交。其预处理要分为三个子步骤:
协调者节点向所有参与者节点询问是否可以执行提交操作(vote),并开始等待各参与者节点的响应。
参与者节点执行询问发起为止的所有事务操作,并将Undo信息和Redo信息写入日志。(注意:若成功这里其实每个参与者已经执行了事务操作)
各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则它返回一个”同意”消息;如果参与者节点的事务操作实际执行失败,则它返回一个”中止”消息。
第二阶段 提交阶段:如果协调者收到了参与者的失败或超时,直接给每个参与者发送回滚(rollback)操作;否则发送提交(commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。
无论最后结果如何,第二阶段都结束当前事务。
两阶段有如下几个缺点:
同步阻塞问题 。执行过程中,所有参与节点都是事务阻塞型的。在第一阶段,做预处理时会锁住对应的资源,到第二阶段收到协调者发送的commit或者rollback消息才释放锁资源,则协调者发送回滚操作才释放锁资源。在锁资源到释放资源过程,会阻塞第三方节点访问该锁资源。单点故障 。由于协调者的重要性,一旦协调者发生故障,则无法继续完成事务操作。数据不一致 。在第二阶段中,当协调者向发送commit消息请求之后,发生了局部网络异常或者发送commit请求过程中协调者发生了故障,会出现部分参与者接收到commit消息并进行提交,而其他参与者未收到commit消息则无法提交,于是整个事务中就会出现数据不一致的现象。二阶段无法解决的问题 。协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
其在应用工程中很少使用,但其有一定的参考性;
2. 三阶段提交协议
基于两阶段的问题,提出了三阶段提交协议,主要的改动点:
引入了超时机制,同时在协调者和参与者都引入超时机制
在第一阶段和第二阶段中插入准备阶段。保证了在最后提交阶段之前各参与者的状态是一致的。
三阶段提交提交协议,分为三个阶段,CanCommit阶段、PreCommit阶段、DoCommit阶段。
简单理解即可,在日常的开发中,很少使用;我们重点了解TCC协议
3. TCC事务协议
TCC是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(回滚)操作。它分为三个阶段:
Try阶段:主要是对业务系统做检测即资源预留
Confirm阶段:主要是对业务系统做确认提交,Try阶段执行成功并开始执行Confirm阶段时,默认Confirm阶段是不会出错的。即Try成功,Confirm一定会成功
Cancel阶段:主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
当其中一个子业务系统返回失败,或者超时,则这次事务以失败处理 ,进入不到第二阶段。那么需要向所有子业务系统发送回滚请求,使其子业务系统释放其资源 。当发送回滚请求超时时,则重复发送,以确保子业务系统回滚成功 。在扣减库存而言,则解冻该库存数量。
为了避免重复发送消息,所有的子业务系统都必须提供 接口幂等性原则 。 为了避免主业务系统宕机,无法知晓这次事务的执行情况,需提供一个机制,记录这次事务的执行状态,待服务器重新提供服务或者定时任务定时处理事务后续的动作,以确保 事务的完整性 。
问题:
当提交超时时,该怎么处理?
需业务场景需要,是否需要回滚,还是依然继续提交。
当只要有一个子业务系统返回失败或者超时,跳到Cancel阶段进行回滚后直接结束这次事务。如果回滚超时或者失败该如何处理?或者中途宕机,有该如何处理?
在业务系统中需要记录该事务的执行状态以及子事务的执行状态;当发现超时或者宕机时,可以从中回复执行;
改善点:
在Confirm阶段、Cancel阶段是否需要异步执行,可以有效的提供响应速度。
4. 最大努力通知
通过异步的形式,或者采用第三方组件将请求确保将消息发送给子业务系统。其需要评估该请求在子业务必须执行成功的;否则子业务系统执行失败,主业务系统还需要进行回滚,逻辑将会变得复杂;什么情况下,会采用该机制呢?主要是发短信等必须执行成功的场景下,才会采用该方法;
4.1 本地消息表
将请求保存到本地数据库,交由后台程序异步将请求推送给子业务系统。一般来讲,设计重试3次即可,当连续发送三次失败,即通知运维人员进行跟进处理,具体什么原因导致;如果涉及不限次数的发送,那么就会导致业务系统压力过大;
4.2 半消息/最终一致性
采用MQ,redis等中间件,事务性的将请求推送子业务系统;前提下,需要确保该中间件是否支持事务性操作,如不支持,需业务系统评估如何才能达到事务性推送。例如RocketMQ消息中间,是支持事务性操作,其原理是将消息保存到临时队列,当业务系统commit操作时,才将该消息从临时队列移出到目标队列。
五. 副本一致性
5.1 raft
该算法中有三种角色,follower(跟随着)、candidate(候选者)、Leader(领导者)
其主要有两个环节,第一个环节是选举Leader;第二环节是副本拷贝。
当集群中,没有Leader时或者Leader宕机时,
当客户端发送请求过来时,有Leader接收处理,并广播给其他follower;当收到半数的回复成功时,即可确认该请求处理成功。
5.2 paxos
5.2.1 目标
多节点之间对提案达成共识,意味着大多数节点都接受该提案。
5.2.2 角色
Proposer::提议者, 专门用来发出提案(一个值);当超过半数,就认为该提案被选定的。
Acceptor:接收者,专门用来接收提案,并判断是否通过该提案;
Learner:学习者,用来学习被选定的提案(个人理解,可有可无)。
5.2.3 basic-paxos
5.2.3.1 流程
其简单的流程图如下,这里不考虑异常,竞争下的场景;

在prepare阶段,Proposer向Acceptor咨询自己是否有提议权(或者发表权)。一旦超过半数Acceptor回复OK,则进入accept第二阶段。Proposer发发送accept请求,超过Acceptor半数回复OK。则结束这次提议。至于Learner通过谁去学习这个【proposal-value】,
如果Acceptor没有批准过提议权的,则无保留意见批准,并记录该
如果Acceptor之前已经批准过提议权
prepare响应中如果有【proposal-value】A,则设置Proposer的【proposal-value】为A,否则自行做决定该值。
如果超过半数回复同意的,则进入第二阶段去发表意见。
否则重新发起提议,发送prepare消息获取提议权。
将【proposal-id】与【proposal-value】发送给Acceptor。
如果Acceptor当前的【proposal-ID】A与这次accept请求中的【提议ID】B相比较,如果不相等,则回复【NO】。否则设置Acceptor的【proposal-value】的值为accept请求中的【proposal-value】,并回复【OK】响应。
如果超过半数回复OK的,则不用管理其他回复【NO】响应,把该【proposal-value】发送给Learner进行学习。否则重新发送prepare消息,再进行一次提议;最终【proposal-value】是一致的。
5.2.3.2 深入探讨
答案:是不会存在多个不同【proposal-value】。因为在prepare阶段,如果Acceptor已经有【proposal-value】值,Proposal会拿这个值在accept阶段进行发送;如果没有的话,Proposal会自行生成一个【proposal-value】值到accept阶段进行发送;同时在accpet阶段,如果Acceptor会去校验【proposal-id】是否相同,相同则设置该【proposal-value】值。有点类似
答案:不会。因为该协议是只要超过半数的Acceptor在运转,依然可以提供服务。而Proposal宕机,Proposal重启进行下一轮提议或者交由其他Proposer提议,最终【proposal-value】是达成一致。
在多个Proposal进行提议时,容易对【proposal-id】进行竞争,导致性能低效,极端情况下,出现活锁现象。以及为了达成共识,需要先prepare阶段以及accept阶段,会有损耗,也是导致性能低效的原因之一。
5.2.4 multi-paxos
这个就是基于basic-paxos中暴露的问题,提供出来的解决方案。
添加一个leader角色,所有的提议都由Leader角色来发起,这样子有效的避免竞争带来的性能低效以及活锁现象。
但是从而导致Leader角色的服务压力过大 。有效的减少Prepare阶段,在满足特定的场景,Leader可以直接跳过prepare阶段,直接到accept阶段,减少交互次数,可以有效的减少性能低效问题。
问题,
只有当Acceptor自身发现只接收到一个Leader的请求时,就会告知Leader,让其跳过prepare阶段;
兰伯特博士提出比较简单的方式,就是哪个server的ID最大,谁就是最大。也可以采用Raft机制,谁先发起竞聘,谁就是Leader。
5.2.5 总结
讲了basic-paxos和multi-paxos,都是可以进行多副本拷贝的,意味着进行多次basic-paxos实例。但仍需全局记录多次baxis-paxos的状态,以便于保证各个basic-paxos实例的一致性。在引用文章介绍multi-paxos例子中,采用的是数组进行记录其状态。
并不是所有Proposal都可以发起accept请求的,只有
当Acceptor接受accept请求时宕机再次重启时,向"最大"的Proposal发起同步请求。在multi-paxos例子中,是向Leader发送同步请求,导致Leader的压力过大,可以向其他Proposal发送同步请求。那么就需要每个节点记录各个节点的proposal-id的数据,可以统称元数据。这样子同步请求可以避免发给Leader。有效减少Leader压力。
有关更多细节讲解的paxos文章,可以仔细查阅我引用的文章。
六. 分布式系统
我们所说的分布式系统,主要是解决计算、存储数据量的问题。无论是计算还是存储,其归根于如何拆分数据,让其数据均匀的分布在各个节点上;
哈希方式 通过哈希算法将数据分布到不同的机器上
按数据范围分布 有点类似与报表系统对数据量大的表按时间维度分区
一致性哈希 结合哈希方式,采用环形的形式,将数据分布到各个节点上;其中提出了虚拟节点的方法,有效的避免数据不均匀的问题。
同时分布式系统也需要高可用,所以需要多副本,从而避免服务宕机,其他副本服务依然提供服务;至于如何保证副本一致性,可以看上面的讲解。
七. 总结
分布式事务,我们主要是采用TCC协议,保证事务的一致性;当个别场景可以采用第三方组件,从而减少服务的压力;