微服务可观测平台-总体设计
1. 背景
服务可观测性,预测与发现系统性能瓶颈,透视系统状态,为系统调优和查故障提供可靠数据支撑
2. 参考和关键词
Metrics
Metrics 计算 Events 发生数量的数据集,这些数据通常具有原子性,且可以聚合。从操作系统到应用程序,任何事物都会产生 Metrics 数据,这些数据可以用来度量操作系统或应用程序是否健康,或者是用以计算一段时间内请求的平均延时。
Logging
记录离散 Events,Logging 描述的是一些列离散事件,在缺乏有力的监控系统时,Logging 数据通常是工程师在定位生产问题时最直接的手段。如果说 Metrics 可以告诉你系统或者应用程序出现问题,那么 Logging 就可以告诉你为什么会出现问题。关于日志的采集现在也有很多方法,比如:filebeat, fluented, loki 等。
Tracing
· 记录应用程序操作的数据
· 一次请求的完整生命周期
· 分布式系统中一次请求经历过多个服务产生操作的数据(Spans)
Tracing 是通过有向无环图的方式记录在分布式系统中发生的 Events 之间的因果关系。云原生场景下,多个服务之间或多或少存在着依赖关系,一次 Tracing 通常会经过多个服务(Span),甚至在高度复杂的分布式系统中,一次 Tracing 包含数以万计的 Span 也是可能存在的。再者,Tracing 更多的是关注这种端到端系统之间的联系,基于该需求,分布式追踪系统应运而生。
3. 特性
Ø
Ø
Ø
Ø
Ø
*日志收集ELK不在本次计划
*系统监控,如cpu,线程数(jvm),内存(jvm),磁盘io,网络io 直接使用Prometheus,不在本平台范围
4. 技术架构
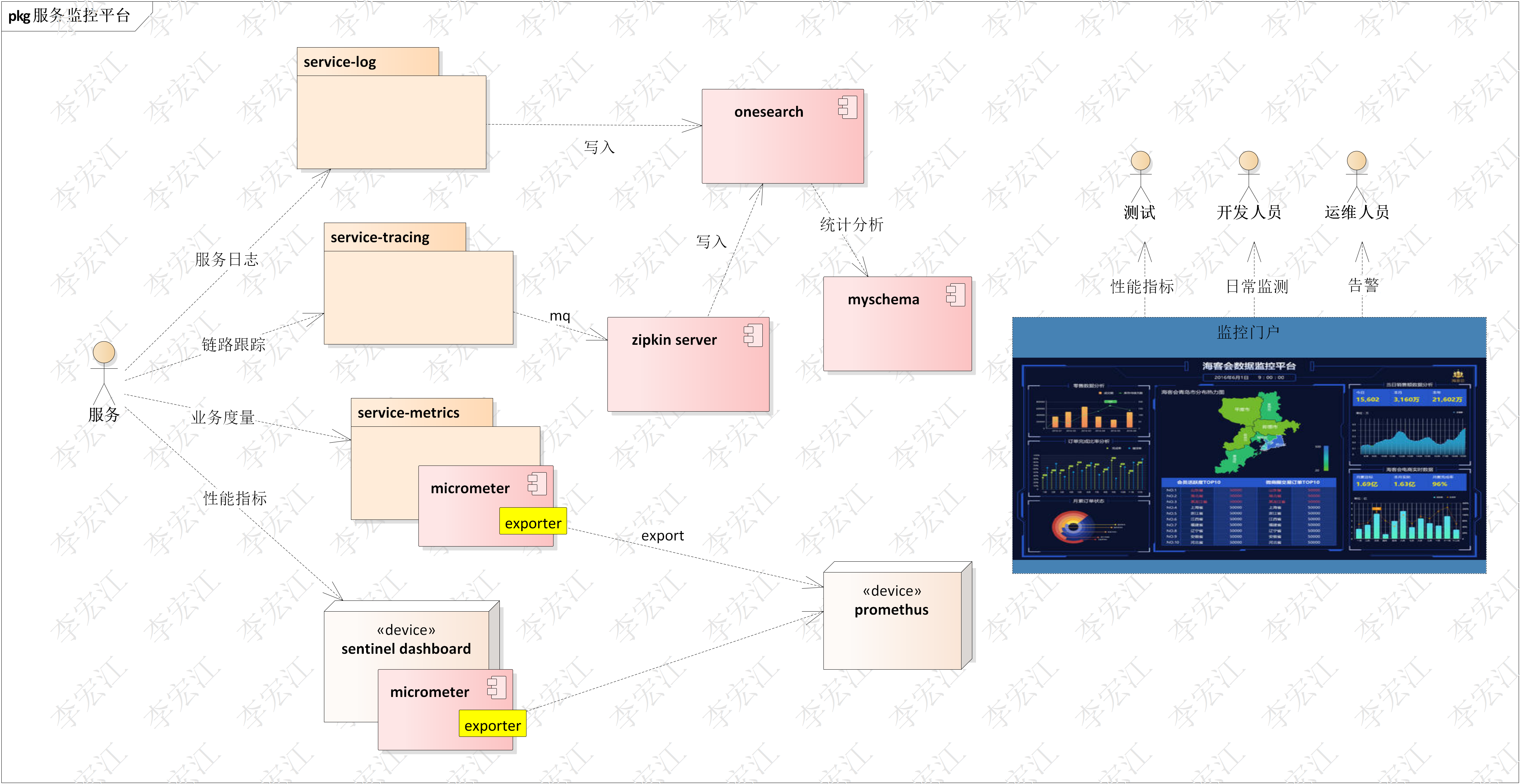
可观测包括4个维度数据 ,
Ø service-log 服务日志,用于服务审计,可加上tracingId关联调用链,存于elasticsearch
Ø service-tracing 服务调用链跟踪,存于elasticsearch
Ø service-metrics 业务度量,直接到Prometheus
Ø performance-metrics 性能指标,存于elasticsearch,转发到Prometheus
Ø 监控门户,通过统一的数据可视化,告警可视化门户,支持用户自定义视图
服务日志设计
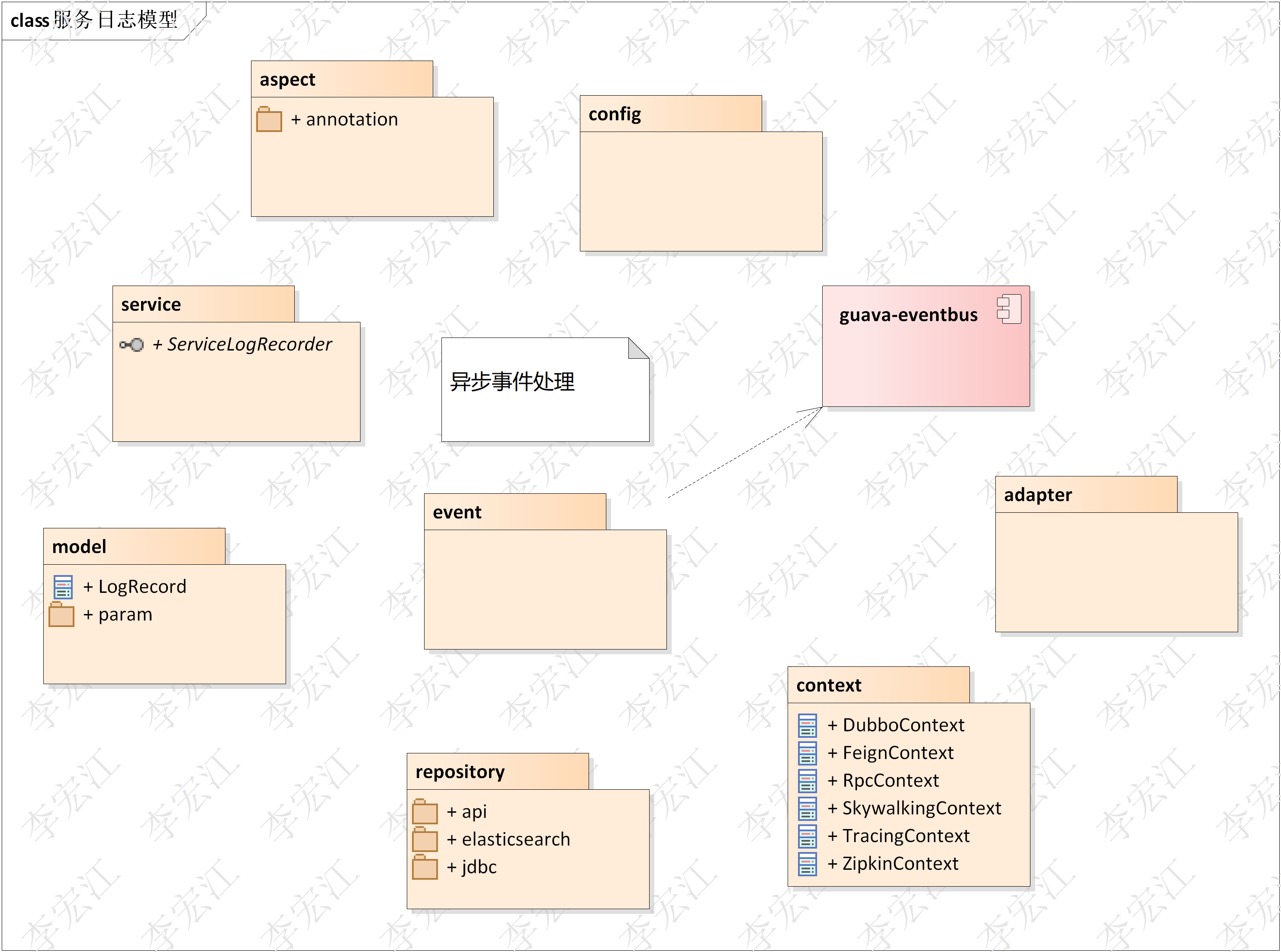
Ø aspect/annotation 切面/注解,拦截服务,实现日志功能,支持自定义标签
Ø service 日志逻辑,由切面发起调用
Ø model log模型
Ø model .param包解释/抓取参数
Ø event 日志打印以事件异步处理,依赖guava的event bus包
Ø repository 日志存储,支持jdbc(用于测试),elasticsearch(生产),可扩展
Ø config spring boot自动配置
Ø context 上下文,rpc上下文feign/dubbo/…,识别上级调用是否为网关,我们假设,网关后的服务是业务服务;链路上下文 zipkin/skywalking,
Ø adapter 适配接口,获取系统用户信息,集成服务提供实现
Ø 集成链路跟踪,tracingId;支持开关
Ø 数据变更跟踪,依赖集成链路跟踪,数据库增加tracingId,canal捕获数据变更,最后定时任务关联服务日志和数据便跟,只关联链路第一个服务;支持开关
服务链路跟踪
引入open zipkin
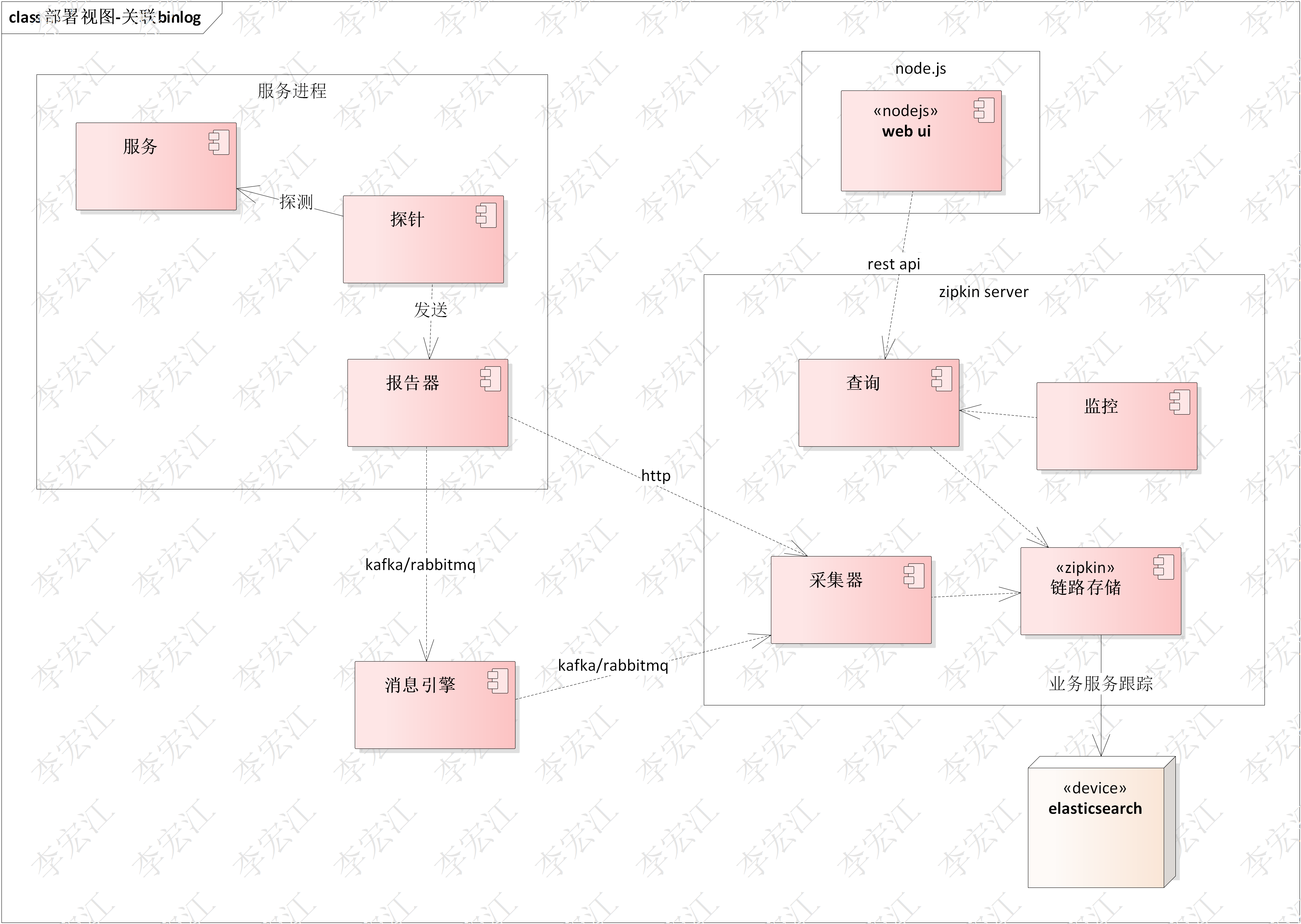
探针/报告器 低侵入,拦截器方式集成到服务,采集数据,支持自定义tag
采集器 与报告器对接,接收采集数据(span),生产环境用mq
存储 支持多种存储,elasticsearch其中一种
web ui zipkin server自带ui,查询跟踪,拓扑,功能比较简陋,直接搜索elasticsearch,做自定义分析
监控门户(TBD)
监控门户支持用户自定义视图,数据包括:
服务日志,存于elasticsearch
链路span, 存于elasticsearch
业务度量,存于promethus
性能指标,存于promethus
监控门户统一数据/告警视图,为用户,包括开发人员,测试人员,运维人员,公司运营提供系统观测数据,支持大屏实时滚动显示订单,交易,支付等统计
Ø 手动主题开发
Ø 可视化数据
引入数据可视化组件,拖拽式构建
业务metrics
引入micrometer
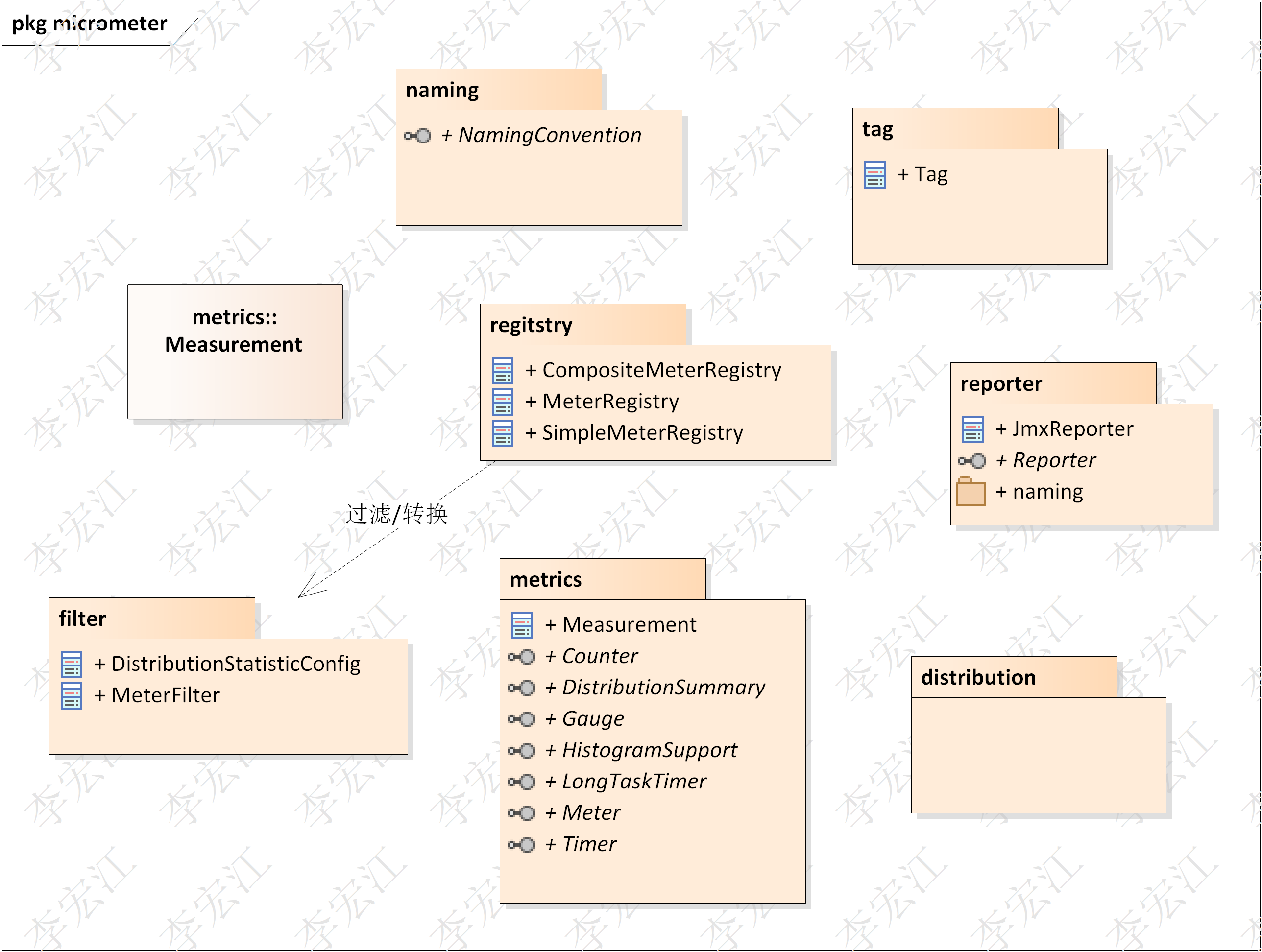
micrometer框架,提供metrics模型,包括metrics类型,counter,gaugegr,timer,等,实现了多种指标输出器,输出多种监控平台,Prometheus在支持列表中
性能metrics
改造sentinel dashboard
sentinel 熔断限流框架, 熔断限流过程产生秒级服务性能指标数据,包括响应事件,通过qps,拦截qps,异常比例等作为熔断决策依据,dashboard使用transport采集性能指标;但开源版本的dashboard单机不能用于生产,指标存于内存,需要改造:
Ø 引入zookeeper作为注册中心,sentinel实例注册,系统按注册实例动态生成拉取任务
Ø 性能指标拉取使用master-worker模式,分布式拉取,支持动态增减拉取worker
Ø 指标持久,使用elasticsearch
Ø 引入micrometer,指标转发送到Prometheus