ZGC在合合信息HBase平台中的实践
1.背景
HBase是一个基于HDFS的低成本、分布式LSM结构数据库,可以支持毫秒级别的查询;支持海量的PB级别的大数据存储,适用于高QPS的随机读写和前缀范围查询等场景,此外,HBase作为Apache老牌顶级开源项目,其优秀的开源环境使得HBase还可以支持丰富的上下游生态与离线任务。
目前在内部,HBase支撑着扫描全能王、名片全能王、启信宝等多条业务线,数据规模合计达到 PB 级别,单表规模达到百亿级别,日吞吐量达到亿级,同时业务方对HBase集群的读写延时有着很高的要求。因此,我们一直在做针对HBase的各种专项优化,而GC优化更是其中的重中之重。
为了满足不同业务场景下的需要,Java的GC算法也在不断更迭,对于特定的场景,选择合适的GC算法,才能更优地达到业务的目标。很多低延迟、高可用的Java服务的系统可用性经常受GC停顿的困扰。就拿HBase来说,如果RegionServer的GC停顿时间过长且频繁,RS的GC毛刺,就会导致大量的请求被延迟处理,从而出现读写毛刺,对业务方的服务SLA影响甚大,且严重影响用户的体验,GC停顿发生时,用户线程停止,这是不可避免的现象,因此,我们对HBase GC上优化的目的就是降低GC停顿时间,磨平这些GC毛刺,消除STW对HBase的响应请求的不良影响。
2.拥抱GC算法
纵观Java的发展史,有诸多大事件,从早期的Serial GC、Parallel GC、到低停顿、并发收集为代表的CMS和G1 GC,再到如今行走在Java最前沿的ZGC,GC算法的优化脚步从未停止,其优良的特性亦持续攀升,具体表现在主要两个方面:能管理的堆内存越来越大,垃圾收集所需要的停顿时间被压缩的越来越低。
Serial GC和Parallel GC的特点,针对HBase的场景不太适合,在此不赘述。CMS作为Hostpot JVM首款以低停顿为目标的GC算法,其并发收集、低停顿的优点,也一度被我们选做HBase的GC算法,但其缺点也同样明显,尤其是CMS基于“并发-清除”算法实现,垃圾收集结束时会有大量空间碎片产生,空间碎片太多的时候,将会给大对象的分配带来很大麻烦,虽然老年大还有空间剩余,但无法找到连续的空间来分配当前大对象,就不得不提前触发full gc。
而且,CMS GC涉及的调优参数众多,调优难度过大,且收效甚微。因此,比CMS GC性能及效果更优的G1 GC便进入了我们的视线,使用G1之后,在很长一段时间内,HBase的读写延迟都可以满足我们业务方的要求。
G1是一款面向服务端引用的垃圾收集器,能充分利用多CPU环境下的硬件优势,以并发的方式让GC线程与用户线程同时工作,来缩短STW时间;与CMS的“标记--清理”算法不同,G1基于Region为单位来划分内存,从整体来看是基于“标记——清理”算法来实现的收集器,从局部来看,Region之间是基于“复制”算法实现,可以有效避免内存碎片的现象发生。G1与CMS一样都期望降低GC停顿时间,但是G1除了追求这个目标之外,还能建立可预测的停顿时间模型,让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒。且从经验上来说,在小内存应用上CMS的表现大概率优先与G1,而G1在大内存的应用上则可以发挥其优势,平衡点在6-8GB之间。
虽然G1在我们HBase应用中的GC表现性能与CMS相比确实有一定的提升,但仍不具有压倒性的优势,在之后我们的使用和测试过程中也能证明,G1 GC仍然会来了大概100~200ms的平均GC耗时,在更高敏的业务场景中,GC毛刺的出现,仍会影响着我们的HBase集群表现出更优的读写请求响应。
因此,对GC的优化也在我们的团队中,占据着很高的优先级,那么,还有什么样的GC算法可以带来更低的STW,但同时又可以兼顾吞吐量呢?这就不得不引出我们今天的主角——ZGC。
3.来自未来的技术——ZGC
ZGC(The Z Garbage Collector)是JDK 11中推出的一款低延迟垃圾回收器,它的设计目标包括:
停顿时间不超过10ms(在最新的JDK16、JDK17中,这个停顿时间可以控制在1ms内)
停顿时间不会随着堆的大小而增加
支持8MB~4TB级别的堆(未来支持16TB)
由设计目标可知,ZGC 主要是为现在及未来大堆的管理问题服务,致力于以最小的性能损失换取最大的停顿优势。从 Oracle 发布的测试数据来看,SPECjbb2015基准测试,使用128G堆,暂停时间ZGC远低于Parallel GC 和 G1GC,如下图所示。
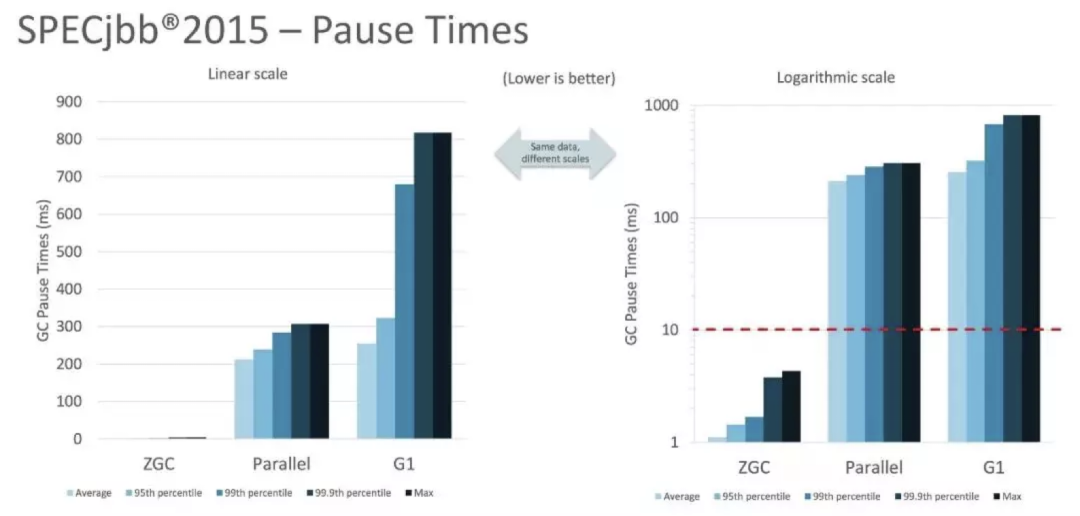
与CMS中的ParNew和G1类似,ZGC也采用“标记——复制”算法,不过ZGC在这里做了重大改进,ZGC在标记、转移和重定位阶段几乎都是并发的,这是ZGC实现停顿时间小于10ms的最关键原因。因此,ZGC几乎所有地方都是并发执行的,停顿时间几乎就耗时在初始标记上。
除并发的特性之外,ZGC的关键技术还有Colored Pointers(着色指针)、Load Barrier(读屏障)等,这都是支撑ZGC目标的关键技术,其详细原理在此不展开叙述,可以参考ZGC的官方文档。
4.ZGC在合合HBase中的应用
我们生产环境中使用的HBase版本是,针对这个版本,HBase社区与Cloudera官方都未曾提供更高版本JDK所编译出的安装包,因此,若想体验ZGC,我们不得不自己去选择JDK和对HBase源码进行编译和部署。
最终,我们选择的JDK是AdoptOpenJDK15,JDK15版本中的ZGC在正式生产环境中已经可用。
AdoptOpenJDK 是社区(伦敦JUG)维护版的OpenJDK,提供预构建的二进制文件,主要维护LTS及最新版本;和OpenJDK一样,AdoptOpenJDK 也支持 GPL 协议且免费,不同的是OpenJDK只会由Oracle提供6个月的安全更新,而AdoptOpenJDK则由社区提供至少4年的免费长期支持(LTS)。但目前随着Oracle JDK17的免费,使用此版本也是一个不错的选择。
如果是HBase1.x,用JDK15来编译HBase还颇费周折,需要解决不少编译时的问题,主要是部分jar包的升级、部分类API的替换或升级,maven插件的版本升级,运行时--add-exports等参数的添加等等。具体编译过程可以参考官方的HBASE-22972,或合合大数据基础架构组的伙伴为社区贡献的ZGC相关的文章:
如果是HBase2.x,用JDK15来编译HBase难度较低,可以参考文章:
有关ZGC在HBase集群中性能表现的详细情况可以参考文章:
5.ZGC在合合HBase中的表现
ZGC的一个设计目标是大幅度降低GC的停顿时间,如果能达成这个目的甚至消除GC STW对HBase读写延迟的影响,那么HBase的请求响应也会进一步获得提升。
在此设想上,我们对应用了G1和ZGC的HBase集群,分别进行了YCSB压测,并尽可能保证两边测试的物理环境、软件环境以及测试数据特征是一致的,然后分别在不同的读写场景下多次运行YCSB测试命令,然后收集GC日志和压测指标数据,获取其平均值,最终得出的几组对比数据如下:
5.1 G1和ZGC的GC表现性能对比
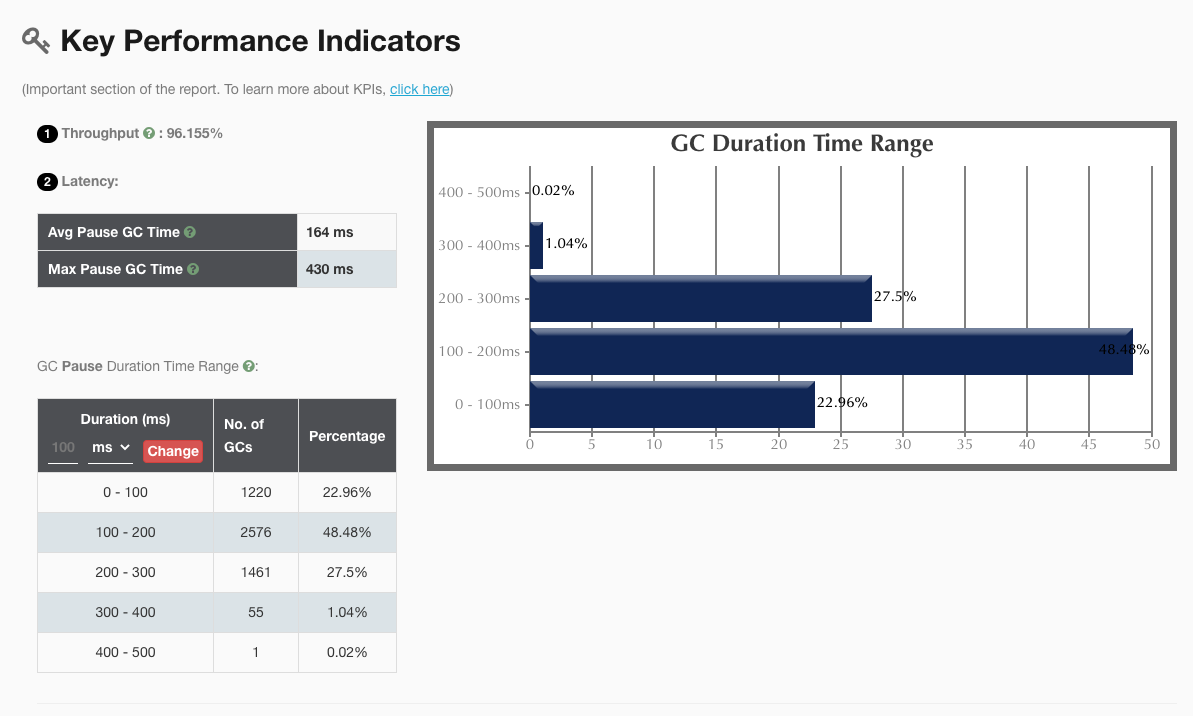
我们收集 ZGC 与 G1 GC 在相同压测场景下生成的详细 gc 日志,上传到之后,分别得出的GC报告如下图所示:
G1
ZGC
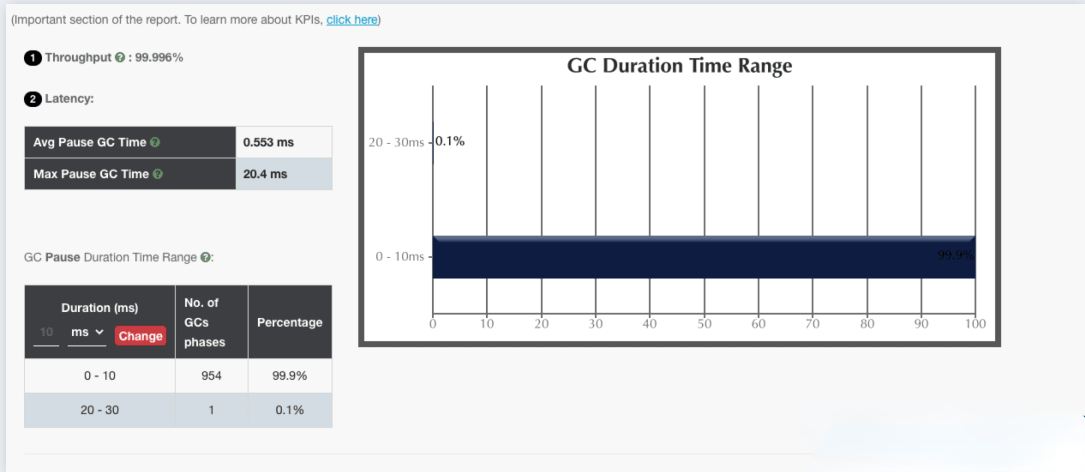
仅从这两个 GC 报告对比来看,ZGC 确实做到了几乎百分之百的 GC 时间在 10ms 内。
5.2 G1和ZGC对HBase吞吐量指标的影响
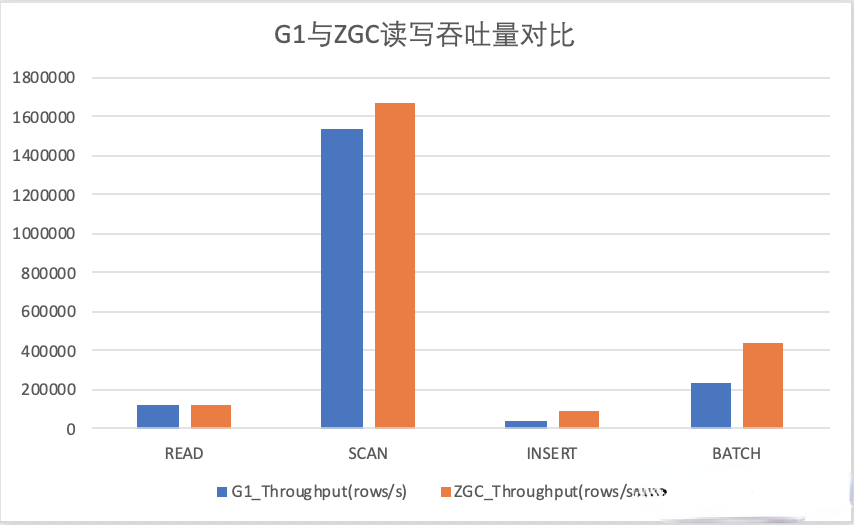
虽然理论上,吞吐量在ZGC的表现中会有降低,但实际测试下来的现象是,在某些读写场景下,ZGC的吞吐量表现更优。
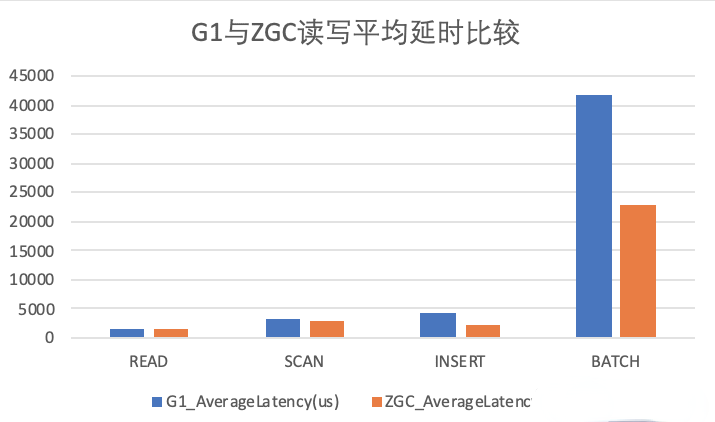
5.3 G1和ZGC对HBase读写平均延迟指标的影响
平均延时
P999
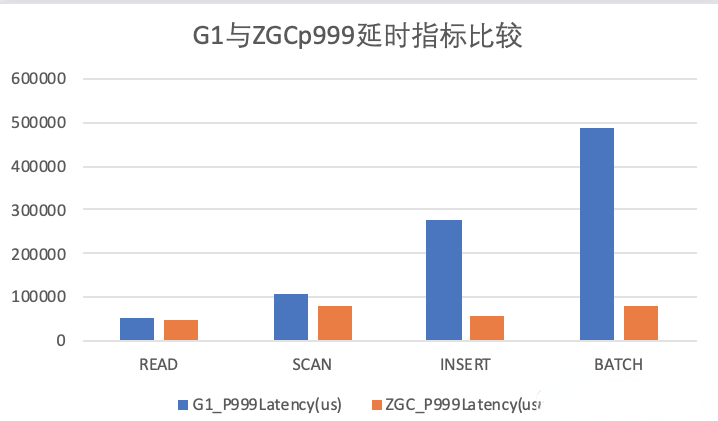
如上图,ZGC在不同的读写场景下,读写延时方面也会由于G1的表现。
以上指标对比,在不同的压测场景,不同的集群环境之下的结果可能会有所不同,不能代表线上真正的表现情况,仅做参考,大家如感兴趣,可以自己尝试一波。
6. 总结
本篇文章为大家分享了在GC层面,我们对合合HBase集群读写性能的优化,尤其是利用ZGC低延迟的优点,消除了GC毛刺对HBase读写延迟的影响,为满足业务方的服务SLA,起到了比较关键的作用。
并在相同的 YCSB 压测场景下,分别测试了 G1 和 ZGC 在真实的应用环境中的 GC 的表现能力,并得出 GC日志的分析报告,从 GC 停顿时间和读写吞吐、延迟等方面,也做了比较详细的对比。
7. 参考文章
滴滴HBase ZGC启明灯式的文章给我们带来了很大的灵感
同时58同城HBase的ZGC应用实践,也一样很有参考价值
作者介绍:
介龙平,大数据基础架构组平台开发工程师。负责大数据平台和基础架构工作。在合合信息期间主导了HBase,Hadoop生态等组件的性能优化,以及一站式大数据平台的设计和开发工作。