创业公司技术体系建设-APM
APM被形象的称为应用医生,做为前文的后续,本文将详细介绍一下公司APM架构的演进过程。
一、1.0版架构
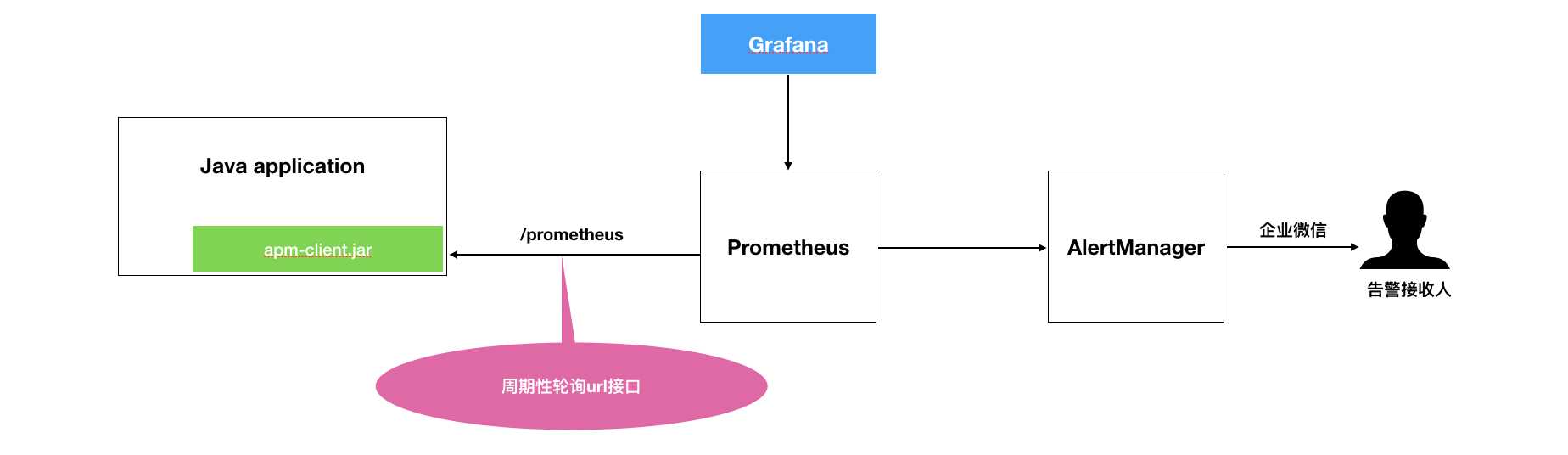
1.0版的架构中,主要通过应用改造集成一个jar包完成metrics采集,通过prometheus收集后,根据预设告警规则发送告警通知。整体的特点是:
二、2.0版架构
为了能够实现trace收集、运行时修改告警规则、尽可能无侵入,先后调研了PinPoint、Skywalking、Elastic Apm等几个通过Agent方式进行应用监控的Apm工具。
Pinpoint部署过于复杂,需要Hbase环境,首先被排除。Skywalking不能运行时修改告警配置也被排除在外(6.5.0之后可以)。Elastic Apm经过调研后也无法满足我们的要求。除此之外,Trace类的APM工具一般都根据Http状态码判断请求成功还是错误,但公司很多遗留的项目中确存在这样一种问题,接口内部已经出现错误,但确仍然返回http status code 200,在返回值中自定义了其他错误码,这样的写法导致了Trace类的APM工具无法判断接口返回是否正常。
public class Sample {
AppResponse getInfo() {
AppResponse ret = new AppResponse();
try {
// ...
// ret.setData()
ret.setCode(0);
}catch(Exception ex) {
ret.setCode(-1);
ret.setMsg(ex.getMessage());
}
return ret;
}
}综合来看,无论哪个APM工具都不能满足我们的需求,需要定制开发,最初希望通过修改Skywalking来实现我们的需求,但很遗憾按照官方文档没有编译成功,最终我们通过修改Elastic Apm来完成公司的APM开发。2.0版的整体架构如下:
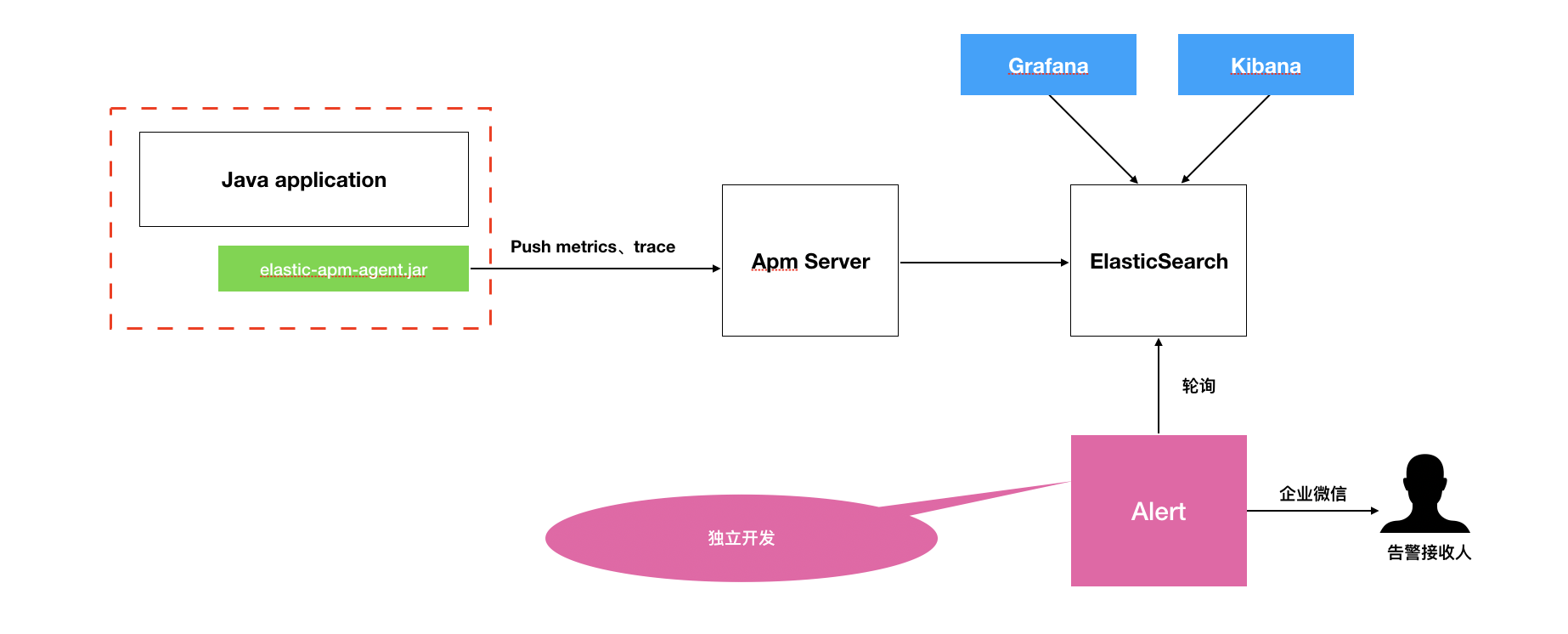
上文提到要解决运行时修改告警配置、判断接口返回是否成功这两个问题,对于运行时修改告警配置,我们开发了一个独立的Alert告警系统,并参考PromQL使用Antlr实现了语法解析器,周期性查询ElasticSearch来判断是否有异常发生。比如:
avg(dubbo{appname="qdp-polaris-server"} by interface range 5m) > 2000
计算5分钟内qdp-polaris-server系统各个dubbo接口的平均响应时间,如果超过2000ms则产生报警。 相当于SQL
select avg(响应时间) from table where timestamp between now() - 5m and now() group by dubbo
avg(http{appname=“qdp-polaris-server”, url ~= “.
计算5分钟内qdp-polaris-server系统http接口名称匹配正则表达式.
avg(jvm.memory{appname="kafka-connect-platform-web"} by ip range 5m) > 1024
计算5分钟内kafka-connect-platform-web系统各实例jvm堆内存利用率,如果超过1024MB则产生报警。 相当于SQL
select avg(heap memory) from table where timestamp between now() - 5m and now() group by ip
对于判断接口返回是否成功这个问题,我们采用变通性办法解决,在程序中使用AOP拦截接口调用,通过自定义指标来记录接口返回是否成功,不在通过http status code进行判断。比如通过在程序中记录ERROR或者其他关键字来实现。
count(event{appname="qdp-skyline-web", keyword ~=".
计算5分钟内qdp-skyline-web系统LOG日志中匹配.
select count(1) from table where timestamp between now() - 5m and now() and message ~= “.
基于Agent方式的APM有一个比较明显的缺点,只能根据用户的请求情况来判断系统是否正常,不能先于用户发现问题。为了解决这个问题,最初我们想使用Elastic HeartBeats进行接口主动探测来触发APM告警,后来在QA同学的建议下,我们用HttpRunner编写用例主动进行探活,用例开发的工作由QA同学来做。
三、总结
目前我们的APM工具仍然在进化开发过程中,告警量太多导致漏掉重要的告警信息也是一个要考虑的问题,目前我们采用类似AlertManager的方法过滤重复告警。
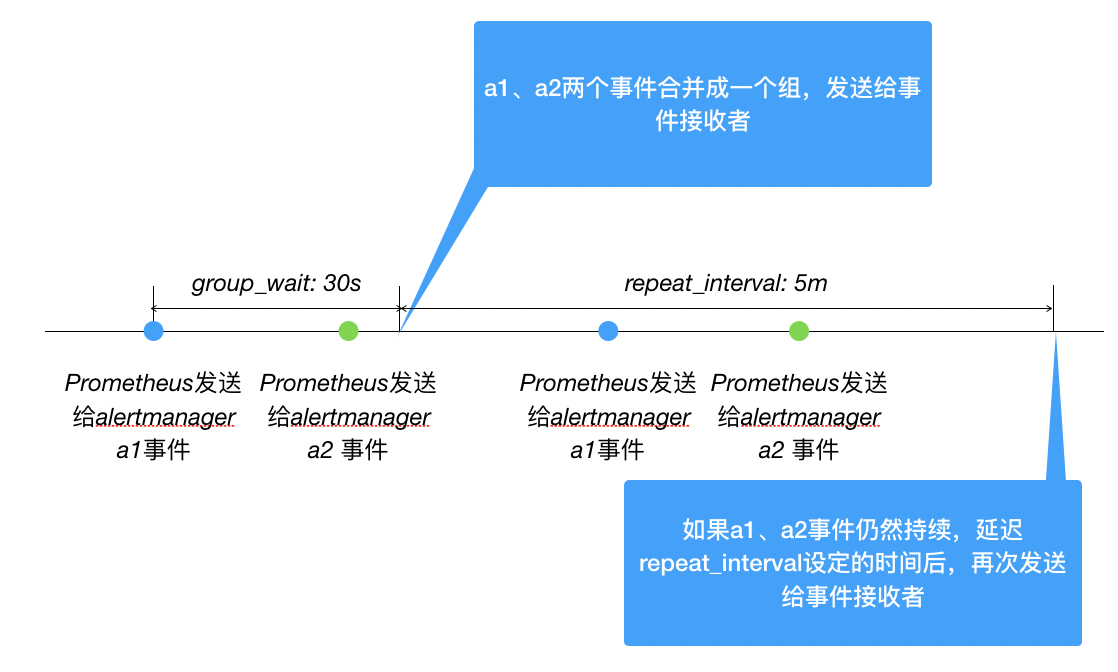
后续希望通过AI算法合并告警消息降低告警数量,以及引入CEP对告警事件做关联分析处理。