NIO 看破也说破(五): 搞,今天就搞,搞懂Buffer
前言
Java NIO 中的三件法宝: 、 和 。前面几节中,我们花了很大篇幅讲过 ,咱们今天只搞 。希望能通过本文搞明白 的基本用法和原理。
掌握重点:
基本操作
上一篇我们模拟 client 发送请求的时候代码如下:
InputStream inputStream = socket.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream));
System.out.printf("接到服务端响应:%s,处理了%d\r\n", br.readLine(), (System.currentTimeMillis() - start));
br.close();
inputStream.close();在普通 BIO 模式下,我们只能自己维护一个 byte 数组或者是 char 数组来进行批量读写,或者使用 和 来做读写缓冲区。
buffer.clear();
buffer.put(("收到,你发来的是:" + sb + "\r\n").getBytes("utf-8"));
buffer.flip();Java NIO Buffer 用于和 NIO Channel 交互,我们从 中读取数据到 里,从 把数据写入到 。本质上,
把数据写入 ;
调用 flip();
从 中读取数据;
调用 clear() 或者 compact()
当写入数据到 中时, 会记录已经写入的数据大小。当需要读数据时,通过 flip() 方法把 从写模式调整为读模式;在读模式下,可以读取所有已经写入的数据。
Buffer实现
缓存区,内部使用字节数组存储数据,并维护几个特殊变量,实现数据的反复利用。在 java.nio.Buffer 中定义了4个成员变量:
核心点:对于 Buffer 的操作,就是在不停的变换 position 和 limit 指针的位置,达到定位读取位置和终止位置的目的,从而可以准确的在边界内读取数据。
代码实现:
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
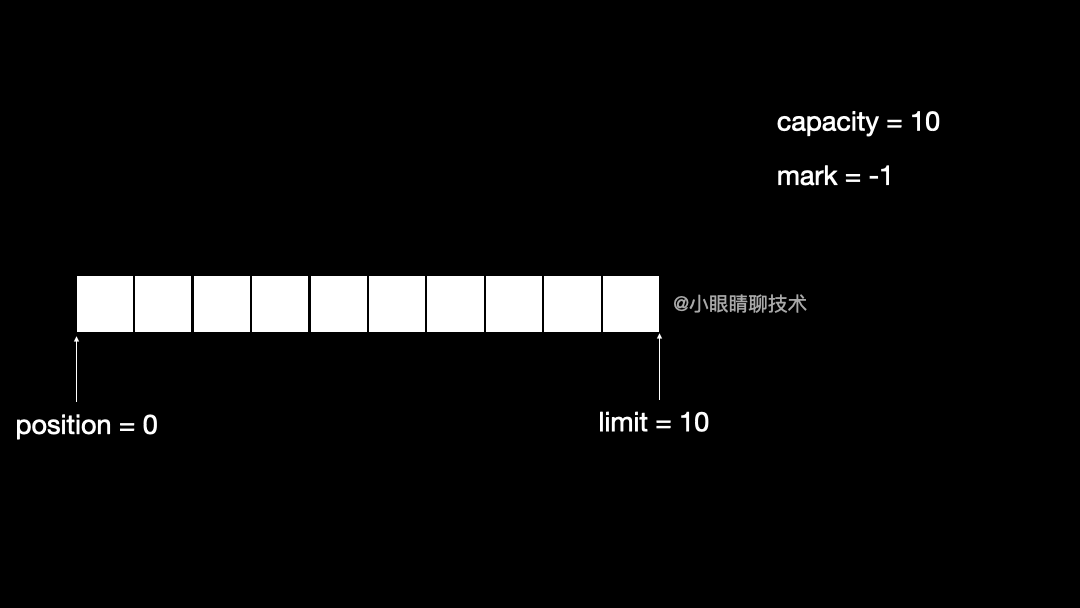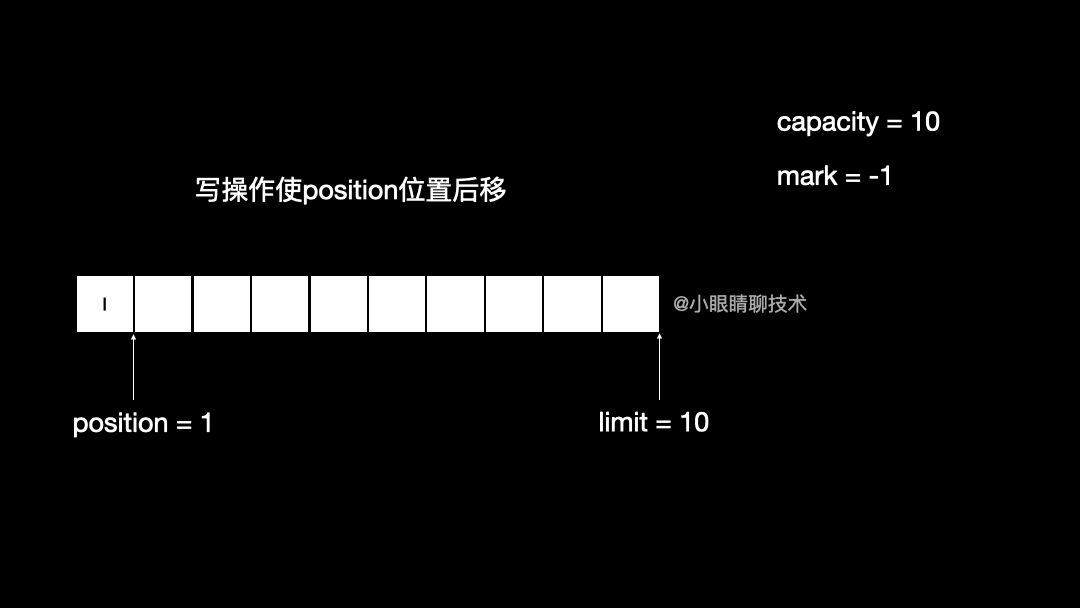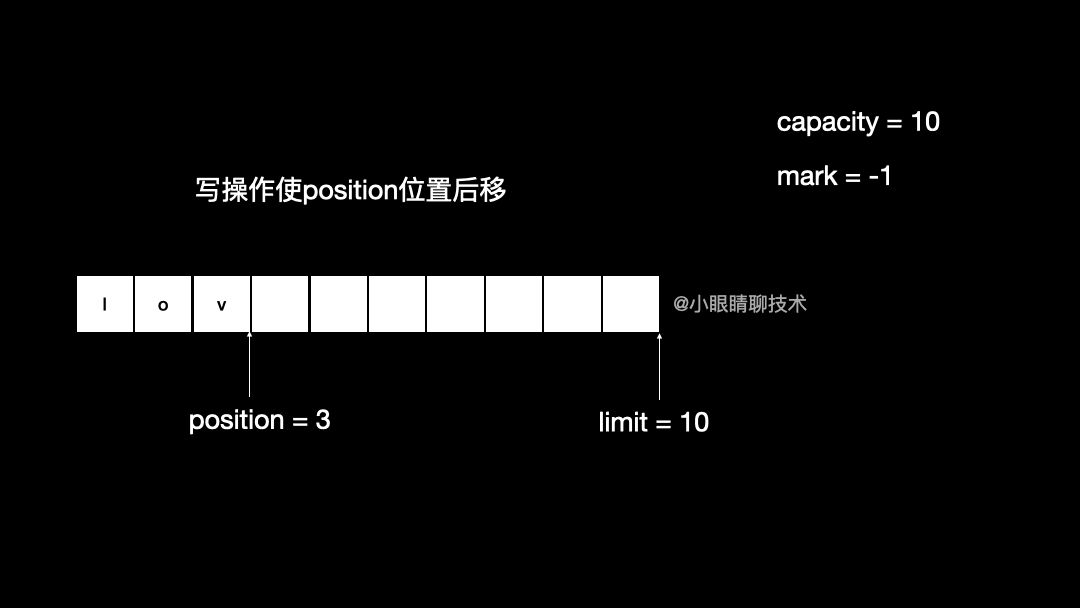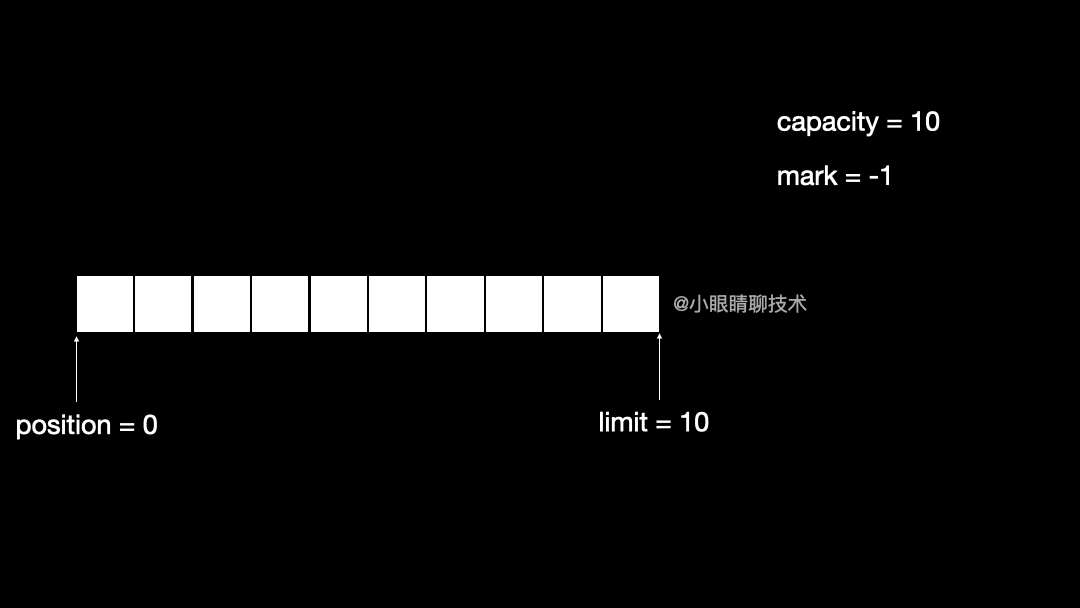
private int capacity;以字节缓冲区为例, 是一个抽象类,不能直接通过 new 语句来创建,只能通过一个 static 方法 allocate 来创建:
ByteBuffer byteBuffer = ByteBuffer.allocate(10);调用上述语句,相当于创建一个大小为 10 个字节的 ,此时 mark = -1, position = 0, limit = 10, capacity = 10
我们看一下 的常见方法,内部是如何实现的:
put
put 方法是把一个 byte 变量 x 放到缓冲区中,同时 position 会加 1
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
final int nextPutIndex() { // package-private
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
一起看一下不停 put 数据时,几个变量的变化:
ByteBuffer byteBuffer = ByteBuffer.allocate(10);
byteBuffer.put((byte) 'l');
byteBuffer.put((byte) 'o');
byteBuffer.put((byte) 'v');
byteBuffer.put((byte) 'e');
System.out.println(byteBuffer.limit()); // 结果10
System.out.println(byteBuffer.position());// 结果4
System.out.println(byteBuffer.capacity());// 结果10
byteBuffer.put((byte) ' ');
byteBuffer.put((byte) 'x');
byteBuffer.put((byte) 'y');
byteBuffer.put((byte) 'j');
System.out.println(byteBuffer.limit());// 结果10
System.out.println(byteBuffer.position());// 结果8
System.out.println(byteBuffer.capacity());// 结果10get
get 方法,是从 position 的位置去取缓冲区中的一个字节
public byte get() {
return hb[ix(nextGetIndex())];
}
final int nextGetIndex() { // package-private
if (position >= limit)
throw new BufferUnderflowException();
return position++;
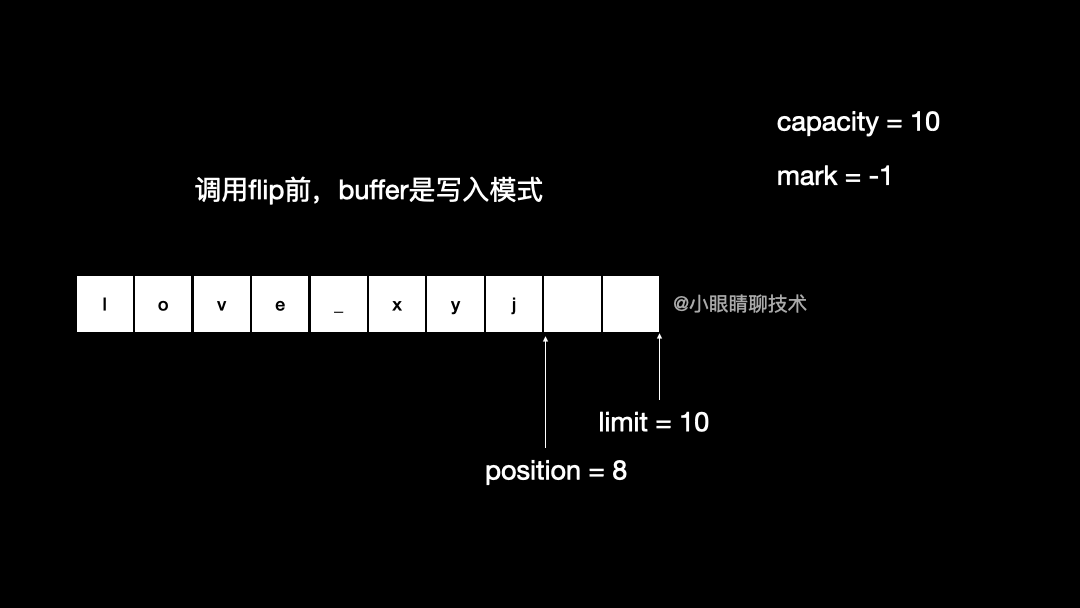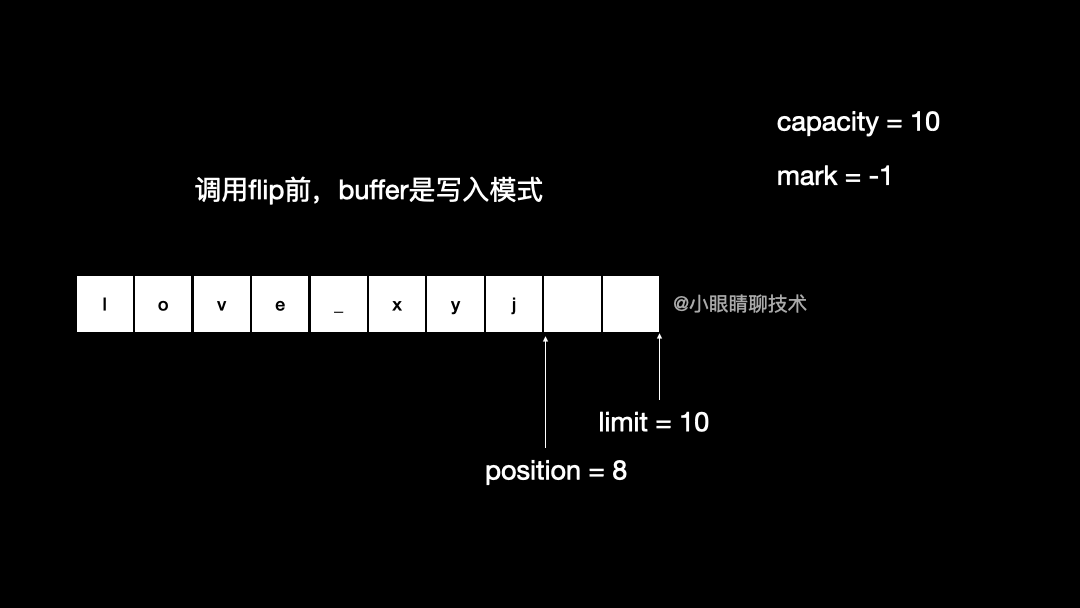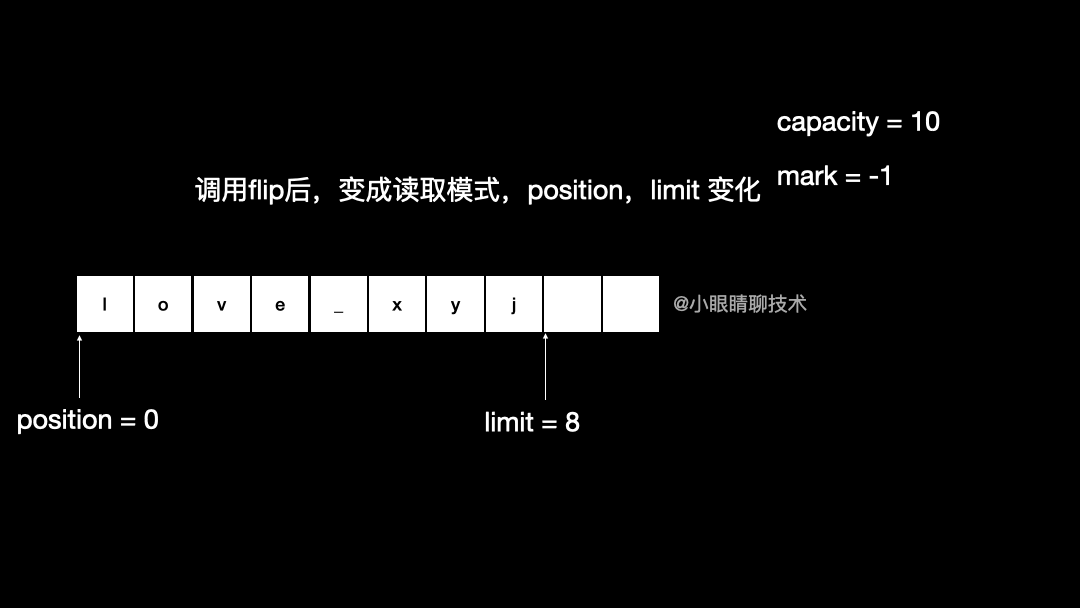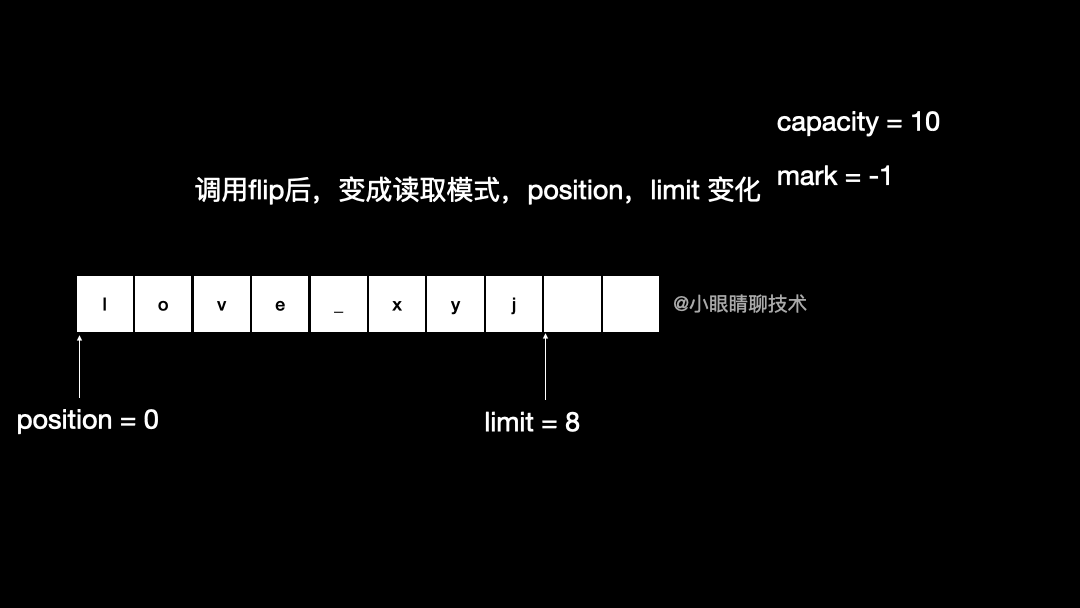
}flip
如果想在一个 中放入了数据,然后想从中读取的话,就要把 position 调到我想读的那个位置才行,同时需要调整 limit。
byteBuffer.limit(byteBuffer.position())
byteBuffer.position(0);
Java 中把这两步操作,封装在一个 flip 方法中:
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
mark
mark 就很容易理解了,它就是记住当前的位置用的
public final Buffer mark() {
mark = position;
return this;
}在调用过 mark 以后,再进行缓冲区的读写操作,position 就会发生变化,为了再回到当初的位置,我们可以调用 reset 方法恢复position 的值:
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}clear
把 中特殊的4个变量初始为原始值
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}回顾一下核心点:对于 Buffer 的操作,就是在不停的变换 position 和 limit 指针的位置,达到定位读取位置和终止位置的目的,从而可以准确的在边界内读取数据。
Direct Buffer
在创建 是我们是采用的静态方法直接 allocate 得到一个 buffer 对象:
ByteBuffer buf = ByteBuffer.allocate(1024);在 JVM 中,创建的对象是放入在堆中。比如,当我们 时,会在堆内存上分配一块内存空间给 ,在栈空间上持有引用 保存 的内存地址 。JVM 做垃圾回收,会把堆中的对象,在不同的分区中来回拷贝。内存地址会频繁发生变化,本身 会频繁读写,这样会导致内存整理繁琐。有没有办法脱离JVM对象管理呢?在创建 的静态方法中还有一个方法:
ByteBuffer buf = ByteBuffer.allocateDirect(1024);我们来比对一下方法的实现:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}调用 allocate() 创建了一个 ,调用 allocateDirect() 创建的是 。看名字很直观的表达,一个是「堆」内存,一个是「直接」内存。
看一下 的实现:
// Primary constructor
//
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}这里最重要的就是使用了 unsafe.allocateMemory 来分配内存,而 allocateMemory 是一个 native 方法,会调用 malloc 方法在 JVM 外分配一块内存空间。
总之,这里在 Java 堆外申请了一块内存,并把这个内存的地址记录下来。以后要是再使用这个的话,就会直接访问从address开始的那一段内存。
一个直观的优点是不被 GC 管理,所以发生 GC 的时候,整理内存的压力就会小。当然,它并不是完全不被 GC 管理还是能被回收的,但是在 GC 平常整理内存的时候确实是不会去管它。
类结构
我们只是以常见的 为例,在 NIO 中还提供了各种类型的Buffer ,这里就不再赘述。

结论
今天就搞到的这里,划的重点需要牢记, 的操作不注意顺序会出现各种问题。
系列
关注我
如果您在微信阅读,请您点击链接 ,如果您在 PC 上阅读请扫码关注我,欢迎与我交流随时指出错误
