打造“云边一体化”,时序时空数据库TSDB技术原理深度揭秘
随着用户对时序数据存放成本的要求进一步提高,时序数据存储就成为了时序数据库的必修课之一,当前时序数据库采用Delta-delta, Simple-8b , XOR-base 等压缩算法,实现了释放90%的存储空间。
所有计算都基于一个简单的原理:所有的信息都是用二进制表示的。虽然存储资源的价格越来越廉价,但是计算资源毕竟不是免费的。我们如果可能更加有效的存储这些信息, 我们就可以用在存储、计算和带宽上面节省更多的资源, 即压缩的定义:
近几十年来, 压缩算法始终在计算机领域扮演重要的角色。而压缩这个概念本身则更为古老, “1838年发明的摩尔斯密码是最早的应用压缩算法实现,对于英语中最为普遍的字母‘t’和‘e’使用较短的摩尔斯密码”。
在本文中, 我们将揭开压缩算法的面纱,向大家介绍几种用于时序数据的算法,以及如何把他们应用项目之中。我们将解释如何把这些算法应用到时序数据库中从而节省了90%以上的存储空间。
1,压缩算法对于时序数据的重要性
时序数据来源多种多样,无论是在 IT系统监控、网络数据分析还是在产品/用户行为分析以及税务系统中, 时序数据都贯穿整个数据线, 对于更好实时了解系统和应用很有帮助。
对于时序数据来说, 存储的覆盖范围始终是一个很重要的挑战。 为了能够更好的分析这些数据的变化, 我们每次获得新的数据之后,并不会更新数据本身, 而是把这些作为新数据插入进数据库。 有些时序系统在新数据写入方面负载很大(如IT系统的监控,物联网传感器数据等), 其时序数据本身都达到了TB级别。
为了能够高效且高速的处理这些数据, 我们选择了目前最为高效的时序压缩算法,并且把他们应用到时序数据库中。根据之前的测试, 时序数据库最终可以达到90%以上无损压缩。 这同时也意味着减少了存储方面的大笔开销。 而且压缩算法还可以提高性能: 数据本身占用的空间少意味着查询时需要请求硬盘空间也少。
2,时序数据压缩算法
以下是按数据类型的时序数据压缩算法:
整型数据:
Delta encoding Delta-of-delta encoding Simple-8b Run-length encoding
浮点数据
XOR-based compression
未知数据
Dictionary compression (字典法)
3,整数压缩
Delta-encoding
Delta-encoding / Delta compression , 通过只存储数据库的差值以及一个或多参考值来节省存储空间。适用于大量冗余数据的情况, 比如版本化的文件系统. (各种网盘)
| time | cpu | mem_free_bytes | temperature | humidity |
|---------------------|-----|----------------|-------------|----------|
| 2020-04-01 10:00:00 | 82 | 1,073,741,824 | 80 | 25 |
| 2020-04-01 10:05:00 | 98 | 858,993,459 | 81 | 25 |
| 2020-04-01 10:05:00 | 98 | 858,904,583 | 81 | 25 |
通过 delta-encoding算法, 我们只需要把每条数据与之前相比的变化值存储即可, 这样使用的空间更小:
| time | cpu | mem_free_bytes | temperature | humidity |
|---------------------|-----|----------------|-------------|----------|
| 2020-04-01 10:00:00 | 82 | 1,073,741,824 | 80 | 25 |
| 5 seconds | 16 | -214,748,365 | 1 | 0 |
| 5 seconds | 0 | -88,876 | 0 | 0 |
这样, 除了第一行之外, 我们就能用更少信息来保存其他行。
使用 delta-encoding 来压缩时序数据库基于时序数据本身的一个特点, 即数据本身是随时缓慢变化的, 并不是完全随机的。对于上百万行的数据来说, 这种存储很有效。尤其是那些是几乎不怎么变化的数据。
Delta-of-delta encoding
对于上面的例子,我们可以得到
| time | cpu | mem_free_bytes | temperature | humidity |
|---------------------|-----|----------------|-------------|----------|
| 2020-04-01 10:00:00 | 82 | 1,073,741,824 | 80 | 25 |
| 5 seconds | 16 | -214,748,365 | 1 | 0 |
| 0 | 0 | -88,876 | 0 | 0 |
在这个例子中,
Simple-8b
通过
由此, 我们引入了simple-8b,这种最为简洁也最为小巧的方法来存储整数变量。
在simple 8b中, 一组整数会被存在一系列固定大小的数据块中。 每个数据块里, 每个整数都用固定字长来表示, 这个固定字长由数据块中最大的整数来表示。而每个数据块的第一位用来标记这个数据块字长。
使用这个技术可以让我们只需要在每个数据块中只记录一次字长, 而不是去记录每个整数的字长。 而且因为每个数据块的字长是一样的, 我们也可能推算出来数据块里中存储了多少个整数。
比如说, 我们存储了随时间变化的温度信息,通过上面提到的差值计算方式,最后得到了以下的一组数字:
| temperature (deltas) |
|----------------------|
| 1 |
| 10 |
| 11 |
| 13 |
| 9 |
| 100 |
| 22 |
| 11
横过来看,我们的数据是这样子的
1, 10, 11, 13, 9, 100, 22, 11
假设我们的数据块大小为10个字长, 那么我们可以用simple-8b 的方式存存储上面数据为两个数据块。 一个存5个2位数据, 另一个存3个3位数据。
{2: [01, 10, 11, 13, 09]} {3: [100, 022, 011]}
由上面可以看出, 两个数据块都存储了10位数据(第二个数据块实际上只用了9位), 虽然在有一些数据前补了0 来凑满位数。
Simple-8b 的实际运行方式就和我们这个例子很像, 唯一不同的地方在于simple-8b使用二进制而不是十进制, 而且通常使用64位的数据块。 通常来说, 数据本身越长, 每个数据块能存储数据也越少。
Run-length encoding (RLE)
虽然simple-8b可以很好地压缩数字, 并把每个数字都压缩到最小值。但是, 对于某些特定情况,仍然不够给力。
比如对于一些大数重复的情况来, 我们可以选择更好的方式。主要是应用于的数据重复度很低,或者在通过差值计算过程中, 后续数据没有变化的情况。
比如考虑前面的那个时间和湿度那个例子, 时间列重复5, 湿度列重复0。
| time | cpu | mem_free_bytes | temperature | humidity |
|---------------------|-----|----------------|-------------|----------|
| 2020-04-01 10:00:00 | 82 | 1,073,741,824 | 80 | 25 |
| 5 seconds | 16 | -214,748,365 | 1 | 0 |
| 5 seconds | 0 | -88,876 | 0 | 0 |
下面这个更为简化的例子可能更好的表示这些重复的数据。 我们仍然用存储那些随着时间变化的温度, 然后应用delta-encoding, 得到了下面一组数据。
| temperature (deltas) |
|----------------------|
| 11 |
| 12 |
| 12 |
| 12 |
| 12 |
| 12 |
| 12 |
| 1 |
| 12 |
| 12 |
| 12 |
| 12 |
即
11, 12, 12, 12, 12, 12, 12, 1, 12, 12, 12, 12
对于这样的数据, 我们实际上不用把每个数据都保存下来,只需要保存每个数字重复了几次。 用
{1; 11}, {6; 12}, {1; 1}, {4; 12}
这样我们只用11位(
以上就是Run-length encoding (RLE)压缩算法,与我们将在后面介绍的字典压缩算法一样都是很经典的压缩算法。对于很多数据中提到的很夸张的压缩比, 比如每个数据被压缩成不到1比特, 通常都是使用了RLE或者类似的算法。 对于某些极端假设, 比如一个数据存储了十亿个0, 或者一个文件里面存储了一百万个相同的重复字符串,都很适合于RLE算法。
RLE算法本身也其他一些算法基石, 比如 simple-8b RLE, 都是一个种组合算法。在实际的情况中, 我们在时序数据库使用的就是simple-8b RLE算法的变种并自动应用于适用RLE算法情景中。 与标准simple 8b不同, 我们用改变了数据块大小以便适用于64位数值和RLE算法。
4,浮点数压缩
XOR-based compression
Facebook在2015年发表的关于时序数据库的论文中, 引入了两种进一部提高差值计算的算法。第一种是之前我们提到过的delta-of-delta encoding算法。 第二种, 就是我们即将介绍的主要是针对浮点数的XOR-based compression。有人会把这两种算法(尤其是后一种)称之为 Gorilla 压缩。
浮点数通常要比整数更难压缩。 与整数中常见的一大串前缀0不同, 浮点数类型的数据一般都会用到所有的数位。 更何况, 对于十进制转化而来的浮点数, 二进制本身有的时候无法精确表示所有数位。
差值压缩这对于浮点数压缩也不是很有效。比如, 在我们上面的例子中, 如果我们把 CPU 的类型设为double,差值仍然有很多小数位。
| time | cpu |
|-------|--------------|
| t1 | 0.8204859587 |
| t2 | 0.9813528043 |
| DELTA | 0.1608668456 |
基于以上的原因, 大部分对浮点数的压缩算法要么是很繁琐很慢, 要么就是通过直接去掉末尾数字无法实现无损。 能否实现无损压缩本身是一个很重要的问题, 因为如果可以接受数据变化, 的确可以节省很多空间, 但数据本身也会出现变化。
XOR-Based 是少数可以做到兼顾速度与无损的浮点数压缩算法。 Gorilla那篇论文也显示, 压缩效果非常显著。
“We addressed this by repurposing an existing XOR based floating point compression scheme to work in a streaming manner that allows us to compress time series to an average of 1.37 bytes per point, a 12x reduction in size.”
在这个算法中, 连续的浮点数被通过异或运算组合在一起, 也就是说只有不同的数位会被存储。

图来自于Gorilla论文
图中所示, 第一个数据不会被压缩, 而且从第二数开始, 只存储异或计算之后的数值。
根据 Facebook 所提供的数据, 在应用了XOR压缩算法之后, 50%浮点数(均为double型,64bit)都被压缩到一个bit,,近30%为26.6bit, 剩下为39.6 bit。
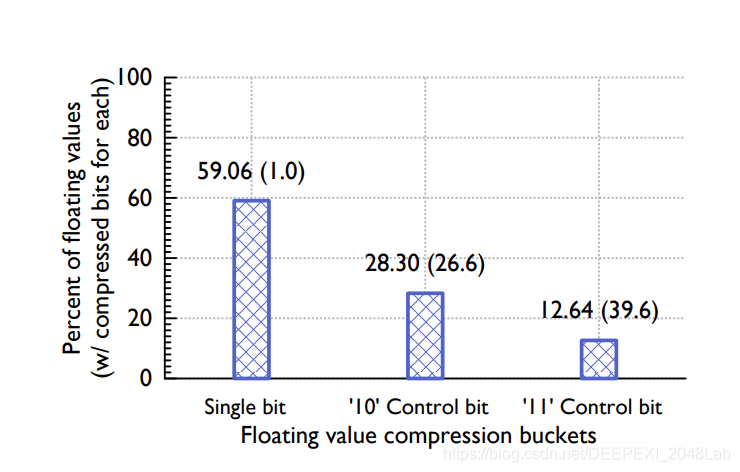
图来自于Gorilla论文
5,未知数据压缩
Dictionary compression
作为最早几个无损压缩来说, 字典压缩可以称得上是很多压缩算法的鼻祖,其衍生算法包括 GIF 使用的 LZW 算法以及PNG和gzip使用的 DEFLATET算法。甚至其基本原理己经不局限于计算机领域。
字典压缩不会直接存储数据本身, 他会把出现过的数据做成一个字典,只需要保存其唯一索引即可。这种方法的应用面很广, 而且不用考虑数据类型。 特别是对那些有大量重复数据的情况特别有效。
举例来说, 如果我们在刚才的例子里面加一个新列来保存城市信息, 如下
| City |
|---------------|
| New York |
| San Francisco |
| San Francisco |
| Los Angeles |
| ⋮ |
如果我们不保存城市名, 而且是使用下面的字典
{0: “New York”, 1: “San Francisco”, 2: “Los Angeles”, ...}
那样我们就可以只存储0, 1, 2.. 这样的索引。
对于像上面这种有很多重复信息的数据,通过字典压缩可以大幅节省空间。在上面的例子中, 每个城市的名字平均下来有11位, 而其索引都不超过4位。 可以节省近四分之三。 在同时应用了simple-8b + RLE之后, 还可以省更多的空间。
当然与其他所有的压缩算法一样,字典压缩也不是适合于所有情况。 对于那些很少重复的数据, 字典压缩后的数据将会与原数据大小一样外加一个多出来字典。然而在时序数据库中,我们将找出这种情况, 然后不把字典压缩应用于这些了情景中。
6,压缩实践
作为基于PostgreSQL的时序数据库,我们应用了以上提到的所有压缩算法,并且最终达到了节省90%空间的目标。
对于不同的数据类型, 我们采用不同的压缩算法。
对于整数、时间戳以及其他类似的数据类型, 我们使用 Delta-of-delta + Simple-8b 与 RLE 压缩相结合的方式。
对于浮点数, 使用XOR压缩。
对于所有的数据, 我们使用 LZ-based array compression。
对于大量重复的数据, 我们使用全列字典压缩法。
而且, 我们还扩展了传统的simple-8b 与 XOR 压缩算法。这样我们就可以反向对数据进行压缩, 这样可以加速对时序数据查询常用反向检索。
XOR 与 Delta of delta 结合, 不但可以得到更高的压缩比,而且还可以比单独使用LZ-base compression 快40倍。
最后,如果有哪些数据完全无法应用以上的所有算法, 我们将把他们放到单独的一个数组中。这样做有以下两点好处:
我们可以把这个数组的空位图与每个数据的大小使用压缩整数的算法一起压缩,这样可以节省少量的空间。
我们可以把很多数据库的行放到一个行中。 PostgreSQL 对每行都会保存一个不可忽略的额外空间(约48个字节)。 我们通过并行可以减少下这部分多出来的空间。
如果你对以上内容感兴趣且需要帮助的话,可以登录了解更多TSDB产品详情。