我一怒之下写了个抄袭举报工具!只因一觉醒来我的文章被多个平台抄袭!
摘要
由于互联网的开发性,知识内容获取极其简便。某些平台、博主、机构为了个人虚荣、营销使用不光彩的手段对博主的文章进行剽窃、洗稿、抄袭,对于许多在互联网上发表技术文章、教程的博主来说是十分不公平的;我曾经听到我的一位朋友
本篇文将会编写一个小工具,随后将会逐步迭代,自动从搜索引擎中获取文章的查询结果,并且与之完成相似度对比,自动编写举报文档等,完成这一部分繁琐的过程,为保护原创增加一份力量。
工具及环境
本篇文章使用
使用
支持库众多方便在之后的功能扩展中能够增加开发效率
语法简单开发效率高
使用
使用
selenium 可以不用考虑大部分的js 页面提高开发效率可视化的操作方式更容易错误的调试
第三方依赖库:
jieba collections selenium BeautifulSoup
注:
以下文章为了考虑篇幅将不赘述安装方式,尽量以简洁且完整的叙述的方式叙述如何开发完整的工具。
为了使更多人能够复现本文内容,将定位本文读者为“零基础”,对部分内容将会细致的进行描述说明。
本篇文将使用颜色对不同属性的英文进行标注:
本篇文代码相关 名词 链接
一、使用 selenium 对目标内容进行搜索
1.1 谷歌与火狐浏览器驱动安装提示
使用
以上驱动下载完毕后还需配置到系统
1.2 使用火狐浏览器打开百度搜索页面
from selenium import webdriver
driver = webdriver.Firefox()
url='https://www.baidu.com'
driver.get(url)以上代码的第一行从
1.3 完成目标内容的搜索
在 1.2 节中使用
知道了我们的流程步骤后,我们可以分析一下正常用户在进行搜索时的操作流程。第一步打开搜索页面、第二步输入搜索关键字、第三步点击搜索键,需要模拟这个过程我们应拿到这 3 个操作所对应的
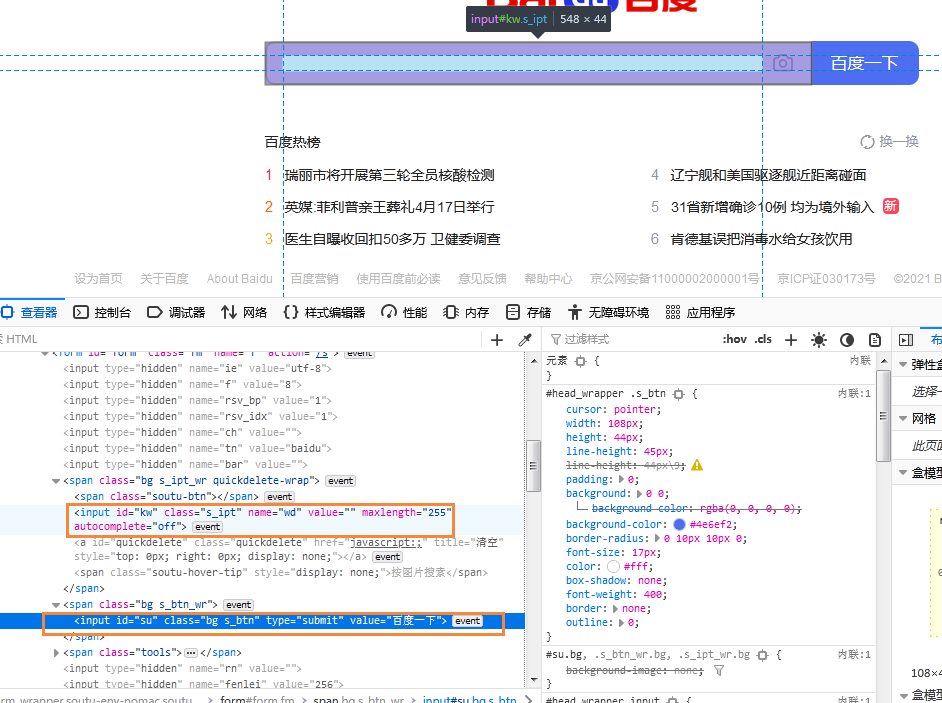
此时我们已经知道了该元素的
知道了搜索内容后,我们可以通过获取到的文本框对象调用
from selenium import webdriver
driver = webdriver.Firefox()
url='https://www.baidu.com'
driver.get(url)
textinput=driver.find_element_by_id('kw')
enter=driver.find_element_by_id('su')
textinput.send_keys('Java 失宠,谷歌宣布 Kotlin 现在是 Android 开发的首选语言')
enter.click()搜索结果如下:

从搜索结果中我们可以看见,标题有超过 1000000 个类似内容,那抄袭该文的有多少呢?由于本文所编写的工具无法进行过大的内容查询,使用
此时我们得到了该数据后,接下来就应该对搜索出来的数据进行收集、记录到本地,方便接下来的相似度分析。
1.4 对搜索结果进行记录
我们需要对搜索结果进行记录需要使用
首先我们在前几节所新建的
from bs4 import BeautifulSoup在
#获取页面源码
html=driver.page_source
#使用 BeautifulSoup 新建解析 html 内容,指定解析器为 html.parser
soup = BeautifulSoup(html, "html.parser") 随后我们查看搜索结果的
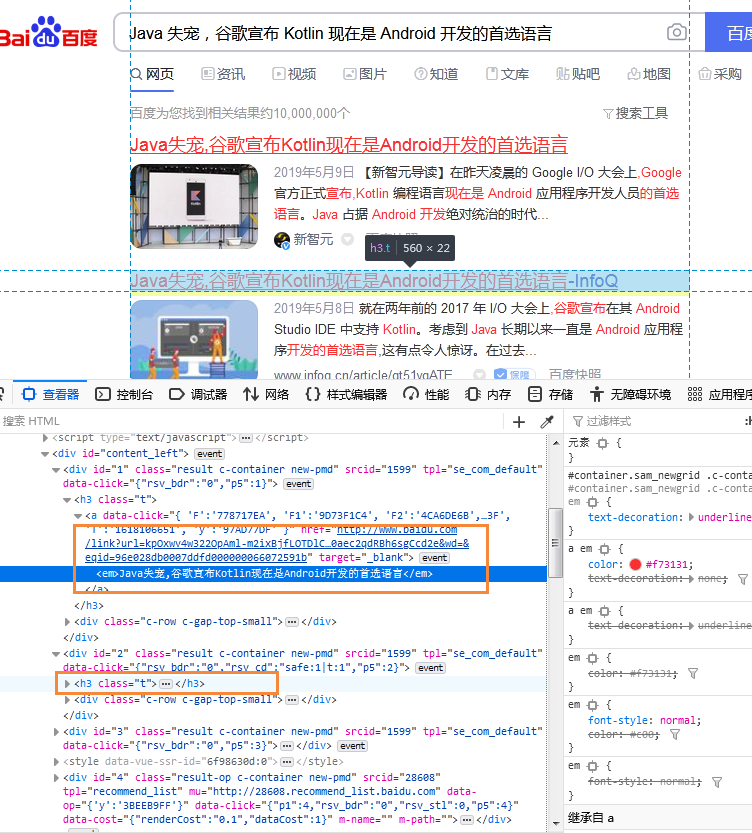
这时我们可以通过使用 的
search_res=soup.select('.t')此时
#遍历结果取值
for res in search_res:
print(res.a['href'])这个时候运行代码可能会取不到值,原因是我们并未等待浏览器解析就直接获取了页面数据,此时可以使用循环对获取的搜索结果进行判断,若为空则继续获取:
for i in range(1000):
#获取页面源码
html=driver.page_source
#使用 BeautifulSoup 新建解析 html 内容,指定解析器为 html.parser
soup=BeautifulSoup(html,"html.parser")
search_res=soup.select('.t')
if len(search_res)>0:
break
#遍历结果取值
for res in search_res:
print(res.a['href'])我使用的是
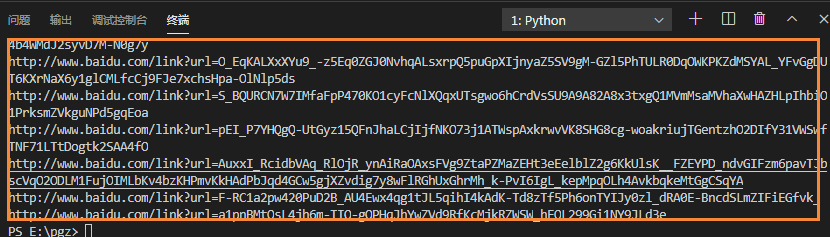
1.5 获取结果的真实链接
此时我们得到的结果并不是搜索出的资源的真实地址,需要进行过滤后提取。
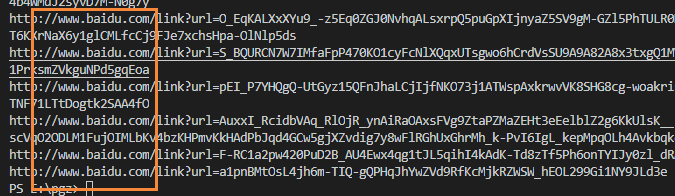
此时只需要访问其地址,得到正确的
第一步使用
for res in search_res:
jscode = 'window.open("'+res.a['href']+'")'
driver.execute_script(jscode)此时将会打开一个
handle_this=driver.current_window_handle # 保留当前句柄随后获取所有的可操作句柄:
handle_all=driver.window_handles # 获取所有句柄之后就简单的使用
handle_exchange=None #要操作的句柄
for handle in handle_all:
if handle != handle_this: #非当前句柄就交换
handle_exchange = handle得到句柄之后使用
driver.switch_to.window(handle_exchange)#切换此时已经完成了句柄的切换操作,那么直接使用
real_url=driver.current_url接着使用
driver.close()
driver.switch_to.window(handle_this)其实此时获取真实链接地址的代码并不严谨,因为在进行请求时,得到的真实链接将会有一定的重定向时间,否则无法获取到相应的真实地址,值为
link_res=[]
#遍历结果取值
for res in search_res:
jscode = 'window.open("'+res.a['href']+'")'
driver.execute_script(jscode)
handle_this=driver.current_window_handle
handle_all=driver.window_handles
handle_exchange=None #要操作的句柄
for handle in handle_all:
if handle != handle_this: #非当前句柄就交换
handle_exchange = handle
driver.switch_to.window(handle_exchange)
real_url=driver.current_url
if real_url=='about:blank':
i=0
while True:
real_url=driver.current_url
if real_url!='about:blank':
break
if i>10000:
real_url='null'
break
i+=1
driver.close()
driver.switch_to.window(handle_this)
link_res.append(real_url)
print(real_url)终端输出结果如下:
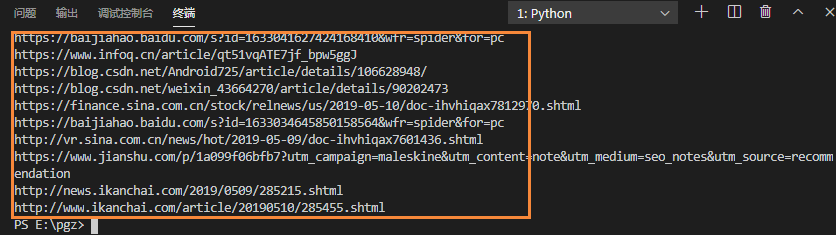
1.6 修改 dataspider.py 代码结构
为了方便之后进行扩展,我们对已有的代码结构进行一下优化。
新建一个类名叫
#打开引擎
class Spider():
def open_engine(self,driver,engine):
if engine=='baidu':
url='https://www.baidu.com'
driver.get(url)
self.input_id='kw'
self.click_id='su'该方法接收两个参数,分别是
接下来创建一个
#键入关键字
def enter_kw(self,driver):
textinput=driver.find_element_by_id(self.input_id)
enter=driver.find_element_by_id(self.click_id)
textinput.send_keys('Java 失宠,谷歌宣布 Kotlin 现在是 Android 开发的首选语言')
enter.click()该方法传入了浏览器操作对象
之后新建一个
#搜索结果链接
def get_search_link(self,driver,engine):
self.open_engine(driver,engine)
self.enter_kw(driver)
engine_res=[]
for i in range(10000):
engine_res=[]
#获取页面源码
html=driver.page_source
#使用 BeautifulSoup 新建解析 html 内容,指定解析器为 html.parser
soup=BeautifulSoup(html,"html.parser")
engine_res=soup.select('.t')
if len(engine_res)>0:
break
return engine_res 在这个方法中,使用了
最后创建
#获取 real link
def get_real_link(self,engine_res,driver):
#遍历结果取值
real_res=[]
for res in engine_res:
jscode='window.open("'+res.a['href']+'")'
driver.execute_script(jscode)
handle_this=driver.current_window_handle
handle_all=driver.window_handles
handle_exchange=None #要操作的句柄
for handle in handle_all:
if handle != handle_this: #非当前句柄就交换
handle_exchange=handle
driver.switch_to.window(handle_exchange)
real_url=driver.current_url
if real_url=='about:blank':
i=0
while True:
real_url=driver.current_url
if real_url!='about:blank':
break
if i>10000:
real_url='null'
break
i+=1
driver.close()
driver.switch_to.window(handle_this)
real_res.append(real_url)
#print(real_url)
return real_res最后编写一个
class Spider():
def get_search_res(self,driver,engine):
engine_res=self.get_search_link(driver,engine)
return self.get_real_link(engine_res,driver)
#打开引擎
def open_engine(self,driver,engine):
if engine=='baidu':
url='https://www.baidu.com'
driver.get(url)
self.input_id='kw'
self.click_id='su'
#键入关键字
def enter_kw(self,driver):
textinput=driver.find_element_by_id(self.input_id)
enter=driver.find_element_by_id(self.click_id)
textinput.send_keys('Java 失宠,谷歌宣布 Kotlin 现在是 Android 开发的首选语言')
enter.click()
#搜索结果链接
def get_search_link(self,driver,engine):
self.open_engine(driver,engine)
self.enter_kw(driver)
engine_res=[]
for i in range(10000):
engine_res=[]
#获取页面源码
html=driver.page_source
#使用 BeautifulSoup 新建解析 html 内容,指定解析器为 html.parser
soup=BeautifulSoup(html,"html.parser")
engine_res=soup.select('.t')
if len(engine_res)>0:
break
return engine_res
#获取 real link
def get_real_link(self,engine_res,driver):
#遍历结果取值
real_res=[]
for res in engine_res:
jscode='window.open("'+res.a['href']+'")'
driver.execute_script(jscode)
handle_this=driver.current_window_handle
handle_all=driver.window_handles
handle_exchange=None #要操作的句柄
for handle in handle_all:
if handle != handle_this: #非当前句柄就交换
handle_exchange=handle
driver.switch_to.window(handle_exchange)
real_url=driver.current_url
if real_url=='about:blank':
i=0
while True:
real_url=driver.current_url
if real_url!='about:blank':
break
if i>10000:
real_url='null'
break
i+=1
driver.close()
driver.switch_to.window(handle_this)
real_res.append(real_url)
#print(real_url)
return real_res
接下来直接新建
s=Spider()
driver=webdriver.Firefox()
res=s.get_search_res(driver,'baidu')
print(res)二、使用余弦相似度对数据进行对比
2.1 余弦相似度(参考阮一峰)
余弦相似度是一种较为简单的文本相似度对比方法,首先需要进行分词,其次进行词向量计算,最后进行相似度分析。分词我们需要使用
余弦相似度使用在文本相似度分析,主要是将句子中的词进行切词,随后去除部分停词后计算剩余词语的词频,随后计算向量;该词频向量是指单一个词语所出现的次数,这个时候文本相似度就变成计算这两个向量之间的相似度。
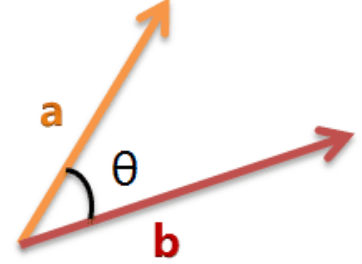
将两个向量当作这两条线段,我们默认指向不同的方向,若两条线段越接近,或者说形成的夹角越小,那么则可以说明这两个向量之间约接近,或者说是这两个文本之间相似度越近。那么可以得出夹角θ:
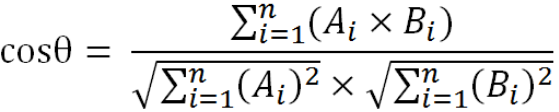
例如有两个句子:
1:我在
info Q 写作很棒,我很开心,我在这里能够认识很多朋友。2:我在
info Q 写文章认识很多朋友,例如小明、小红都是在这里认识的,我很开心,感觉很棒。
我们将句子 1 可以分词为:我、
我们将句子 2 可以分词为:我、
之后将词频进行统计:
1:[我:3,
2:[我:2,
转换为:
1: [2,1,1,1,1,1,1,1]
2: [2,1,1,1,2,1,1,1]
最后套入公式之中为:
(2*2+1*1+1*1+1*1+1*2+1*1+1*1+1*1)/sqrt(sqr(2)+7)*sqrt(sqr(2)+sqr(2)+6)
最终结果如下:

如果给予一个百分比则为是 96% 相似度。
2.2 实现相似度计算
在这一部分中,我们需要新建一个
#分词
def Count(self,text):
tag = analyse.textrank(text,topK=20)
word_counts = collections.Counter(tag) #计数统计
print(word_counts)
return word_counts这一步其实就是分词,并且返回权重值
#词合并
def MergeWord(self,T1,T2):
MergeWord = []
for i in T1:
MergeWord.append(i)
for i in T2:
if i not in MergeWord:
MergeWord.append(i)
return MergeWord接着开始计算向量:
#得出文档向量
def CalVector(self,T1,MergeWord):
TF1 = [0] * len(MergeWord)
for ch in T1:
TermFrequence = T1[ch]
word = ch
if word in MergeWord:
TF1[MergeWord.index(word)] = TermFrequence
return TF1接着我们添加一个方法用于计算相似度(以上以说过如何进行计算,在此就不再赘述):
def cosine_similarity(self,vector1, vector2):
dot_product = 0.0
normA = 0.0
normB = 0.0
for a, b in zip(vector1, vector2):#两个向量组合成 [(1, 4), (2, 5), (3, 6)] 最短形式表现
dot_product += a * b
normA += a ** 2
normB += b ** 2
if normA == 0.0 or normB == 0.0:
return 0
else:
return round(dot_product / ((normA**0.5)*(normB**0.5))*100, 2)最后,我们添加一个方法用于调用这些计算步骤方便使用
def get_Tfidf(self,text1,text2):
T1 = self.Count(text1)
T2 = self.Count(text2)
mergeword = self.MergeWord(T1,T2)
return self.cosine_similarity(self.CalVector(T1,mergeword),self.CalVector(T2,mergeword))from jieba import lcut
import jieba.analyse
import collections
class Analyse:
def get_Tfidf(self,text1,text2):#测试对比本地数据对比搜索引擎方法
# self.correlate.word.set_this_url(url)
T1 = self.Count(text1)
T2 = self.Count(text2)
mergeword = self.MergeWord(T1,T2)
return self.cosine_similarity(self.CalVector(T1,mergeword),self.CalVector(T2,mergeword))
#分词
def Count(self,text):
tag = jieba.analyse.textrank(text,topK=20)
word_counts = collections.Counter(tag) #计数统计
return word_counts
#词合并
def MergeWord(self,T1,T2):
MergeWord = []
for i in T1:
MergeWord.append(i)
for i in T2:
if i not in MergeWord:
MergeWord.append(i)
return MergeWord
# 得出文档向量
def CalVector(self,T1,MergeWord):
TF1 = [0] * len(MergeWord)
for ch in T1:
TermFrequence = T1[ch]
word = ch
if word in MergeWord:
TF1[MergeWord.index(word)] = TermFrequence
return TF1
#计算 TF-IDF
def cosine_similarity(self,vector1, vector2):
dot_product = 0.0
normA = 0.0
normB = 0.0
for a, b in zip(vector1, vector2):#两个向量组合成 [(1, 4), (2, 5), (3, 6)] 最短形式表现
dot_product += a * b
normA += a ** 2
normB += b ** 2
if normA == 0.0 or normB == 0.0:
return 0
else:
return round(dot_product / ((normA**0.5)*(normB**0.5))*100, 2)
2.3 本地文本数据获取
此时已编写相似度对比类、浏览器搜索结果获取,接下来我们可以用一种较为简单的方式实现搜索结果的文本对比。
在
在
class Srcdata():
srcroot=os.getcwd()+r'/txtsrc/'
def getlocaltxt(self):
name=self.gettxtfile()
txt={}
for p in name:
f = open(self.srcroot+p,'r')
txt[p]=f.read()
f.close()
return txt
def gettxtfile(self):
os.chdir(self.srcroot) # 切换到指定目录
name=[]
for filename in glob.glob("*.txt"):
name.append(filename)
return name以上代码中
在此获取文本数据的原因是可以准确的消除对比数据的“噪点”,因为在接下的文本相似度对比中,所取的文本数据为
不过此方面也可以保证质量,使用
2.4 进行文本相似度对比
此时对于搜索结果的文本,我们可以在获取真实连接后强制一段时间等待浏览器加载数据,随后获取整页数据,并且将原有
def get_real_link(self,engine_res,driver):
#遍历结果取值
real_res={}#更改为字典(新增)
for res in engine_res:
jscode='window.open("'+res.a['href']+'")'
driver.execute_script(jscode)
handle_this=driver.current_window_handle
handle_all=driver.window_handles
handle_exchange=None #要操作的句柄
for handle in handle_all:
if handle != handle_this: #非当前句柄就交换
handle_exchange=handle
driver.switch_to.window(handle_exchange)
real_url=driver.current_url
if real_url=='about:blank':
i=0
while True:
real_url=driver.current_url
if real_url!='about:blank':
break
if i>10000:
real_url='null'
break
i+=1
time.sleep(5)#强制等待加载(新增)
html_txt=driver.page_source#获取网页数据(新增)
driver.close()
driver.switch_to.window(handle_this)
real_res[real_url]=html_txt#存储键值对(新增)
#print(real_url)
return real_res接下来为了方便测试,直接在
src=Srcdata().getlocaltxt()#获取本地文本
driver=webdriver.Firefox()#火狐浏览器
s=Spider()#抓取搜索结果及 web 数据
als=Analyse()#相似度分析
接着创建一个
res_html=[]
for kw in src:
res=s.get_search_res(driver,'baidu',kw)
for k in res:
clean_str = ''.join(re.findall('[\u4e00-\u9fa5]',res[k]))#使用 Unicode 提取汉字
src_str = ''.join(re.findall('[\u4e00-\u9fa5]',src[kw]))#使用 Unicode 提出汉字
#print(k,'相似度:',als.get_Tfidf(src_str,clean_str))
res_html.append([k,kw,als.get_Tfidf(src_str,clean_str)])此时编写一个类,生成
class Analyseres():
def res(self,res_html):
html_str=''
for v in res_html:
html_str+=''+str(v[1])+' 相似度:'+str(v[2])+'
'
self.writefile(html_str)
def writefile(self,html):
filename = './res.html'
with open(filename, 'w') as file_object:
file_object.write(html)
print('save res done')并且在结尾处保存结果:
wres=Analyseres()
wres.res(res_html)运行代码后终端将出现如下结果:
将会生成

2.5 结果分析
我们此时可以通过结果查看低相似度的文章结果是否正确:
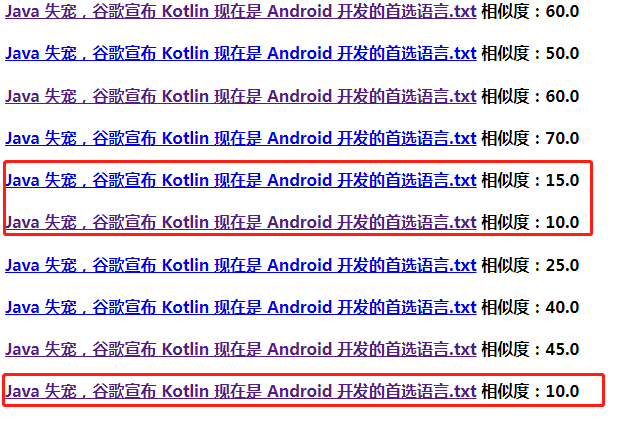
在此列出一篇文章作为例子,可以看出两篇文章内容相似度不高,相似度结果可信度比较高:
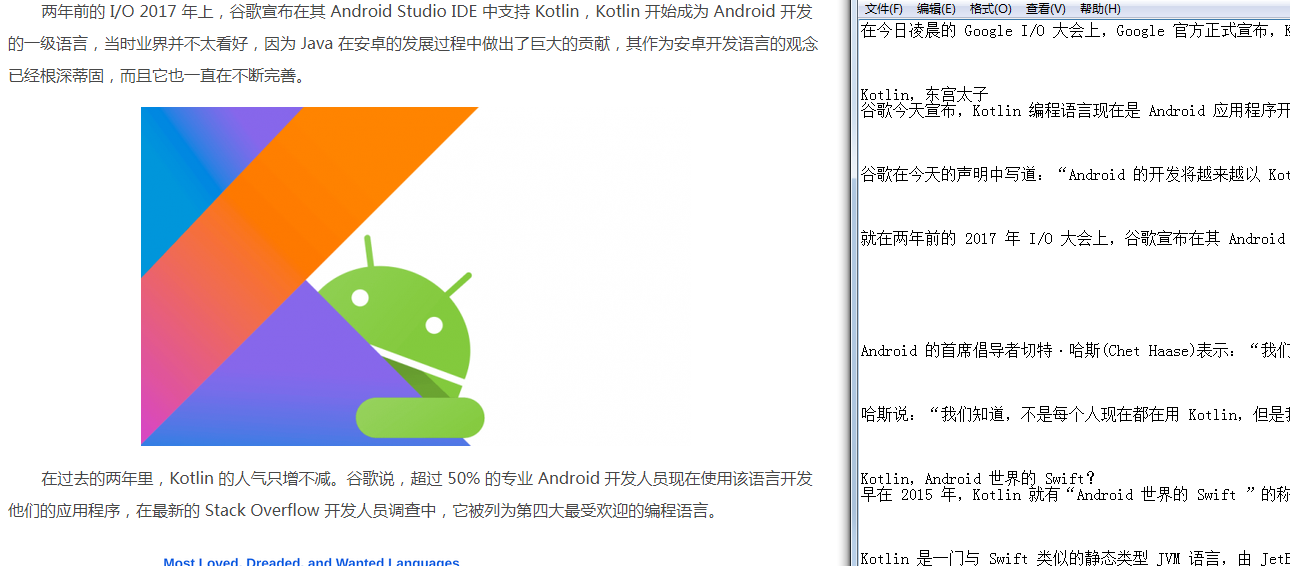
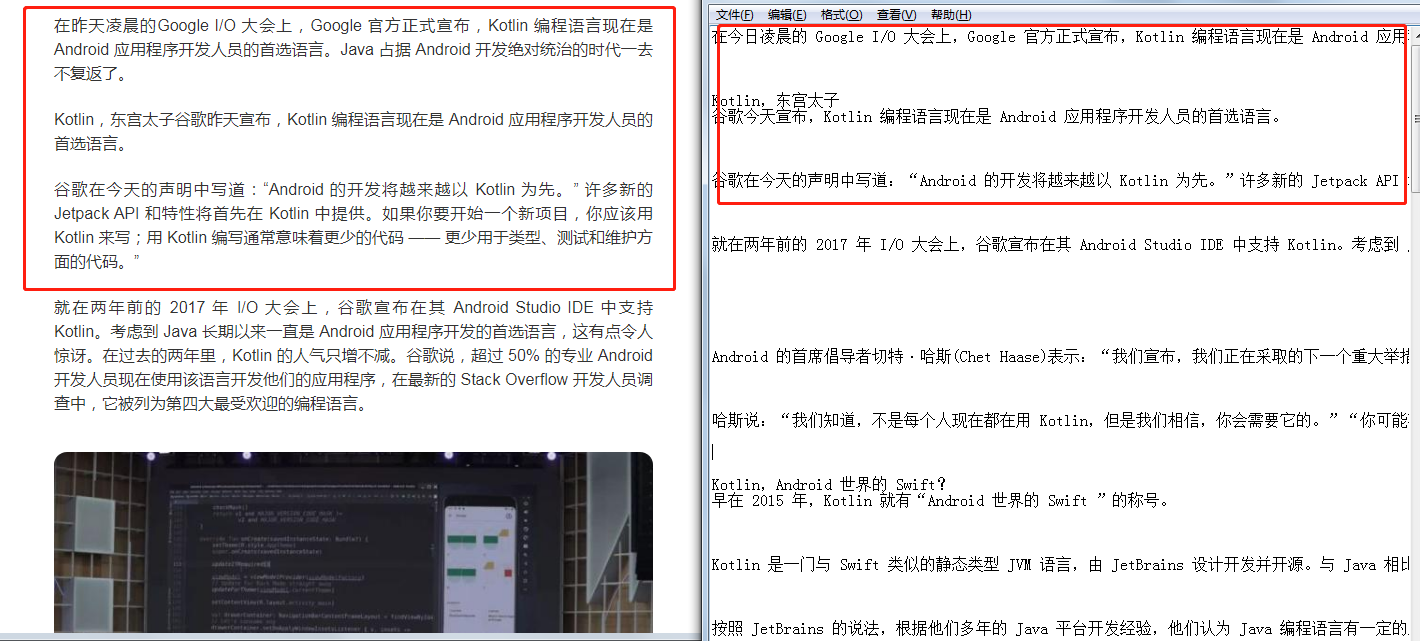
再此再使用一篇较高相似度的文章进行对比,结果发现文章重复度较高,由此可见该工具对查重有一定的准确度:
三、总结
3.1 改进及优化
以下功能将会在之后的文章中进行迭代:
此工具在本地数据获取并不方便,可以编写方法进行扩展,直接获取博主的文章列表,通过
xpath 进行文章数据获取。在进行
Web 搜索时翻页并未实现,也通过id 或者class 获取到元素,随后进行点击翻页。浏览器查重应考虑多个搜索引擎,通过不同策略完成搜索引擎的配置,从而实现不同搜索引擎的查重,包括微信公众号内容的查重搜索。
在过滤数据时可考虑部分头部平台,在头部平台中的网站可设置策略,自动精确获取文本数据。
白名单设置,部分网站不需要抓取,否则将影响查重数据。
3.2 完整代码
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.support.ui import WebDriverWait
import glob,os,time,re
from Analyse import Analyse
class Spider():
def get_search_res(self,driver,engine,kw):
engine_res=self.get_search_link(driver,engine,kw)
return self.get_real_link(engine_res,driver)
#打开引擎
def open_engine(self,driver,engine):
if engine=='baidu':
url='https://www.baidu.com'
driver.get(url)
self.input_id='kw'
self.click_id='su'
#键入关键字
def enter_kw(self,driver,kw):
textinput=driver.find_element_by_id(self.input_id)
enter=driver.find_element_by_id(self.click_id)
textinput.send_keys(kw)
enter.click()
#搜索结果链接
def get_search_link(self,driver,engine,kw):
self.open_engine(driver,engine)
self.enter_kw(driver,kw)
engine_res=[]
for i in range(10000):
engine_res=[]
#获取页面源码
html=driver.page_source
#使用 BeautifulSoup 新建解析 html 内容,指定解析器为 html.parser
soup=BeautifulSoup(html,"html.parser")
engine_res=soup.select('.t')
if len(engine_res)>0:
break
return engine_res
#获取 real link
def get_real_link(self,engine_res,driver):
#遍历结果取值
real_res={}
for res in engine_res:
jscode='window.open("'+res.a['href']+'")'
driver.execute_script(jscode)
handle_this=driver.current_window_handle
handle_all=driver.window_handles
handle_exchange=None #要操作的句柄
for handle in handle_all:
if handle != handle_this: #非当前句柄就交换
handle_exchange=handle
driver.switch_to.window(handle_exchange)
real_url=driver.current_url
if real_url=='about:blank':
i=0
while True:
real_url=driver.current_url
if real_url!='about:blank':
break
if i>10000:
real_url='null'
break
i+=1
time.sleep(5)
html_txt=driver.page_source
driver.close()
driver.switch_to.window(handle_this)
real_res[real_url]=html_txt
#print(real_url)
return real_res
class Srcdata():
srcroot=os.getcwd()+r'/txtsrc/'
def getlocaltxt(self):
name=self.gettxtfile()
txt={}
for p in name:
f = open(self.srcroot+p,'r')
txt[p]=f.read()
f.close()
return txt
def gettxtfile(self):
os.chdir(self.srcroot) # 切换到指定目录
name=[]
for filename in glob.glob("*.txt"):
name.append(filename)
return name
class Analyseres():
def res(self,res_html):
html_str=''
for v in res_html:
html_str+=''+str(v[1])+' 相似度:'+str(v[2])+'
'
self.writefile(html_str)
def writefile(self,html):
filename = './res.html'
with open(filename, 'w') as file_object:
file_object.write(html)
print('save res done')
src=Srcdata().getlocaltxt()
driver=webdriver.Firefox()
s=Spider()
als=Analyse()
res_html=[]
for kw in src:
res=s.get_search_res(driver,'baidu',kw)
for k in res:
clean_str = ''.join(re.findall('[\u4e00-\u9fa5]',res[k]))
src_str = ''.join(re.findall('[\u4e00-\u9fa5]',src[kw]))
#print(k,'相似度:',als.get_Tfidf(src_str,clean_str))
res_html.append([k,kw,als.get_Tfidf(src_str,clean_str)])
wres=Analyseres()
wres.res(res_html)from jieba import lcut
import jieba.analyse
import collections
class Analyse:
def get_Tfidf(self,text1,text2):#测试对比本地数据对比搜索引擎方法
# self.correlate.word.set_this_url(url)
T1 = self.Count(text1)
T2 = self.Count(text2)
mergeword = self.MergeWord(T1,T2)
return self.cosine_similarity(self.CalVector(T1,mergeword),self.CalVector(T2,mergeword))
#分词
def Count(self,text):
tag = jieba.analyse.textrank(text,topK=20)
word_counts = collections.Counter(tag) #计数统计
return word_counts
#词合并
def MergeWord(self,T1,T2):
MergeWord = []
for i in T1:
MergeWord.append(i)
for i in T2:
if i not in MergeWord:
MergeWord.append(i)
return MergeWord
# 得出文档向量
def CalVector(self,T1,MergeWord):
TF1 = [0] * len(MergeWord)
for ch in T1:
TermFrequence = T1[ch]
word = ch
if word in MergeWord:
TF1[MergeWord.index(word)] = TermFrequence
return TF1
#计算 TF-IDF
def cosine_similarity(self,vector1, vector2):
dot_product = 0.0
normA = 0.0
normB = 0.0
for a, b in zip(vector1, vector2):#两个向量组合成 [(1, 4), (2, 5), (3, 6)] 最短形式表现
dot_product += a * b
normA += a ** 2
normB += b ** 2
if normA == 0.0 or normB == 0.0:
return 0
else:
return round(dot_product / ((normA**0.5)*(normB**0.5))*100, 2)