理解RocketMQ
目录
概念
1. low latency
2. high perference
3. Reliability
4. trillion-level capacity
5. flexible scalability
架构
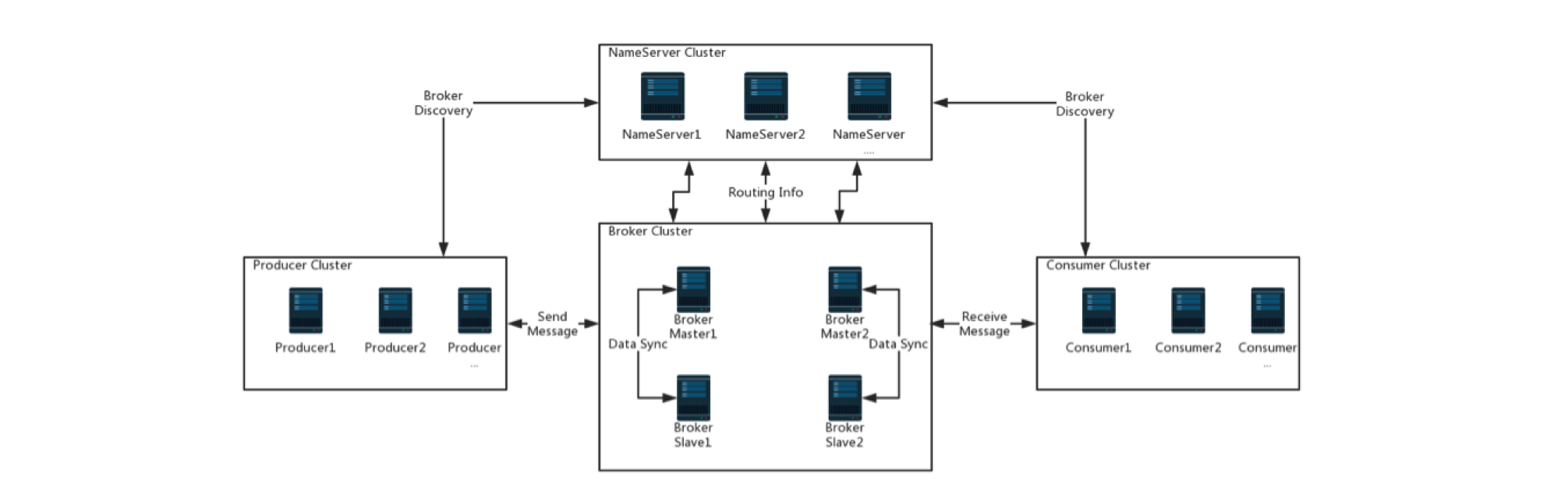
四大组成部分
以上四大部分均可以水平扩展,不存在单点的问题
NameServer Cluster
Name Servers提供了轻量级的服务发现与路由功能。每个NameServer记录了全量的路由信息,并提供相应的读写服务,支持快速存储扩容
Broker Cluster
Brokers通过提供轻量级的Topic和Queue机制来管理消息存储。支持推和拉模型,容错机制(2 copys or 3 copys),提供了强大的消锋填谷和累计百亿级顺序消息堆积能力。另外,Brokers还提供了其他传统消息系统中缺少的灾难恢复、丰富的指标统计和告警机制等。
Producer Cluster
Producers支持分布式部署。分布式的生产者通过多种负载均衡方式发送消息至Broker。消息发送处理支持快速失败和低延时。
Consumer Cluster
Consumers支持分布式部署,即支持推模型也支持拉模型。Consumers同样支持集群消费和广播。Consumers提供了实时消息订阅机制且能满足大部分Consumer需求。
Name Server
NameServer是一个完全的基础性服务,提供了两大特性:
1. Broker管理,NameServer接收Broker Cluster的注册请求并提供了心跳监测机制对Broker判活
2. Routing管理,每个NameServer包含了Broker集群的所有路由信息和客户端查询的队列信息。
客户端如何获取NameServer的地址信息?有四种方式:
1. 硬编码:producer.setNamesrvAddr("ip:port”)
2. Java Options:rocketmq.namesrv.addr
3. 环境变量:NAMESRV_ADDR
4. Http endpoint
Programmatic Way > Java Options > Environment Variable > HTTP Endpoint
详情见:http://rocketmq.apache.org/rocketmq/four-methods-to-feed-name-server-address-list/
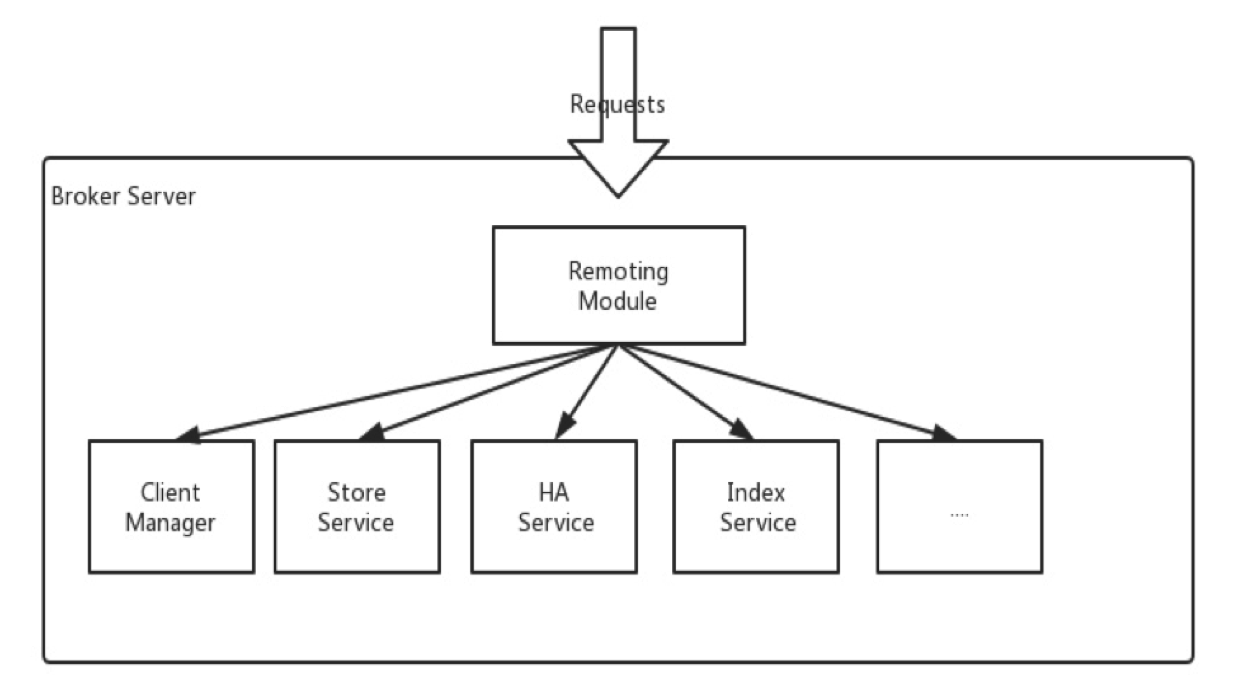
Broker Server
Broker负责消息存储、发送、查询、HA等,主要包含如下几个模块:
1. Rmoting Module:borker入口,负责处理请求
2. Client Manager:管理客户端(Produer & Consumer)和客户端订阅Topic信息
3. Store Service:提供简易API从物理硬盘存储和查询消息
4. HA Service:提供了主从之间的数据同步特性
5. Index Service:针对消息特定的key构建索引,方便快速查询
部署
Broker
Brokers根据角色划分可以分为两大类:Master & Slave
Master提供读写访问操作而Slave只提供读操作。
为了搭建没有单点故障的高可用Broker集群,需要部署几个Broker集。一个Broker集包含一个Master(brokerId=0)和几个brokerId不重复的slaves(brokerId!=0),一个broker set中的所有broker拥有相同的brokerName。在一些场景中, 一个broker set一般至少包含两个broker。每个Topic至少在两个或两个以上的broker存在。
NameServer
建议至少部署两台NameServer,以确保在一个实例crash后整个集群可以继续提供服务。只要有一台NameServer存活,整个集群即可用。
NameServer遵循各自独立不共享的设计模式。所有Broker发送信息数据到所有NameServer。Producer/Consumer当发送或接收消息的时候可以从任何一个存活的NameServer获取meta data。
##Broker配置

客户端工具CLI Admin Tool
复制模式
1. 为了确保成功发送的消息不丢失,RocketMQ提供了Sync & Async两种复制模式
2. 像很多其他系统一样,sync brokers等待commit log成功复制到slave后再确认。而Async brokers,消息被master处理后立即返回。
最佳实践
##核心概念
生产者发送业务系统产生的消息到brokers。RocketMQ提供了多重发送方式:同步、异步、one-way(比如日志)
相同角色的生产者聚集成组。为了防止原来的生产者crash after transaction,同组下的另一个生产者实例会被broker通知coomit or role back transaction。
注意:一般一个组下一个producer实例已经足够可靠,减少不必要的开销
消费者从brokers获取消息反馈给应用。RocketMQ提供了两种类型的comsumers
1. PullConsumer
2. PushConsumer
封装pulling,消费处理,提供消费接口供Consumer实现处理逻辑
1. 与前面提到的Producer Group概念非常类似,完全相同角色的comsumers聚集成组为Consumer Group
2. Consumer Goup是一个广泛的概念,在消息消费方面,达到负载均衡,容错处理非常简单。
3. 同组下的消费者实例必须拥有完全相同的Topic订阅
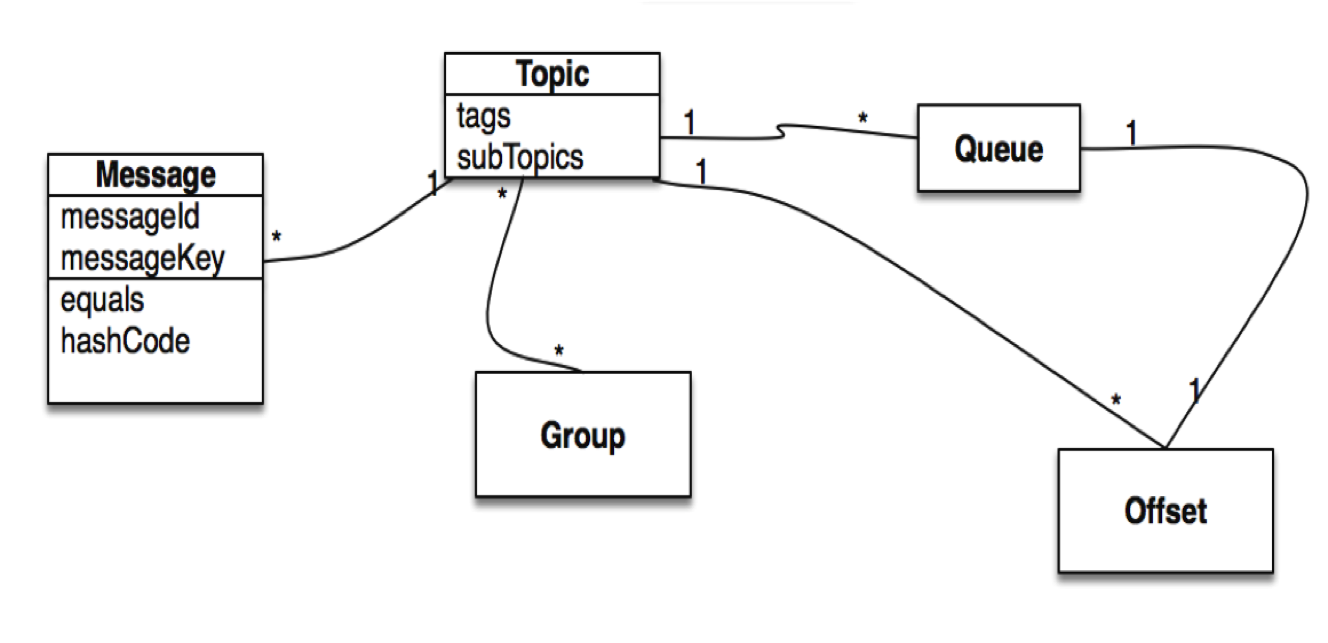
Topic是生产者发送消息和消费者拉去消息的范畴。Topics与producers & consumers之间松耦合。可以有0,1或多个producers发送消息到一个Topic;反过来,一个producer发送消息到不同的topics。从消费端开来,一个topic可以被0,1或多个consumer groups。而一个consumer group,类似的可以订阅1或多个topics只要这个consuer group下的实例保持一致的订阅。
Message是被传送的信息。一个message必须包含一个topic(可以理解为邮件发送地址)。一个消息可以包含一个可选择的tag和一些额外的key-value属性。比如,在开发过程中你可以设置一个业务key在你的消息并且在broker上查找消息来定位问题。
Topic被分为1到多个sub-topics,”message queues”
Tag,换句话说sub-topic,为用户提供了额外的弹性。With tag,相同业务模块的不同用途的消息可以拥有相同的topic和不同的tag。Tags对我们代码的整洁性和清晰度是有益的,并且tags可以完善RocketMQ提供的查询机制
Broker是RocketMQ系统的一个重要组件。它接收来自producers发来的消息,存储并处理来自consumers端的拉取请求。Broker也存储了消息关联的meta data,包括consumer groups,consuming progress offsets 以及topic/queue信息。
NameServer作为路由信息提供者服务。Producer/Consumer客户端查询topics找到相应的broker list。
Cluster
Broadcasting
Oderly
Concurrently
Broker Role:Broker分为ASYNC
FlushDiskType:建议ASYNC
ReentrantLock VS CAS
os.sh
SendStatus
FLUSH
FLUSH
SLAVE
SEND_OK
Duplication or Missing
消息重试
消息幂等,防止Consumer重复消费
Timeout
缺省超市时间为3秒,可以自定义send(msg, timeout),不建议超时时间太长
Message Size
建议不超过512k,一批不超过1M
Async Sending
Producer Group
在同一个jvm中在一个producer group只能创建一个producer实例,一个就足够了
Thread Safety
Performance
3~5个producers,异步发送
为每个producer设置实例名字
不同Consumer Group可以独自消费相同的topic,并且各自有各自的消费offsets。确保下同Group的Consumer订阅了相同的topics
MessageListener
Orderly
消费者锁定消息队列确保顺序消费。这样会带来性能开销,但如果你关心消息的是有帮助的。不建议抛出异常,可返回SUSPEND
Concurrently
并发访问,高性能。同样不建议抛出异常,建议返回RECOMSUME_LATER。
Consume Status
Blocking
不建议阻塞监听,因为这样会阻塞线程池,甚至停止消费进程
Thread Number
Consumer内部使用线程池处理消费,可以设置setConsumeThreadMin和setConsumeThreadMax
ConsumeFromWhere
CONSUME
CONSUME
CONSUME
Duplication
原因
Producer消息重发
Consumer停止导致一些offsets没有及时更新到Broker
解决方案
幂等
在RocketMQ中,NameServers被设计用来协调分布式系统中的组件,协调工作主要通过管理topic路由信息完成。
两大协调工作
1. Brokers定期同步更新meta data到每个name server
2. NameServers用最新的路由信息服务于producers,consumers和命令行。
JVM Options
Version jdk1.8
-server -Xms8g -Xmx8g -Xmn4g
如果不关心Broker的启动时长,可以设置
-XX:+AlwaysPreTouch
关闭biased locking 减少jvm停顿,可以设置:
-XX:-UseBiasedLocking
Use G1
-XX:+UseG1GC -XX:G1HeapRegionSize=16m -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30
Rolling GC log file
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=30m
GC log file指向内存文件系统
-Xloggc:/dev/shm/mq
Linux Kernel Parameters
os.sh
vm.extra
RocketMQ使用此值降低内存分配延迟
vm.min
低于1024k,系统容易宕机,在高负载下容易死锁
vm.max
RokcetMQ使用mmqp加载CommitLog和ConsumeQueue,建议调高这个参数
vm.swappiness
建议10
File descriptor limits 建议设置为655350
Disk scheduler 建议deadline IO
附录
附录1
Linux磁盘IO调度策略
1. cfq(Complete Fairness Queueing),这是一个复杂的调度策略,按进程创建多个队列,试图保持对多个进程的公平(忽略了读、写操作的不同消耗)
2. deadline,这是一个比较单间的策略,只分了读和写两个队列(加速读取量比较大的系统),内核为每个IO操作设置了一个超时时间
3. noop,这个策略最简单,只有单个队列,只有一些简单合并操作
附录2
文件句柄数(文件描述符)设置
shell级,ulimit –n num
用户级,修改/etc/security/limitis.conf
root soft nofile 65535
root hard nofile 65535
备注:
1、soft数小于等于hard数
2、系统会给出一个建议值/proc/sys/fs/file-max,但是limits.conf设定可以超过建议值
附录3
MMAP VS DMA
MMAP:将磁盘文件映射到内存,通过修改内存就能达到修改磁盘文件的目的。利用操作系统的Page实现文件到物理内存的映射,之后对物理内存的操作会在适当的时候同步到硬盘上。适合大量小数据块高效传输,依赖于cpu,不太适合大数据块传输。
DMA:Direct Memory Access,是一种硬件机制,降低对cpu的依赖,适合大数据块传输。