MySQL系列 - SQL查询与修改执行过程
我们平时都是输入一条语句,返回结果。那么,这条语句在MySQL内部的执行过程是什么样的呢?
select * from tab1 where id = 1;MySQL的逻辑架构
首先我们来看MySQL的基本逻辑架构示意图
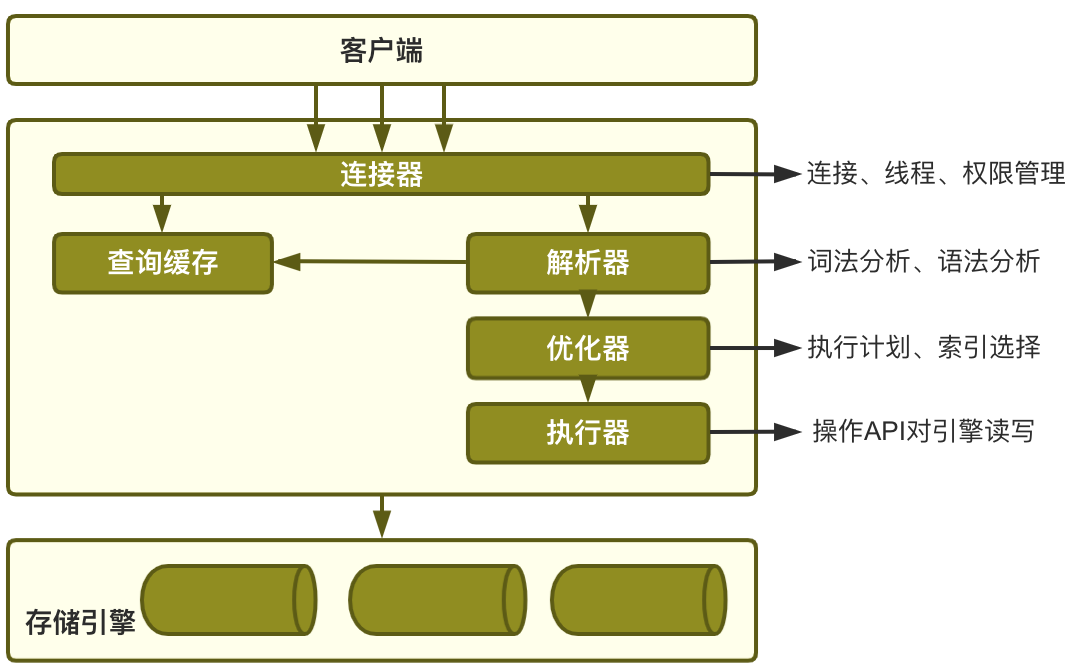
Server
MySQL的核心服务功能。
查询解析、分析、优化、缓存
所有的内置函数:日期、时间、数学与加密函数等
所有的跨存储引起 的功能都在这一层实现:存储过程、触发器、视图
存储引擎
数据的存储与提取。
每个存储引擎都有它的优势与劣势。
Server层通过API接口与存储引擎通信,屏蔽不同引擎的差异。
存储引擎不会解析SQL(InnoDB的外键定义解析是例外)。
连接管理与安全性
每个客户端通过服务端的连接器:建立连接、获取权限、维持连接、管理连接。
mysql -h$ip -P$port -u$user -p长连接与短链接
连接建立的过程是比较复杂的,所以我们尽量使用长连接。
但是要注意内存情况,查询过程中临时使用的内存式管理在连接对象里面的,这些资源会在连接断开的时候才释放。所以随着长连接基类下来,可能会产生OOM。
优化与执行
查询缓存
一个查询请求会先查询一个对大小写敏感的哈希缓存,看之前是否执行过,假如匹配到了,直接返回结果给客户端。
但是,查询缓存会跟踪查询中涉及的每张表,如果这些表有数据变化,那么和这个表相关的所有缓存都将失效。所以对于一个线上业务的表来说,查询缓存是弊大于利的,因为频繁的缓存和失效会带来更多的消耗。MySQL 8.0 +开始直接将查询缓存的整块功能删掉了。
解析与优化
MySQL会解析查询,并创建内部数据结构(解析树),然后对其进行各种优化,包括重写查询、决定表的读取顺序,以及选择合适的索引。
Tips:
用户可以通过关键帧提示优化器,影响它的决策过程。
可以通过 解释优化过重中的各个因素,使用户知道优化器如何决策,提供一个参考基准,便于用户重构查询与Schema,优化配置。
优化器不关心使用的是什么存储引擎,但存储引擎对优化查询是有影响的,所以优化器会请求存储引擎的一些“元”数据,比如表数据统计信息、容量、操作开销等。
慢查询中的 就是指执行器扫描了多少行。
数据更新
相比于查询流程,数据更新基于WAL(Write-Ahead Log)。
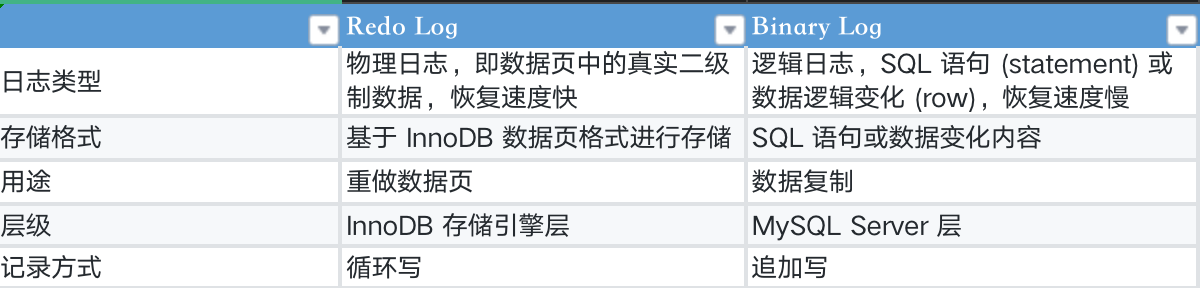
Binary Log、Redo Log
Binlog 是 MySQL 本身提供的一种逻辑日志,和具体存储引擎无关,描述的是数据库所执行的 SQL 语句或数据变更情况,主要用于数据复制。
Redo Log 是 InnoDB 存储引擎提供的一种物理日志结构,用来描述对底层数据页操作的具体内容,主要用于实现 crash-safe,并将部分随机 IO 写变为顺序写,提升磁盘操作效率。
这个参数设置成1表示每次事务的redo log都持久化到磁盘
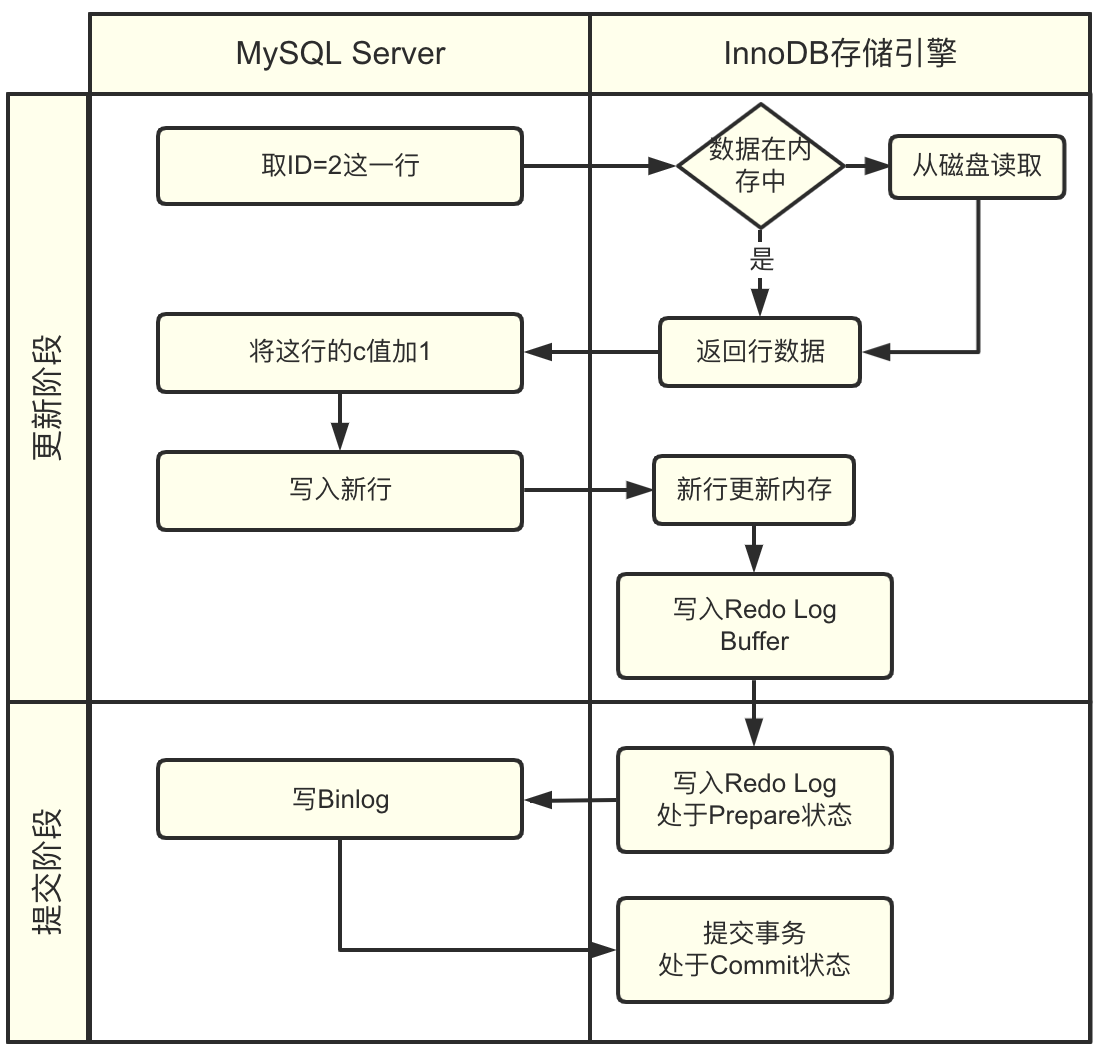
两阶段提交
两阶段提交不是 Redo Log 或 InnoDB 中的设计,而是 MySQL 服务器的设计。MySQL是插件化的存储引擎设计,事务提交时,服务器本身与存储引擎都需要提交数据,所以从整体来看,其本身就面临着分布式事务问题。
MySQL 执行器和 InnoDB 存储引擎在执行简单 update 语句 时的流程(因为此例只执行单条更新语句,所以其自身就是一个事务)。
小结
关于具体的优化与执行点:重写查询、决定表的读取顺序,以及选择合适的索引会在该系列其他文章详细解读。
分布式事务的两段提交(2PC)、三段提交(3PC)、共识算法(VSR、Paxos、Raft、Zab等)与全序广播,也会出专门的文章讲解。