ChaosBlade x SkyWalking 微服务高可用实践

前言
在分布式系统架构下,服务组件繁多且服务间的依赖错综复杂,很难评估单个故障对整个系统的影响,而且请求链路长,如果监控告警、日志记录等基础服务不完善会造成故障响应、故障定位问题难,所以如何构建一个高可用的分布式系统面临着很大挑战。混沌工程就此产生,在可控范围或环境下通过对系统注入故障,观察系统行为并发现系统缺陷,以建立对分布式系统因意外条件引发混乱的能力和信心,持续提升系统的稳定性和高可用能力。
混沌工程的实施流程是制订混沌实验计划、定义稳态指标,做出系统容错行为假设,然后执行混沌实验,检查系统稳态指标等。也因此混沌实验整个过程需要可靠的、易于使用且场景丰富的混沌实验工具注入故障以及完整的分布式链路追踪和系统监控工具,以便触发应急响应预警方案与快速地进行故障定位,并观察整个过程系统的各项数据指标等。本篇文章我们介绍混沌实验工具(ChaosBlade)和 分布式系统监控工具(SkyWalking),并且结合一个的微服务案例分享一下 ChaosBlade 和 SkyWalking 微服务高可用实践。
工具介绍
1. ChaosBlade
是一款遵循混沌工程实验原理,提供丰富故障场景实现,帮助分布式系统提升容错性和可恢复性的混沌工程工具,可实现底层故障的注入,并且在企业上云或往云原生系统迁移过程中业务连续性保障,特点是操作简洁、无侵入、扩展性强。ChaosBlade 可以在可控范围或环境下,通过故障注入,来持续提升系统的稳定性和高可用能力。
ChaosBlade 不仅使用简单,而且支持丰富的实验场景,场景包括:
基础资源:比如 CPU、内存、网络、磁盘、进程等实验场景;
Java 应用:比如数据库、缓存、消息、JVM 本身、微服务等,还可以指定任意类方法注入各种复杂的实验场景;
C++ 应用:比如指定任意方法或某行代码注入延迟、变量和返回值篡改等实验场景;
Docker 容器:比如杀容器、容器内 CPU、内存、网络、磁盘、进程等实验场景;
云原生平台:比如 Kubernetes 平台节点上 CPU、内存、网络、磁盘、进程实验场景,Pod 网络和 Pod 本身实验场景如杀 Pod,容器的实验场景如上述的 Docker 容器实验场景;
ChaosBlade 将场景按领域实现封装成一个个单独的项目,不仅可以使领域内场景标准化实现,而且非常方便场景水平和垂直扩展,通过遵循混沌实验模型,实现 chaosblade cli 统一调用 。
2. SkyWalking
是一个开源的 APM 系统,包括对云本地架构中的分布式系统的监视、跟踪和诊断功能。核心特性如下:
服务、服务实例、端点指标分析
根本原因分析
服务拓扑图分析
服务、服务实例和端点依赖性分析
检测到慢速服务和终结点
性能优化
分布式跟踪和上下文传播
数据库访问指标。检测慢速数据库访问语句(包括SQL语句)。
报警
工具安装及使用
ChaosBlade 的安装和使用都很简便,ChaosBlade 各场景通过 chaosblade cli 统一调用,仅需要下载对应的 tar 包,解压后使用 可执行文件来进行混沌实验,下载地址详见: 。
1. ChaosBlade 安装
本次我们的实际环境是 linux-amd64,下载最新版本 chaosblade-linux-amd64.tar.gz 包,安装步骤如下:
## 下载
wget https://chaosblade.oss-cn-hangzhou.aliyuncs.com/agent/github/0.9.0/chaosblade-0.9.0-linux-amd64.tar.gz
## 解压
tar -zxf chaosblade-0.9.0-linux-amd64.tar.gz
## 设置环境变量
export PATH=$PATH:chaosblade-0.9.0/
## 测试
blade -h2. ChaosBlade 使用
ChaosBlade 安装完成后,仅需要使用 可执行文件即可创建目前所支持的所有场景的混沌实验。首先使用 查看如何使用,选择子命令之后只需要逐层向下使用 即可看到完整的使用案例以及各参数的详细解析,下面我们来演示一下:
1)blade 如何使用
执行 可以查看支持命令有哪些:
An easy to use and powerful chaos engineering experiment toolkit
Usage:
blade [command]
Available Commands:
create Create a chaos engineering experiment
destroy Destroy a chaos experiment
...2)创建实验场景
比如创建 CPU 满载场景,执行 就可以查看具体的场景参数,选择相应参数执行即可:
Create chaos engineering experiments with CPU load
Usage:
blade create cpu fullload
Aliases:
fullload, fl, load
Examples:
# Create a CPU full load experiment
blade create cpu load
#Specifies two random kernel's full load
blade create cpu load --cpu-percent 60 --cpu-count 2
...
Flags:
--blade-release string Blade release package,use this flag when the channel is ssh
--channel string Select the channel for execution, and you can now select SSH
--climb-time string durations(s) to climb
--cpu-count string Cpu count
--cpu-list string CPUs in which to allow burning (0-3 or 1,3)
--cpu-percent string percent of burn CPU (0-100)
...3)恢复实验
ChaosBlade 支持三种方式恢复实验:
ChaosBlade 创建实验成功后会返回一个UID,执行 即可。
如果找不到对应的UID时,执行 即可,例如 。
在创建实验时带上 参数,在实验场景执行十秒后会自动恢复,同时支持表达式,例如三分钟 。
3. SkyWalking 安装&使用
工具部署好之后,下面我们将结合案例,主动出击,通过故障注入,观察系统行为,定位问题并发现系统缺陷,以便构建高可用的微服务系统。
应用容错案例
我们在日常环境部署一个 来进行实验,使用 ab 测试模拟系统请求。微服务应用服务包含前端、购物车、推荐服务、商品、订单等,使用组建包含 Springboot、Nacos、Mysql、Redis、Lettuce、Dubbo 等。ChaosBlade 支持该应用的大部分组件,我们通过 ChaosBlade 来注入混沌实验,验证应用容错能力并且使用 SkyWalking 进行应用监控和问题定位。
1. 案例环境
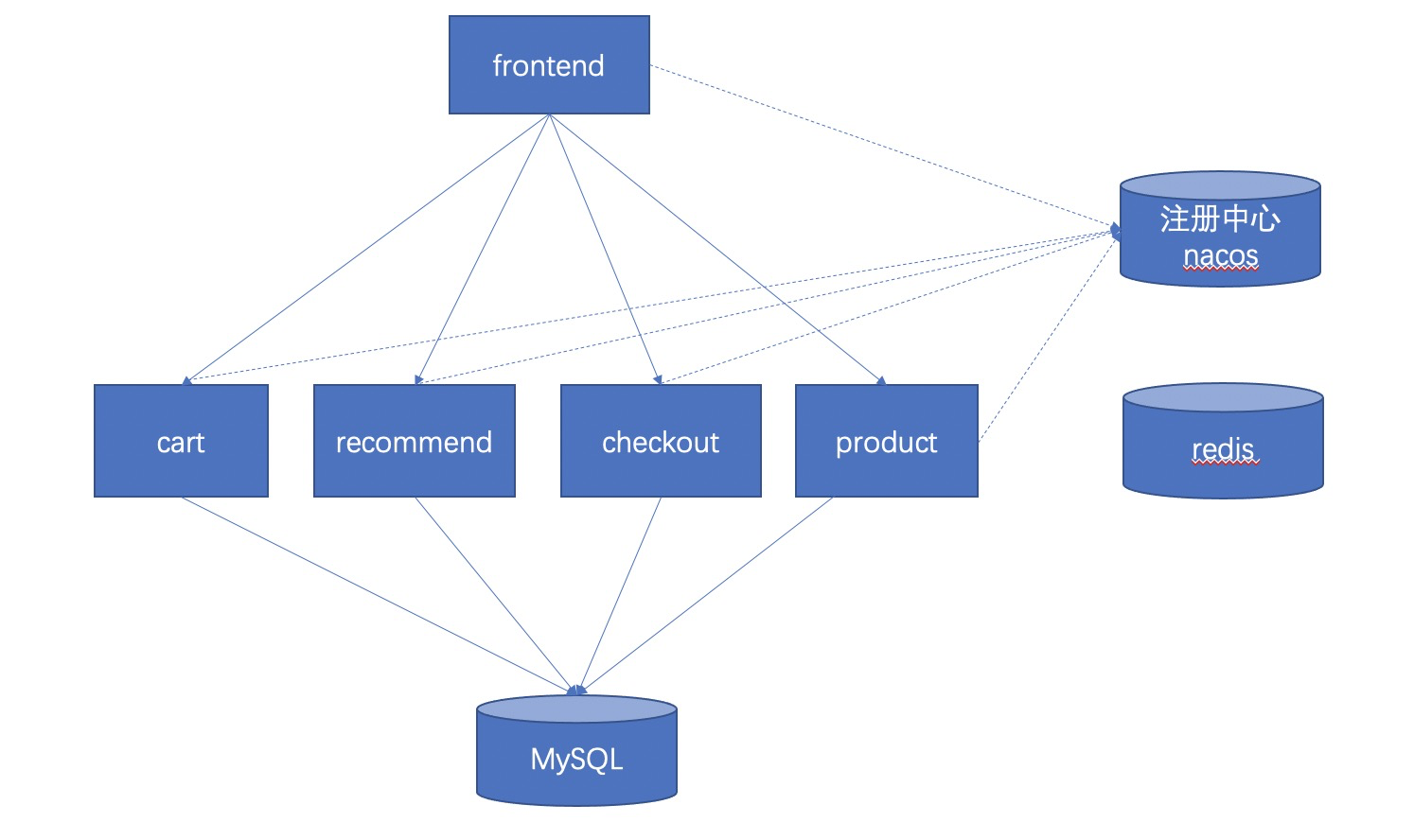
2. 应用拓扑结构
应用的整体架构如下,前端(frontend)对购物车(car)、产品(product)等都是通过 Dubbo 强依赖调用。
3. 混沌实验步骤
制定混沌实验计划
定义系统稳态指标
作出系统容错行为假设
执行混沌实验
检查稳态指标
记录和恢复混沌实验
修复发现的问题
自动化持续进行验证
下面我们将根据混沌实验步骤使用 ChaosBlade 实际进行混沌实验。
4. 案例一
1)场景
制定混沌实验计划,调用下游服务频繁延迟,使用 ab 测试,模拟常态访问购物车接口,开启 2 个线程,进行 10000 次接口访问。
ab -n 10000 -c 2 http://127.0.0.1:8083/cart2)监控指标
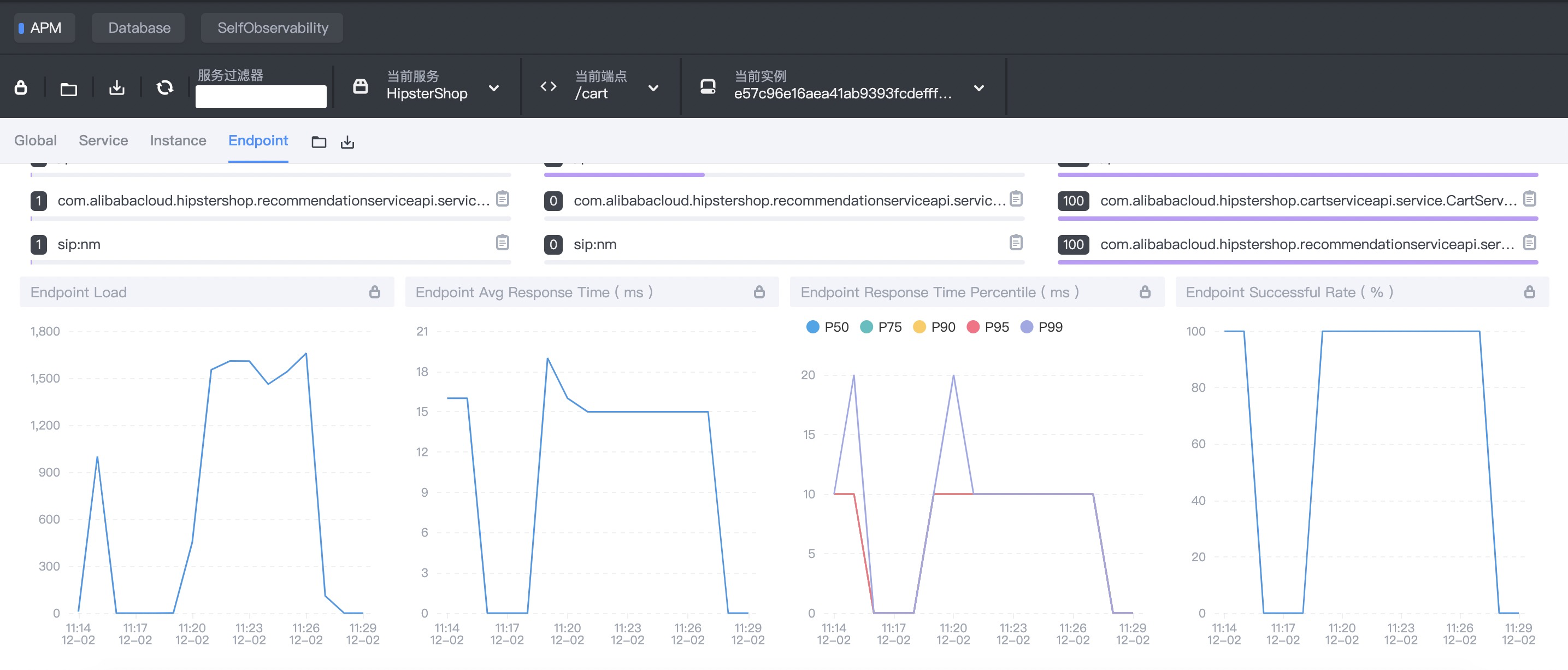
定义系统稳态指标,在 SkyWalking 控制台选择 /cart 端点,稳态指标如下:
平均响应时间(RT)在 15ms 左右。
P99 指标在 20ms 以内。
3)期望假设
配置调用超时时间,不会长时间阻塞客户端请求。
配置服务熔断策略/服务降级。
4)混沌实验
在上节我们已经介绍过 ChaosBlade 的安装和简单实用,本次案例我们使用 ChaosBlade 对下游 Dubbo 购物车服务注入延迟故障(延迟时间 30 秒),执行 命令查看 dubbo 调用延迟的命令用法:
Dubbo interface to do delay experiments, support provider and consumer
Usage:
blade create dubbo delay
Examples:
# Invoke com.alibaba.demo.HelloService.hello() service, do delay 3 seconds experiment
blade create dubbo delay --time 3000 --service com.alibaba.demo.HelloService --methodname hello --consumer
Flags:
--appname string The consumer or provider application name
--consumer To tag consumer role experiment.
--effect-count string The count of chaos experiment in effect
--effect-percent string The percent of chaos experiment in effect
--group string The service group
-h, --help help for delay
--methodname string The method name
--offset string delay offset for the time
--override only for java now, uninstall java agent
--pid string The process id
--process string Application process name
--provider To tag provider experiment
--service string The service interface
--time string delay time (required)
--timeout string set timeout for experiment in seconds
--version string the service version
Global Flags:
-d, --debug Set client to DEBUG mode
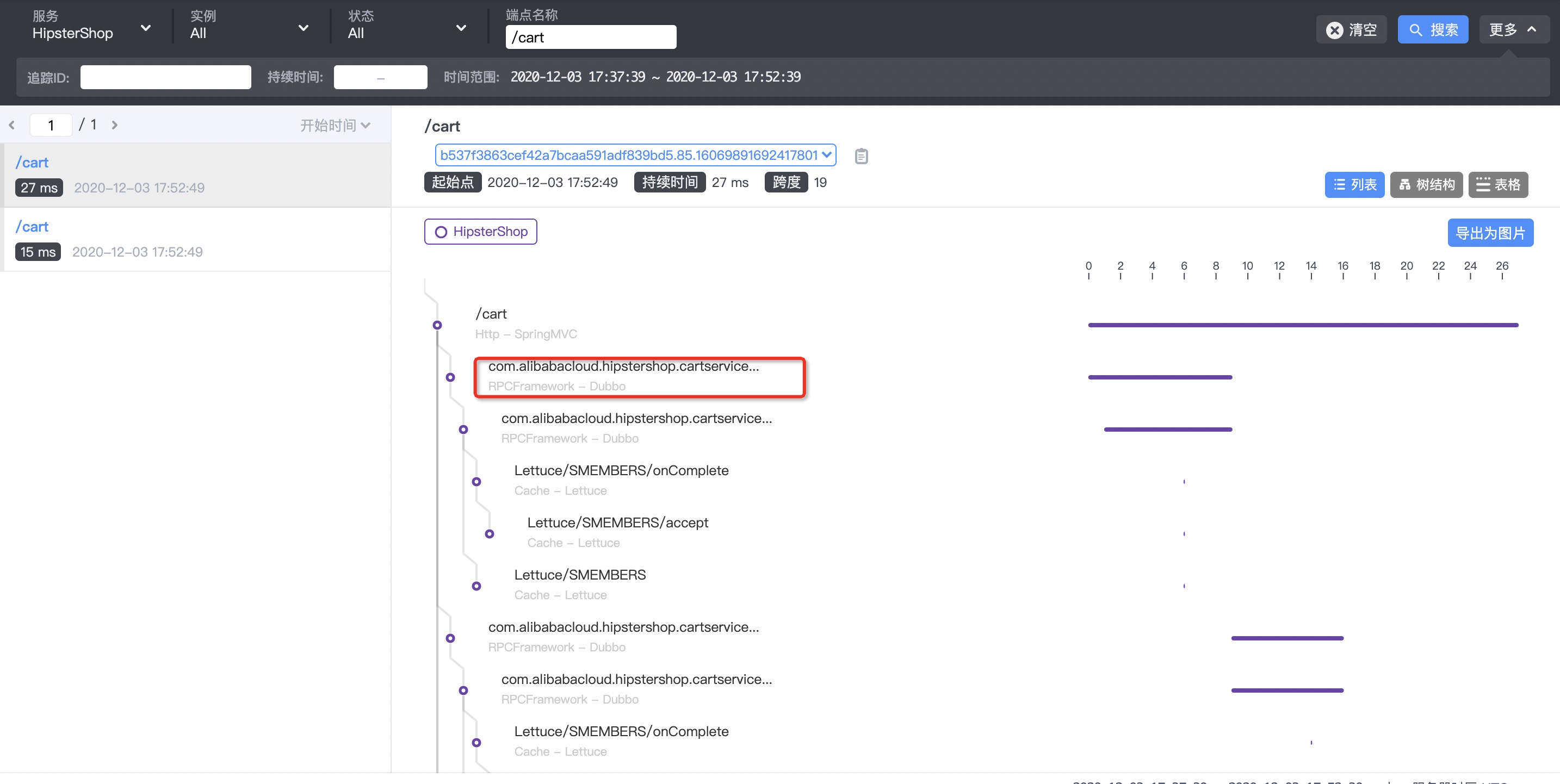
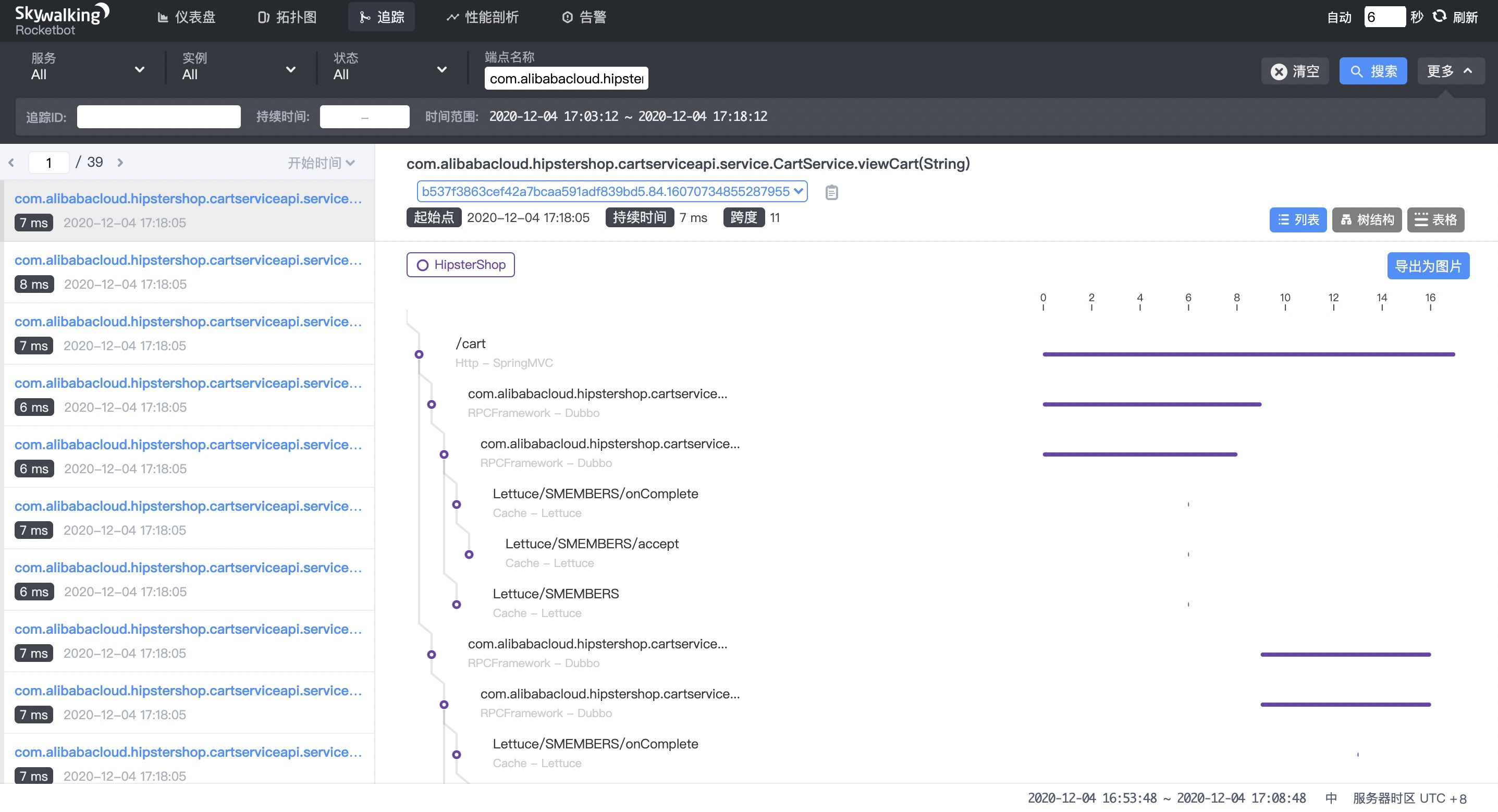
--uid string Set Uid for the experiment, adapt to docker参考案例和参数解释,需要上游服务客户端注入延迟故障(延迟时间 30 秒),借助 SkyWalking 可以很方便找到链路上 Dubbo 服务相关信息,首先查询端点为 /cart 的链路,在链路上找到 Dubbo 服务,如下图:
查找链路
获取协议详细信息
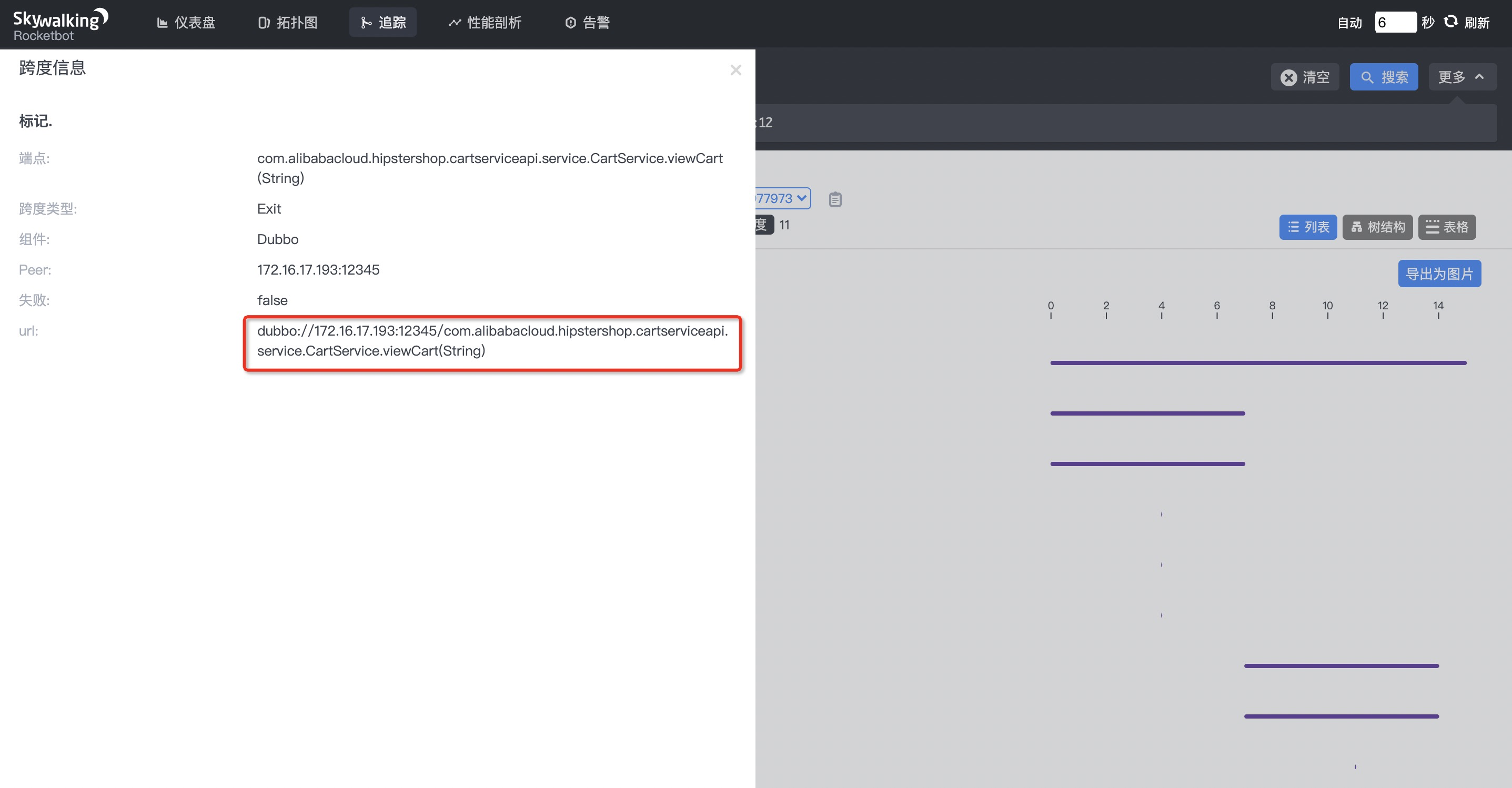
点进来可以查看 Dubbo 服务详细跨度信息,获取 Dubbo 服务的 URL 后,就可以拿到使用 ChaosBlade 来注入上游服务延时所需要的参数,因此我们的最终参数结构为:
延迟30s
服务
服务方法
Java 进程
当前是 Dubbo 服务客户端
下发命令注入故障:
blade create dubbo delay --time 30000 --service com.alibabacloud.hipstershop.cartserviceapi.service.CartService --methodname viewCart --process frontend --consumer5)监控指标
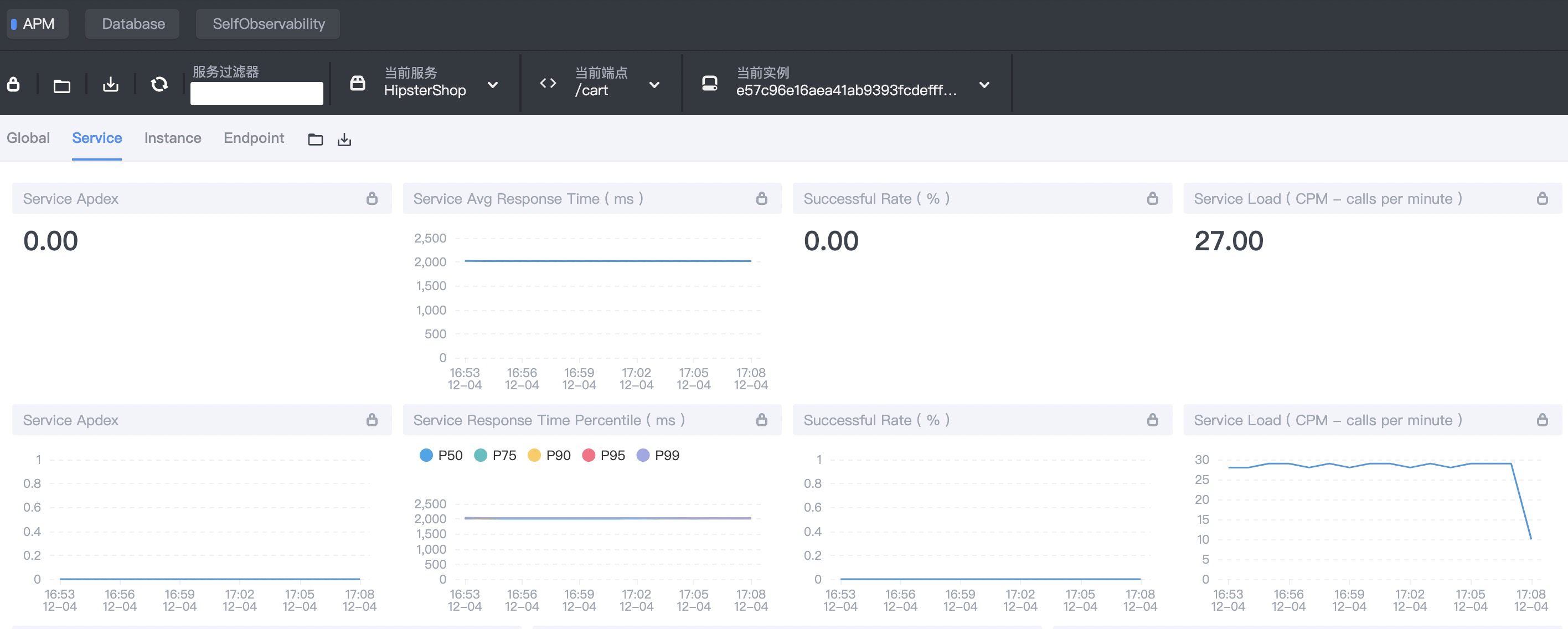
注入故障后检查系统指标,查看 SkyWalking 上的指标:
平均响应时间(RT)在 2000ms 左右,P99 指标在 2000ms 左右
/cart 接口调用报错,com.alibabacloud.hipstershop.cartserviceapi.service.CartService 服务出现异常。

出现 timeout 异常,超时时间为 2000ms
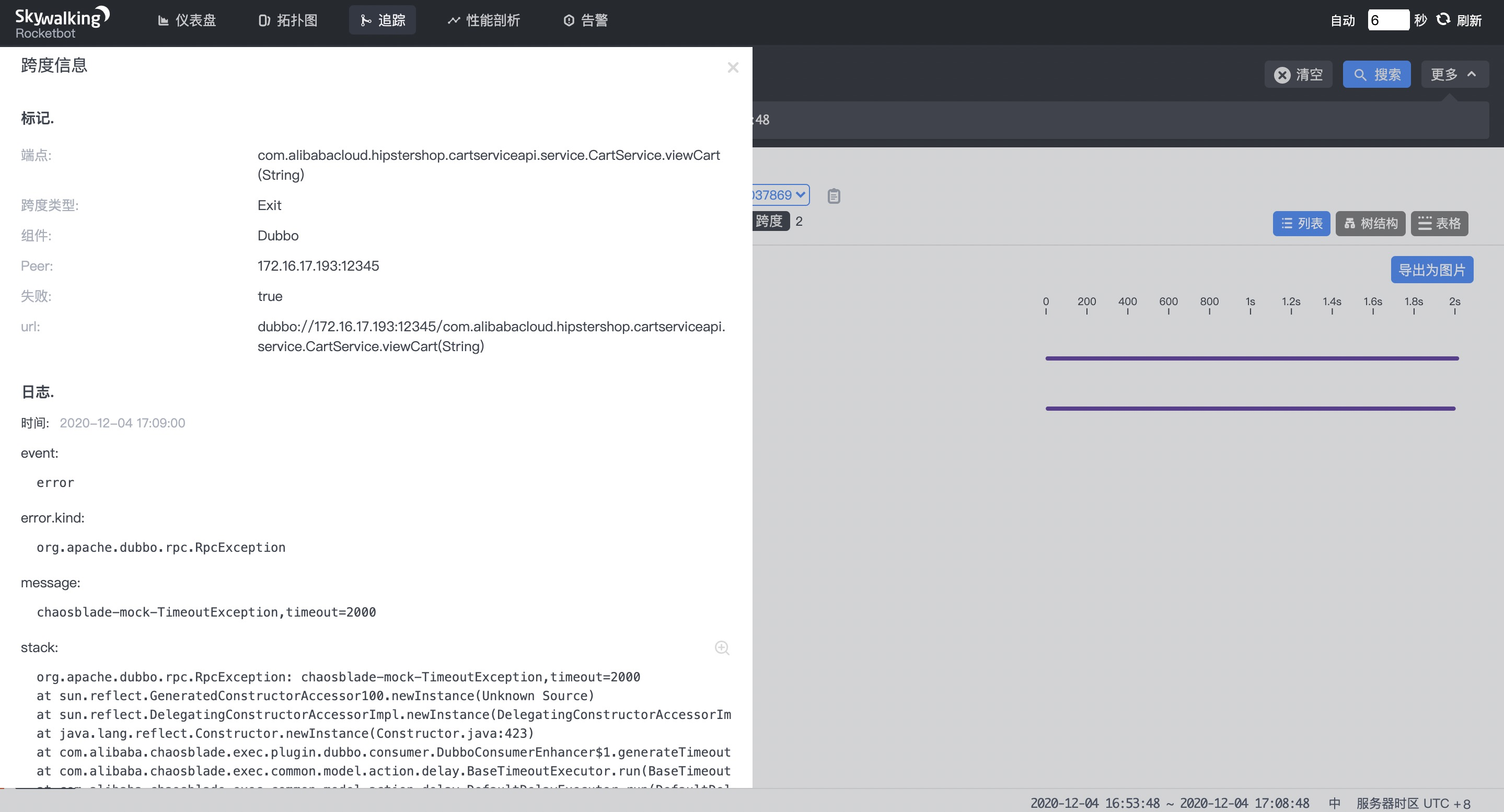
结论说明上游服务配置了调用超时时间,但没有配置服务熔断策略,实际是不符合预期的。

6)修复问题
配置服务熔断策略/服务降级。
5. 案例二
1)场景
运行中 Dubbo 服务提供方访问注册中心失败,在注册中心机器注入故障网络丢包 100%。
2)监控指标
定义系统稳态指标,在 SkyWalking 控制台选择服务端点,稳态指标如下:
com.alibabacloud.hipstershop.cartserviceapi.service.CartService.viewCart 服务正常
3)期望假设
上游服务业务不受影响,下游服务不受影响。
4)混沌实验
对注册中心端口注入丢包故障(100%),我们是使用的 nacos 作为 Dubbo 的注册中心,默认端口 8848,网卡是 eth0,命令参数如下:
网卡
丢包率100%
本地端口 8848
下发命令注入故障:
blade create network loss --interface eth0 --percent 100 --local-port 88485)监控指标
在注入故障后,在 SkyWalking 控制台选择服务端点,稳态指标如下:
com.alibabacloud.hipstershop.cartserviceapi.service.CartService.viewCart 服务正常
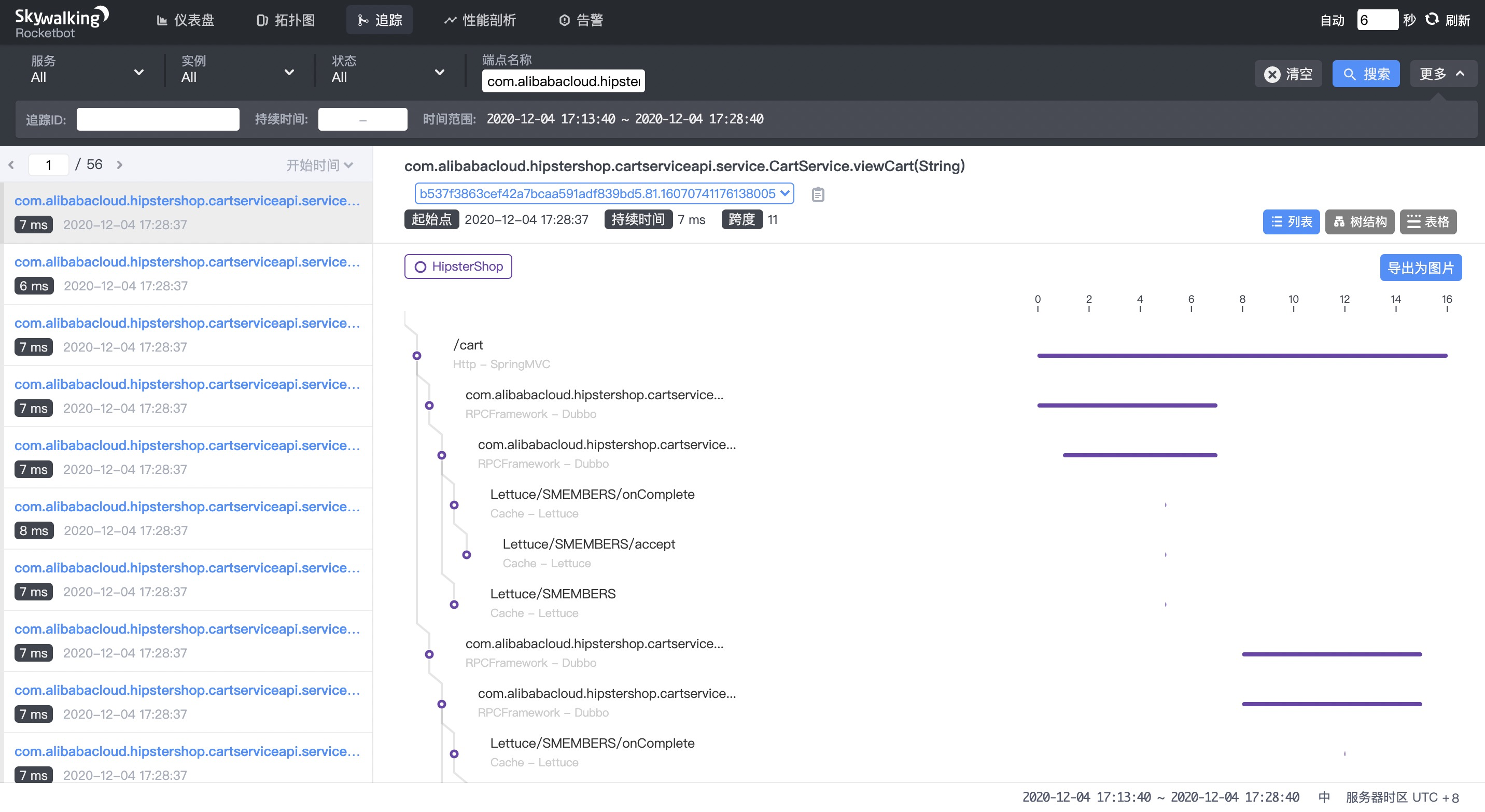
结论:服务对注册中心是弱依赖且服务本身具有本地缓存,符合期望假设。

假设应用现在部署 Kubernetes 集群中,可以增加验证注册中心水平扩容能力,ChaosBlade 同时也支持 Kubernetes 集群场景。
6. 牛刀小试
在上诉案例中,我们验证了服务是否配置了超时和熔断策略,验证了 Dubbo 是否对注册中心是弱依赖且服务本身具有本地缓存。你是否也跃跃欲动,想要在自己系统中体验一把?ChaosBlade 为大家准备了丰富的实验场景,不仅支持基础资源、应用维度,还是云原生平台的一把利器。 ChaosBlade 易于使用,也提供了详细的参数来控制故障最小爆炸半径,相信 ChaosBlade 会让大家非常容易上手。
纸上得来终觉浅,这里我们提供一个额外的小案例,供大家实践。我们在应用开发中经常会与关系数据库打交通,而当应用流量快速增长时,瓶颈往往会在数据库端发生,出现很多慢 SQL。当没有慢 SQL 预警时,我们很难找到原始 SQL 并对它进行优化,所以慢 SQL 预警十分重要。如何验证应用具备这个能力,ChaosBlade 就可以支持注入 MySQL 慢 SQL 故障,执行 查看 MySQL 调用延迟的命令用法:
Mysql delay experiment
Usage:
blade create mysql delay
Examples:
# Do a delay 2s experiment for mysql client connection port=3306 INSERT statement
blade create mysql delay --time 2000 --sqltype select --port 3306
Flags:
--database string The database name which used
--effect-count string The count of chaos experiment in effect
--effect-percent string The percent of chaos experiment in effect
-h, --help help for
--host string The database host
--offset string delay offset for the time
--override only for java now, uninstall java agent
--pid string The process id
--port string The database port which used
--process string Application process name
--sqltype string The sql type, for example, select, update and so on.
--table string The first table name in sql.
--time string delay time (required)
--timeout string set timeout for experiment in seconds
Global Flags:
-d, --debug Set client to DEBUG mode
--uid string Set Uid for the experiment, adapt to docker可以看到 ChaosBlade 提供了完整的案例,支持更细粒度的 SQL 类型,表名等参数。对连接端口时 3306 的 select 操作延时 10s 看看,当流量命中时,是否在你的应用中产生了预警呢?
blade create mysql delay --time 10000 --sqltype select --port 3306命令参数解释:
延时 10s
仅支持 select 类型的 SQL 语句
仅支持端口是 3306 的连接
总结
在本篇文章中,我们介绍了混沌工程在实际复杂分布式架构中的应用,并且结合 ChaosBlade 和 SkyWalking 在实际应用中进行混沌实验,从而可以根据故障的情况来对系统分析优化,持续提升系统的稳定性和高可用能力。ChaosBlade 不仅支持基础资源、应用维度,还是云原生平台的一把利器,欢迎大家尝试使用。
ChaosBlade 项目地址: , 欢迎大家加入,一起共建!点击查看[贡献指南](https://github.com/chaosblade-io/chaosblade/blob/master/CONTRIBUTING.md)。
作者信息
叶飞:Github @tiny-x,开源社区爱好者,ChaosBlade Committer,参与推动 ChaosBlade 混沌工程生态建设。