Kafka设计实现与最佳实践之客户端篇
开场

大家好,我是欧二强,在公司主要负责基础架构组,我相信在坐的各位或多或少的都有基础架构打过交道,后续大家有什么疑问或者有什么建议都可以随时给我反馈。
提纲
我这次分享到内容是关于Kafka的,会分为两场进行,毕竟内容比较多,第一场就是与大家关系紧密的客户端方向。我们本次培训分享分为3个提纲:
MQ与Kafka的简介
Kafka生产者
Kafka消费者
MQ与Kafka的简介
MQ概述

我们现在先进入到第一章:MQ与Kafka的简介
我们先认识一个概念MQ是什么?
消息中间件属于分布式系统中的重要的组件,关注于数据的发送和接收,利用高效可靠的消息传递机制对分布式系统中的其余各个子系统经进行集成。
换句话说,MQ就是分布式系统中的桥。
MQ发展历程
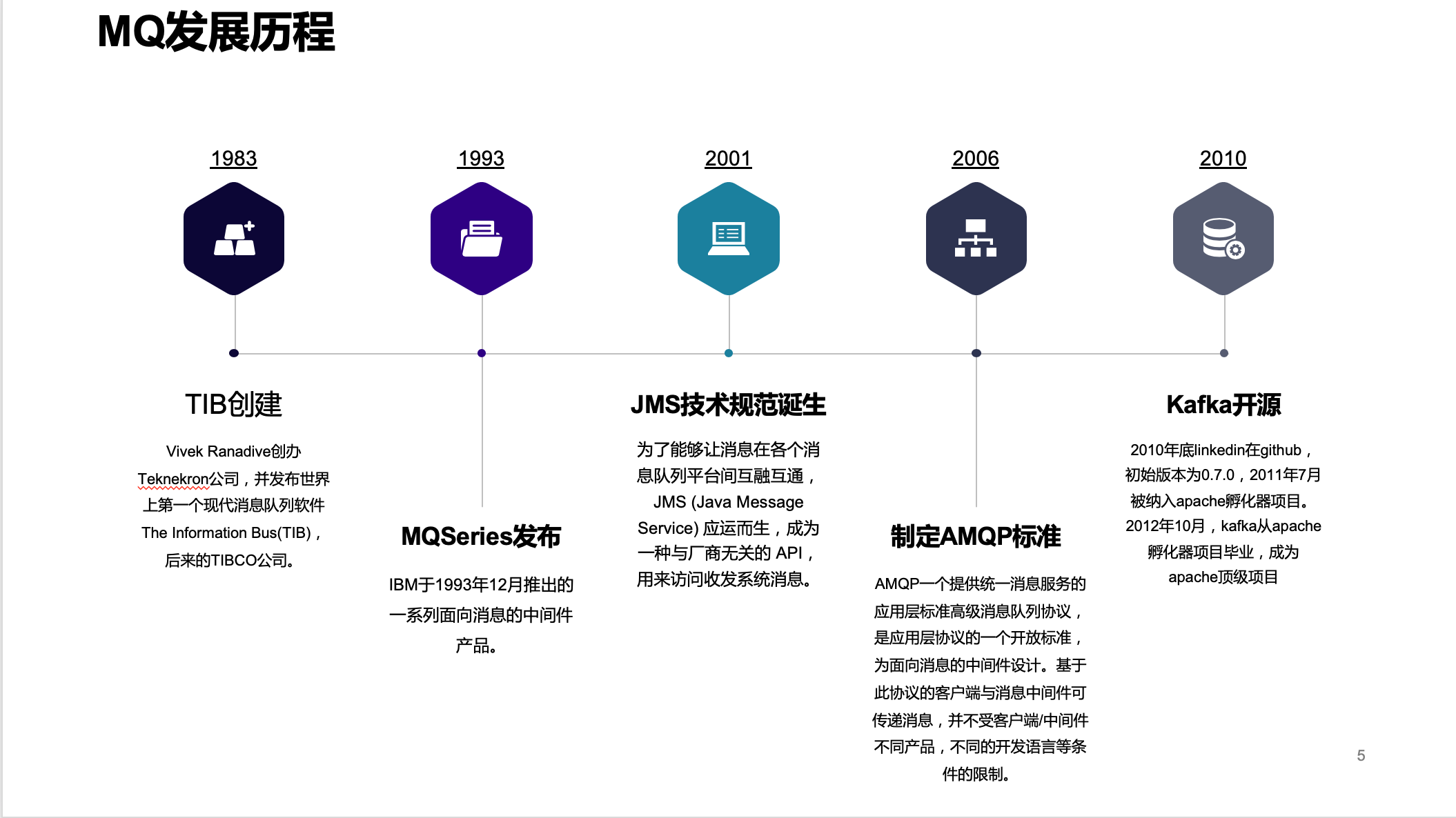
我们来看看这座桥的历史。话说1983年一个印度哥哥Vivek Ranadive创办Teknekron公司,并发布世界上第一个现代消息队列软件The Information Bus(TIB),后来的TIBCO公司。这是一家拥有30多年的老牌中间件公司了,是时间上最大的独立业务整合软件公司,也是实时业务解决方案提供商,在纯软件公司全球排第18位。
看着TIBCO生意做的风风火火的,"蓝色巨人"IBM眼红了,IBM于1993年12月推出的一系列面向消息的中间件产品--MQSeries。越多越多的公司加入战局,一时间MQ市场风云涌动,正所谓专利保护,美国太贪,中国太慢。各个公司研发的MQ是不兼容的,互有壁垒,一家公司了上了贼船,就很难再下来了。
为了打破这个壁垒,同时为了能够让消息在各个消息队列平台间互融互通。sun公司站了出来发布了JMS (Java Message Service) ,成为一种与厂商无关的 API,用来访问收发系统消息。各大公司各个MQ中间件纷纷响应支持:
的[Java消息库](http://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/jmsclient.html)
,使用[AMQP](https://en.wikipedia.org/wiki/AMQP) \[[17\]](https://en.wikipedia.org/wiki/Java
Message Service#cite_note-17)的服务集成总线(SIBus)\[[18\]](https://en.wikipedia.org/wiki/Java
Message Service#cite_note-18)和[HornetQ的](https://en.wikipedia.org/wiki/HornetQ)从[JBoss的](https://en.wikipedia.org/wiki/JBoss_(company))
JMS在企业平台混得风生水起,在Java平台战无不胜,但是需要看到随着计算机技术的发展,跨平台跨语言的需要日日旺盛。2006 年 6 月,由 Cisco 、 Redhat 、iMatix 等联合制定了 AMQP 的公开标准,由此 AMQP 登上了历史的舞台 。它是应用层协议的一个开放标准,以解决众多消息中间件的需求和拓扑结 构问题 。它为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受 产品、开发语言等条件的限制 。
正所谓天下大势,分久必合。合久必分。2010年底linkedin在github,初始版本为0.7.0,Kafka设计之初就不支持AMQP,阿里的RocketMQ亦是如此。
MQ的作用

那么MQ有什么作用的呢?去年的培训我椰油说过这一页的内容,今年为了内容的完整性,我继续说一遍。
解耦:消息队列在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
异步:消息队列提供了异步处理机制,允许把一个消息放入队列,但并不立即处理它。
削峰:使用消息队列能够使关键组件顶住增长的访问压力,而不是因为超出负荷的请求而完全崩溃。
冗余:消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。
缓冲:消息队列通过一个缓冲层来帮助任务最高效率的执行--写入队列的处理会尽可能的快速,而不受从队列读的预备处理的约束。
扩展性:消息队列解耦数据处理过程,只需增大消息入队和处理的频率。
送达保证:除非消费端明确的表示已经处理完了这个消息,否则这个消息会被放回队列中去,在一段可配置的时间之后可再次被处理。
可恢复:消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
顺序保证:消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。
数据流:数据流内部数据通讯也是依赖消息队列。
MQ的副作用
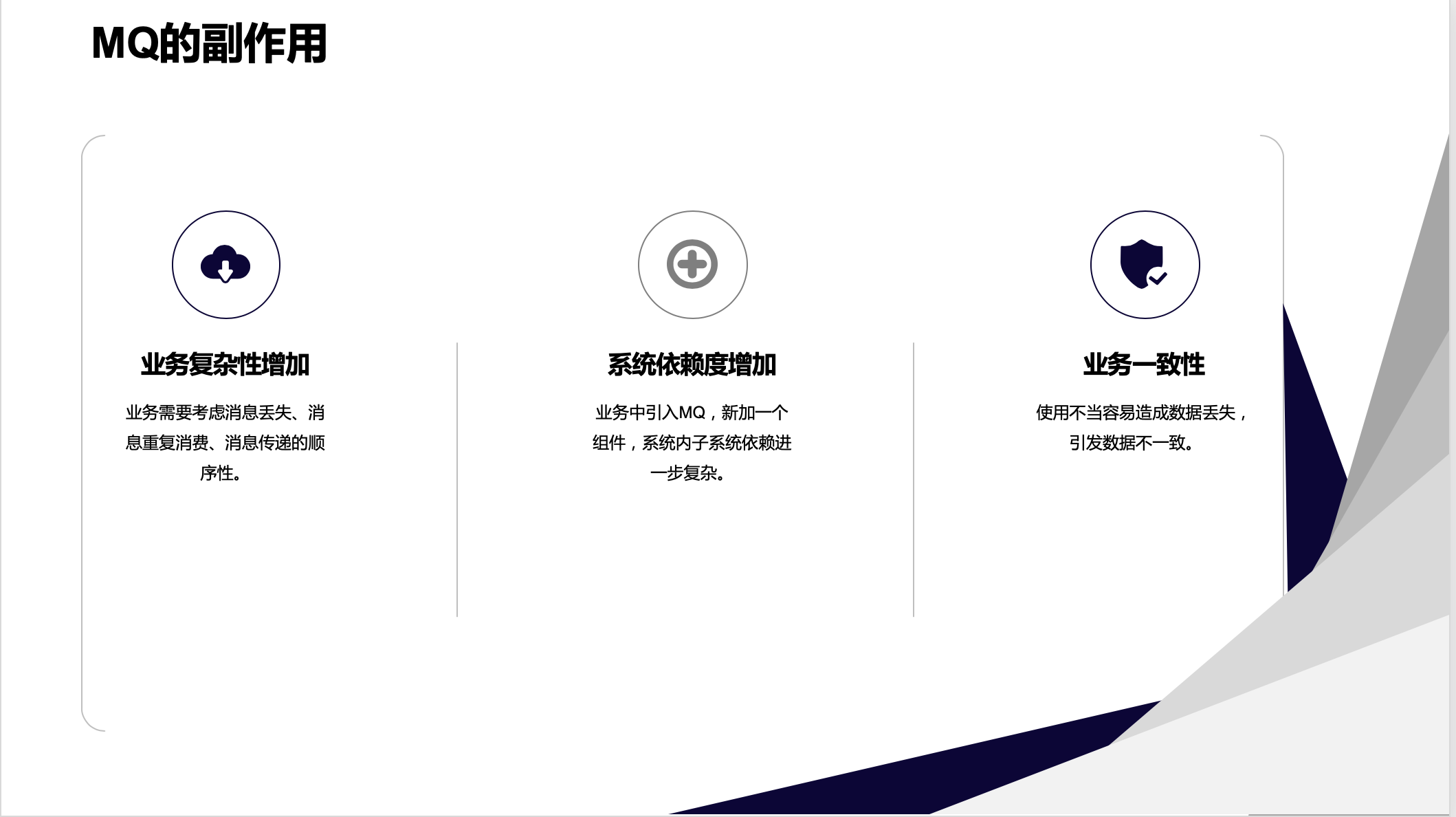
对一个事务不能直说好处,也需要说说它的副作用。MQ的副作用有:
业务复杂性增加:业务需要考虑消息丢失、消息重复消费、消息传递的顺序性。
系统依赖度增加:业务中引入MQ,新加一个组件,系统内子系统依赖进一步复杂。
业务一致性:使用不当容易造成数据丢失,引发数据不一致。
MQ关注点
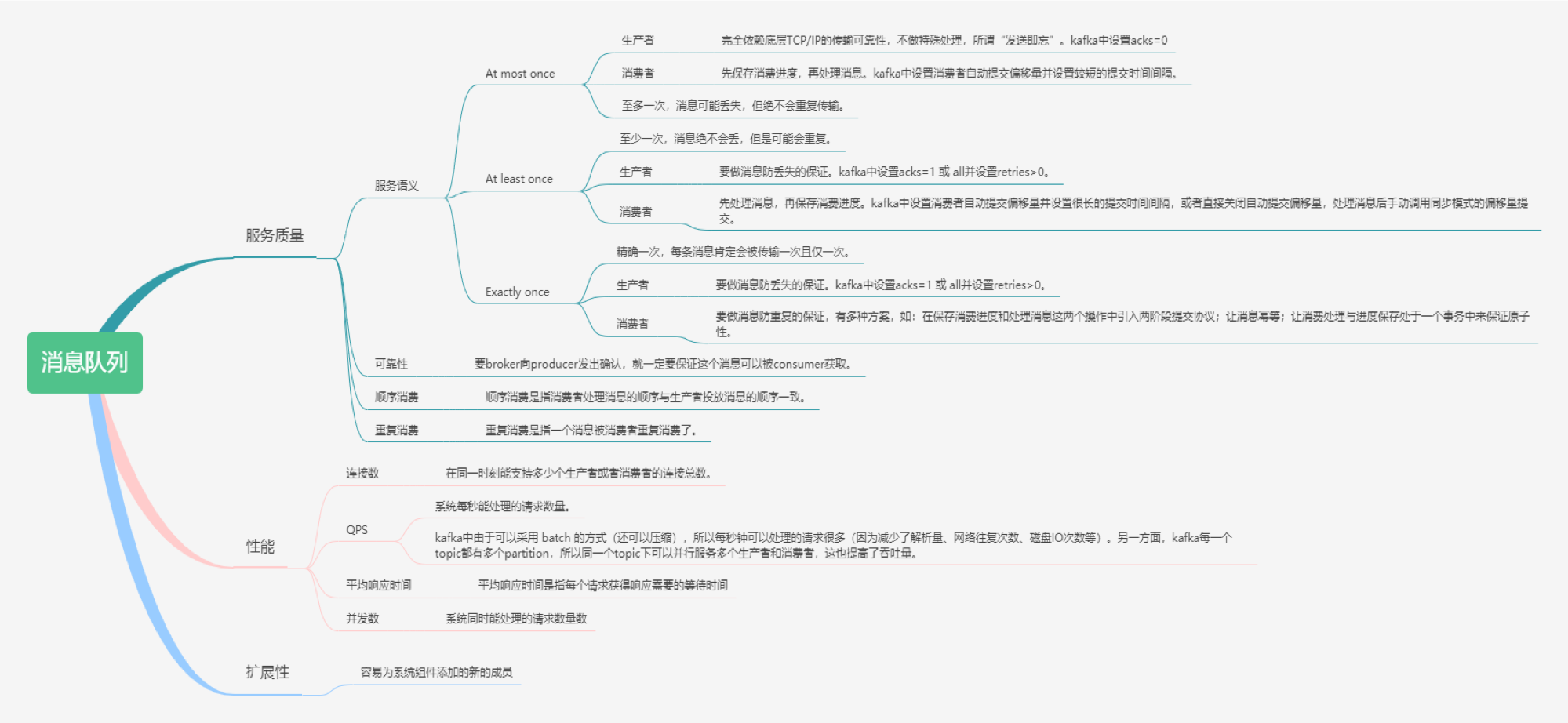
不论是MQ选型还是实现MQ我们都需要关注这些点,脑图已经很详细的解说了,我就挑选几个很少人注意到的来说说。 服务质量,真所谓宁吃好瓜一口,不要烂瓜一筐。 只要用到消息的场景都是需要关注服务语义。
有至多一次,消息可能丢失,但绝不会重复传输。
至少一次,消息绝不会丢,但是可能会重复。
精确一次,每条消息肯定会被传输一次且仅一次。
连接数这里需要多讲一些,后续我们见到生产者与消费者的设计实现的时候就会体现出连接数的优化点。
各个MQ对比
这些MQ大家都可以看看,只是作为一个扩展知识来即可。我们主要还是在使用Kafka。
| 对比项 | Kafka | ActiveMQ | RabbitMQ | RocketMQ |
| --- | --- | --- | --- | --- |
| 开发语言 | Scala/Java | Java | Erlang | Java |
| 协议支持 | Pull,自定义 | Push,JMS | Pull and Push,AMQP | Pull,JMS、MQTT,自定义 |
| 事务支持 | 0.11.0后支持 | 支持 | 支持 | 支持 |
| Producer容错 | ACK模型 | 失败重试 | ACK模型 | ACK模型 |
| 吞吐量 | 百万 TPS | 万级 TPS | 万级 TPS | 20w TPS |
| 时效性 | ms | ms | us | ms |
| 可用性 | 非常高(分布式架构) | 高(主从架构) | 高(主从架构) | 非常高(分布式架构) |
| 持久性 | 支持 | 支持 | 支持 | 支持 |
| 客户端支持 | 大部分主流的语言 | 大部分主流的语言 | 大部分主流的语言 | Java、Python、Go |
| 宕机恢复 | 自动选主 | 自动选主 | 镜像队列自动选主 | v4.5开始支持自动选主 |
| 使用场景 | 大数据日志处理 | 在线业务场景 | 在线业务场景 | 在线业务场景 |
kafka设计目标
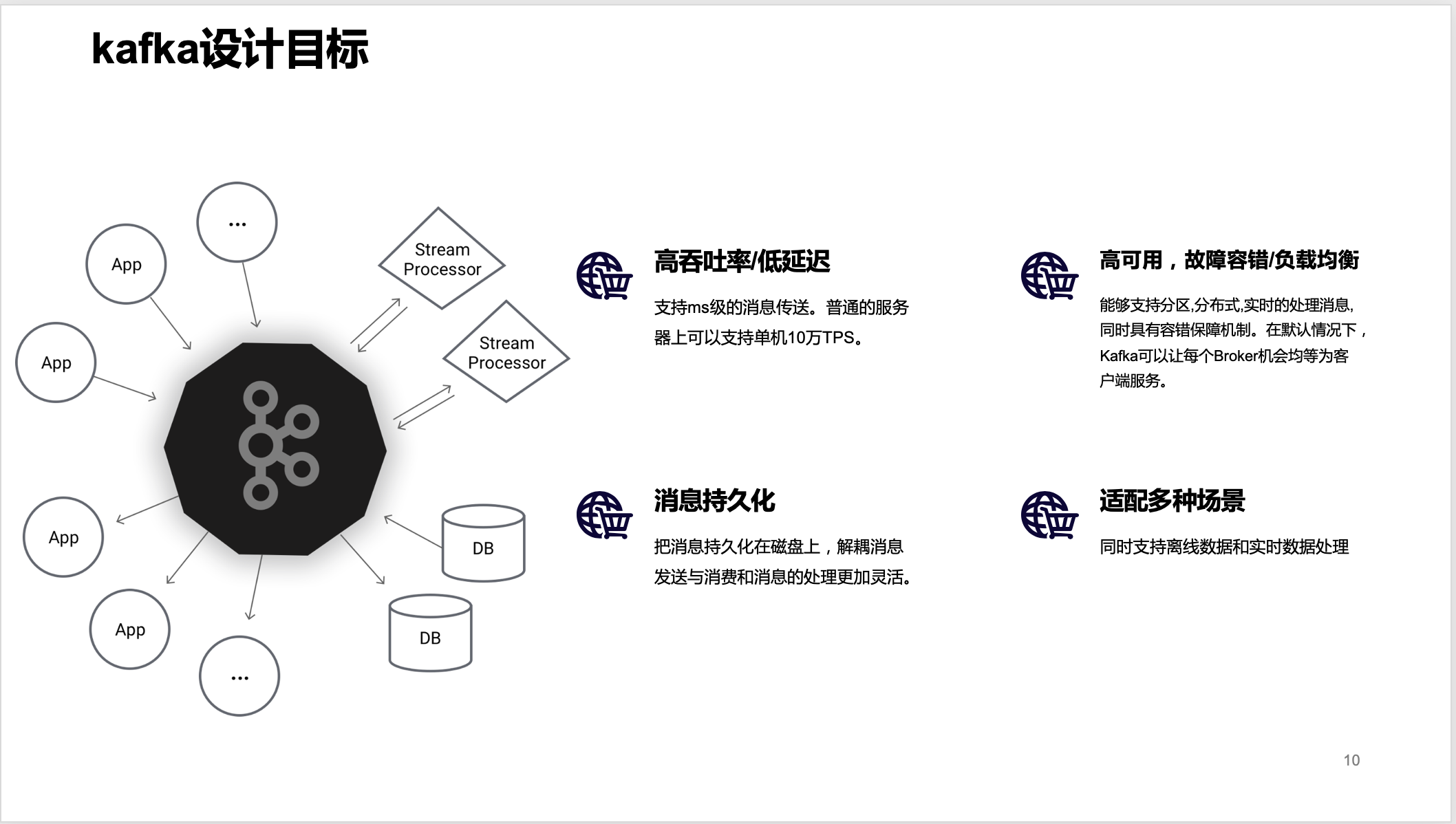
kafka立项之初也是有自己的目标,之后讲到的Kafka种种机制都是围绕着这些目标进行。
高吞吐率/低延迟:支持ms级的消息传送。普通的服务器上可以支持单机10万TPS。 高吞吐率是指每秒能够处理的消息或者每秒能够处理的字节数。
低延时表示客户端发起请求与服务端处理请求并发送响应给客户端的时间差。
高吞吐率/低延迟,这是一对矛盾体,一般都反比关系,一个指标好了,另一个指标会下降。
高可用,故障容错/负载均衡:能够支持分区,分布式,实时的处理消息,同时具有容错保障机制。在默认情况下,Kafka可以让每个Broker机会均等为客户端服务。
消息持久化:把消息持久化在磁盘上,解耦消息发送与消费和消息的处理更加灵活。
适配多种场景:同时支持离线数据和实时数据处理
Kafka基本概念

想要了解Kafka就需要提前了解到Kafka的一些基本概念,挺多的名词,不过我相信大家使用Kafka这么久了,很多名词都是听说过的。
Zookeeper :管理 Kafka 集群中的 broker和Topic注册,还负责生产者负载均衡;
Broker: Kafka 服务 部署的一个节点,一个 Kafka 集群( Kafka Cluster )会有多个节点(broker);
Topic:一个逻辑概念,代表一类消息,也可以认为消息被发送到的地方,是消息的分类;
Partition:从把存储上可以分区看做Topic的日志文件,每一个分区都是一个有序的、不可变的记录序列,新的消息只会不断追加到提交日志。
Offset:Partition中的每条消息都会按照时间顺序分配到一个单调递增的顺序编号,该编号可以唯一的定位当前分区的每一条消息;
Replica:副本,同一个分区的不同副本保存相同的消息(在同一时刻,副本之间并非完全一致)副本之间是一主多从关系,leader副本负责读写请求,follower只负责同步leader副本的消息。
Producer:生产者,就是发送消息的一端;
Consumer:消费者,就是接收消息的一端;
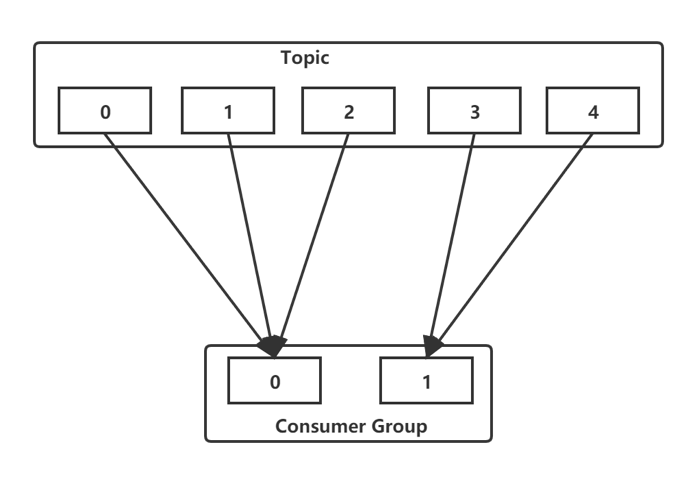
Consumer Group:消费者使用一个消费者注明来标记自己,Topic的每一条消息都只会被发送给每一个订阅他的消费者组的一个消费者实例。
Kafka架构
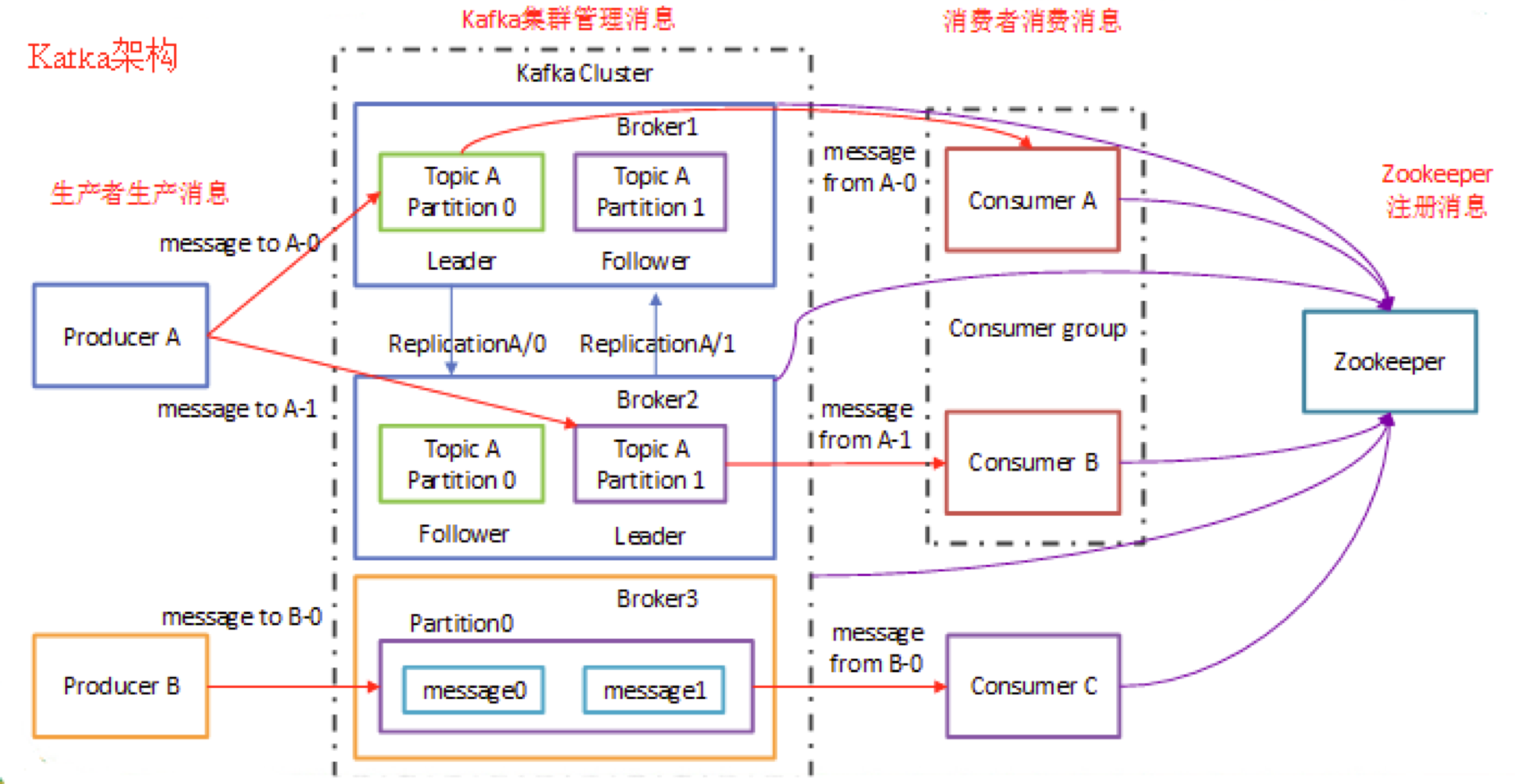
这是一张别人画的图,我觉得很好,就拿来使用了。这张图清晰地表明了之前地各个概念之间地关系,当然这个图仅仅是显示除了Kafka地消息模型地,如果是再加上流式数据平台模型,那就不是这样了。
从图中我们可以将Kafka架构分为四部分:生产者、Kafka集群、消费者和ZK。我们更需要关注地是生产者和消费者与Topic、分区地关系。
Kafka模型
分区模型
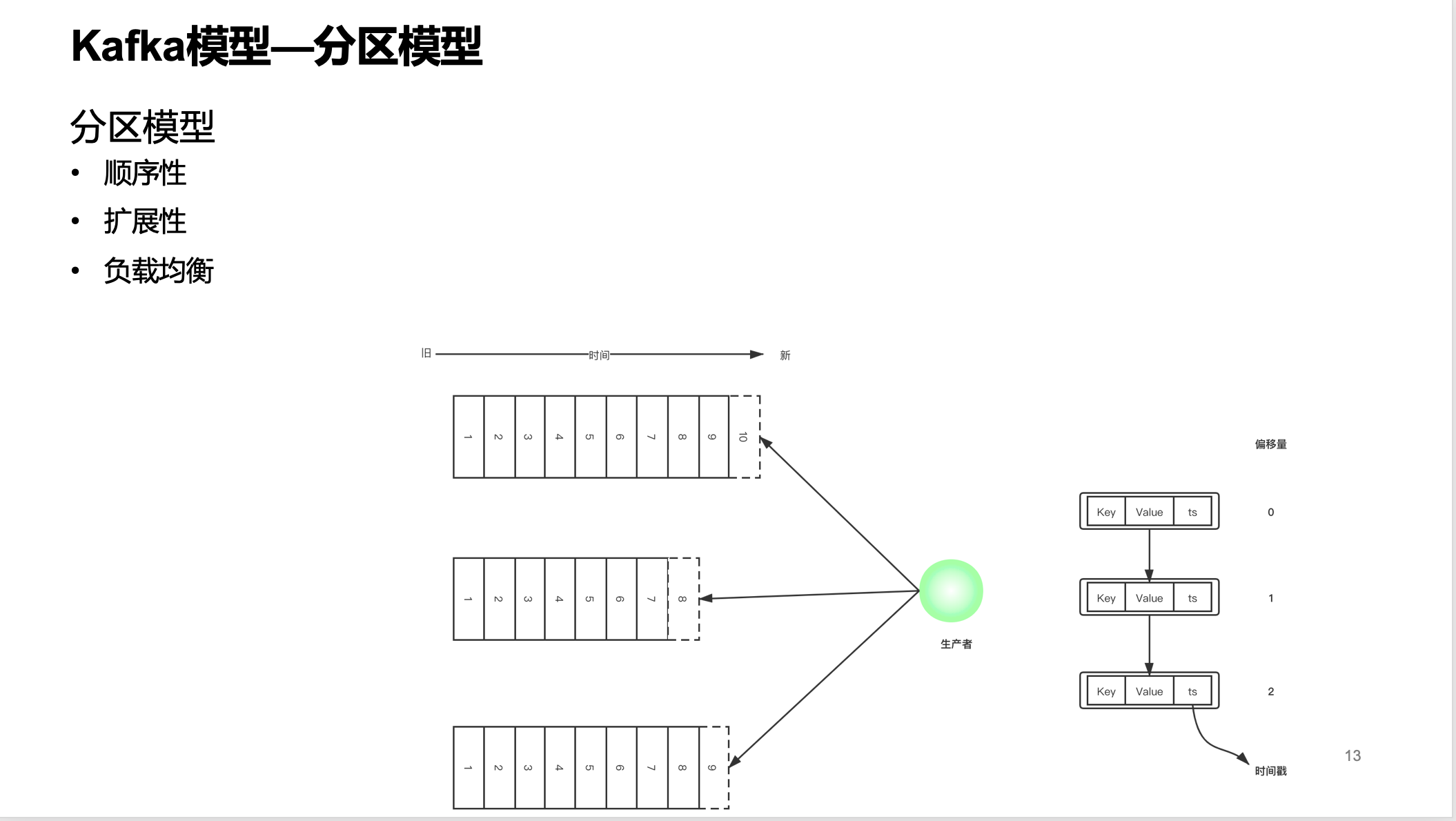
分区模型也可以称为并发模型,Kafka的并发度是基于分区来实现的。分区模型提供了三个功能:
顺序性
扩展性
负载均衡
顺序性可以通过kafka服务端、生产者和消费组这3个方面来解释。Kafka集群为每一个Topic维护分布式地分区日志文件,这是物理物理文件。每一个分区都是有序地、不可变地消息序列,新的消息只会追加提交到日志文件。分区内的每条消息都会按照时间顺序分配到一个单调递增地序列id,称为偏移量,Offset。这个偏移量可以唯一定位到这条记录。
从图中可以看到生产者往一个Topic的多个分区写入消息,因为给不同的分区写入的消息量不一样,所以在某一些时刻各个分区的Offset是不一样的。还可以看到这个消息的大致结构,有key、value还有时间戳。
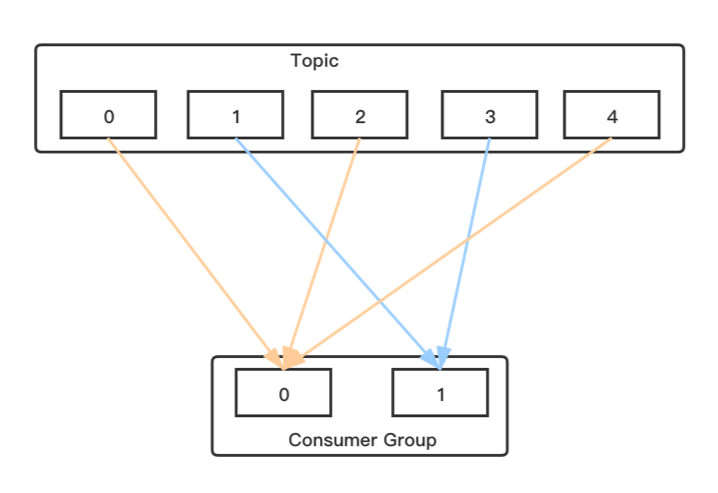
Kafka使用Topic的分区作为消息处理的并行单元。kafka以分区作为最小的粒度,将每个分区分配给消费组中不同的而且是唯一的消费者,并确保一个分区只属于一个消费者,即这个消费者就是这个分区的唯一读取线程。那么,只要分区的消息写入和存储都是有序的,消费者处理的消息顺序就有保证,每个主题有多个分区,不同的消费者处理不同的分区,所以kafka不仅保证了消息的有序性,也做到了消费者的负载均衡。
扩展性就好理解了,在一定分区数阈值内,增加分区数是可以提升性能的。
消费模型
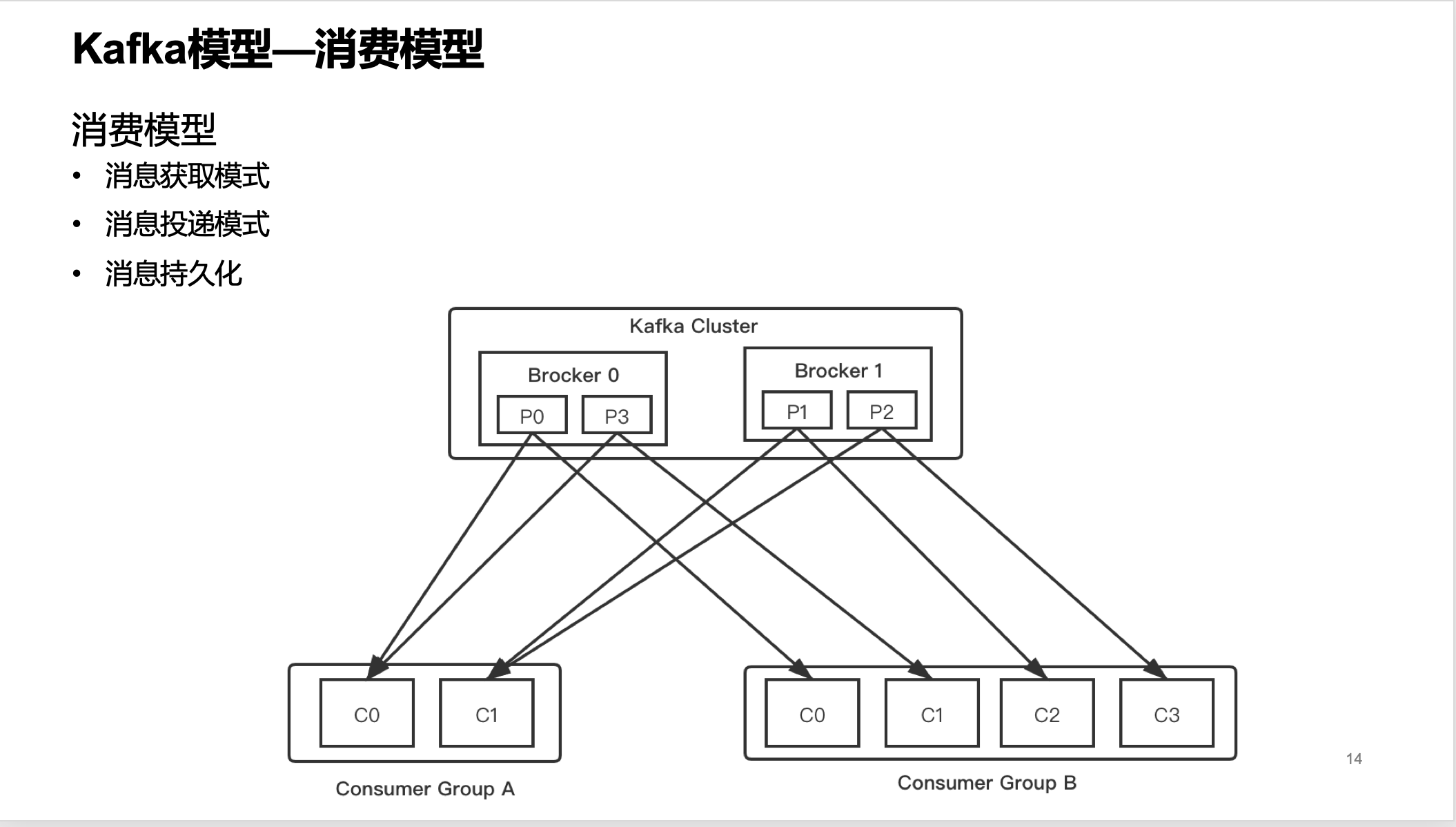
消费模型这里提供了功能:
消息获取模式
消息投递模式
消息持久化
前两种后续会有讲解,我们说说消息持久化。消息追加写入到分区日志文件后,就会被持久化下来,只要还在有效期内,消费者就可以多次读取。
分布式模型
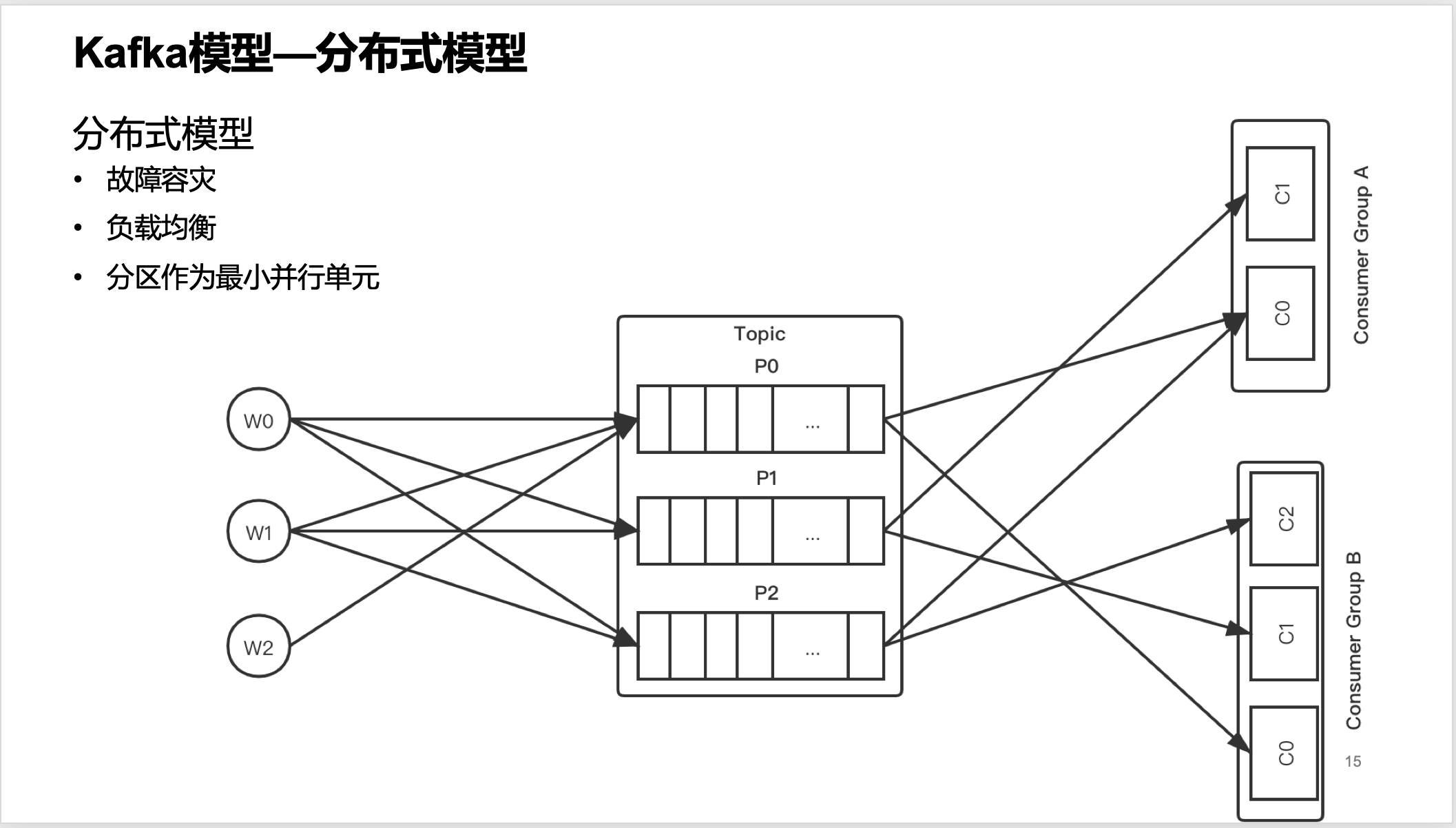
分布式模型提供了:
故障容灾
负载均衡
分区作为最小并行单元
Kafka每个主题的多个分区日志分布式地存储在Katka集群上,同时为了故障容错,每个分区都会以副本的方式复制到多个消息代理节点上。其中一个节点会作为主副本(Leader ),其他节点作为备份副本(Follower,也叫作从副本),主副本会负责所有的客户端读写操作,备份副本仅仅从主副本同步数据。当主副本出现故障时,备份副本中的一个副本会被选择为新的主副本。因为每个分区的副本中只有主副本接受读写,所以每个服务端都会作为某些分区的主副本,以及另外一些分区的备份副本,这样Kafka集群的所有服务端整体上对客户端是负载均衡的。 生产者客户端发布消息到服务端的指定主题,会指定消息所属的分区。生产者发布消息时根据消息是否有键,采用不同的分区策略。消息没有键时,通过轮询方式进行客户端负载均衡;消息有键时,根据分区语义确保相同键的消息总是发送到同一个分区。 Katka的消费者通过订阅主题来消费消息,并且每个消费者都会设置一个消费组名称。因为生产者发布到主题的每一条消息都只会发送给消费组的一个消费者。所以,如果要实现传统消息系统的“队列”模型,可以让每个消费者都拥有相同的消费组名称,这样消息就会负载均衡到所有的消费者;如果要实现“发布-订阅”模型,则每个消费者的消费组名称都不相同,这样每条消息就会广播给所有的消费者。
kafka生产者
三种发送方式
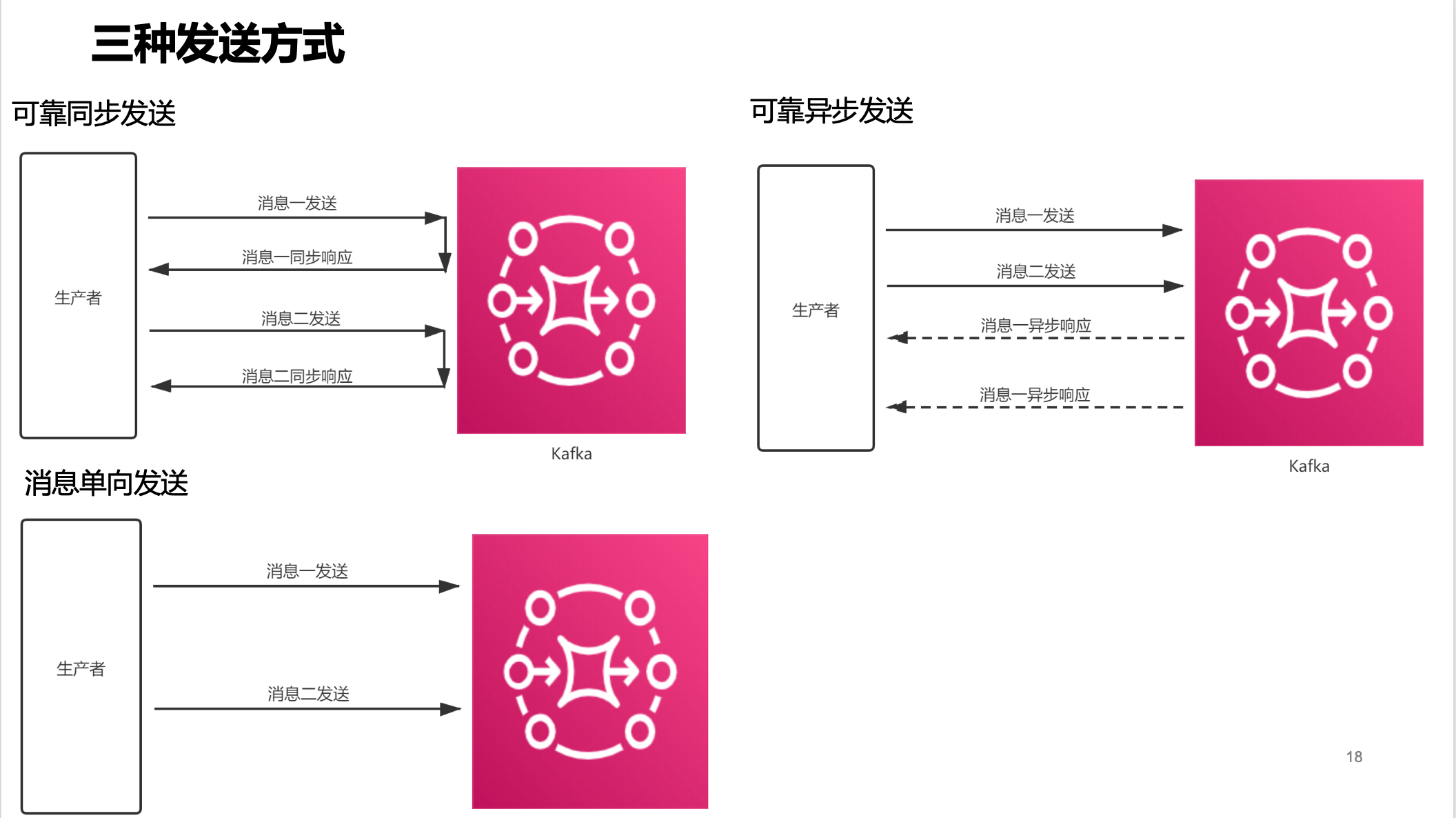
Kafka提供了三种发送方式:
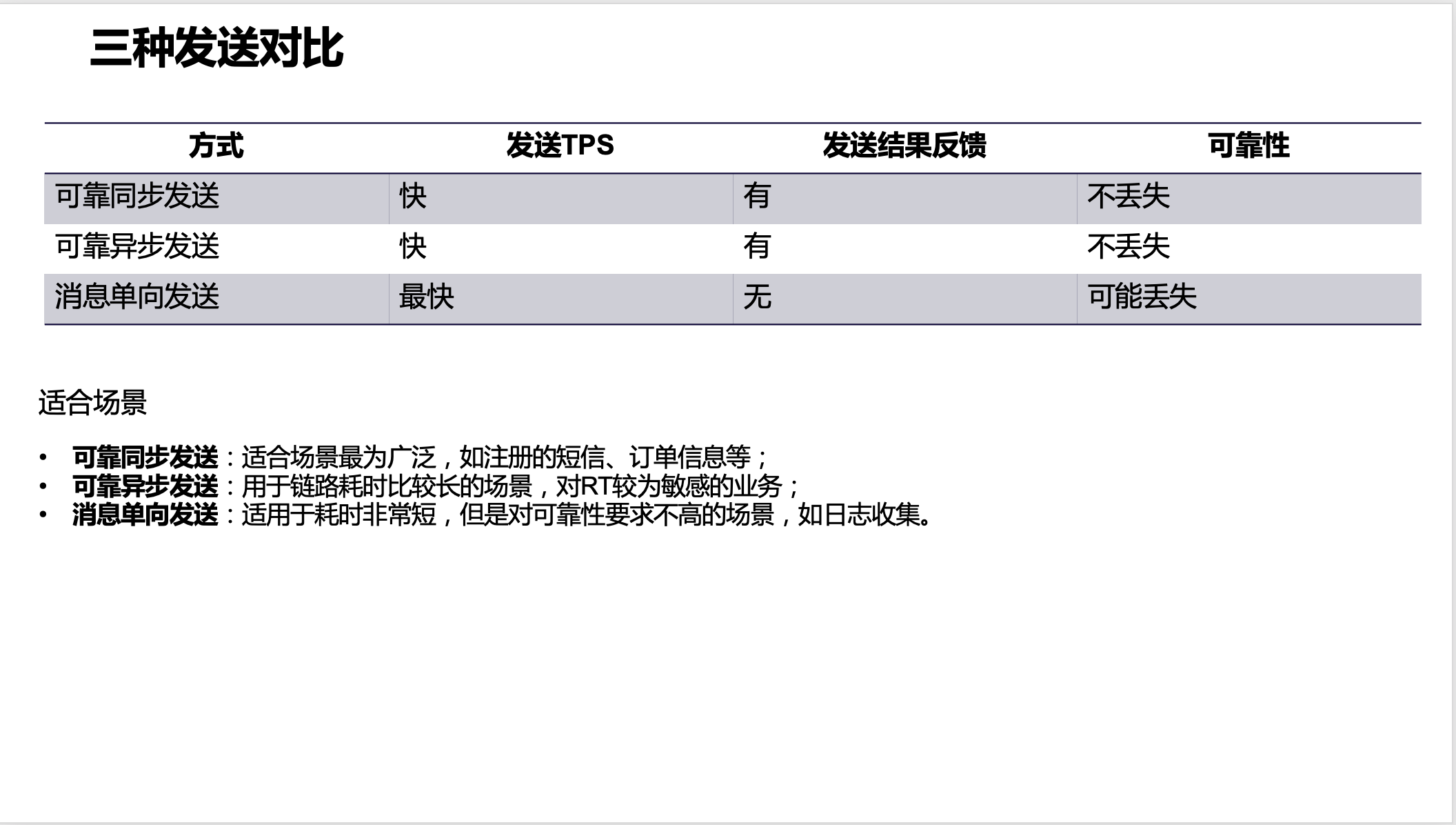
可靠同步发送:适合场景最为广泛,如注册的短信、订单信息等;
可靠异步发送:用于链路耗时比较长的场景,对RT较为敏感的业务;
消息单向发送:适用于耗时非常短,但是对可靠性要求不高的场景,如日志收集。
sarama生产者
我们本次的分析都是基于sarama 1.26.1进行,生产者示例代码:
func AsyncProducter() {
mqConfig := sarama.NewConfig()
mqConfig.Version = sarama.V1_1_0_0
mqConfig.Producer.Return.Successes = true
mqConfig.Producer.RequiredAcks = 1 // OR -1
producer, err := sarama.NewAsyncProducer([]string{"10.1.0.107:9093"}, mqConfig)
if err != nil {
log.Errorf("NewSyncProducer=%v", err)
return
}
go func() {
for {
select {
case su := <-producer.Successes():
log.Printf("Successes:%v", su)
case err := <-producer.Errors():
log.Printf("Errors:%v", err)
}
}
}()
for i := 0; i < 2; i++ {
now := time.Now()
msg := &sarama.ProducerMessage{
Topic: "dedao_ddkafka_test_01",
Key: sarama.StringEncoder(fmt.Sprintf("Key-%d", i)),
Value: sarama.StringEncoder(fmt.Sprintf("Hello World!_%v", now)),
}
producer.Input() <- msg
log.Printf("i=%v , err=%v ,now=%v\n", i, err, now)
}
}
sarama生产者函数链路
sarama使用还是挺简单的,但是里面的调用链非常复杂。看看这个链路就知道了。
看这个图,我们把它分为四个链路进行拆分,从上到下来解释一下:
第一条链路:初始化client,获取kafka集群的元数据信息,这个请求期间出现失败就会重试;
第二条链路:根据分区分配规则,确定需要发送消息的分区位置;
第三条链路:该链路室真实发送消息的链路,根据消息确认的分区和kafka集群元数据确定消息对应的broker,将相同分区的消息聚合成为ProducerSet,再进行BrokerProducer发送。
第四条链路:如果设置失败重试就会有进行重试。
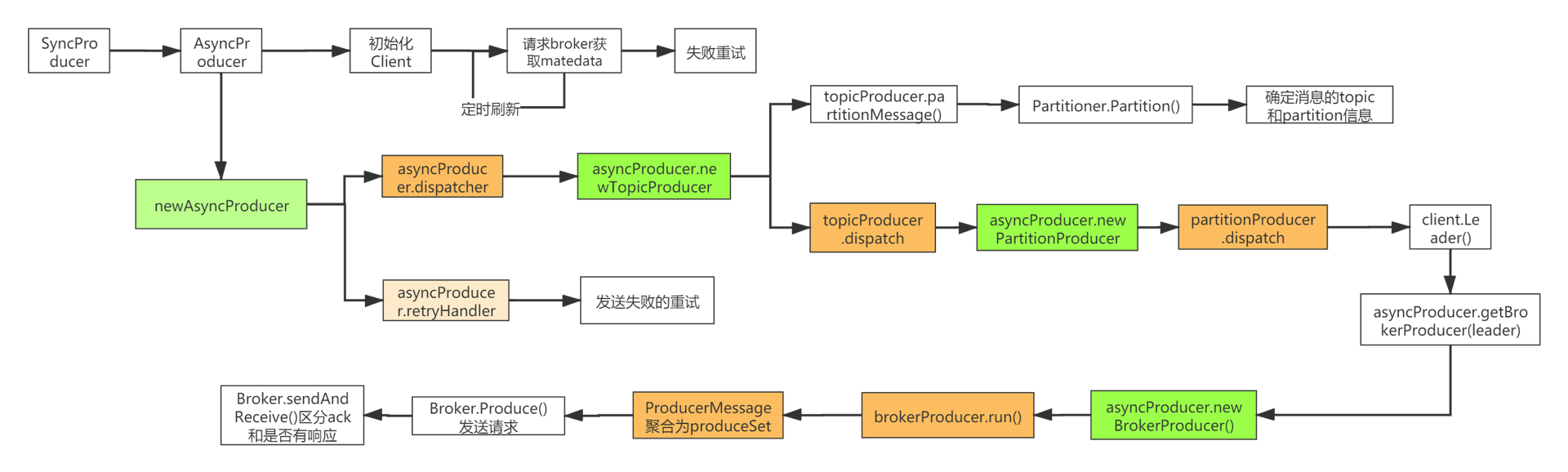
sarama生产者主要流程
上面的图只要是给愿意看源码的同学看的,毕竟太复杂了,我们简化一下:
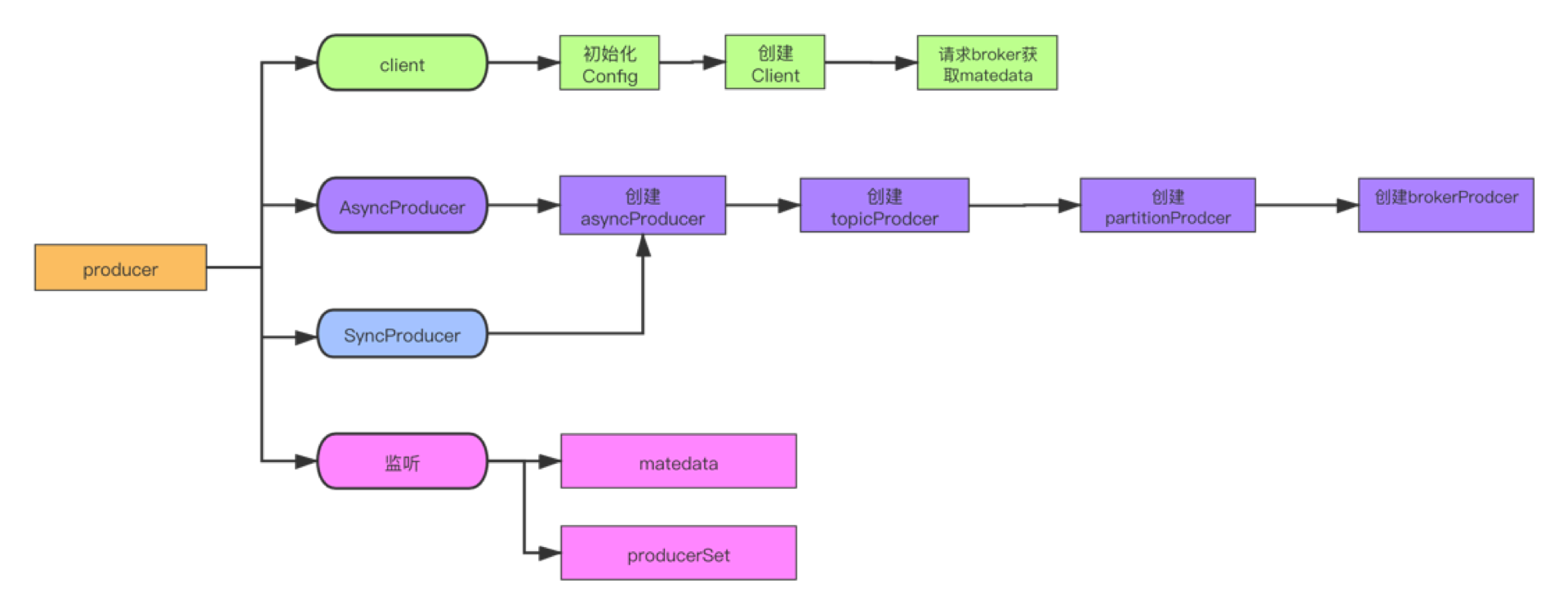
Sarama获取matedata
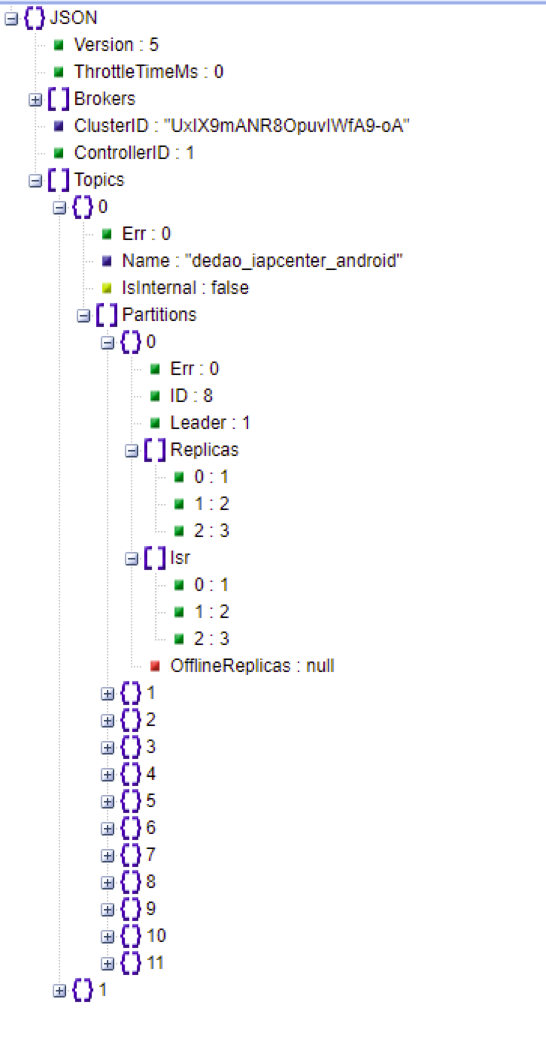
之前说到client获取获取kafka集群的元数据,那么元数据如何获取?长的是什么模样?
我给你大家写了一个示例代码,大家可以看看:
func Getmetadata() {
mqConfig := sarama.NewConfig()
mqConfig.Version = sarama.V1_1_0_0
mqConfig.Producer.Return.Successes = true
client, err := sarama.NewClient([]string{"10.1.0.107:9093"}, mqConfig)
if err != nil {
log.Println(err)
return
}
b, err := client.Controller()
if err != nil {
log.Println(err)
return
}
req := &sarama.MetadataRequest{Topics: []string{},AllowAutoTopicCreation: false}
req.Version = 5 // 不同的kafka版本version不一样
mr, err := b.GetMetadata(req)
if err != nil {
log.Println(err)
return
}
ss, err := json.Marshal(mr)
log.Println(string(ss))
}
sarama生产者确定分区
消息发送之前需要确定该消息的需要发送的分区。这个操作就是之前说的第二条链路,在本地SDK就确定了。sarama生产者确定分区接口定义如下:
type Partitioner interface {
Partition(message *ProducerMessage, numPartitions int32) (int32, error)
RequiresConsistency() bool
}
其中:
Partition:给定消息就返回该消息确定发送的分区;
RequiresConsistency:key与分区是否一一对应。
目前sarama提供了如下的算法规则。
| Partitioner类型 | 类型 | 说明 | 备注 |
| --- | --- | --- | --- |
| ManualPartitioner | 已定义 | 根据ProducerMessage.Partition | |
| RandomPartitioner | 已定义 | 随机生成分区数 | |
| RoundRobinPartitioner | 已定义 | 轮询给定分区数 | |
| HashPartitioner | 已定义 | 根据ProducerMessage.Key使用32-bit FNV-1a算法 | 默认使用 |
| ReferenceHashPartitioner | 已定义 | HashPartitioner有错误将referenceAbs = false,所以新加该类型 | |
| CustomHashPartitioner | 自定义 | 自定义hash算法 | |
| CustomPartitioner | 自定义 | 自定义分区算法 | |
自定义
func CustomHashPartitioner() {
hashFunc := func() hash.Hash32 {
return murmur3.New32()
}
cp := sarama.NewCustomHashPartitioner(hashFunc)
for i := 0; i < 15; i++ {
mp := &sarama.ProducerMessage{
Key: sarama.StringEncoder(fmt.Sprintf("%v", i)),
Value: sarama.StringEncoder("1468509572224"),
Partition: 2,
}
fmt.Println(cp(topic).Partition(mp, ps))
}
}
sarama生产者聚合消息
为了减少网络的请求操作,生产者采用批量和定时间隔的方式,达到一个时延与性能的平衡。那么生产者是怎么实现的呢,通过下面代码一起来分析:
func (bp *brokerProducer) run() {
for {
select {
case msg := <-bp.input:
... ...
if bp.buffer.wouldOverflow(msg) {// 校验消息是否正确
if err := bp.waitForSpace(msg); err != nil {// 写入到待发送队列
bp.parent.retryMessage(msg, err)// 错误重试
continue
}
}
if err := bp.buffer.add(msg); err != nil {// 组装produceSet
bp.parent.returnError(msg, err)
continue
}
if bp.parent.conf.Producer.Flush.Frequency > 0 && bp.timer == nil {// 定时发送
bp.timer = time.After(bp.parent.conf.Producer.Flush.Frequency)
}
case <-bp.timer:
bp.timerFired = true
case output <- bp.buffer:
bp.rollOver()
case response := <-bp.responses:
bp.handleResponse(response)
}
if bp.timerFired || bp.buffer.readyToFlush() {// 判断是否达到发送条件:时间间隔和数据要求
output = bp.output
} else {
output = nil
}
}
}
发送条件判断:
func (ps *produceSet) readyToFlush() bool {
switch {
// If we don't have any messages, nothing else matters
case ps.empty():
return false
// If all three config values are 0, we always flush as-fast-as-possible
case ps.parent.conf.Producer.Flush.Frequency == 0 && ps.parent.conf.Producer.Flush.Bytes == 0 && ps.parent.conf.Producer.Flush.Messages == 0:
return true
// If we've passed the message trigger-point
case ps.parent.conf.Producer.Flush.Messages > 0 && ps.bufferCount >= ps.parent.conf.Producer.Flush.Messages:
return true
// If we've passed the byte trigger-point
case ps.parent.conf.Producer.Flush.Bytes > 0 && ps.bufferBytes >= ps.parent.conf.Producer.Flush.Bytes:
return true
default:
return false
}
}
Kafka消费者
MQ消费模式

消息投递模式的划分只要是根据消息与消费者的关系进行,可以分为:
点对点模式:每一条消息都会被一个消费者处理,对应到Kafka同一个消费组;
发布/订阅模式:每一条消息都会被不同消费组处理,对应到Kafka不同消费组。
消息获取模式
消息获取模式就是大家常常说到的拉取还是推送获取消息的方式了,通过表格来对比一下:
| 获取模式 | 过程 | 角色 | 优点 | 缺点 |
| --- | --- | --- | --- | --- |
| push | 1.mq接收到消息;
2.mq主动将消息推送给消费者(消费者需提供一个消费接口) | mq属于主动方,消费者属于一种被动消费 | 1.消费者实现简单; 2.消息实时性比较高。 | 1.消费者性能要求比较高;
2.消费者可用性要求比较高。 |
| pull | 1.消费端采用轮询的方式,从mq服务中拉取消息进行消费;
2.消费完成通知mq删除已消费成功的消息;
3.继续拉取消息消费。 | 消费者为主动方 | 1.消费者可以根据自己的性能主动控制消息拉去的速度;
2.实时性相对于push方式会低一些; | 1.消费方需要实现消息拉取的代码,复杂度高;
2.消费速度较慢时,可能导致mq中消息积压,消息消费延迟等。 |
Sarama消费者组
值得一提的是,Sarama 1.19后消费者开支持是消费组模式了,不需要依赖其他的组件了。
先通过一个示例学习:
// Consumer represents a Sarama consumer group consumer
type Consumer struct {
ready chan bool
}
// Setup is run at the beginning of a new session, before ConsumeClaim
func (consumer *Consumer) Setup(sarama.ConsumerGroupSession) error {
// Mark the consumer as ready
close(consumer.ready)
return nil
}
// Cleanup is run at the end of a session, once all ConsumeClaim goroutines have exited
func (consumer *Consumer) Cleanup(sarama.ConsumerGroupSession) error {
return nil
}
// ConsumeClaim must start a consumer loop of ConsumerGroupClaim's Messages().
func (consumer *Consumer) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for message := range claim.Messages() {
log.Printf("Message claimed: value = %s, timestamp = %v, topic = %s,partition=%v,offset=%v", string(message.Value), message.Timestamp, message.Topic,message.Partition,message.Offset)
session.MarkMessage(message, "")
}
return nil
}
sarama.Logger = log.GetLogger()
config := sarama.NewConfig()
config.Net.TLS.Enable = false
config.Net.SASL.Enable = false
config.Consumer.Return.Errors = true
config.Consumer.Offsets.Initial = sarama.OffsetNewest //初始从最新的offset开始
config.Version = sarama.V1_1_0_0
config.Metadata.RefreshFrequency = 10 * time.Second
// RangeAssignor
config.Consumer.Group.Rebalance.Strategy = sarama.BalanceStrategyRange
// RoundRobinAssignor
// config.Consumer.Group.Rebalance.Strategy = sarama.BalanceStrategyRoundRobin
// StickyAssignor
// config.Consumer.Group.Rebalance.Strategy = sarama.BalanceStrategySticky
consumer := Consumer{
ready: make(chan bool),
}
ctx, cancel := context.WithCancel(context.Background())
client, err := sarama.NewConsumerGroup(Brokers, GroupID, config)
if err != nil {
log.Printf("Error creating consumer group client: %v", err)
return
}
wg := &sync.WaitGroup{}
wg.Add(1)
go func() {
defer wg.Done()
for {
if err := client.Consume(ctx, []string{Topic, "ddtrace_prod"}, &consumer); err != nil {
log.Errorf("Error from consumer: %v", err)
}
if ctx.Err() != nil {
return
}
consumer.ready = make(chan bool)
}
}()
<-consumer.ready
定义一个consumer结构体实现接口:
type ConsumerGroupHandler interface {
// Setup is run at the beginning of a new session, before ConsumeClaim.
Setup(ConsumerGroupSession) error
// Cleanup is run at the end of a session, once all ConsumeClaim goroutines have exited
// but before the offsets are committed for the very last time.
Cleanup(ConsumerGroupSession) error
// ConsumeClaim must start a consumer loop of ConsumerGroupClaim's Messages().
// Once the Messages() channel is closed, the Handler must finish its processing
// loop and exit.
ConsumeClaim(ConsumerGroupSession, ConsumerGroupClaim) error
}
Sarama消费者函数链路
Sarama消费者函数链路明显比生产者的链路复杂,需要耐心的阅读源码,寻找关系。
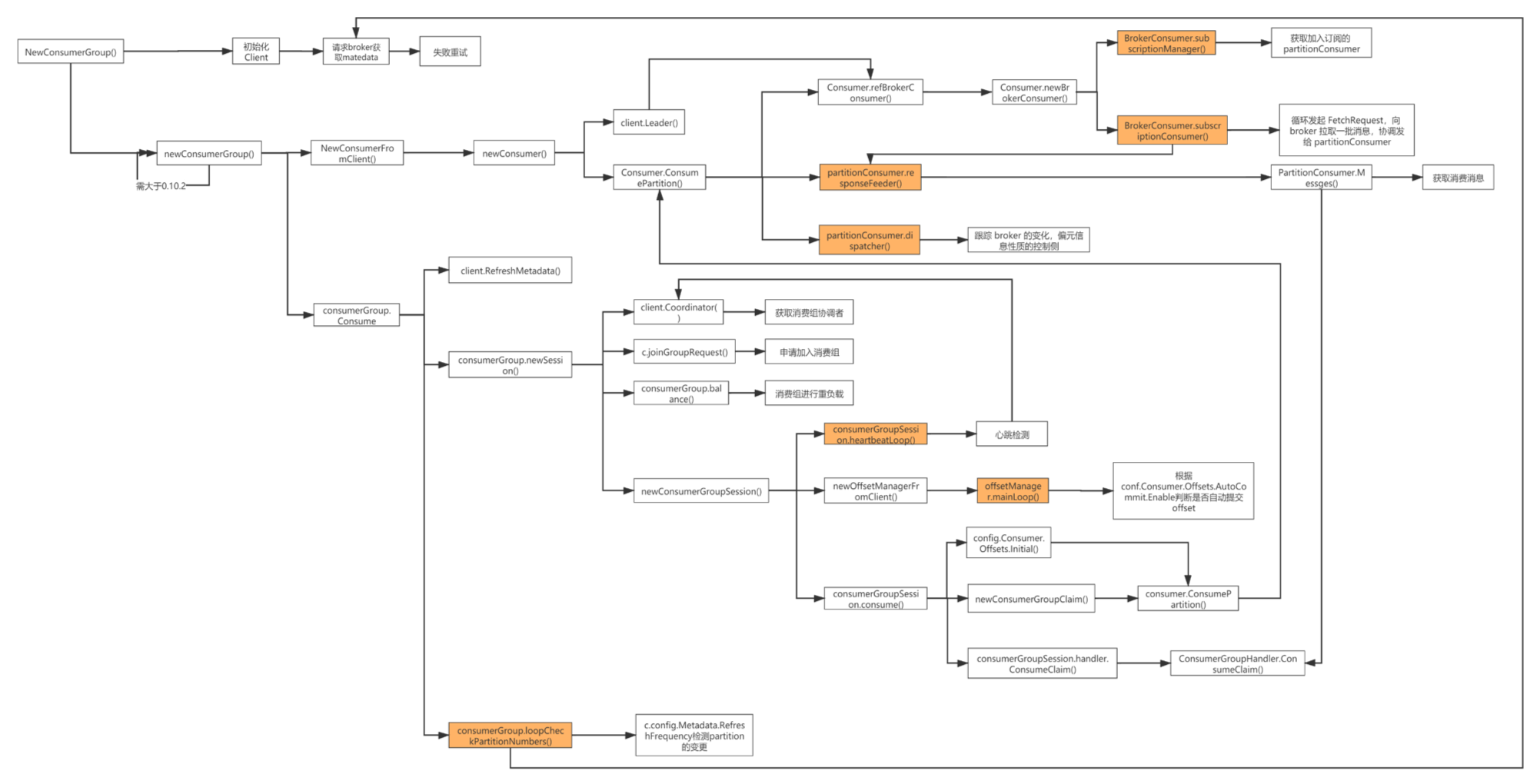
这张图可以分为3个链路来看,从上到下可以看到:
第一条链路:主要是创建client连接,依旧是为了获取Kafka集群metadate数据;
第二条链路:创建消费者,一个消费者关联到一个分区指定的分区中,获取消息也是批量获取的;
第三条链路:将多个消费者组装为消费组,多加协调者交互、负载能力和管理offset能力;
大家可以把这张和之前的生产者函数链路图作为阅读源码的指引,发现有什么错误的,随时找我反馈。
Sarama消费者主要流程
与生产者一样,上一页是给阅读源码的同学看的,只需要了解的同学就看这张图就行了。基本上看这个图就应该知道说的是什么了。

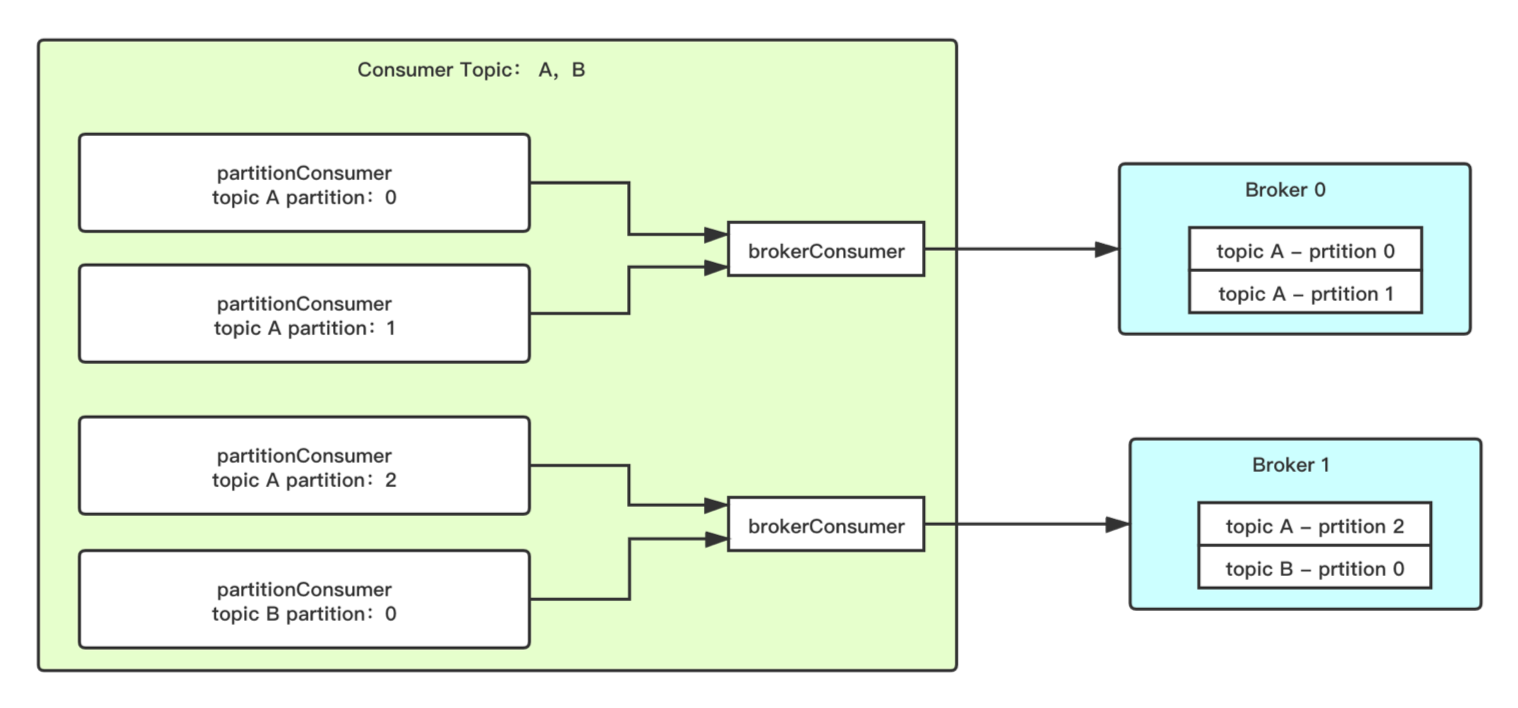
为了降低连接数,客户端也是做了优化,当 Consumer 需要从 Broker 订阅多个 Topic 时,会使用单独的一个连接来消费数据,再将数据按 partition 分给不同的 partitionConsumer。
消费组提交offset
通过之前这么多的讲解,我们可以确定是写入kafka分区中的消息都会有该分区中唯一确定的offset了。在Kafka集群中Offset可以翻译为"偏移量",在消费者中Offset应该翻译为"消费位移",简称位移。
" style="zoom:50%;" />
我们先通过代码来认识一下如何提交位移:
func (c *Consumer) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for message := range claim.Messages() {
log.Printf("Message claimed: value = %s, timestamp = %v, topic = %s,partition=%v,offset=%v",
string(message.Value), message.Timestamp, message.Topic, message.Partition, message.Offset)
session.MarkMessage(message, "") // 提交位移
}
return nil
}
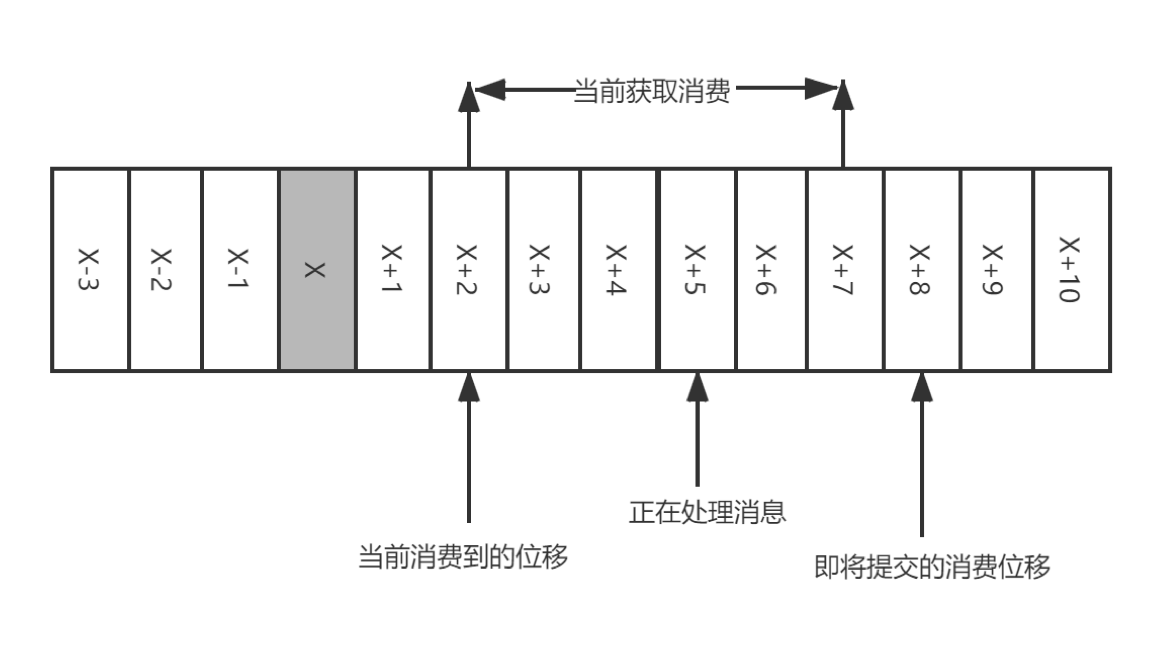
大家看图,假设X表示某一次拉取操作中此分区消息的最大偏移量,假设当前消费者已经消费了x位置的消息,那么我们现在需要提交位移了。此时需要注意的是提交的位移并不是X,而是X+1。
很多人都没注意到这点,口说无凭,show me your code。
func (s *consumerGroupSession) MarkMessage(msg *ConsumerMessage, metadata string) {
s.MarkOffset(msg.Topic, msg.Partition, msg.Offset+1, metadata)
}
消费组提交offset场景
消费组提交offset的时间把握不好就会产生两类问题:
重复消费:位移提交的动作在消费完所有拉取到的消息后才执行,那么当消费到X+5时候遇到异常。当故障恢复后,重新拉取消息是从X+2开始,导致X+2至X+4之间的消息重新消费一遍。
消息丢失:拉取完成消息后不等消息确认完成消费既执行提交。如图,拉取\[X+2,X+7\]后提交位移X+8,当执行到X+5时候出现异常,当故障恢复后重新拉取消息是从X+8开始,那么\[X+5,X+7\]之间的消息是未能被消费。
消费组提交offset最佳实践
在大家日常的使用中,我常常发现很多业务都是消费一条消息就提交一个offset,导致\
- 采用自动提交
- 批量处理完成消息后手动提交最大的偏移量
- 消息量小
- 消息不容丢失
- 消息不容重复消费
- 对性能要求不高
分区分配策略
在同一个Consumer Group 中,同一个Topic的不同分区会分配给不同的消费者进行消费,那么分区是如何进行介配呢?这就是我们本节需要回答的问题了。Kafka客户端提供了3种分区分配策略,
RangeAssignor
RangeAssignor原理很简单。
按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配, 以保证分区尽可能均匀地分配给所有的消费者。每一个主题 , RangeAssignor 策略会将消费组内所有订阅这个主题的消费者按照名称的字典序排序。
不过需要关注的是Java的和sarama的实现还是有一定的区别的。
先看看Go的版本:
func GetRangeStrategy_Go() {
step := float64(len(partitions)) / float64(len(memberIDs))
ret := map[string][]int32{}
for i, memberID := range memberIDs {
pos := float64(i)
// 向下取整
min := int(math.Floor(pos*step + 0.5))
max := int(math.Floor((pos+1)*step + 0.5))
fmt.Println(memberID, i, min, max, step)
ret[memberID] = partitions[min:max]
}
}
结果:
// a:[0 1 2] b:[3 4 5] c:[6 7 8] d:[9 10 11]
// a:[0 1] b:[2 3 4] c:[5 6] d:[7 8 9] e:[10 11]
Java版本:
func GetRangeStrategy_Java() {
ret := map[string][]int32{}
numPartitions := len(partitions) / len(memberIDs)
extraPartition := len(partitions) % len(memberIDs)
for i := 0; i < len(memberIDs); i++ {
start := numPartitions*i + int(math.Min(float64(i),
float64(extraPartition)))
length := 0
if i+1 > extraPartition {
length = numPartitions + 0
} else {
length = numPartitions + 1
}
ret[memberIDs[i]] = partitions[start : start+length]
}
fmt.Println(ret)
}
结果:
// a:[0 1 2] b:[3 4 5] c:[6 7 8] d:[9 10 11]
// a:[0 1 2] b:[3 4 5] c:[6 7] d:[8 9] e:[10 11]
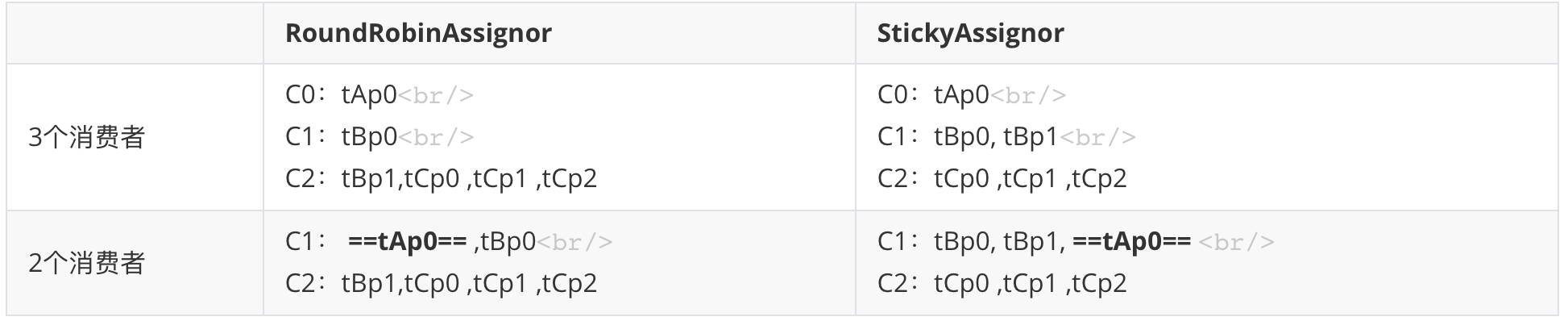
到现在为止看起来一起都很美,但是现实就是这么骨感。我们加上有这样的场景。 现在有两个Topic ,每个Topic均有3各分区:
Topic A: p0,p1,p2
Topic B: p0,p1,p2
存在一个消费组有两个消费者C1和C2,需要同时消费Topic A和Topic B。
那么根据之前说的到算法,可以得到如下:
C1:tAp0,tAp1,tBp0,tBp1
C2:tAp2,tBp2
如果再来几个这样的Topic,那就更加严重。
RoundRobinAssignor
既然RangeAssignor策略有这个问题,那我们换另一种来看看。与RangeAssignor策略一样sarama的实现与Java的实现也是不一样的。
区别点就是前者是后者是
go的实现:
var BalanceStrategyRoundRobin = &balanceStrategy{
name: RoundRobinBalanceStrategyName,
coreFn: func(plan BalanceStrategyPlan, memberIDs []string, topic string, partitions []int32) {
for i, part := range partitions {
memberID := memberIDs[i%len(memberIDs)]
plan.Add(memberID, topic, part)
}
},
}
java的实现:
public Map> assign(Map partitionsPerTopic,
Map subscriptions) {
Map> assignment = new HashMap<>();
List memberInfoList = new ArrayList<>();
for (Map.Entry memberSubscription : subscriptions.entrySet()) {
assignment.put(memberSubscription.getKey(), new ArrayList<>());
memberInfoList.add(new MemberInfo(memberSubscription.getKey(),
memberSubscription.getValue().groupInstanceId()));
}
CircularIterator assigner = new CircularIterator<>(Utils.sorted(memberInfoList));
for (TopicPartition partition : allPartitionsSorted(partitionsPerTopic, subscriptions)) {
final String topic = partition.topic();
while (!subscriptions.get(assigner.peek().memberId).topics().contains(topic))
assigner.next();
assignment.get(assigner.next().memberId).add(partition);
}
return assignment;
}
RoundRobinAssignor也是存在局限性的,假设有如下情况。
现在有三个Topic ,每个Topic均有3各分区:
Topic A: p0
Topic B: p0,p1
Topic C: p0,p1,p2
存在一个消费组有三个消费者C0、C1和C2,需要同时消费Topic A 、Topic B和Topic C。
Java分区如下:
C0:tAp0
C1:tBp0
C2:tBp1,tCp0,tCp1,tCp2
Golang分区如下:
C0:tAp0,tBp0, tCp0
C1:tBp1, tCp1
C2:tCp2
StickyAssignor
StickyAssignor是Kafka 0.11之后提供的。
如果发生分区重分配,那么对于同一个分区而言 ,有可能之前的消费者和新指派的消 费者不是同一个,之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很琅费系统资源。 StickyAssignor 分配策略如同其名称中的“ sticky ” 一样,让分配策略具备一定的“黏性”,尽可能地让前后两次分配相同,进而减少系统资源的损耗及其他异常情况的发生 。
StickyAssignor目标:
分区的分配要尽可能均匀 。
分区的分配尽可能与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标
不怕不识货就怕货比货,我们通过RangeAssignor的示例做对比。
现在有两个Topic ,每个Topic均有3各分区:
Topic A: p0
Topic B: p0,p1
Topic C: p0,p1,p2
存在一个消费组有三个消费者C0、C1和C2,需要同时消费Topic A、 Topic B和Topic C。
golang当作是作业吧,大家回去自己实现。
消费组重负载
重负载,别名有再负载,英文有rebalance,说的都是同一个东西--分区的所属权从一个消费者转梯到另一消费者的行为,它为消费组具备高可用性和伸缩性提供保障,提供方便安全的删除消费组内的消费者或往消费组内添加消费者。
有如下的场景就会触发重负载:
有新的消费者加入消费组;这个好理解,原来消费组只有3个消费者,现在多加一个变为4个;
有消费者若机下线 :这里的宕机并不是说消费者真的宕机了,有可能是长时间无响应,比如GC时间长、网络延时不能发送心跳给GroupCoorinator,还有就是poll消息的时间间隔超过了配置的拉取间隔也会导致;
有消费者主动退出消费组:消费者客户端主动Close;
消费组所对应的 GroupCoorinator 节点发生了变更:broker宕机导致 GroupCoorinator 节点漂移;
消费组内所订阅的任一主题或者主题的分区数量发生变化:指定的Topic增加分区数了。
重负载发生的时候会有如下影响:
重负载期间的这一小段时间内,消费组会变得不可用;
当一个分区被重新分配给另一个消费者时, 消费者当前的状态也会丢失。
重负载的过程非常复杂,如果拿出来将可以用一节课来说,我们这里只是概要介绍,有兴趣的可以查看: 。
sarama客户端参数
| 参数配置 | 作用域 | 类型 | 默认值 | 说明 |
| --- | --- | --- | --- | --- |
| Admin.Timeout | Client | time.Duration | 3s | ClusterAdmin操作超时时间 |
| Net.MaxOpenRequests | Client | Int | 5 | 一个连接运行最大的等待请求数 |
| Net.DialTimeout | Client | time.Duration | 30s | TCP超时 |
| Net.ReadTimeout | Client | time.Duration | 30s | 网络读取超时 |
| Net.WriteTimeout | Client | time.Duration | 30s | 网络写入超时 |
| Net.TLS.Enable | Client | bool | false | 是否启用TLS |
| Net.TLS.Config | Client | *tls.Config | nil | TLS配置 |
| Net.SASL.Enable | Client | bool | false | 是否启用SASL |
| Net.SASL.Mechanism | Client | SASLMechanism | PLAIN | 启用的SASL机制的名称,值:OAUTHBEARER, PLAIN |
| Net.SASL.Version | Client | int16 | 0 | SASL Protocol版本:
- Kafka > 1.x使用V1;
- Kafka < 1.x使用V0 |
| Net.SASL.Handshake | Client | bool | true | 先发送Kafka SASL握手,若使用非Kafka SASL代理时,才应该将其设置为false |
| Net.SASL.User | Client | string | "" | SASL的用户 |
| Net.SASL.Password | Client | string | "" | SASL的密码 |
| Net.SASL.SCRAMAuthzID | Client | string | "" | 用于SASL/SCRAM认证 |
| Net.SASL.SCRAMClientGeneratorFunc | Client | func() SCRAMClient | | 一个用户提供的SCRAM客户端的生成器,用于与服务器进行SCRAM交换 |
| Net.SASL.TokenProvider | Client | AccessTokenProvider | | 用户定义的回调,用于为SASL/OAUTHBEARER auth生成访问令牌 |
| Net.SASL.GSSAPI | Client | GSSAPIConfig | | |
| Net.KeepAlive | Client | time.Duration | 0 | 活动的网络连接的保持时间.为0,则keep-alives被禁用 |
| Net.LocalAddr | Client | net.Addr | nil | 拨号地址时要使用的本地地址。该地址必须是与所拨网络兼容的类型。 如果为nil,则自动选择一个本地地址。 |
| Net.Proxy.Enable | Client | bool | false | 连接是否使用代理 |
| Net.Proxy.Dialer | Client | proxy.Dialer | nil | 代理配置 |
| Metadata.Retry.Max | Client | int | 3 | 当Kafka集群正处于leader选举的期间,重试元数据请求的总次数 |
| Metadata.Retry.Backoff | Client | time.Duration | 250ms | 每次重试的时间间隔 |
| Metadata.Retry.BackoffFunc | Client | func(retries, maxRetries int) time.Duration | nil | 调用来动态地计算重试时间。有助于实施更复杂的回退策略。如果设置为 "Backoff",则优先于 "Backoff"。 |
| Metadata.RefreshFrequency | Client | time.Duration | 10min | 后台刷新集群元数据的时间间隔 |
| Metadata.Full | Client | bool | true | 维护所有主题的全套元数据,还是只维护到目前为止所需要的最小的元数据集。全集更简单,通常更方便,但如果你有很多主题和分区,则会占用大量内存。默认为true。 |
| Metadata.Timeout | Client | time.Duration | | 等待元数据响应成功的时间。默认情况下已禁用,这意味着针对无法到达的集群的元数据请求(所有的经纪人都无法到达或没有响应)可能需要等待长达 |
| Producer.MaxMessageBytes | Producer | int | 1000000 | 消息的最大允许大小,单位byte |
| Producer.RequiredAcks | Producer | int | 1 | ACK |
| Producer.Timeout | Producer | time.Duration | 10s | broker等待收到RequiredAcks数量的最长时间 |
| Producer.Compression | Producer | CompressionCodec | none(无压缩) | 对消息使用的压缩类型 |
| Producer.CompressionLevel | Producer | int | -1000 | 对消息使用的压缩等级,其含义取决于实际使用的压缩类型,默认为编解码器的默认压缩级别。 |
| Producer.Partitioner | Producer | PartitionerConstructor | HashPartitioner | 生成分区器,用于选择要发送消息的分区。 |
| Producer.Idempotent | Producer | bool | false | 启用幂等 |
| Producer.Return.Successes | Producer | bool | false | 成功发送的消息将在成功通道上返回 |
| Producer.Return.Errors | Producer | bool | true | 失败发送的消息将在失败通道上返回 |
| Producer.Flush.Bytes | Producer | int | 0 | 触发刷新消息大小,单位byte |
| Producer.Flush.Messages | Producer | int | 0 | 触发刷新消息个数 |
| Producer.Flush.Frequency | Producer | time.Duration | 0 | 触发刷新时间间隔 |
| Producer.Flush.MaxMessages | Producer | int | 0 | 触发刷新最大消息数 |
| Producer.Retry.Max | Producer | int | 3 | 最大重试次数 |
| Producer.Retry.Backoff | Producer | time.Duration | 100ms | 重试间隔 |
| Producer.Retry.BackoffFunc | Producer | func(retries, maxRetries int) time.Duration | nil | 自定义重试方法 |
| Consumer.Group.Session.Timeout | Consumer | time.Duration | 10s | 用于检测消费者故障的超时时间。消费者会定期发送心跳,以显示其有效性。 |
| Consumer.Group.Heartbeat.Interval | Consumer | time.Duration | 3s | 消费者协调人预期的心跳间隔时间。心跳时间用于确保消费者的会话保持活跃,并在新的消费者加入或离开群组时便于重新平衡。该值的设置必须低于Consumer.Group.Session.Timeout,但通常不应高于该值的1/3。 |
| Consumer.Group.Rebalance.Strategy | Consumer | BalanceStrategy | BalanceStrategyRange | 用于向成员分配主题分区的策略 |
| Consumer.Group.Rebalance.Timeout | Consumer | time.Duration | 60s | 消费者加入消费组的最大超时时间 |
| Consumer.Group.Rebalance.Retry.Max | Consumer | int | 4 | 重负载最大重试次数 |
| Consumer.Group.Rebalance.Retry.Backoff | Consumer | time.Duration | 2 | 重负载重试时间间隔 |
| Consumer.Group.Member.UserData | Consumer | \[\]byte | nil | 自定义的元数据,在加入群组时包含。可以通过发送DescribeGroupRequest给作为组的协调者的代理来检索所有加入成员的用户数据 |
| Consumer.Retry.Backoff | Consumer | time.Duration | 2s | 重试时间间隔 |
| Consumer.Retry.BackoffFunc | Consumer | func(retries int) time.Duration | nil | 自定义重试时间间隔 |
| Consumer.Fetch.Min | Consumer | int32 | 1 | 请求中要获取的最小报文字节数 ,broker将至少等待到有字节数的消息。默认值是1,因为0会导致消费者在没有消息可用的情况下旋转。 |
| Consumer.Fetch.Default | Consumer | int32 | 1MB | 每次请求中要从代理处获取的消息字节数 |
| Consumer.Fetch.Max | Consumer | int32 | 0 | 单次请求中从broker中获取的最大报文字节数 |
| Consumer.MaxWaitTime | Consumer | time.Duration | 250ms | 等待Consumer.Fetch.Min字节可用的最大时间 |
| Consumer.MaxProcessingTime | Consumer | time.Duration | 100ms | 处理一条消息所需的最大时间。因为Messages通道是有缓冲的,所以实际的宽限期是(MaxProcessingTime * ChanneBufferSize |
| Consumer.Return.Errors | Consumer | bool | false | 是否在消费过程中发生的任何错误都会在Errors通道上返回 |
| Consumer.Offsets.CommitInterval | Consumer | time.Duration | 1s | 自动提交offset时间间隔 |
| Consumer.Offsets.Initial | Consumer | int64 | OffsetNewest | 初始化消费offset,OffsetNewest 或 OffsetOldest |
| Consumer.Offsets.Retention | Consumer | time.Duration | 0 | 承诺的偏移量的保留时间。 |
| Consumer.Offsets.Retry.Max | Consumer | int | 3 | 提交失败重试次数 |
| Consumer.IsolationLevel | Consumer | IsolationLevel | ReadUncommitted | 事务隔离级别,值:ReadUncommitted、ReadCommitted |
| Consumer.ClientID | Consumer | string | sarama | 消费者id |
| Consumer.ChannelBufferSize | Consumer | int | 256 | 内部和外部通道中要缓冲的事件数量 |
| Consumer.Version | Consumer | KafkaVersion | | 设定Kafka版本 |
| Consumer.MetricRegistry | Consumer | metrics.Registry | | 注册指标监控 |