实用机器学习笔记十七:模型评估
前言:
本文是个人在 B 站自学李沐老师的实用机器学习课程【斯坦福 2021 秋季中文同步】的学习笔记,感觉沐神讲解的非常棒 yyds。
本文的定位:
先来说一说本文所讲内容与前面文章之间的关系:这一系列文章,最开始讲述的是如何得到数据,以及如何对数据进行处理。比如:对房子价格的预测,从数学上来说,价格实际上就是一个分布P,数据收集就是在这个分布上采样数据,做成数据集data;然后讲述的是算法部分,比如:决策树,MLP,CNN, RNN,然后使用合适的算法对data进行训练,得到模型model。机器学习关注的不是训练好的模型对训练数据集的预测有多好,更加关心的是,在P上再采样一个新的数据样本,然后输入到训练好的模型,这个模型对新的数据的预测性能。所以本文关注的
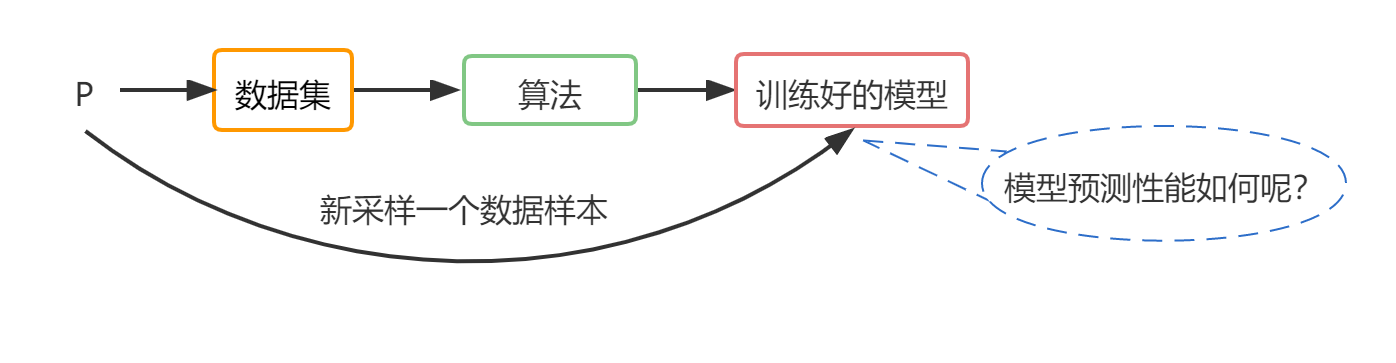
模型指标:
在监督学习中,通过最小化损失来训练模型:
损失的值是一个被广泛使用来衡量模型质量的指标
其他衡量指标:
模型方面:比如分类的准确率,目标检测的mAP
商业方面:比如模型对营收的影响,推理时间等
在对模型进行评估时,同时不止使用一个指标。
实例:广告展现:
首先用户会通过关键词进行搜索,或者在某一个页面,后台根据关键词等信息找到相关的广告,然后算法对每一个广告的点击率进行预测,并计算出预计收入进行排序,最后选择top广告进行展现。
在这个广告的二分类问题中,因为绝大部分人是不点击广告的,因此,负样本特别多,正样本特别少。

分类问题指标:
Accuracy:正确预测数量/样本数量。
sum(y = y_hat) / y.size。y_hat代表模型预测值,下同。y=y_hat即样本标签和模型预测值相同
Precision:正确预测类型 i 的数量 / 被预测成类型 i 的数量
sum((y_hat == 1) & (y = 1)) / sum(y_hat == 1) 。
这里的y_hat == 1 表示模型预测的值为类型 i ,即类型 i 对应的标号是1。
Recall:正确预测类型 i 的数量 / 类型 i 的样本数量
sum((y_hat == 1) & (y = 1)) / sum(y == 1)
从精度(Precision)和 召回率(Recall)的计算公式来看,分子都相同,只是分母不一样。为什么要区分成两个指标呢?因为,如果数据集中正样本太少,那么sum(y_hat == 1)会更小,从而精度就会很高,导致模型训练很好的错觉。评价太偏面,所以就出现了召回率。
F1:平衡精度和召回率指标
调和平均值=2pr/(p+r)。p代表精度,r代表召回率。
二分类问题指标AUC&ROC:
在二分类问题中,为了确定模型的预测到底是一个正样本还是负样本,通常会设置一个阈值,如果,就认为预测为正样本,反之。如果训练集中的正负样本比较平衡,阈值可以设置为0.5。但是在实际生产中,会根据很多东西来调节阈值,通过调节阈值的大小,就可以控制模型的精度等指标。
那么如何观察模型对阈值变化的反应呢?ROC曲线就上场了,黄色曲线上每一个点就是在不同阈值下,模型得到的ROC值。如下图:阴影部分面积就是AUC值,AUC最大值等于1,最小值为0。
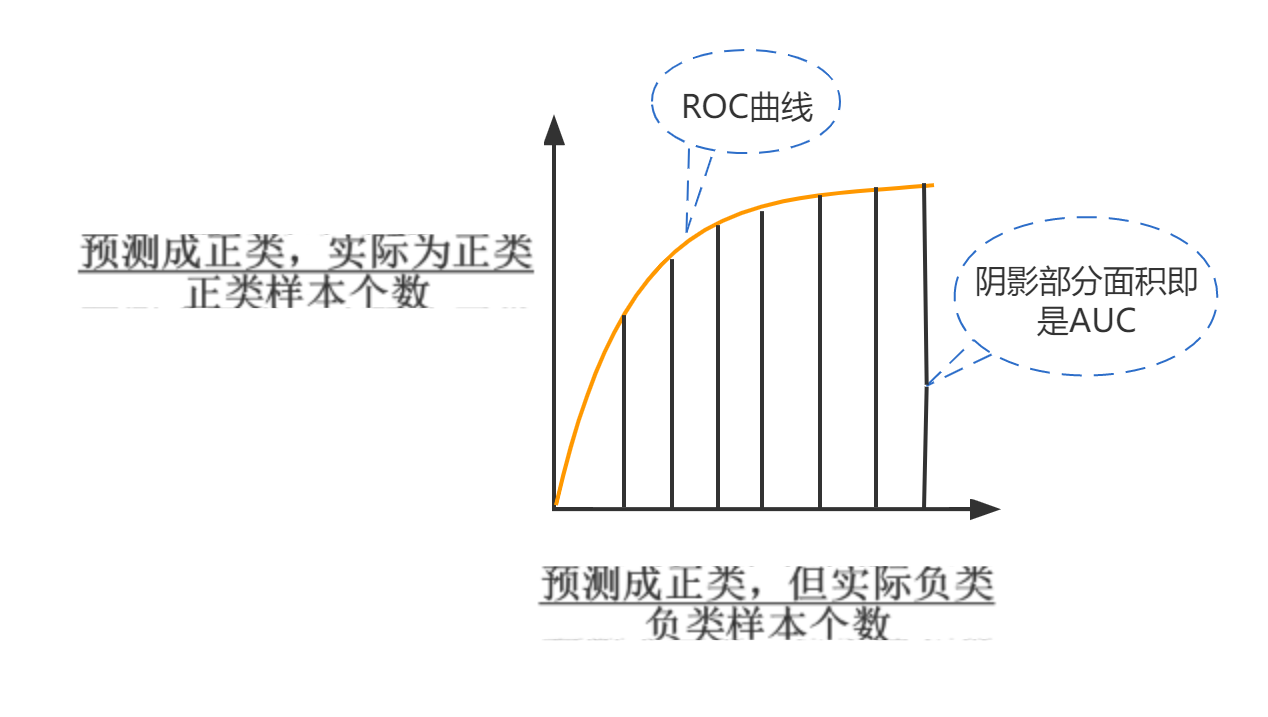
AUC的意义:
如下图左边所示,AUC=1,表示模型可以完完美地把正负样本分开,从图上就可以看到存在一条直线可以把正负样本完全切开。红色曲线为正样本,绿色曲线为负样本。
再看第三行图,AUC= 0.5,完全没法把正负样本分开,是一个随机预测。
看第四行图,AUC = 0,正好完全把正样本预测成负样本,把负样本预测成正样本。但是这不是问题, 把预测值的正负号换一下就可以了。
我们的任务就是避免AUC的值为0.5,从0.5拉升到1,如果AUC小于0.5,变成1-0.5。

部署广告的商业指标:
优化广告收入和用户体验
延迟:部署在线上的模型要在很短的时间内完成数据特征抽取,模型预测等等。因为如果一旦广告投放太慢的话,用户可能就会错过广告,不再关注。这个指标和推理所用的硬件设备有关,cpu?gpu?
ASN:平均每一个页面投放的广告量。
CTR:用户真实的点击率
ACP:平均每一个点击量,广告主支付的费用
平台方收入= 流量*ASN*CTR*ACP