【得物技术】得物分布式UI自动化实践
前言
提起UI自动化测试,总是会有人抛出很多疑问
......

今天小编就在这里跟大家分享下,自己对UI自动化测试的理解以及我司质量平台正在搭建的分布式平台 DuLab 是怎样实现批量运行UI自动化测试Case的。
为什么要做UI自动化?
随着不停的版本迭代,软件新增功能变的越来越多,对测试资源的需求也变得越来越大,执行人工测试的时间越来越长。对于人工测试的依赖开始变得棘手,因此大家开始寻找解决方案,UI自动化也应运而生。
人工测试的弊端
人工回归测试需要花费很长时间才能完成,很小的延迟就会让发布面临风险。
发布节奏受到人工回归测试的限制。两天以上的人工回归测试意味着最好的情况下能够一个月发布两次。而且,开发者需要一次性发布所有东西。要么全部发布,要么什么都发布不了,因为需要将所有东西一起测试。
UI自动化测试的优点
解放了测试团队针对临时的和探索性案例的测试时间;
可以一边开发一边进行回归测试,减少等待时间;
可重复性使用,快速进行回归测试;
更好的利用资源(周未/晚上的资源空闲时段) 。
UI自动化的特点
UI即User Interface(用户界面)的简称,UI自动化做的事情就是模拟用户行为进行操作,完成对用户界面的测试。这也就从本质上限制了它的使用场景:
软件需求变动不频繁 产品更新维护周期长 比较频繁的回归测试 自动化测试脚本可重复使用
所以在你开始之前,最好认识清楚哪些业务场景是可以自动化的~
预期效果
针对我司的业务现状,确定好预期效果。
兼容性测试:针对市场上常用机型与系统版本,进行下载安装使用,以发现兼容性故障,进而修复。
埋点测试:校验埋点数据是否正常上报,有无漏报,错报,多报。
回归测试:版本迭代中,进行回归测试保障代码改动不会导致其他场景产生故障。
测试阶段性能收集:在测试阶段为自动化case指定优先级,按照优先级运行自动化case,提供更多的性能数据。
思路
与接口自动化测试思路相同,我们在进行UI自动化测试时,每个Case都是一个单独的TestCase,我们将所有需要执行的case放在同一个TestSuit中,批量执行并生成聚合报告。
难点
......
架构
下面是小编自己从点到面一步步的思考历程,从基本的移动设备远程管理,case编写到case的维护,再到lab平台的搭建:
主流工具调研
目前市面上有很多成熟的UI自动化工具,如,,等等,它们提供了非常便捷的录制服务,我们只需要在idea上拖拖拽拽,马上就可以生成一个简单的UI自动化脚本,且我们只需要将这些工具封装的工具库部署在我们的电脑上就可以多次运行我们编写的case了。
这里我们将分开剖析进行UI自动化用到的录制器和执行器的原理:
case执行的原理
解读其源码我们发现这些工具其实底层的实现原理都基本相同,核心即为:对移动设备的远程控制,并将控制指令封装为可读通用的语法。
其实我们日常使用手机时,手机系统就是通过我们点击的屏幕坐标,从最上层的view依次向下遍历,直到找到该坐标位置下可以响应用户行为的UI控件,执行对应的响应代码。
但是我们在编写case时,如果case中记录的全是在某个坐标下对应的操作行为的话,就会特别的晦涩难懂,且针对不同屏幕尺寸的设备也完全不通用,这显然是行不通的。
真实的用户行为其实无非就是,点击了某个按钮,滑动了某个页面等等,主体其实就是UI控件,我们在编写case时也是一样的,我希望的是对某个UI控件进行操作,那么其实在执行case时,我们完全可以获取该UI控件在当前屏幕中的位置,再去调用底层的控制指令进行操作。
case录制的原理
其实case录制的原理就是上述执行原理的逆向思维,我们可以在移动设备上开启server服务,将移动设备的屏幕影像通过二进制流的形式实时传输给录制器,将移动设备投屏到我们的录制器上。同时还需要实时获取移动设备上的 UI Tree ,当我们在录制器上进行鼠标移动时,利用鼠标在屏幕上的坐标信息从UI tree中遍历对应的UI元素,并打印该元素的所有UI信息。
是不是感觉很复杂,不用担心,已经有成熟的框架 Android Debug Bridge 和 WebDriverAgent为我们提供了这些服务,下面👇会重点介绍的。
与移动设备进行通信的框架

有兴趣的同学可以自行google。
Case管理
解决了case的录制问题,下面我们再来思考case的管理问题,在录制case的过程中我们发现很多case都存在高度可复用模块,如登录模块,可能我们80%的case中都进行了登录操作,若某个版本中登录页面的UI发生了改动,导致元素的path发生了改变,这个时候我们难道要找到所有设计到登录的case,逐个进行修改吗?
其实在编写UI自动化case时,我们同样也需要设计模式,参考业界优秀模式,再结合我司实际场景,整理的大体思路入下:
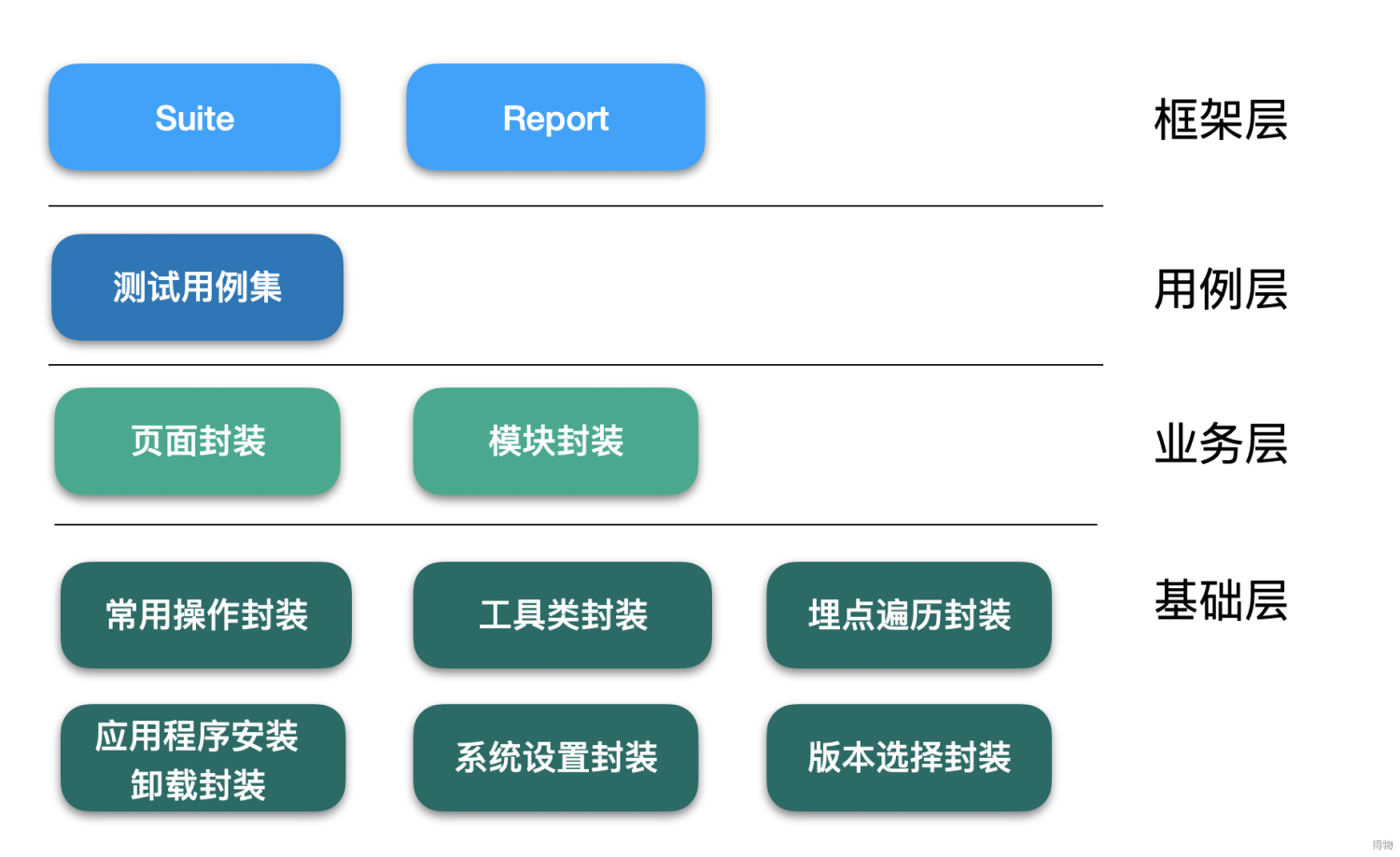
基础层
常用操作封装:抽离重复代码,进行封装;
工具类封装:数据校验,设备信息获取,安装包数据查询,按照包下载等操作;
埋点遍历封装:以单个页面为单位,获取所有可点击,可滑动,可编辑的UI元素,再模拟相应的用户行为;
应用程序安装卸载封装:根据udid获取各版本对应的安装包,进行覆盖安装,或卸载安装;
系统设置封装:切换环境,ab实验,网络环境;
版本选择封装:指定case运行的版本区间。
业务层
页面封装:按照功能划分,如评论相关操作,登录相关操作等,将这些通用部分抽离并封装,供所有测试case调用;
模块封装:进入某个业务模块的前置路基封装等。
用例层
测试用例集:按照业务分子文件夹,包含该业务的所有测试用例。
框架层
suit:存放用于组织不同用例集的Suit类;
report:生成单个case的report报告,和整个suit的聚合报告。
APP安装包管理
接入发布平台,定时轮训获取提测后的测试包和灰度包信息并落库。 表结构如下:
CREATE TABLE `lab_package` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`version` varchar(32) CHARACTER SET utf8mb4 DEFAULT '' COMMENT '版本号',
`buildVersion` varchar(32) CHARACTER SET utf8mb4 DEFAULT '' COMMENT '构建版本号',
`bundleId` varchar(255) CHARACTER SET utf8mb4 DEFAULT '' COMMENT '包ID',
`pkgPath` varchar(255) CHARACTER SET utf8mb4 DEFAULT '' COMMENT '包存储路径,可以用来下载包体',
`platform` varchar(255) DEFAULT NULL COMMENT '平台 ios/android',
`timestamp` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`branch` varchar(255) DEFAULT NULL COMMENT ' 所属分支',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=579001 DEFAULT CHARSET=utf8;在case指定版本范围时,从数据库中查询最新的符合要求的按照包地址(iOS端存在多个不同bundleId的安装包,需要先根据设备的udid获取正确的bundleId),然后下载安装包并安装到运行的设备上。
接入mock平台
UI自动化case运行时,最大的困扰是UI界面的变动。但是如果我们接入mock平台,保障case运行时的界面和case编写时的界面以及数据是完全相同的,那么我们在执行case时校验验证点,将会变的轻而易举。
分布式
前面我们准备工作做好以后,就要考虑case运行的问题了。不同于接口自动化,UI自动化依赖于真实的设备,但是设备资源是有限的,我们在一台Mac上运行时,根据Mac的性能,最多可以同时控制几台设备,但是当我们希望批量运行case时,可能需要在几十台甚至几百台设备上同时运行我们的UI自动化case。此时我们就需要分布式了,搭建一个手机lab集群,由一台server分配任务,多台worker执行任务,远程控制连接在该worker上的移动设备,最后再将所有的report报告进行聚合。
lab框架
语言:python
核心框架:tornado+celery+redis

整体架构:
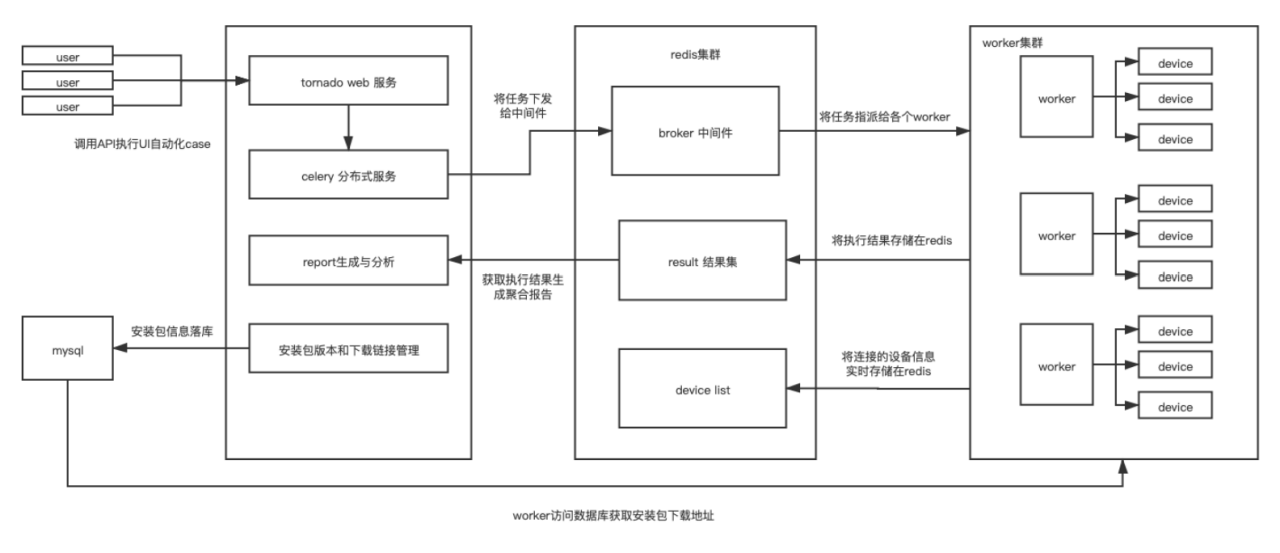
lab主要分两个模块,server调度服务,以及worker集群。当server服务接收到用户执行指令时,会去case仓库遍历符合用户要求的case脚本,由broker中间件将任务分别分配给worker集群,各worker任务执行结束后,会将每个case的执行结果存储到result结果集之中,待任务全部执行结束server会生成总的聚合报告,并将report报告通过飞书发送给用户。
其中worker的整体架构如下:
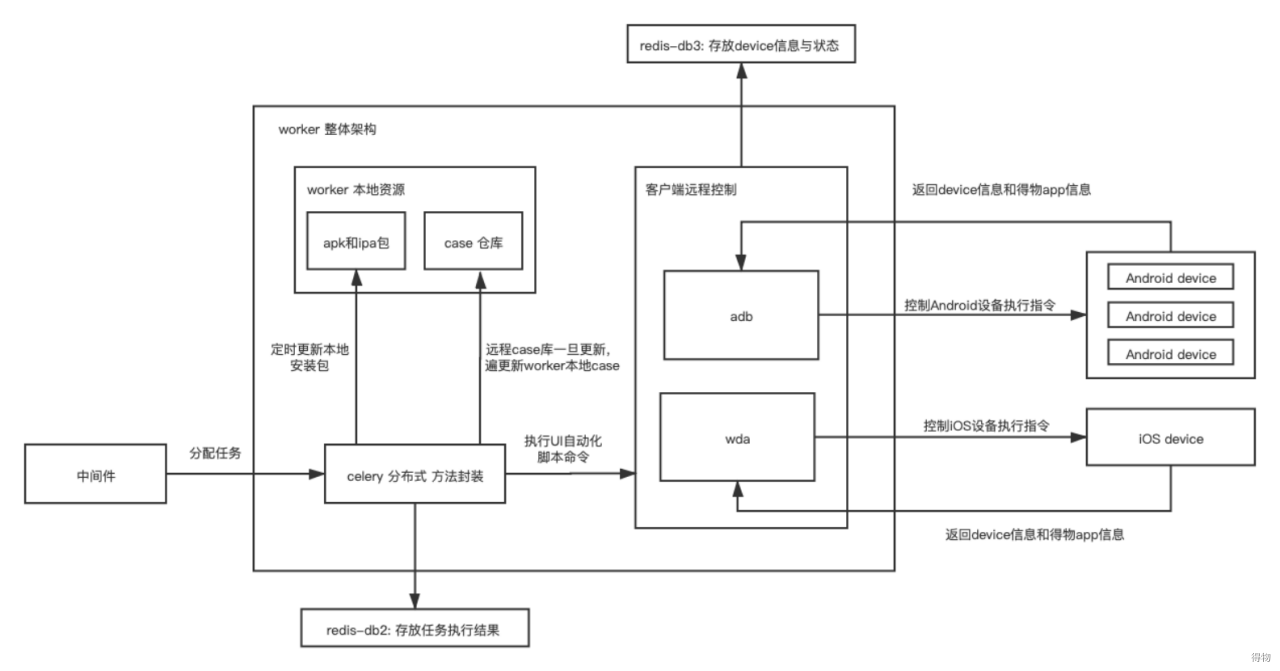
当worker收到任务后,会开启多进程在连接的移动设备上批量执行UI自动化case,
值得一提的是,worker中本地资源的管理,分别是对安装包的管理和对case仓库的管理;
case仓库其实是lab项目的子模块,测试人员在日常case的编写和维护都是在case仓库的项目中完成的,完全不用关心lab项目的维护;当有测试同学push代码到远程仓库时,Jenkins就会调用server服务的接口,由server服务通知各个worker更新case仓库的代码即可,保证worker在批量运行自动化case时,代码是最新的;
安装包的管理:有两种形式,worker服务除了每天定时获取最新的安装包列表缓存到本地外,当case执行时若本地安装包无法满足版本要求,worker也会遍历app安装包的数据库,将适合的安装包缓存在本地并安装到移动设备中;
因为我们的app每天都在进行着很多的版本迭代,相应的我们的case可能只能在部分版本区间中运行,那么我们此时就需要在case中限制版本区间,当case运行时,判读设备中已安装的app版本是否在该区间内,若不存在则下载安装满足要求的版本到移动设备中再去执行case;
更多更细节的设计这里就不再介绍了,有兴趣的同学留言探讨哦~
文|crystal
关注得物技术,携手走向技术的云端