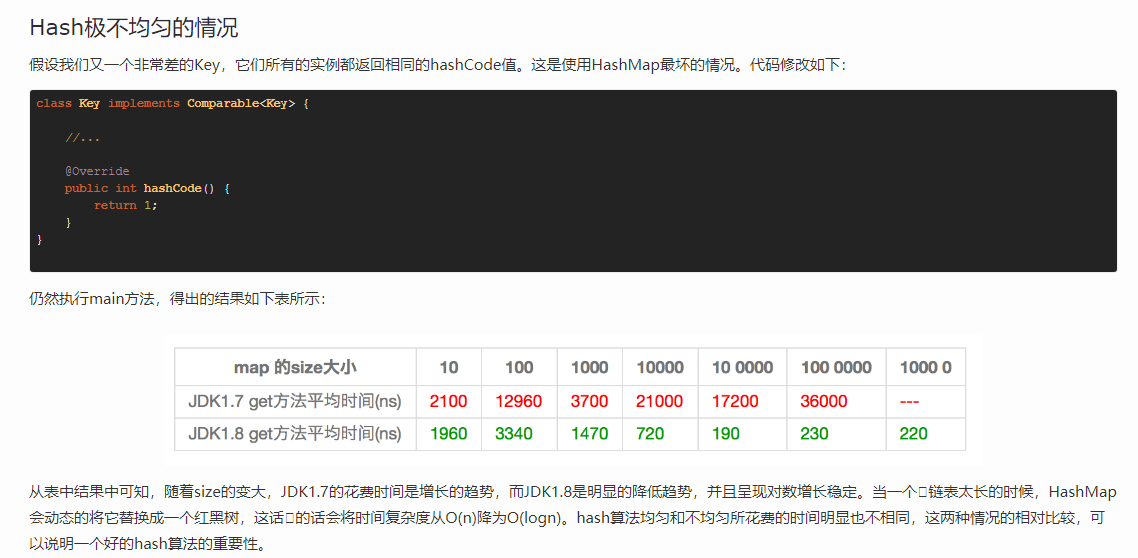
HashMap面试中的12个点
一. 你知道哪些 ?
, , ,
二. 的特点是什么?
三. JDK1.8 中 为什么要引入红黑树 ?
链表 查询时间复杂度 O(n) , 插入时间复杂度O(1)
红黑树 查询和插入时间复杂度都是 O(lgn)
可以参考下 美团技术团队 的这篇文章 https://tech.meituan.com/2016/06/24/java-hashmap.html
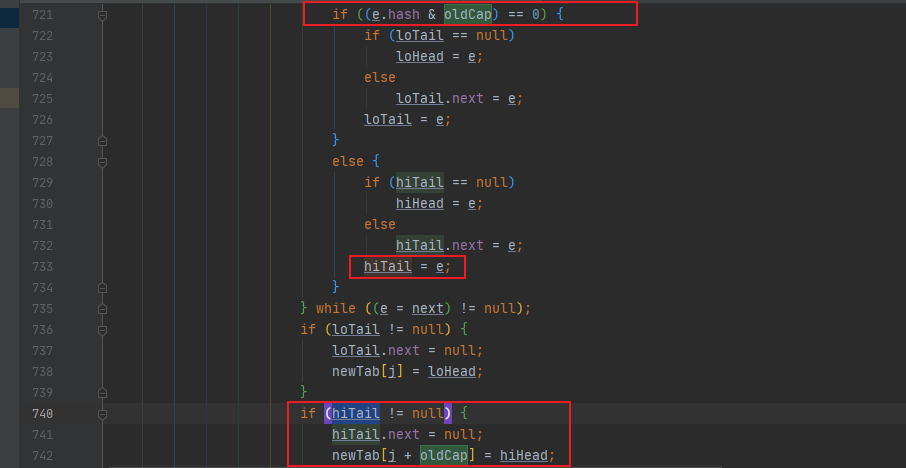
四. 长度为什么只能是2的倍数

元素对应的 index 是通过下面代码赋值的 ,即
if ((p = tab[i = (n - 1) & hash]) == null)
这里 4ye 就直接截取了 中 链表 重新计算 index 的部分,红黑树 中也有类似的代码
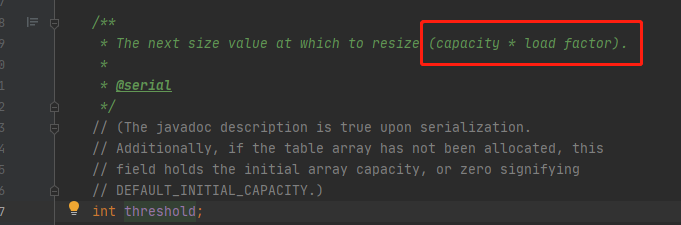
五. 什么时候进行扩容
当( hash 表的大小),> ( hash表的大小 * 负载因子)的值时,则进行扩容

六. 负载因子的大小
负载因子大小决定着 哈希表的扩容 和 哈希冲突 ,每次 put **新元素 **后都要检查,看看需不需要扩容,扩容默认是原来的两倍。
调高负载因子,会增加 hash 冲突的概率 ,同样会增加耗时,扩容本身也会耗时。
七. 怎么计算 hash 值
计算 key 的 hashCode 值,然后将这个值与它的高十六位进行异或运算
这么做是为了减少hash冲突
// >>> 无符号位右移,即不管该数的正负,都在高位补0
// >> 表示右移,如果该数为正,则高位补0,若为负数,则高位补1
// << 左移直接在低位补0,无正负之分
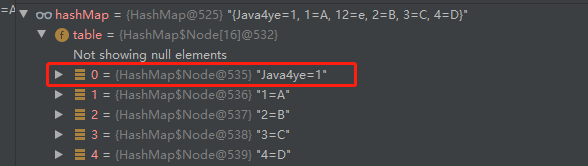
验证下~
int hashCode = "Java4ye".hashCode();
System.out.println((hashCode ^ (hashCode >>> 16))&15);
// 打印出 0
hashMap.put("Java4ye","1");
八. hash 冲突的解决办法
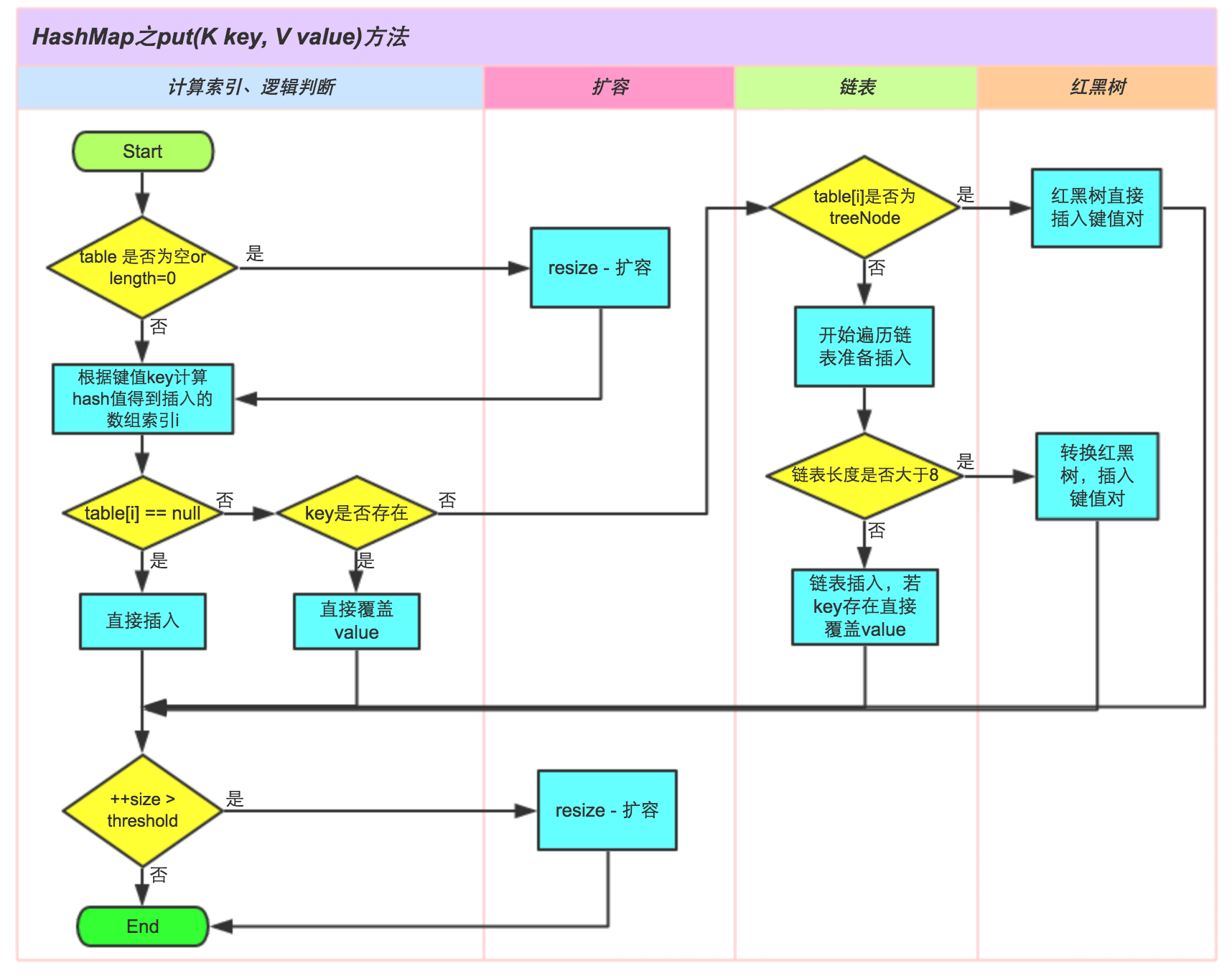
九. put 和 get 的实现
put 时
先计算该 key 的 hash 值,并算出它 所在的 bucket 的 index ,如果没有碰撞的话,直接放到数组中。
如果碰撞了,先判断,这个 key 是不是同一个key,是的话直接覆盖。
不是的话 再去判断当前是 链表 还是 红黑树,再依据不同的情况进行插入,如果 key 一样的话,会根据 的值 或者 原来的值是否为 进行替换或者保留原来的值。
如果是找到对应的key的话,会返回该旧值,不会继续往下执行
如果是增加新元素的话,最后会判断 hash 表的大小,如果 该值 大于 hash表的大小 * 负载因子,则进行扩容;最后返回null
大家可以看看 4ye 给出的这个源码,每一步都做了这个重要的注释了~ ,反正我自己看懂了 哈哈哈哈哈😝
put源码:
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
// 创建Hashmap时是没有去初始化 bucket 的容量的,在put操作时才去扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 这里看看对应的 index 有没有数据,没有就直接放到这里
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 有数据的话,就进入下面去判断,先判断是不是同个key,再判断属于哪种数据结构,红黑树或者链表
else {
Node e; K k;
// 判断是不是同个key
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 判断是不是红黑树
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
// 链表,这里采用的是尾插法!在链表中查找该key,有的话break,没有的话一直找,直到链表中最后一个元素,并加入链表尾部
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果超过这个阈值8,转化成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 判断是不是同个key,是的话跳过
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// e 有值表示 当前 key 有对应的值 如果 onlyIfAbsent 的值为 false 或者当前的 value 为 null 时 则进行覆盖 , 然后 return 该 旧的值。
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// 如果 put 的是一个新元素,则会来到这一步,进行 +1 ,判断是否需要扩容
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
get 的时候也要先计算 key 的 hash 值,然后算出它的 index,接着判断有没有 hash冲突,没有冲突的话,直接返回,有的话需要判断当前的数据结构是链表还是红黑树,然后分别从相应的结构中取出值
这图片来自 美团技术团队 ~
十. 怎么判断一个元素是否相同的呢
先判断他们的 hash 值是否相同,相同的话再判断该 key 的 equals 方法 || == 方法是否相同,相同的话则是同一个元素

十一. 什么情况下会用到红黑树?
可以参考上面的 put 源码 ,主要代码如图:


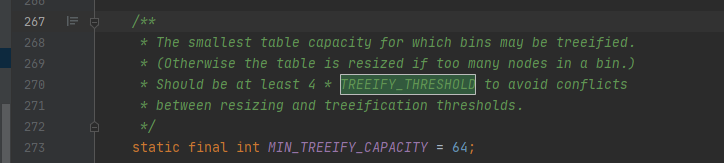
可以看到当数组的大小大于64且链表的长度大于8时,会将链表转换成红黑树。

当红黑树的大小小于等于6时,会转换成链表,参考 源码

十二. 头插法和尾插法
由于 jdk1.7 中 使用的是头插法, 那么新元素总会被放在链表的头部。
比如 大小为 4, key 2,6 ,10 所在的index 都是2
那么当它 扩容的时候,顺序就会变成
index:2,key:10 ,2
index:6,key:6
在多线程环境下,有可能会导致死循环~
比如 线程a 还停留在2.next 6,6.next 10 ,线程b已经完成resize了,变成了10.next2 这时就会进入死循环了。
这也是 HashMap 线程不安全的原因之一。
同样的例子:尾插法不会导致死循环
如:线程a 还停留在2.next 6,6.next 10 ,线程b已经完成resize了,变成了2.next10 了。
使用尾插法并不意味着 HashMap 就是线程安全了,因为你无法保证 put 进去的值,get 出来的还是 put 进去的值
,因为有可能已经被别的线程修改了。
今天就先写这么多啦,觉得还可以的小伙伴别忘了 先收藏呀,面试前看看~
最后
欢迎小伙伴们来一起探讨问题~
如果你觉得本篇文章还不错的话,那拜托再点点赞支持一下呀😝
让我们开始这一场意外的相遇吧!~
欢迎留言!谢谢支持!ヾ(≧▽≦*)o 冲冲冲!!
我是4ye 咱们下期应该……很快再见!! 😆
如果文章对您有所帮助,欢迎关注公众号 J a v a 4 y e 😆