以太坊剖析 - 区块(Block)
区块
以太坊在整体上可以看作一个基于交易的状态机:起始于一个创世区块(Genesis)状态,逐笔执行交易直到其转变为某个版本的最终状态。这里的版本是以区块为单位,所以我们会说某个区块的世界状态。
在以太坊网络中,参与方可以在任意时间,通过任意账户经由任意节点发起一笔交易。此时,交易尚未生效(写入账本),只是由网络中某些节点传播和暂存。以太坊是以区块为单位进行记账,需要担任矿工角色的节点将一定数量的交易打包为区块,然后通过挖矿(PoW共识算法)来争夺下一区块的记账(出块)权,最后拥有记账权的矿工将新区块写入本地账本,并同步给其他节点。节点将区块写入本地账本,包含一系列的操作过程:区块的验证和解析,交易的验证和执行,然后将交易执行后的账户状态数据写入状态数据库,将区块写入账本数据库;也包含一些其他逻辑(比如处理区块分叉)。我们可以发现,区块在以太坊的设计理念中占据重要的地位,与账本结构、记账粒度、PoW共识算法都密切相关。
区块的属性列表:
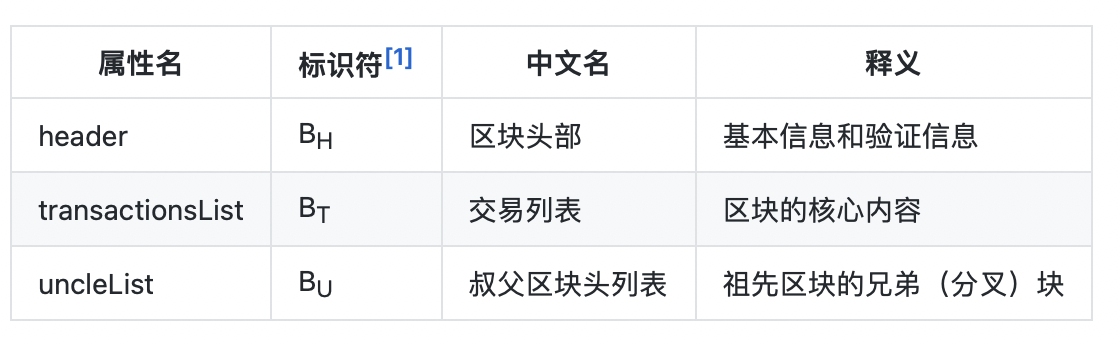
区块头部
区块头部包含一些区块相关的基本信息,以及区块生命周期中关键数据的验证信息,每个区块包含一个区块头部(详见BlockHeader.java的解读)。
//Block.java:L54
private BlockHeader header;
打包新区块是一系列的操作过程,仅区块头部的创建过程就可分为3个阶段:
//BlockchainImpl.java:L482,createNewBlock函数部分代码段
final long blockNumber = parent.getNumber() + 1;//当前区块高度等于父区块高度加1,对应黄皮书的40公式
final byte[] extraData = config.getBlockchainConfig().getConfigForBlock(blockNumber).getExtraData(minerExtraData, blockNumber);
Block block = new Block(parent.getHash(),//获取父区块头部哈希值,对应黄皮书的39公式
EMPTY_LIST_HASH, // uncleHash
minerCoinbase,
new byte[0], // log bloom - from tx receipts
new byte[0], // difficulty computed right after block creation
blockNumber,
parent.getGasLimit(), // (add to config ?)
0, // gas used - computed after running all transactions
time, // block time
extraData, // extra data
new byte[0], // mixHash (to mine)
new byte[0], // nonce (to mine)
new byte[0], // receiptsRoot - computed after running all transactions
calcTxTrie(txs), // TransactionsRoot - computed after running all transactions//根据交易列表,计算区块头部的交易树根节点哈希值(txTrieRoot)属性,对应黄皮书的31公式的Ht部分
new byte[] {0}, // stateRoot - computed after running all tranxsactions
txs,
null); // uncle list
for (BlockHeader uncle : uncles) {//根据叔父块列表,计算区块头部unclesHash属性,对应黄皮书的31公式的部分逻辑
block.addUncle(uncle);
}
block.getHeader().setDifficulty(ByteUtil.bigIntegerToBytes(block.getHeader().//计算区块头部的难度值,对应黄皮书41、42、43、44、45、46公式
calcDifficulty(config.getBlockchainConfig(), parent.getHeader())));
//BlockchainImpl.java:L507,createNewBlock函数部分代码段
Repository track = repository.getSnapshotTo(parent.getStateRoot());//根据父区块的世界状态树的根节点哈希值(Hr),获取对应版本的世界状态,对应黄皮书的33公式
BlockSummary summary = applyBlock(track, block);
List receipts = summary.getReceipts();
block.setStateRoot(track.getRoot());//行507-510:计算世界状态树的根节点哈希值,并赋值给区块头部的stateRoot属性,对应黄皮书的31公式的Hr部分和169公式
Bloom logBloom = new Bloom();
for (TransactionReceipt receipt : receipts) {
logBloom.or(receipt.getBloomFilter());
}
block.getHeader().setLogsBloom(logBloom.getData());//行512-516:根据交易收据列表中的Bloom过滤器信息,计算区块头部的日志Bloom属性,对应黄皮书的31公式的Hb部分
block.getHeader().setGasUsed(receipts.size() > 0 ? receipts.get(receipts.size() - 1).getCumulativeGasLong() : 0);//根据交易收据列表,取最后一个交易收据的Gas累计使用量,对应黄皮书的158公式
block.getHeader().setReceiptsRoot(calcReceiptsTrie(receipts));//根据交易收据列表,计算区块头部的交易收取哈希值,对应黄皮书的31公式的He部分逻辑
//Ethash.java:L343
protected void postProcess(MiningResult result) {
Pair pair = hashimotoLight(block.getHeader(), result.nonce);
block.setNonce(longToBytes(result.nonce));//获取Ethash PoW参数中随机数,赋值给区块头部的nonce属性,对应黄皮书的167公式
block.setMixHash(pair.getLeft());//获取Ethash PoW函数返回值中的工作量证明哈希,赋值给区块头部的mixHash属性,对应黄皮书的168公式
}
交易列表
组成当前区块的一些交易,整个区块的核心内容,一个区块中包含多笔交易(详见Transaction.java的解读)。
//Block.java:L57
private List transactionsList = new CopyOnWriteArrayList<>();
单个区块可以包含的交易数量,与区块头部的gasLimit属性有关,因为每笔交易的执行都需要消耗一定数量的gas,以太坊通过设定单个区块可以使用的gas数量,来控制区块大小。
叔父区块头列表
祖先区块的兄弟(分叉)块,在给定高度范围内,选择一定数量的叔父区块头部进行打包。
//Block.java:L60
private List uncleList = new CopyOnWriteArrayList<>();
区块打包时,矿工可以在叔父块中按照规则选取一定数量的叔父块,将其区块头打包到区块中。具体选取方法是:
//BlockMiner.java:L207
protected List getUncles(Block mineBest) {
List ret = new ArrayList<>();
long miningNum = mineBest.getNumber() + 1;
Block mineChain = mineBest;
long limitNum = max(0, miningNum - UNCLE_GENERATION_LIMIT);
Set ancestors = BlockchainImpl.getAncestors(blockStore, mineBest, UNCLE_GENERATION_LIMIT + 1, true);
Set knownUncles = ((BlockchainImpl)blockchain).getUsedUncles(blockStore, mineBest, true);
knownUncles.addAll(ancestors);
knownUncles.add(new ByteArrayWrapper(mineBest.getHash()));
if (blockStore instanceof IndexedBlockStore) {
outer:
while (mineChain.getNumber() > limitNum) {
List genBlocks = ((IndexedBlockStore) blockStore).getBlocksByNumber(mineChain.getNumber());
if (genBlocks.size() > 1) {
for (Block uncleCandidate : genBlocks) {
if (!knownUncles.contains(new ByteArrayWrapper(uncleCandidate.getHash())) &&
ancestors.contains(new ByteArrayWrapper(blockStore.getBlockByHash(uncleCandidate.getParentHash()).getHash()))) {
ret.add(uncleCandidate.getHeader());
if (ret.size() >= UNCLE_LIST_LIMIT) {
break outer;
}
}
}
}
mineChain = blockStore.getBlockByHash(mineChain.getParentHash());
}
} else {
logger.warn("BlockStore is not instance of IndexedBlockStore: miner can't include uncles");
}
return ret;
}
区块序列化
区块的RLP序列化的属性顺序:BH, BT, BU
//Block.java:L425
public byte[] getEncoded() {//行425-436:getEncoded,函数,获取区块内容的RLP编码字节数组,参与RLP编码的区块属性依次为:header(含nonce)、transactionsList、uncleList。
if (rlpEncoded == null) {//此函数被当前类和BlockchainImpl.java、IndexedBlockStore.java、BlockMiner.java、SyncManager.java等源文件引用。
byte[] header = this.header.getEncoded();
List block = getBodyElements();//获取区块体:交易列表、叔父块列表
block.add(0, header);//区块序列化顺序:区块头、区块列表、叔父块列表
byte[][] elements = block.toArray(new byte[block.size()][]);
this.rlpEncoded = RLP.encodeList(elements);//行426-433:区块的RLP序列化的属性顺序:区块头部、交易列表、叔父块列表,对应黄皮书的35、36公式
}
return rlpEncoded;
}