Kafka集群缩容实战
CDH 版本5.15.1,Kafka版本1.0.1
由于历史原因,我们有两套Kafka集群,老集群的规模对于它所承载的流量有些过剩,为了充分利用资源,需要对老集群进行缩容。
本文记录了Kafka集群缩容的过程,仅供参考。
缩容过程中用到的脚本已经上传到github:https://github.com/iamabug/kafka-shrink-scripts
公众号:大数据学徒
缩容思路
假设集群有15台机器,预计缩到10台机器,那么需要做5次缩容操作,每次将一个节点下线,那么现在问题就是如何正确、安全地从Kafka集群中移除一台broker?搞定这个之后,重复5次即可。
众所周知,一个broker下线,它上面的所有partition都会处于副本不足的状态,并且Kafka集群不会在其它的broker上生成这些副本,因此,在将一个broker从集群中移除之前,需要将这个broker上的partition副本都转移到最终会保留的10台机器上,怎么实现这个呢?Kafka自带的分区重分配工具。
在集群数据量较大的情况下,分区的转移可能会花费较长时间,那么在转移过程中最好不要创建新topic,不然新的topic有可能又创建到要被移除的broker上,当然如果实在无法避免的话,可以再对新的topic进行一次额外的转移。
总结一下,从Kafka集群中移除一个broker的步骤如下:
其中重点是partition的转移或者说重分配。
分区重分配
分区重分配主要使用的是kafka-reassign-partitions脚本,参考的说明,这个脚本有三种模式:
--generate,给定topic列表和broker列表,生成一个备选的重分配方案,重分配方案是一个JSON;
--execute,根据一个JSON文件里的重分配方案,进行分区重分配;
--verify,根据集群当前partition的分布情况,验证和JSON文件提供的重分配方案是否一致;
根据这个脚本的使用方式,分区重分配包括以下几步。
获取broker id
在测试集群的CM中Kafka的配置页面里,在搜索栏里输入“id”,可以看到broker id和主机名的对应关系:

可以看到,共有5个broker,broker id分别为150,151,152,165,294,选择 294 作为被移除的broker。
获取topic列表及输出格式转换
使用 脚本获取集群所有的topic:
$ kafka-topics --list --zookeeper ${ZK_HOSTS}把输出的topic列表保存在 里,然后用python脚本把它处理成json格式:
import json
obj = {}
obj["version"] = 1
obj["topics"] = []
with open("topics.txt") as f:
for line in f.readlines():
topic = {"topic": line.strip()}
obj["topics"].append(topic)
with open("topics.json", "w") as f:
json.dump(obj, f, indent=2)输出的json文件是 ,其中的内容格式如下:
{
"version": 1,
"topics": [
{
"topic": "first"
},
{
"topic": "second"
},
...
]
}获取当前partition分配方案
使用 脚本的 来获取当前的partition分配方案:
$ kafka-reassign-partitions --zookeeper ${ZK_HOSTS} --topics-to-move-json-file topics.json --broker-list "150,151,152,165" --generate
# 注意 --broker-list 这个参数传入的值里面没有 294 这个broker id这个命令会有非常多的输出,分为两部分,一部分是当前partition的分配情况,一部分是这个脚本生成的重分配方案:
Current partition replica assignment
{
"version": 1,
"partitions": [
{
"topic": "first",
"partition": 0,
"replicas": [150, 151, 294]
},
...
]
}
Proposed partition reassignment configuration
{
"version": 1,
"partitions": [
{
"topic": "first",
"partition": 0,
"replicas": [150, 151, 165]
},
...
]
}可以看到,脚本生成的重分配方案里面,replicas里面是没有 294 这个broker id的。
注意:通过比较可以发现,脚本生成的重分配方案不光将原来在294上的partition转移到了其它broker上,即使和294无关的partition也会被调整,这样既增大了重分配的耗时,也带来不必要的leader切换,不是特别理想,在这种情况下,可以手动生成重分配方案。
生成重分配方案
我希望的重分配方案是:把partition从待移除的broker上转移到不会被移除的broker上,且不存在同一partition的两个副本在同一个broker上的情况即可。
将上一步输出的当前分配方案保存到为 ,然后使用python脚本进行处理:
import json
import random
BROKER_ID = 294
# 不会被移除的broker id列表
BROKER_IDS = [150, 151, 152, 165]
n = len(BROKER_IDS)
topics = {}
with open("current.json") as f:
topics = json.load(f)
# 遍历每个partition
for partition in topics["partitions"]:
# 遍历当前partition的每个副本
replicas = partition['replicas']
for i in range(len(replicas)):
# 当前副本需要转移
if replicas[i] == BROKER_ID:
# 随机生成一个broker id,确保新的副本不和当前partition的其他副本在同一个broker上
choice = random.randint(0, n-1)
while BROKER_IDS[choice] in replicas:
choice = random.randint(0, n-1)
#print("before: ", replicas)
replicas[i] = BROKER_IDS[choice]
#print("after: ", replicas)
with open("reassigned.json", "w") as f:
json.dump(topics, f, indent=2)生成的重分配方案保存在 中。
执行分区重分配
执行分区重分配命令:
$ kafka-reassign-partitions --zookeeper ${ZK_HOSTS} --reassignment-json-file reassigned.json --execute这个命令是在后台运行的,如果你安装了kafka-manager的话,可以在“Reassign Partitions”页面看到状态:
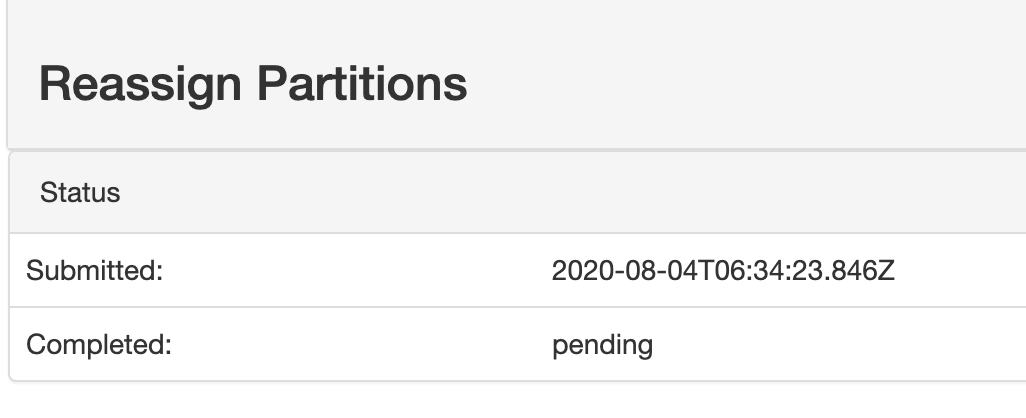
pending 表示还未完成。
参考时间:15个节点、160T总磁盘占用的Kafka集群对一个节点做分区重分配大约花费时间为6个小时。
注意事项
在分区重分配的过程中,因为partition的leader会发生切换,客户端有可能报 的错,这个报错一般来说是可恢复的,但还是需要密切关注。
验证
可以通过三种方式进行验证:
$ kafka-reassign-partitions --zookeeper ${ZK_HOSTS} --reassignment-json-file reassigned.json --verify | grep -v successsfully在重分配完成之前会得到很多类似 的输出,完成之后执行的话就没有太多输出。
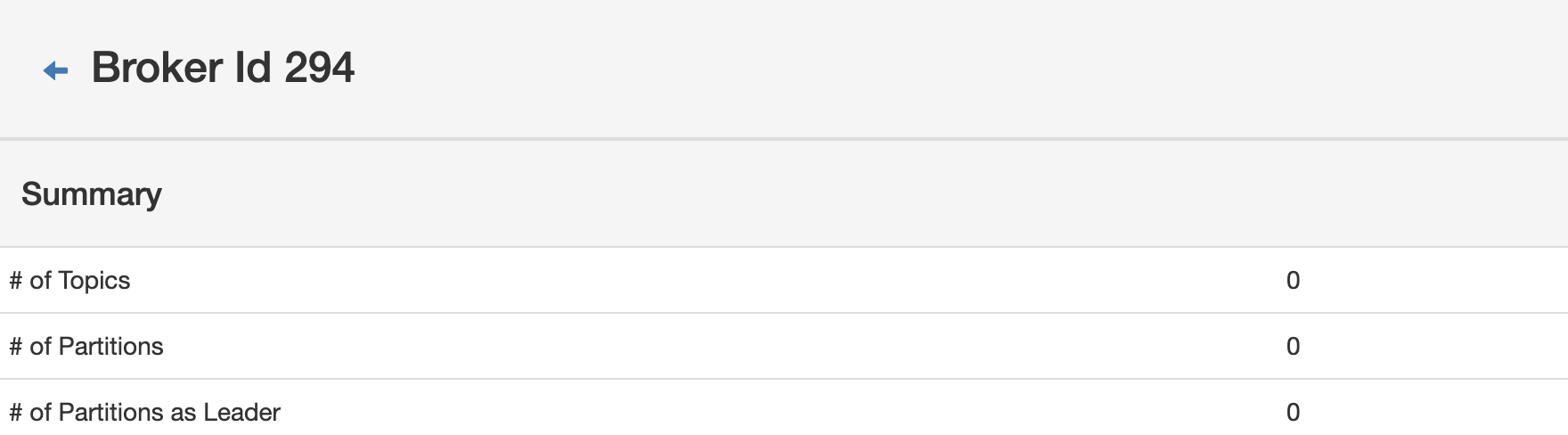
topic数、分区数都是0,符合预期。
# 假设kafka的数据目录为/data*/kafka/data
$ ls /data*/kafka/data
/data01/kafka/data:
cleaner-offset-checkpoint meta.properties replication-offset-checkpoint
log-start-offset-checkpoint recovery-point-offset-checkpoint
/data02/kafka/data:
cleaner-offset-checkpoint meta.properties replication-offset-checkpoint
log-start-offset-checkpoint recovery-point-offset-checkpoint
...可以看到,kafka的数据目录下只剩下kafka自己的数据文件,分区重分配成功。
broker下线
确认待移除的broker上没有任何分区之后,在CM里,先停止broker,再删除broker,broker下线完成。
根据需要下线的broker数量,重复上面的操作,就可以实现多台broker的缩容。
欢迎批评指正沟通建议。
公众号:大数据学徒