CI/CD之基于Jenkins的发布平台实践
现状
由于历史原因,公司各个团队维护了好几套Jenkins,流水线使用方式也各有差异,导致配置碎片化严重,基本不可维护,而且流程冗长低效,难以复用。另外,Jenkins流水线UI可配置性较差,不利于功能迭代。
目标
改造合并现有流程,提供统一的流水线模版
使用Jenkins pipeline as code功能特性
提供统一的发布入口,对外屏蔽Jenkins
Jenkins multibranch pipeline简介
是Jenkins提供的一大亮点,它可以很方便的让你生成一个工作流水线,并且使用groovy脚本语言,可以让你写Java代码方式处理流水线逻辑。
multibranch pipeline是pipeline的一个扩展,主要是针对常用的分支开发模式提供支持。在配置了Jenkins流水线所依赖的pipeline文件后,Jenkins会去扫描仓库中的所有分支,对每个分支如果有匹配的pipeline文件,则Jenkins会将该作为一个pipeline任务,整个multibranch项目会是一个pipeline任务的集合。
Pipeline as code
经过对现有Jenkins流水线使用方式的调研,主要分为几大类:
Java应用
Python应用
Javascript应用
其他特殊流程应用
我们为这几类使用方式都做了分析,移除非必须流程节点,抽象成若干个流程模版,对外只暴露模版,对工程师透明,模版内部则使构建流程代码化,易于组装复杂流程。
举个例子,Java业务方的Jenkinsfile是这样的:
PlatCI(this)而Python工程的业务方的Jenkinsfile是这样的:
ErpCI(this)下面我将介绍下模版背后的实现原理
配置使用Global Pipeline Library
首先需要在Jenkins上配置一个全局共享库(),如下图所示:
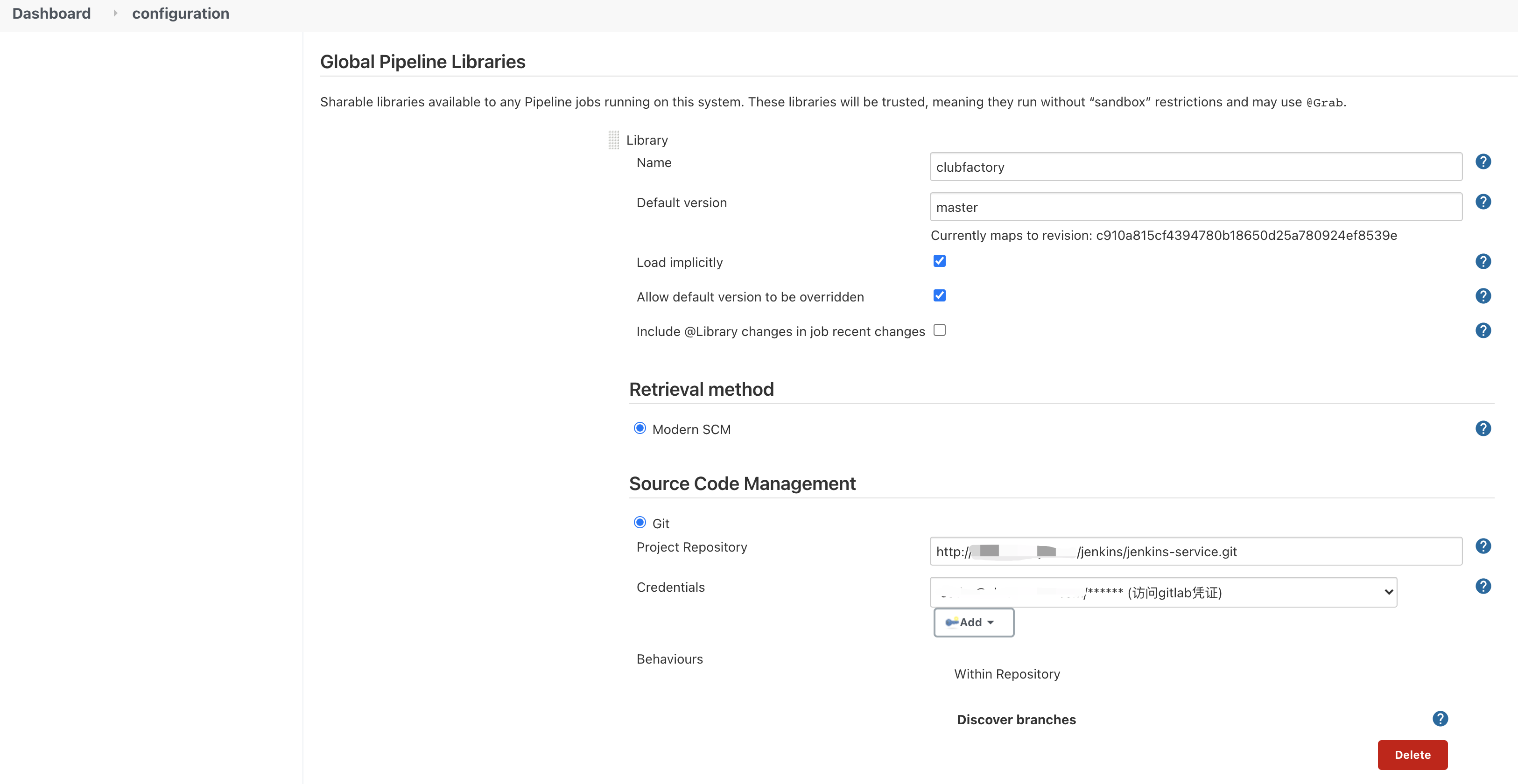
项目仓库需要满足下述要求:
(root)
+- src # Groovy source files
| +- org
| +- foo
| +- Bar.groovy # for org.foo.Bar class
+- vars
| +- foo.groovy # for global 'foo' variable
| +- foo.txt # help for 'foo' variable
+- resources # resource files (external libraries only)
| +- org
| +- foo
| +- bar.json # static helper data for org.foo.Bar简单来说,就是vars目录下.groovy后缀的文件即是可以暴露出去的全局变量,src目录下是辅助全局变量脚本所需的其他文件。
全局变量的实现
首先是调用入口,如下:
/**
* Declarative Pipeline
* Java 语言pipeline入口
*
* @param WorkflowScript
* @return
*/
def call(Object WorkflowScript) {
pipeline {
environment {
// YYYY-mm-dd-{hash:6}
SIG = sh(
returnStdout: true,
script: 'echo $(date +%Y-%m-%d)-$(git rev-parse --short HEAD)'
).trim()
}
stages{
stage('构建'){
}
stage('部署'){
}
}
}
}而对于辅助该pipeline的src目录,则是完全按照项目开发进行组织管理,按功能模块进行了划分,比如控制器层
Build
Deploy
还有服务层包括:
WechatService
ReportService
在pipeline执行中,最核心的是如何让指定worker节点执行相应的任务,这里我们封装了一个工具类 如下:
class Launch implements Serializable {
@NonCPS
static def runSlaveSsh(nodeName, command, pipeline, workspace) {
def listener = pipeline.getContext(TaskListener.class)
// 获取构建节点
String slaveNodeName = nodeName
if (pipeline.hasProperty('siteNodes')) {
slaveNodeName = pipeline.siteNodes[nodeName] ?: nodeName
}
def slave = Jenkins.get().getNode(slaveNodeName)
if (!slave) {
// master 即是主节点
if (nodeName=="aws-usa" || nodeName == "master") {
slave = Jenkins.get()
} else {
throw new Exception("构建节点:${nodeName} 不可用!")
}
}
listener.getLogger().println('[inner-command-start]\nnodeName = ' + nodeName + '\nslaveName = ' + slave.getNodeName() + '\nworkspace = ' + workspace + '\n' + command + '\n[inner-command-end]\n')
def proc = slave.createLauncher(listener)
.launch()
.cmds("bash","-l", "-c", """${command}""")
.quiet(true)
.readStdout()
.readStderr()
.pwd(workspace)
.start()
def result = leftShift(listener.getLogger(), proc.getStdout())
int rc = proc.join()
if(rc != 0) {
return [rc, result.takeRight(10).join('\n')]
} else {
return [rc, null]
}
}
@NonCPS
static def leftShift(output, input) {
List result = []
input.eachLine {
output.println(it)
result.add it
}
return result
}
} 最后,贴上完整的全局变量实现
import com.clubfactory.Logger
import com.clubfactory.Utils
import com.clubfactory.model.StageException
import com.clubfactory.controller.*
import com.clubfactory.service.*
import groovy.transform.Field
// 脚本类变量, 接收外部传进来的值, 在call中初始化
@Field String Language // 语言类别
@Field String AppExec // 自定义启动命令
@Field String StopHookCommand // 自定义停止命令
@Field String AppName // 应用名称
@Field String JarFile // 运行jar包的相对路径,可以不填,如果不填的化默认通过 ${MainModule}/target/${MainModule}*.jar 查找
@Field String HealthUrl // url for health check
@Field Integer HealthTimeout// 健康检查时间
@Field Boolean UseLoadBalancer
@Field List> LoadBalancers // [{"env": "dev", "region": "aws-usa", "name": "lb1,lb2", "targetServerPort": 7777}]
@Field Set Infoee // 消息通知人
@Field Boolean Apollo // 部分项目需要用apollo区分环境
@Field Boolean QaTest // 运行Qa测试
@Field String QaCommand
@Field String SwaggerToken
@Field Logger logger
@Field List Ips = [] //最终部署的服务器
@Field Set siteUsed = [] //最终使用的站点
@Field Map siteNodes = [:] //站点使用的Node节点名
@Field Map Works = [:] //编译目录
@Field Map build = [:] // owl自动构建传递参数, version2
@Field String RollbackArtifact = '' // 回滚包
@Field Boolean continueDeploy = false //是否属于继续部署
@Field String deployMode = '' // 部署模式,WAR :war包部署, EXPLODED_JAR :exploded jar部署,默认空值普通jar包部署
@Field String buildMode = '' // 编译构建模式
@Field String JvmOptions = ''
def javaDeploy0(String ipInfo, Deploy clubDeploy) {
echo '[' + new Date() + '] start deploy ' + ipInfo
def (plat, snd, trd) = ipInfo.split(':',-1) + [null]
if (plat == 's3' || plat == 'oss') {
if (snd && trd) {
clubDeploy dir: '' to plat bucket trd region snd strip ''
} else {
clubDeploy dir: '' to plat bucket snd region '' strip ''
}
}else {
def (platform, loc, u, ip, port) = ipInfo.split(':',-1) + [null]
String ENV = build['env']
def SPRING_PROFILE = Apollo ? "${ENV}-${platform}-${loc}" : ENV
def debugPort = build['debugPort'] ?: ''
clubDeploy platform: platform, loc: loc, files: "", user: "${u ?: 'admin'}" via 'ssh' host "${ip}" port "${port ?: '22'}" directory "\$HOME/apps/${AppName}" hook """
mkdir -p \$HOME/envs
echo "export APP=\\\"${AppName}\\\"" > \$HOME/envs/${AppName}.env
echo "export ENV=\\\"${ENV}\\\"" >> \$HOME/envs/${AppName}.env
echo "export ENV_ORIGIN=\\\"${ENV}\\\"" >> \$HOME/envs/${AppName}.env
echo "export JVM_OPTIONS=\\\"${JvmOptions}\\\"" >> \$HOME/envs/${AppName}.env
echo "export DEBUG_PORT=\\\"${debugPort}\\\"" >> \$HOME/envs/${AppName}.env
echo "export MAIN_MODULE=\\\"${build['mainModule']}\\\"" >> \$HOME/envs/${AppName}.env
echo "export SPRING_PROFILE=\\\"${SPRING_PROFILE}\\\"" >> \$HOME/envs/${AppName}.env
echo "export JAR=\\\"${JarFile}\\\"" >> \$HOME/envs/${AppName}.env
echo "export DEPLOY_MODE=\\\"${deployMode}\\\"" >> \$HOME/envs/${AppName}.env
echo "export COMMAND=\\\"${AppExec}\\\"" >> \$HOME/envs/${AppName}.env
echo "export STOP_HOOK_COMMAND=\\\"${StopHookCommand}\\\"" >> \$HOME/envs/${AppName}.env
echo "export HEALTH_URL=\\\"${HealthUrl}\\\"" >> \$HOME/envs/${AppName}.env
echo "export HEALTH_TIMEOUT=\\\"${HealthTimeout}\\\"" >> \$HOME/envs/${AppName}.env
echo "export IP_INFO=\\\"${ipInfo}\\\"" >> \$HOME/envs/${AppName}.env
bash \$HOME/apps/${AppName}/${Language}.sh restart ${AppName}
""".stripIndent()
}
}
def javaDeploy(List Ips, Deploy clubDeploy) {
def tasks = [:]
Ips.eachWithIndex { it, batch ->
def ip
def (platform, loc) = it.split(':',-1) + [null]
if(platform == 's3' || platform == 'oss'){
ip = it
}else{
def (p, l, u, host, port) = it.split(':',-1) + [null]
ip = host
}
def label = "[${build['env']}-${build['serialId']}-第${build['currentNum']}批] " + ip
tasks[label] = {
javaDeploy0(it, clubDeploy)
}
}
parallel tasks
}
def customTestScript(Wechat wechat){
def testMsg = ''
if (QaTest && 'master' == env.BRANCH_NAME){
testMsg = sh script: """${QaCommand}""", returnStdout: true
wechat.testInfo(testMsg,AppName)
}
echo testMsg
}
/**
* Declarative Pipeline
* Java 语言pipeline入口
*
* @param WorkflowScript
* @return
*/
def call(Object WorkflowScript) {
// currentBuild.currentResult 只在pipeline范围内有效,故用pipelineStatus做脚本全局状态
int pipelineStatus = 1
try {
logger = new Logger(this)
// 初始化部件
def clubDeploy = new Deploy(this)
def clubBuild = new Build(this)
def wechat = new Wechat(this)
def k8sService = new K8sService(this)
// 报错信息
ERRMSG = ''
SEND_IPS = []
// pipeline workflow
pipeline {
environment {
// YYYY-mm-dd-{hash:6}
SIG = sh(
returnStdout: true,
script: 'echo $(date +%Y-%m-%d)-$(git rev-parse --short HEAD)'
).trim()
// Commit ID
COMMIT = sh(
returnStdout: true,
script: 'echo $(git rev-parse --short HEAD)'
).trim()
// commit log
COMMIT_LOG = sh(
returnStdout: true,
script: "git log --format=%B -n 1 ${COMMIT} | xargs -I{} echo {}\\| | xargs"
).trim()
// Tool Path
MAVEN_HOME = tool 'M3' // maven:3
BUILD_INFO = currentBuild.build().getCauses()[0].getShortDescription()
}
agent { node 'master' }
parameters {
string(name: 'build', defaultValue: '', description: "owl平台发起的调用参数,json格式")
}
stages {
stage('检查') {
when {
expression {
if(BUILD_INFO == 'Branch event'){
return false
}
// 首次部署,属于空跑,带默认参数,直接忽略
return env.BUILD_NUMBER != '1'
}
}
steps {
script {
try {
echo 'JENKINS START TO PREPARE'
echo "pipeline start time: " + new Date()
echo "original params: " + params
build = Utils.parseJson(params.build)
AppName = build['appName']
Language = build['language']
HealthUrl = build['healthUrl']
HealthTimeout = (Integer)build['healthTimeout'] ?: 150
UseLoadBalancer = build['useLoadBalancer'] ?: false
LoadBalancers = (List)build['loadBalancers'] ?: Collections.emptyList()
JvmOptions = build['jvmOptions'] ?: ''
Apollo = build['apolloProfile'] ?: false
QaTest = build['qaTest'] ?: false
QaCommand = build['qaCommand'] ?: ''
SwaggerToken = build['swaggerToken'] ?: ''
AppExec = build['appExec'] ?: ''
StopHookCommand = build['stopHookCommand'] ?: ''
buildMode = build['buildMode'] ?: ''
deployMode = build['deployMode'] ?: ''
JarFile = build['jarFile'] ?: ''
continueDeploy = (build["currentNum"] != 1)
String allIps = build["allIps"] ?: ''
String currentIps = build["currentIps"] ?: ''
if(allIps != ''){
siteUsed = Utils.mergeBuildSite(Utils.formatDeployIp(allIps.split(",",-1).toList()))
}
if(continueDeploy && currentIps != ''){
//owl继续部署,只需要当前部署IP列表确认在哪个jenkins节点执行
siteUsed = Utils.mergeBuildSite(Utils.formatDeployIp(currentIps.split(",",-1).toList()))
}
Ips = Utils.formatDeployIp(currentIps.split(",",-1).toList())
Infoee = (Set)build['infoee'] ?: []
// 本次部署包
RollbackArtifact = AppName + "-" + env.SIG + ".tar.gz"
// 规则检查
// #1: java项目需要指定执行模块
if (Language == 'java' && !build.containsKey('mainModule') && !build['s3ossApp']) {
throw new Exception('java语言必须指定模块名称')
}
if (Language == 'java' && HealthUrl == '' && !build['s3ossApp']) {
throw new Exception('未提供健康检查URL, 点击链接添加 http://owl.yuceyi.com/#/application/index')
}
echo "---部署参数---"
echo "triggered by user: " + build["deployUser"]
echo "the parsed autoBuild param is:"
StringBuilder sb = new StringBuilder()
for(Map.Entry entry : build.entrySet()){
sb.append(entry.key).append("=").append(entry.value).append("\n")
}
echo sb.toString()
echo "siteUsed: " + siteUsed
echo "to be deployed Ips: " + Ips
if(Ips.size() == 0 && !build['useK8S']){
throw new Exception("can not recognize deploy ips.")
}
if(build['useK8S'] && (build['site'] == null || build['site'] == '')){
throw new Exception("param 'site' is empty! must specify the k8s site when deploy to k8s cluster.")
}
} catch (e) {
ERRMSG = e.message ?: "${e}"
throw new StageException('prepare',ERRMSG, e)
}
}
}
}
// 这个stage只是为了给构建阶段提供一个日志搜素入口
stage ('post-prepare'){
when {
expression {
if(BUILD_INFO == 'Branch event'){
return false
}
// 首次部署,属于空跑,带默认参数,直接忽略; 继续部署使用先前的构建包
return env.BUILD_NUMBER != '1'
}
}
steps {
script {
echo 'JENKINS END TO PREPARE ' + AppName
// 通知检查完成
if (!continueDeploy) {
new Report(this).sendResultToDeployPlatform(env.BUILD_NUMBER == '1', currentBuild.currentResult == 'SUCCESS' ? 1 : -1, "prepare")
}
}
}
}
// 这个stage只是为了给构建阶段提供一个日志搜素入口
stage ('pre-build'){
when {
expression {
if(BUILD_INFO == 'Branch event'){
return false
}
// 首次部署,属于空跑,带默认参数,直接忽略; 继续部署使用先前的构建包
return env.BUILD_NUMBER != '1'
}
}
steps {
script {
echo 'JENKINS START TO BUILD ' + AppName
}
}
}
stage('构建') {
when {
expression {
if(BUILD_INFO == 'Branch event'){
return false
}
// 首次部署,属于空跑,带默认参数,直接忽略; 继续部署使用先前的构建包
return env.BUILD_NUMBER != '1'
}
}
failFast true
parallel {
stage('亚马逊美西子节点') {
when {
beforeAgent true
expression { return siteUsed.contains('aws-usa') || build['site'].equals('aws-oregon') }
}
agent { label 'aws-usa' }
steps {
script {
try {
siteNodes['aws-usa'] = env.NODE_NAME
Works['aws-usa'] = env.WORKSPACE
if(!build['rollback'] && !build['onlyRestart'] && !continueDeploy){
clubBuild platform: 'aws', loc: 'usa', apollo: Apollo
}
} catch (e) {
echo "build encounter error. \n ${e}"
ERRMSG = e.message
throw new StageException('build',ERRMSG, e)
}
}
}
}
stage('阿里云杭州') {
when {
beforeAgent true
expression { return siteUsed.contains('aliyun-hangzhou') || build['site'].equals('aliyun-hangzhou') }
}
agent { label 'aliyun-hangzhou' }
steps {
script {
try {
siteNodes['aliyun-hangzhou'] = env.NODE_NAME
Works['aliyun-hangzhou'] = env.WORKSPACE
if(!build['rollback'] && !build['onlyRestart'] && !continueDeploy){
clubBuild platform: 'aliyun', loc: 'hangzhou', apollo: Apollo
}
} catch (e) {
echo "build encounter error. \n ${e}"
ERRMSG = e.message ?: "${e}"
throw new StageException('build',ERRMSG, e)
}
}
}
}
}
}
stage ('post-build'){
when {
expression {
if(BUILD_INFO == 'Branch event'){
return false
}
// 首次部署,属于空跑,带默认参数,直接忽略; 继续部署使用先前的构建包
return env.BUILD_NUMBER != '1'
}
}
steps {
script {
echo 'JENKINS END TO BUILD ' + AppName
// 通知编译完成
if (!continueDeploy) {
new Report(this).sendResultToDeployPlatform(env.BUILD_NUMBER == '1', currentBuild.currentResult == 'SUCCESS' ? 1 : -1, "build")
}
}
}
}
stage("部署") {
when {
expression {
// 首次部署,属于空跑,带默认参数,直接忽略
if (env.BUILD_NUMBER == '1') {
return false
}
if(BUILD_INFO == 'Branch event'){
return false
}
// 走k8s流程部署
if(build['useK8S']){
return false
}
if (build['rollback']) {
return false
}
if (build['env'] == 'dev') {
return env.BRANCH_NAME == 'develop' || BUILD_INFO != 'Branch event'
} else if (build['env'] == 'prod') {
return env.BRANCH_NAME == 'master'
} else {
return env.BRANCH_NAME != 'develop'
}
}
}
steps {
script {
echo 'JENKINS START TO DEPLOY ' + AppName
try {
if (Ips.size() > 0) {
javaDeploy(Ips, clubDeploy)
// 相关应用的定制测试脚本
customTestScript(new Wechat(this))
} else {
ERRMSG = '部署机器列表为空'
echo ERRMSG
throw new StageException('deploy',ERRMSG)
}
} catch (e) {
echo "deploy encounter error. \n ${e}"
if(e instanceof InterruptedException){
ERRMSG = '执行进程被中断,请检查是否启动时间过长(超过5分钟)'
}else{
ERRMSG = e.message ?: "${e}"
}
throw new StageException('deploy',ERRMSG, e)
}
echo 'JENKINS END TO DEPLOY ' + AppName
}
}
}
stage ('post-deploy'){
when {
expression {
// 首次部署,属于空跑,带默认参数,直接忽略; 继续部署使用先前的构建包
return env.BUILD_NUMBER != '1' && !build['rollback']
}
}
steps {
script {
// 通知部署完成
new Report(this).sendResultToDeployPlatform(env.BUILD_NUMBER == '1', currentBuild.currentResult == 'SUCCESS' ? 1 : -1, "deploy")
}
}
}
// 回滚阶段
stage('回滚') {
when {
expression {
if(BUILD_INFO == 'Branch event'){
return false
}
if(build['useK8S']){
return false
}
return build['rollback']
}
}
steps {
script {
echo 'JENKINS START TO ROLLBACK ' + AppName
try {
if (build["rollbackArtifact"]?.trim()) {
// 自动化部署传值
echo "the config rollbackArtifact is :" + build["rollbackArtifact"]
env.rollbackArtifact = build["rollbackArtifact"]
RollbackArtifact = build["rollbackArtifact"]
}else{
throw new StageException("rollback","回滚包参数为空,无法进行回滚!")
}
if (Ips.size() > 0) {
SEND_IPS = Ips
javaDeploy(Ips, clubDeploy)
} else {
ERRMSG = '部署机器列表为空'
echo ERRMSG
throw new StageException('deploy',ERRMSG)
}
} catch (e) {
if(e instanceof InterruptedException){
ERRMSG = '执行进程被中断,请检查是否启动时间过长(超过5分钟)'
}else{
ERRMSG = e.message ?: "${e}"
}
throw new StageException('rollback',ERRMSG, e)
}
echo 'JENKINS END TO ROLLBACK ' + AppName
}
}
}
stage ('post-rollback'){
when {
expression {
if(BUILD_INFO == 'Branch event'){
return false
}
// 首次部署,属于空跑,带默认参数,直接忽略; 继续部署使用先前的构建包
return env.BUILD_NUMBER != '1' && build['rollback']
}
}
steps {
script {
// 通知回滚完成
new Report(this).sendResultToDeployPlatform(env.BUILD_NUMBER == '1', currentBuild.currentResult == 'SUCCESS' ? 1 : -1, "rollback")
}
}
}
}
post {
success {
script {
if(build['currentNum'] == build['totalNum'] && env.BUILD_NUMBER != '1'){
wechat.deployInfo()
}
}
}
failure {
script {
if(env.BUILD_NUMBER != '1'){
wechat.error(ERRMSG)
}
}
}
// 先于success/failure执行
always {
// 自动部署通知
script {
if (SwaggerToken && (build['env'] == 'dev' || build['env'] == 'test')) {
echo 'trigger swagger service'
new Swagger(this).trigger(SwaggerToken, Ips)
}
}
}
}
}
} catch(err) {
pipelineStatus = -1
echo 'Caught err : ' + err
if(err instanceof StageException){
new Report(this).sendResultToDeployPlatform(env.BUILD_NUMBER == '1', pipelineStatus, err.getStageName())
}
throw err
} finally{
new Report(this).sendResultToDeployPlatform(env.BUILD_NUMBER == '1', pipelineStatus, 'final')
}
} pipeline流程分析
首先,pipeline的指定为master,表示该pipeline在master上执行。其次, 表示pipeline入参,我们约定为build,格式为json串,这样可以避免Jenkins pipeline运行的缓存问题导致的新增参数不生效异常。
紧接着就是pipeline各个stage任务,Java应用的基本流程任务包括:
=> => / / =>
注意到,我们对每个stage任务阶段和整个pipeline过程都做了try-catch-finally,并在finally中增加report回调,保证每个阶段任务的执行结果都会回调给部署发起方。
另外,在构建和部署阶段,我们使用到了并行机制,这要求Jenkins集群需要挂载多个slave节点(具体分析可参见下节 )。比如,本次部署需要发布到aliyun-hangzhou 和 aws-usa机器,那么可以并行在对应的slave站点进行构建和推送部署,缩短总体流程时间,这也是Jenkins集群优化的一部分(详情见文章后续章节 )。
这里还有一个特别的点要注意,就是在并行处理任务时,需要将对应节点的名称 及其工作目录 暂存起来(方便后续向指定节点推送任务),否则后面通过环境变量无法获取到相应信息(此时只能获取到master节点的信息),因为那些信息只在指定 节点时候才会准确生成。如下图所示:
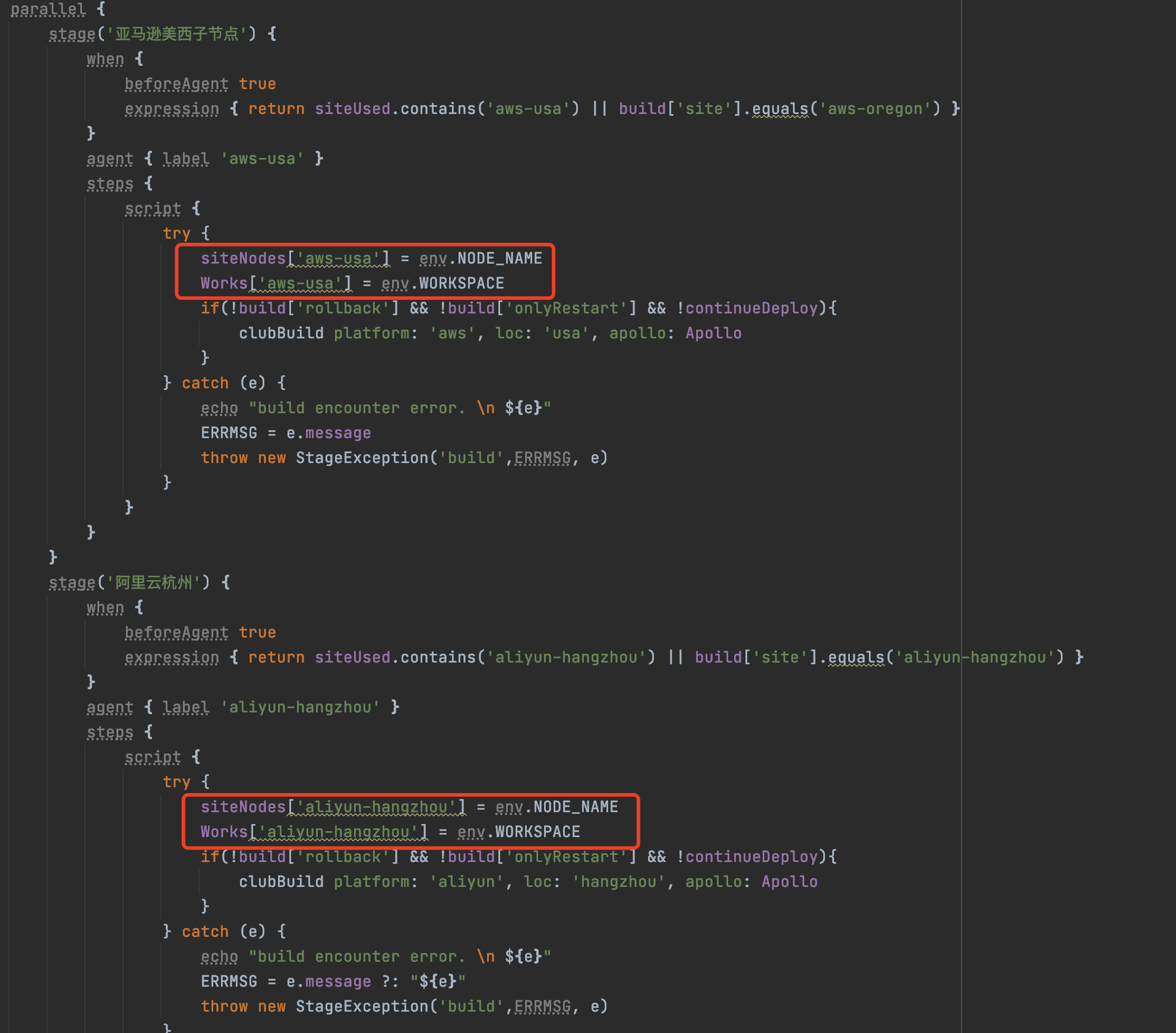
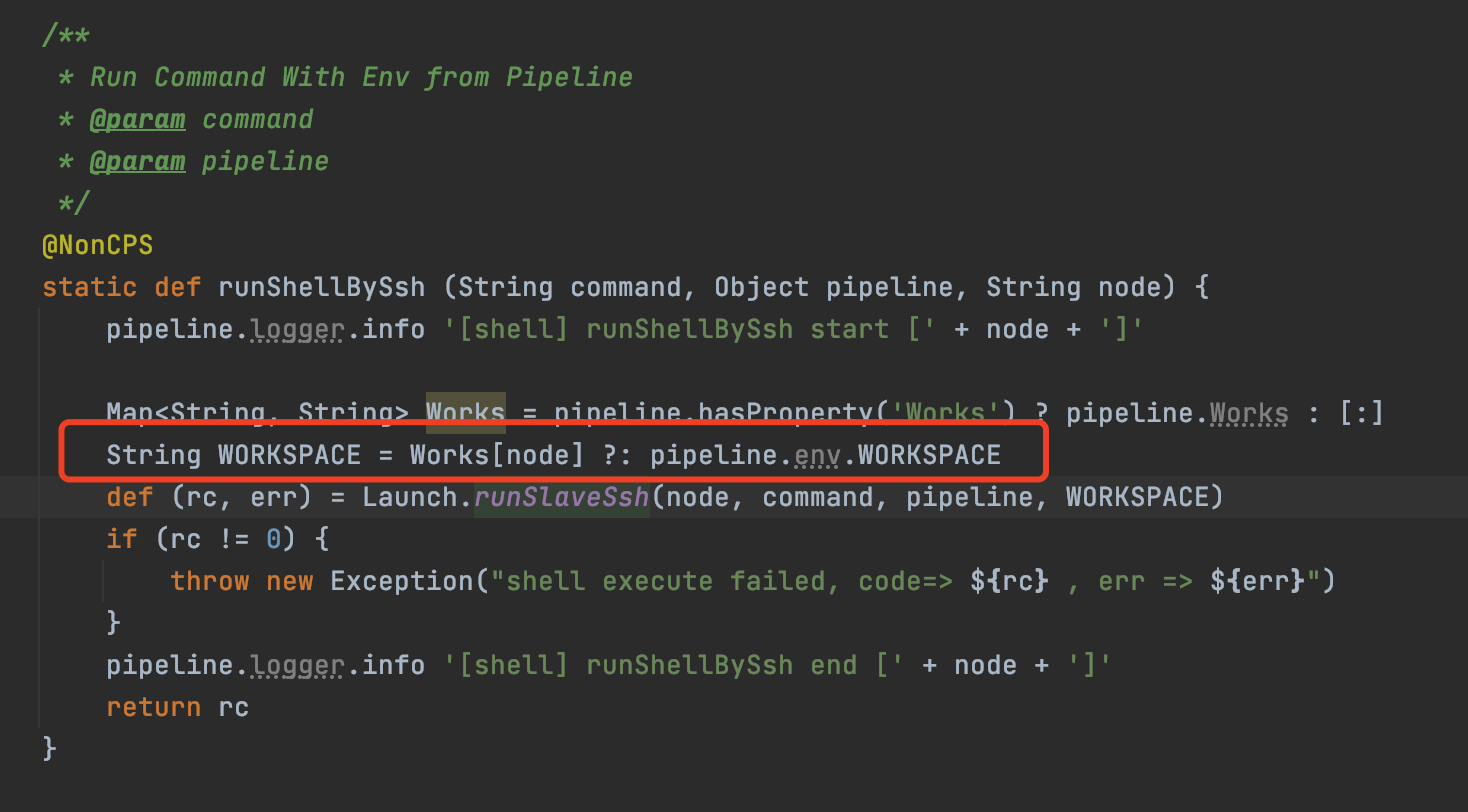
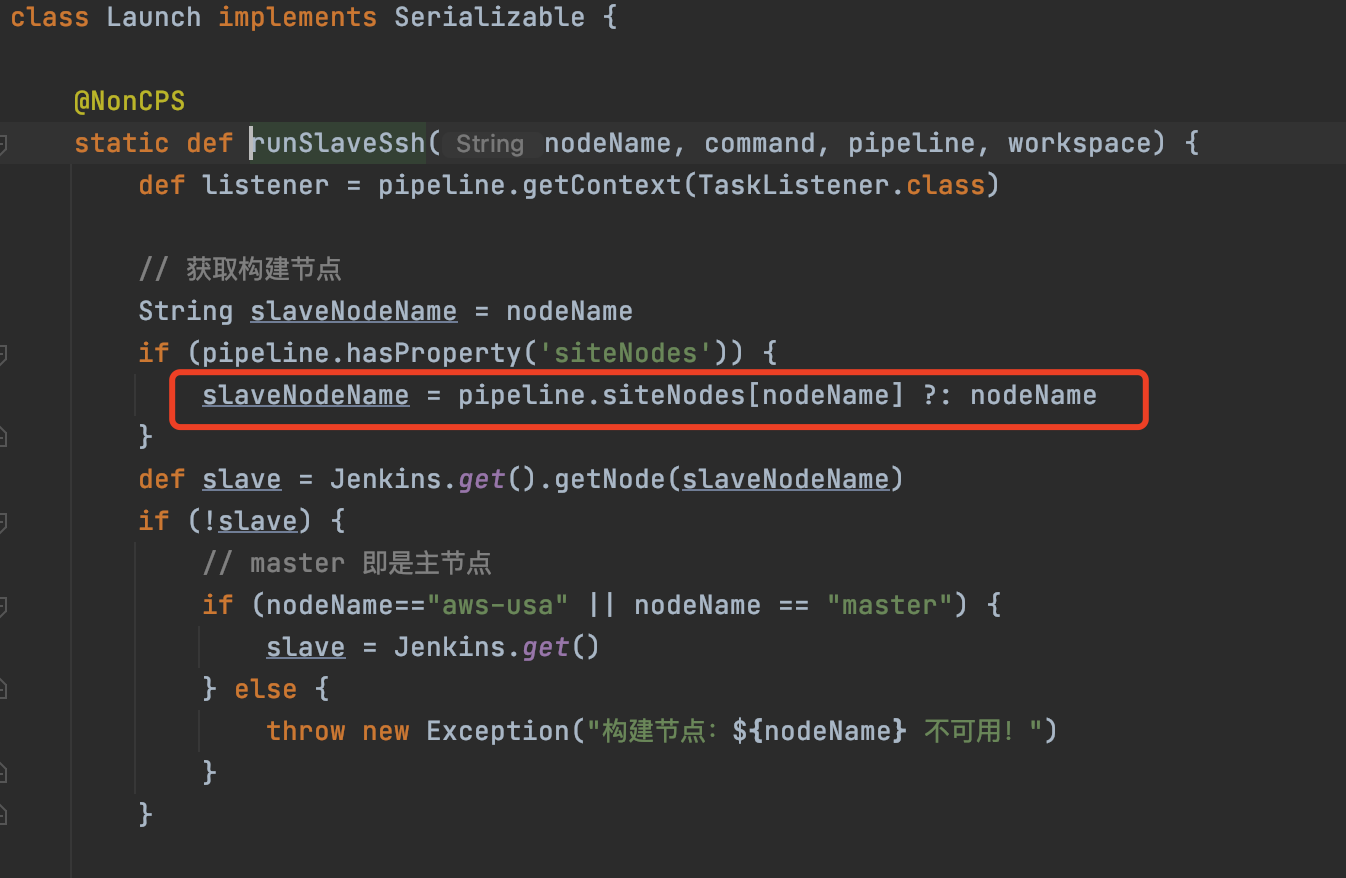
特别的,一些pipeline运行机制特有的限制导致我们不得不做一些特殊处理,比如首次部署无法获得参数,刷新branch引起的pipeline执行需要避免等,都在代码中做了注释说明,也是我们踩过的坑,大家实践时候也要注意。

Jenkins集群架构
jenkins的部署架构有 和 两种。
standalone方式部署简单,整个集群只有一个节点,这个节点既是提供UI访问入口,也提供job执行能力,即该节点负责所有工作,因此在任务较多时容易形成瓶颈。
master-slave方式则是处理任务的经典架构,master节点负责接收任务和调度,slave节点负责具体执行任务并反馈结果给master节点。这种架构方式可以依据需求增减slave节点,应对负载的变化,其部署架构如下图所示:

由于业务迭代频繁,部署应用众多,我们采取了master-slave部署架构,如图所示:
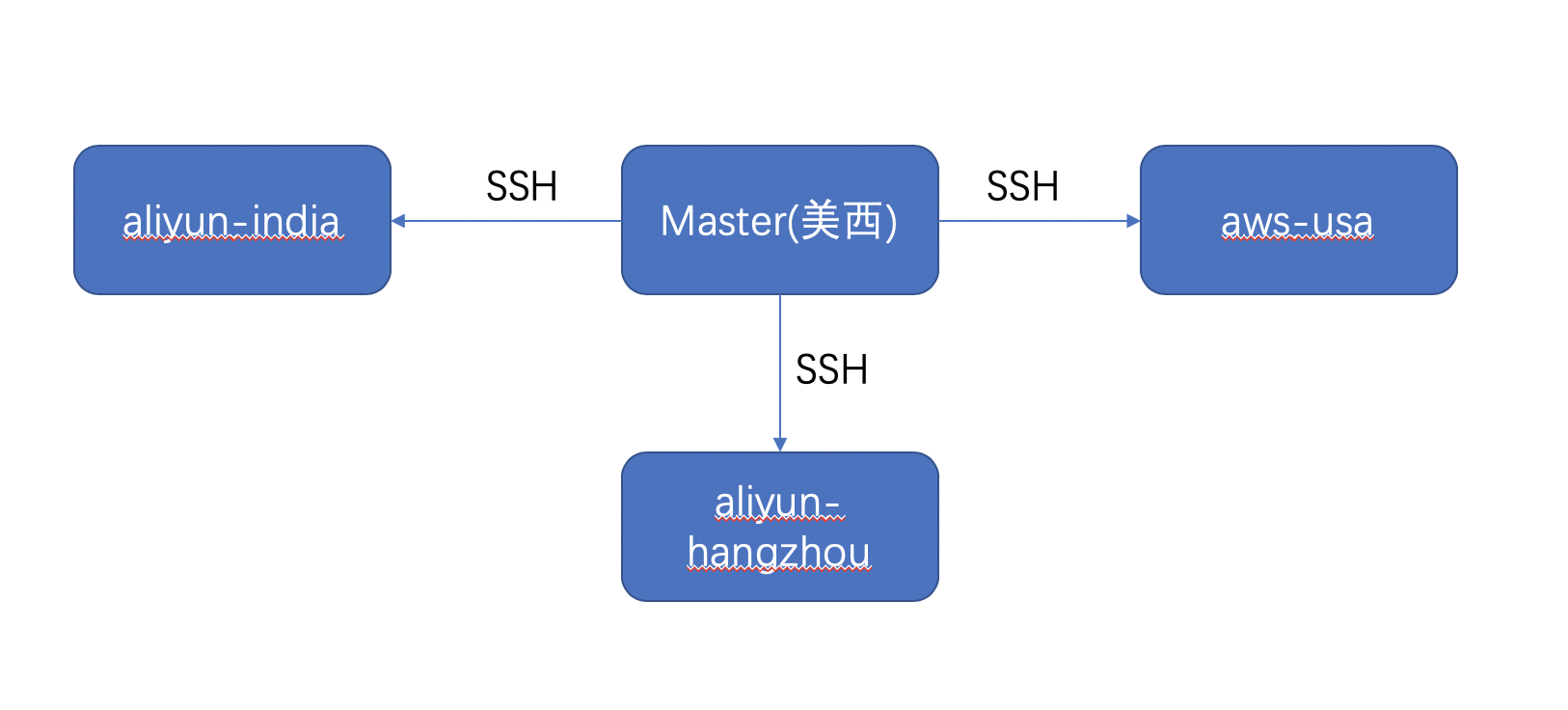
其中主节点部署在美西,主节点与从节点通过 ssh 方式保持连接。主节点根据部署机器所在的站点,将构建和部署任务分派到对应节点,利用站点内网加快同站点内任务的执行。这点对跨网带宽较小,同时要求回滚/重启等有较快速度要求的企业尤其有效。
基于Jenkins的发布调度

我们这里讲的是集群层面的调度,不涉及单个节点内 executor 层面的调度。嘉云的业务系统分布涉及美西,杭州,印度三个站点,美西是使用 aws 云服务,杭州和印度使用阿里云服务,各个站点之间是通过企业专线连接起来,可以认为是一个内网环境。每个站点有自己的网段范围,比如 172.16 开头的是杭州机器,172.19 开头是印度机器,172.131 开头是美西机器,这样 master 可以根据部署机器所属的站点,将编译和部署任务分派给相应的 slave 节点,slave 执行完后将结果返回给 master 节点。
这里也实现了我们前面提及的设计目标的第三点,owl平台(嘉云的研发效能平台)提供统一的应用发布入口,对业务方屏蔽Jenkins。因此,在改造进行到这里时,Jenkins在我们整个发布流程中是作为底层提供任务调度存在的,与外界通过api交互,不在提供UI入口。
Jenkins集群优化
在没有优化之前,Jenkins 集群的现状是经常性的变慢,然后宕机,导致大家发布时候会没有响应,所以不得不采用一个定时脚本,每天凌晨 5 点重启一下 master 节点。在排查宕机原因时我们观察发现,Jenkins 进程是被系统干掉的,对,就是这个 OOM killer,如图所示:

原因就是 Jenkins 进程占用对内存空间太多了,导致没有足够内存让系统正常运行,因此被系统选中杀掉。再对比 Jenkins 启动时候对 JVM 参数,最大堆空间使用到了 20G,还有 1G 直接内存,2G Metaspace,而机器总内存 30G,因此相对来说是占用比例过高。
优化过程
在尝试将参数调整为堆空间初始化为 10G,最大 15G,2G Metaspace,1G 直接内存,使用 G1 收集器后,系统逐渐稳定,没有再发生经常性宕机,因此取消了定时重启的监控脚本。
在稳定运行了一段时间后,前几天还是发生了 OOM,查看日志,是 Metaspace 溢出导致的,故将 JVM 参数调整为最大堆 14G,1G 直接内存,3G Metaspace,重启后目前稳定运行中。因此,从 JVM 参数调整来看,达到了一定的优化效果。
在解决了系统运行方面的问题后,接下来主要在调度方面进一步优化。首先,将绑定 master 节点的任务委派到美西 slave 节点执行,这大大减轻了 master 节点的负载。其次,将使用 groovy 脚本进行部署的 s3/oss 任务,改造成使用 shell 脚本进行,这样可以分派给 slave 节点执行,进一步减轻 master 压力(所有的 groovy 脚本都只能在 master 节点执行)。
性能测试
为了检验优化后集群性能,我们对 Jenkins 集群进行了压测,得到了一些基本指标。
集群配置
aws 美西 master 主节点 [16 core * 30G]
阿里云杭州 [16 core * 30G]
阿里云印度 [4 core * 8G]
aws 美西 slave【8 core * 15G】
测试数据 & 结果
100 个 Java 项目并发部署【自身部署耗时约 30-90s】
aliyun-hz 站点 耗时约 185s
aws-usa 站点 耗时约 165s
aliyun-india 站点 耗时约 660s
200 个 Java 项目并发部署【自身部署耗时约 30-90s】
aliyun-hz 站点 耗时约 330s
aws-usa 站点 耗时约 300s
300 个部署任务,从零点到八点持续进行测试,集群运行稳定,没有发生宕机【表现略差的是阿里云印度 slave 节点,拖慢 master 执行其他 job】。
从测试数据看,除了阿里云印度节点配置较低,耗时较长,美西和杭州节点支持 200 个并发部署任务,耗时在可接受范围内。
后续展望
本文介绍了嘉云公司基于Jenkins multibranch pipeline的发布体系的一些实践和经验,重点是Jenkins的pipeline as code 及 集群性能调优,这对于大多数中小创业公司在解决发布平台搭建时有一定借鉴意义。
近期由于公司业务进展放缓,有时间思考下一阶段Jenkins平台的迭代。结合容器化及k8s平台是首要考虑方向,毕竟很多大厂都已在CI/CD实践中运用了,作为没那么多历史包袱的创业公司,推动起来会更容易些。