极客大学架构师训练营 大数据 GFS、MapReduce、BigTable,Hadoop HDFS Yarn Hive 第12次作业
1. 在你所在的公司(行业、领域),正在用大数据处理哪些业务?可以用大数据实现哪些价值?
笔者在一家成立于1885年的全球性跨国银行,用大数据处理的业务包括:分析出洗黑钱的用户,根据用户的存款和消费数据给用户信用评分,贷款的时候给出相应额度。
大数据实现的价值:
2. 分析如下 HiveQL,生成的 MapReduce 执行程序,map 函数输入是什么?输出是什么,reduce 函数输入是什么?输出是什么?
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age
FROM page_view pv
JOIN user u
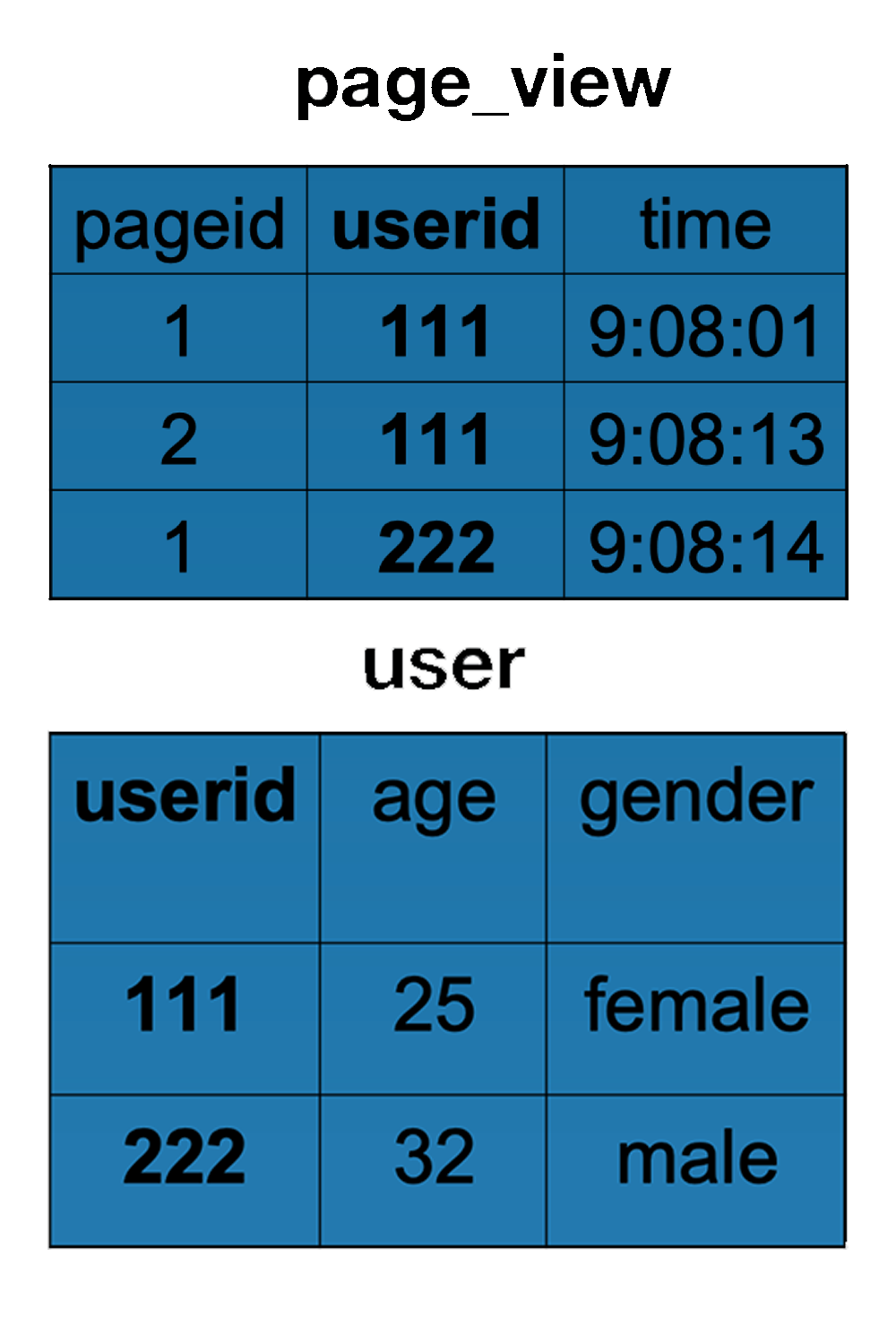
ON (pv.userid = u.userid);Page_view 表和 user 表结构与数据示例如下:
MapReduce 的输出流程图如下:
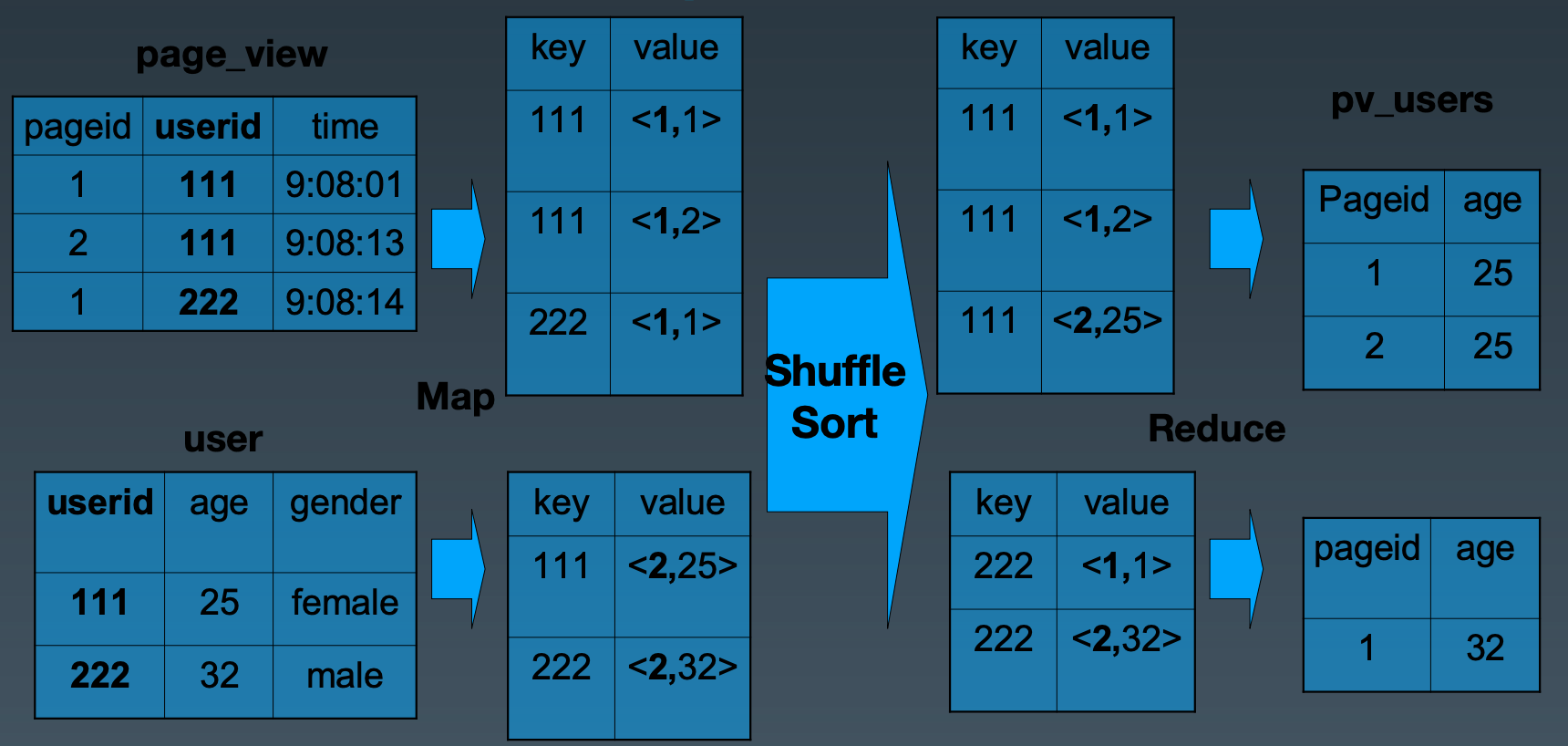
第一张表
Map 输入:
key是偏移量,不重要。
value 就是一行记录。key 是 userId,value是<来源于哪张表id,pageId>
Map 输出:
输出结果:是userId, 是<来源于哪张表id, pageId>
第二张表
Map 输出:
key是偏移量,不重要。
value 就是一行记录。key 是 userId,
Map 输出:
输出结果:是userId, 是<来源于哪张表id, age>
Shuffle Sort:相同的key放在一起。
Reduce 输入:
每张表相同的key要进行join操作,最后把结果输出。
key就是Map输出的<来源于哪张表id, pageId>, <来源于哪张表id, age> , values就是userId组成的list。
Reduce 输出:
key是Map输出的<来源于哪张表id, pageId>, <来源于哪张表id, age>,result就是pageId访问的和。