Flink 和流式应用运维(十-中)
写在前面:
大家好,我是强哥,一个热爱分享的技术狂。目前已有 12 年大数据与AI相关项目经验, 10 年推荐系统研究及实践经验。平时喜欢读书、暴走和写作。
业余时间专注于输出大数据、AI等相关文章,目前已经输出了40万字的推荐系统系列精品文章,强哥的畅销书「构建企业级推荐系统:算法、工程实现与案例分析」已经出版,需要提升可以私信我呀。如果这些文章能够帮助你快速入门,实现职场升职加薪,我将不胜欢喜。
想要获得更多免费学习资料或内推信息,一定要看到文章最后喔。
内推信息
如果你正在看相关的招聘信息,请加我微信:liuq4360,我这里有很多内推资源等着你,欢迎投递简历。
免费学习资料
如果你想获得更多免费的学习资料,请关注同名公众号【数据与智能】,输入“资料”即可!
学习交流群
如果你想找到组织,和大家一起学习成长,交流经验,也可以加入我们的学习成长群。群里有老司机带你飞,另有小哥哥、小姐姐等你来勾搭!加小姐姐微信:epsila,她会带你入群。
控制任务调度
Flink 应用程序通过将算子并行化为任务并将这些任务分配到集群中的工作进程来并行执行。 就像在许多其他分布式系统中一样,Flink 应用程序的性能在很大程度上取决于任务的调度方式。 任务分配到的工作进程、与任务共存的任务以及分配给工作进程的任务数量会对应用程序的性能产生重大影响。
在“任务执行”中,我们描述了 Flink 如何将任务分配到槽,以及它如何利用任务链来降低本地数据交换的成本。 在本节中,我们将讨论如何调整默认行为并控制任务链以及将任务分配到slot以提高应用程序的性能。
控制任务链接
任务链将两个或多个算子的并行任务合并为一个由单个线程执行的任务。合并任务通过方法调用交换记录,因此基本上没有通信成本。由于任务链提高了大多数应用程序的性能,因此在Flink 中默认启用。
但是,某些应用程序可能无法从任务链中受益。一个原因是打破一系列昂贵的函数,以便在不同的slot上执行它们。 你可以通过 StreamExecutionEnvironment 完全禁用应用程序的任务链:
StreamExecutionEnvironment.disableOperatorChaining()
除了为整个应用程序禁用任务链之外,还可以控制各个算子的任务链行为。要禁用特定算子的链接,可以调用它的disableChaining()方法。这将防止算子的任务被链接到前面和后面的任务(例如10-1)。
val input: DataStream[X] = ...
val result: DataStream[Y] = input.filter(new Filter1()).map(new Map1())
// disable chaining for Map2
.map(new Map2()).disableChaining()
.filter(new Filter2())
示例10-1 中的代码产生了三个任务——Filter1 和 Map1 的链接任务、Map2 的单独任务和 Filter2 的任务,不允许链接到 Map2。
也可以通过调用其startNewChain() 方法(示例 10-2)来使用算子启动一个新链。 如果满足链接的要求,算子的任务将不会链接到前面的任务,但会链接到后续任务。
val input: DataStream[X] = ...
val result: DataStream[Y] = input
.filter(new Filter1())
.map(new Map1())
// start a new chain for Map2 and Filter2
.map(new Map2()).startNewChain()
.filter(new Filter2())
在示例10-2 中,创建了两个链式任务:一个任务用于 Filter1 和 Map1,另一个任务用于 Map2 和 Filter2。 请注意,新的链式任务以调用 startNewChain() 方法的算子开始——在我们的示例中为 Map2。
定义Slot共享组
Flink 的默认任务调度策略将程序的一个完整切片——一个应用程序的每个算子中最多一个任务分配到一个slot。 根据应用程序的复杂性和算子的计算成本,这种默认策略可能会使处理slot超载。 Flink 手动控制任务分配到slot的机制是槽共享组。
每个算子都是一个slot共享组的成员。属于同一slot共享组的算子的所有任务都由相同的slots处理。在一个slot共享组中,任务被分配到“任务执行”章节中所描述的——每个slot最多处理一个成员算子的任务。因此,一个slot共享组需要尽可能多的处理slot来满足其算子的最大并行度。不同slot 共享组中的算子任务不会由相同的slot执行。
默认情况下,每个算子都位于“默认”slot共享组中。对于每个算子,你可以使用slotSharingGroup(String)方法显式地指定其slot共享组。如果输入算子的所有成员都属于同一组,则算子将继承其输入算子的slot共享组。如果输入算子在不同的组中,则算子在“默认”组中。示例10-3展示了如何在Flink DataStream应用程序中指定slot共享组。
// slot-sharing group "green"
val a: DataStream[A] = env.createInput(...)
.slotSharingGroup("green")
.setParallelism(4)
val b: DataStream[B] = a.map(...)
// slot-sharing group "green" is inherited from a
.setParallelism(4)
// slot-sharing group "yellow"
val c: DataStream[C] = env.createInput(...)
.slotSharingGroup("yellow")
.setParallelism(2)
// slot-sharing group "blue"
val d: DataStream[D] = b.connect(c.broadcast(...)).process(...)
.slotSharingGroup("blue")
.setParallelism(4)
val e = d.addSink()
// slot-sharing group "blue" is inherited from d
.setParallelism(2)
示例10-3中的应用程序由五个算子、两个源、两个中间算子和一个sink算子组成。算子被分配到三个共享位置组:用绿色、黄色和蓝色来表示。图10-1显示了应用程序的JobGraph,以及如何将其任务映射到处理slot。
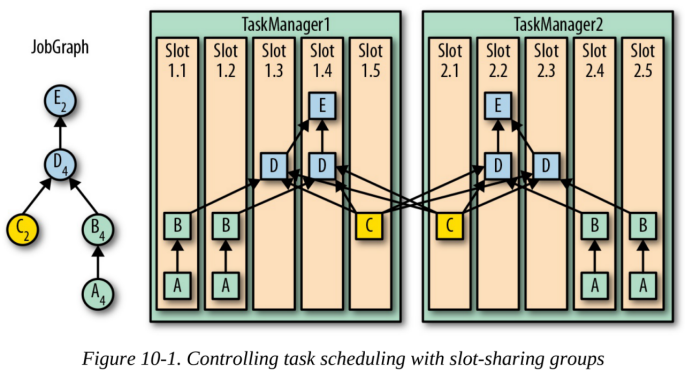
该应用程序需要10个处理slot。由于分配的算子的最大并行度,蓝色和绿色的slot共享组需要各4个slot。黄色slot共享组需要两个slot。
调整检查点及恢复
在启用容错的情况下运行的Flink 应用程序会定期获取其状态的检查点。 检查点可能是一个代价比较昂贵的操作,因为需要复制到持久存储的数据量可能非常大。 增加检查点间隔可以减少常规处理过程中的容错开销。 但是,它也增加了作业在从故障中恢复后在赶上流的尾部之前需要重新处理的数据量。
Flink 提供了几个参数来调整检查点和状态后端。 配置这些选项对于确保生产中流应用程序的可靠和平稳运行非常重要。例如,减少每个检查点的开销可以提高检查点频率,从而加快恢复周期。在本节中,我们将介绍用于控制检查点和应用程序恢复的参数。
配置检查点
当你为应用程序启用检查点时,你必须指定检查点间隔——JobManager 将在应用程序源启动检查点的时间间隔。
在StreamExecutionEnvironment上启用检查点:
val env: StreamExecutionEnvironment = ???
// enable checkpointing with an interval of 10 seconds.
env.enableCheckpointing(10000);
CheckpointConfig 提供了配置检查点行为的更多选项,可以从 StreamExecutionEnvironment 获取:
// get the CheckpointConfig from the StreamExecutionEnvironment
val cpConfig: CheckpointConfig = env.getCheckpointConfig
默认情况下,Flink 创建检查点以保证恰好一次的状态一致性。 但是,它也可以配置为提供至少一次保证:
// set mode to at-least-once
cpConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);
根据应用程序的特性、其状态的大小和检查点比配置的检查点间隔花费更多的时间。默认情况下,Flink 一次只允许一个检查点进行,以避免检查点占用太多常规处理所需的资源。 如果——根据配置的检查点间隔——需要启动一个检查点,但有另一个检查点正在进行中,第二个检查点将被搁置,直到第一个检查点完成。
如果许多或所有检查点花费的时间比检查点间隔长,则此行为可能不是最佳的,原因有两个。首先,这意味着应用程序的常规数据处理将始终与并发检查点竞争资源。因此,它的处理速度会变慢,并且可能无法取得足够的进展来跟上传入的数据。其次,一个检查点可能会被延迟,因为我们需要等待另一个检查点完成导致检查点间隔较短,从而导致恢复期间的追赶处理时间更长。Flink 提供了参数来解决这些情况。
为确保应用程序可以取得足够的处理速度,你可以配置检查点之间的最小暂停时间。如果你将最短暂停时间配置为30 秒,那么在检查点完成后的前 30 秒内将不会启动新的检查点。 这也意味着有效的检查点间隔至少为 30 秒,并且最多同时发生一个检查点
// make sure we process at least 30s without checkpointing
cpConfig.setMinPauseBetweenCheckpoints(30000);
在某些情况下,你可能希望确保在配置的检查点间隔内获取检查点,即使检查点花费的时间长于间隔。一个例子是检查点需要很长时间但不消耗太多资源;例如,由于对外部系统的高延迟调用的操作。在这种情况下,你可以配置检查点的最大并发数。
// allow three checkpoint to be in progress at the same time
cpConfig.setMaxConcurrentCheckpoints(3);
保存点与检查点同时进行。由于检查点操作,Flink 不会延迟显式触发的保存点。 无论正在进行多少检查点,保存点将始终启动。
为了避免长时间运行的检查点,你可以配置一个超时间隔,在此之后检查点将被取消。默认情况下,检查点会在10 分钟后取消。
// checkpoints have to complete within five minutes, or are discarded
cpConfig.setCheckpointTimeout(300000);
最后,你可能还想配置检查点失败时会发生什么。默认情况下,失败的检查点会导致应用程序重新启动的异常。你可以禁用此行为并在检查点错误后让应用程序继续运行。
// do not fail the job on a checkpointing error
cpConfig.setFailOnCheckpointingErrors(false);
启用检查点压缩
Flink 支持压缩检查点和保存点。 在 Flink 1.7 之前,唯一支持的压缩算法是 Snappy。 你可以按如下方式启用压缩检查点和保存点:
注意,增量式RocksDB检查点不支持检查点压缩。
在应用程序停止后保留检查点
检查点的目的是在失败后恢复应用程序。因此,它们会在作业因失败或显式取消而停止运行时进行清理。但是,你还可以启用称为外部化检查点的功能,以在应用程序停止后保留检查点。
// Enable externalized checkpoints
cpConfig.enableExternalizedCheckpoints(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
外部化检查点有两种选择:
l RETAIN_ON_CANCELATION 在应用程序完全失败后和显式取消时保留检查点。
l DELETE_ON_CANCELLATION 只在应用程序完全失败之后才保留检查点。如果应用程序被显式取消,检查点将被删除。
外部化检查点不会替换保存点。它们使用状态后端特定的存储格式,并且不支持重新缩放。因此,它们足以在应用程序失败后重新启动应用程序,但提供的灵活性不如保存点。一旦应用程序再次运行,你就可以创建一个保存点。
配置状态后端
应用程序的状态后端负责维护本地状态,执行检查点和保存点,并在发生故障后恢复应用程序状态。因此,应用程序状态后端的选择和配置对检查点的性能有很大的影响。在“选择状态后端”章节中更详细地描述了各个状态后端。
应用程序的默认状态后端是MemoryStateBackend。 由于它将所有状态保存在内存中,并且检查点完全存储在易失性和 JVM 大小受限的 JobManager 堆存储中,因此不建议用于生产环境。 但是,它非常适合本地开发 Flink 应用程序。 “检查点和状态后端”描述了如何配置 Flink 集群的默认状态后端。
你也可以显式地选择一个应用程序的状态后端:
val env: StreamExecutionEnvironment = ???
// create and configure state backend of your choice
val stateBackend: StateBackend = ???
// set state backend
env.setStateBackend(stateBackend)
可以使用最少的设置创建不同的状态后端,如下所示。MemoryStateBackend 不需要任何参数。 但是,有些构造函数采用参数来启用或禁用异步检查点(默认启用)并限制状态大小(默认为 5 MB):
// create a MemoryStateBackend
val memBackend = new MemoryStateBackend()
FsStateBackend 只需要一个路径来定义检查点的存储位置。 还有用于启用或禁用异步检查点的构造函数变体(默认启用):
// create a FsStateBackend that checkpoints to the /tmp/ckpfolder
val fsBackend = new FsStateBackend("file:///tmp/ckp", true)
RocksDBStateBackend只需要一个路径来定义检查点的存储位置,并使用一个可选参数来启用增量检查点(默认情况下禁用)。RocksDBStateBackend总是异步写入检查点:
// create a RocksDBStateBackend that writes incremental checkpoints
// to the /tmp/ckp folder
val rocksBackend = new RocksDBStateBackend("file:///tmp/ckp",true)
在“检查点和状态后端”中,我们讨论了状态后端的配置选项。 当然,你也可以在应用程序中配置状态后端,覆盖默认值或集群范围的配置。 为此,你必须通过将 Configuration 对象传递给你的状态后端来创建一个新的后端对象。 有关可用配置选项的说明,请参阅“检查点和状态后端”:
// all of Flink's built-in backends are configurable
val backend: ConfigurableStateBackend = ???
// create configuration and set options
val sbConfig = new Configuration()
sbConfig.setBoolean("state.backend.async", true)
sbConfig.setString("state.savepoints.dir", "file:///tmp/svp")
// create a configured copy of the backend
val configuredBackend = backend.configure(sbConfig)
由于RocksDB 是一个外部组件,它带来了自己的一组调整参数,这些参数也可以针对你的应用程序进行调整。 默认情况下,RocksDB 针对 SSD 存储进行了优化,如果状态存储在旋转磁盘上,则不会提供出色的性能。 Flink 提供了一些预定义的设置来提高常见硬件设置的性能。 请参阅文档以了解有关可用设置的更多信息。 你可以将预定义选项应用于 RocksDBStateBackend,如下所示:
val backend: RocksDBStateBackend = ???
// set predefined options for spinning disk storage
backend.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED)
配置故障恢复
当检查点应用程序失败时,它将通过启动其任务、恢复其状态(包括源任务的读取偏移量)并继续处理来重新启动。在应用程序重新启动后,它正处于追赶阶段。由于应用程序的源任务被重置为较早的输入位置,因此它会处理它在失败之前处理的数据和应用程序关闭时积累的数据。
为了能够赶上流——到达它的尾部——应用程序必须以高于新数据到达的速度处理累积的数据。 当应用程序在追赶时,处理延迟(输入可用到实际处理的时间)会增加。
因此,在应用程序重新启动以成功恢复其常规处理后,应用程序需要足够的备用资源用于追赶阶段。这意味着应用程序在常规处理期间不应接近100% 的资源消耗。 可用于恢复的资源越多,追赶阶段完成得越快,处理延迟恢复正常的速度就越快。
除了恢复的资源考虑之外,我们还将讨论另外两个与恢复相关的主题:重启策略和本地恢复。
重新启动策略
根据导致应用程序崩溃的故障,应用程序可能会再次被相同的故障杀死。一个常见的例子是应用程序无法处理的无效或损坏的输入数据。在这种情况下,应用程序最终会进入一个无限的恢复周期,消耗大量资源,而没有机会恢复到正常处理状态。Flink 提供了三种重启策略来解决这个问题:
固定延迟重新启动策略(fixed-delay restart strategy):以固定的次数重新启动应用程序,并在重新启动尝试之前等待已配置的时间。
故障率重新启动策略(failure-rate restart strategy):只要不超过可配置的故障率,故障率重启策略就会重启应用程序。 故障率被指定为一个时间间隔内的最大故障数。 例如,你可以配置一个应用程序,只要它在过去 10 分钟内失败的次数不超过 3 次就可以重新启动。
不重启策略(no-restart strategy):不重启应用程序,但会立即失败。
应用程序的重启策略是通过StreamExecutionEnvironment配置的,如示例10-4所示。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
5, // number of restart attempts
Time.of(30, TimeUnit.SECONDS) // delay between attempts
)
)
如果未明确定义重启策略,则使用的默认重启策略是具有Integer.MAX_VALUE 重启尝试和 10 秒延迟的固定延迟重启策略。
本地恢复
Flink 的状态后端(MemoryStateBackend 除外)在远程文件系统中存储检查点。 这首先确保状态被保存和持久化,其次确保在工作节点丢失或应用程序重新缩放时可以重新分配状态。 但是,在恢复期间从远程存储读取状态不是很有效。 此外,在恢复时,可能会在故障前运行的同一工作人员上重新启动应用程序。
如果应用程序可以在同一台机器上重新启动,Flink 支持一种称为本地恢复的功能,以 显著加快恢复速度。 启用后,除了将数据写入远程存储之外,状态后端还会在其工作节点的本地磁盘上存储检查点数据的副本。 当应用程序重新启动时,Flink 尝试将相同的任务调度到相同的工作节点。 如果成功,任务首先尝试从本地磁盘加载检查点数据。 如果出现任何问题,它们会回退到远程存储。
实现了本地恢复,使远程系统中的状态副本成为备用来源。任务只有在远程写入成功时才确认生成检查点。而且,检查点不会因为本地状态副本失败而失败。由于检查点数据被写入两次,本地恢复会增加检查点的开销。
可以在flink-conf.yaml文件中启用和配置集群的本地恢复特性,也可以为每个应用程序设置不同的状态后端配置:
state.backend.local-recovery:此标志用于启用或禁用本地恢复。默认情况下,本地恢复被禁用。
taskmanager.state.local.root-dirs:此参数指定存储本地状态副本的一个或多个本地路径。
本地恢复只影响键状态,它总是分区的,通常占状态大小的大部分。算子状态不会存储在本地,需要从远程存储系统中检索。但是,它通常比键状态小得多。此外,MemoryStateBackend不支持本地恢复,它无论如何也不支持大的状态。