如何评价Netty封装的io_uring?
linux AIO 简史
在继续 io_uring 的旅行之前,让我们先回顾一下 linux 中的各种异步 IO,也就是 AIO。
1. glibc aio
官方地址:Perform I/O Operations in Parallel(官方文档用的字眼比较考究)
glibc 是 GNU 发布的 libc 库,该库提供的异步 IO 被称为 glibc aio,在某些地方也被称为 posix aio。glibc aio 用多线程同步 IO 来模拟异步 IO,回调函数在一个单线程中执行。
该实现备受非议,存在一些难以忍受的缺陷和bug,极不推荐使用。详见:
2. libaio
linux kernel 2.6 版本引入了原生异步 IO 支持 —— libaio,也被称为 native aio。
ibaio 与 glibc aio 的多线程伪异步不同,它真正的内核异步通知,是真正的异步IO。
虽然很真了,但是缺陷也很明显:libaio 仅支持 O_DIRECT 标志,也就是 Direct I/O,这意味着无法利用系统缓存,同时读写的的大小和偏移要以区块的方式对齐。
3. libeio
由于上面两个都不靠谱,所以 Marc Lehmann 又开发了一个 AIO 库 —— libeio。
与 glibc aio 的思路一样,也是在用户空间用多线程同步模拟异步 IO,但是 libeio 实现的更高效,代码也更稳定,著名的 node.js 早期版本就是用 libev 和 libeio 驱动的(新版本在 libuv 中移除了 libev 和 libeio)。
libeio 提供全套异步文件操作的接口,让用户能写出完全非阻塞的程序,但 libeio 也不属于真正的异步IO。
4. io_uring
接下来就是 linux kernel 5.1 版本引入的 io_uring 了。
io_uring 类似于 Windows 世界的 IOCP,但是还没有达到对应的地位,目前来看正式使用 io_uring 的产品基本没有,我感觉还是没有一个成熟的编程模型与其匹配,就像 Netty 的编程模型特别适配 epoll。
至于 Netty 对 io_uring 的封装,看下来的总体感受是:Netty 为了维持编程模型统一,完全没有发挥出 io_uring 的长处。具体 Netty 是如何封装的,我们下面一起探讨一下。
Netty 对 io_uring 的封装
1. 使用方式
public class EchoIOUringServer {
private static final int PORT = Integer.parseInt(System.getProperty("port", "8080"));
public static void main(String []args) {
EventLoopGroup bossGroup = new IOUringEventLoopGroup(1);
EventLoopGroup workerGroup = new IOUringEventLoopGroup(1);
final EchoIOUringServerHandler serverHandler = new EchoIOUringServerHandler();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(IOUringServerSocketChannel.class)
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new ChannelInitializer() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
//p.addLast(new LoggingHandler(LogLevel.INFO));
p.addLast(serverHandler);
}
});
// Start the server.
ChannelFuture f = b.bind(PORT).sync();
// Wait until the server socket is closed.
f.channel().closeFuture().sync();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// Shut down all event loops to terminate all threads.
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
} 从 Netty 官方给的这个例子来看,io_uring 的使用方式与 epoll 一样,初步来看线程模型也是一样的,也是分了 bossGroup 和 workerGroup 两个EventLoopGroup,从名字猜测 bossGroup 还是处理连接创建,workerGroup 还是处理网络读写。
io_uring 的具体逻辑都封装在了 IOUringEventLoopGroup 和 IOUringServerSocketChannel 中。
2. IOUringEventLoopGroup
Netty 的线程模型此处不再赘述,详见《Netty in Action》的第七章。
我们先看一下 IOUringEventLoop 构造方法:
IOUringEventLoop(IOUringEventLoopGroup parent, Executor executor, int ringSize, int iosqeAsyncThreshold,
RejectedExecutionHandler rejectedExecutionHandler, EventLoopTaskQueueFactory queueFactory) {
super(parent, executor, false, newTaskQueue(queueFactory), newTaskQueue(queueFactory),
rejectedExecutionHandler);
// Ensure that we load all native bits as otherwise it may fail when try to use native methods in IovArray
IOUring.ensureAvailability();
ringBuffer = Native.createRingBuffer(ringSize, iosqeAsyncThreshold);
eventfd = Native.newBlockingEventFd();
logger.trace("New EventLoop: {}", this.toString());
}可见每个事件循环处理线程都创建了一个 io_uring ringBuffer,另外还有一个用来通知事件的文件描述符 eventfd。
深入 Native.createRingBuffer(ringSize, iosqeAsyncThreshold) 看一下:ringSize 默认值为 4096,iosqeAsyncThreshold 默认为 25
static RingBuffer createRingBuffer(int ringSize, int iosqeAsyncThreshold) {
long[][] values = ioUringSetup(ringSize);
assert values.length == 2;
long[] submissionQueueArgs = values[0];
assert submissionQueueArgs.length == 11;
IOUringSubmissionQueue submissionQueue = new IOUringSubmissionQueue(
submissionQueueArgs[0],
submissionQueueArgs[1],
submissionQueueArgs[2],
submissionQueueArgs[3],
submissionQueueArgs[4],
submissionQueueArgs[5],
submissionQueueArgs[6],
submissionQueueArgs[7],
(int) submissionQueueArgs[8],
submissionQueueArgs[9],
(int) submissionQueueArgs[10],
iosqeAsyncThreshold);
long[] completionQueueArgs = values[1];
assert completionQueueArgs.length == 9;
IOUringCompletionQueue completionQueue = new IOUringCompletionQueue(
completionQueueArgs[0],
completionQueueArgs[1],
completionQueueArgs[2],
completionQueueArgs[3],
completionQueueArgs[4],
completionQueueArgs[5],
(int) completionQueueArgs[6],
completionQueueArgs[7],
(int) completionQueueArgs[8]);
return new RingBuffer(submissionQueue, completionQueue);
}
Netty 的这个 RingBuffer 封装基本上与 io_uring 的结构一一对应。
再深入看一下 io_uring_setup 的 JNI 封装,发现 Netty 当前的实现并没设置任何 flag,使用默认模式,也就是通过 io_uring_enter 提交任务。该模式倒是与 Netty 的线程模型很匹配,如果要支持 SQPOLL 可能需要较大改动。
Netty 的这个 RingBuffer 封装基本上与 io_uring 的结构一一对应。
再深入看一下 io_uring_setup 的 JNI 封装,发现 Netty 当前的实现并没设置任何 flag,使用默认模式,也就是通过 io_uring_enter 提交任务。该模式倒是与 Netty 的线程模型很匹配,如果要支持 SQPOLL 可能需要较大改动。
回过头来再看一下 IOUringEventLoop 的事件循环:
@Override
protected void run() {
final IOUringCompletionQueue completionQueue = ringBuffer.ioUringCompletionQueue();
final IOUringSubmissionQueue submissionQueue = ringBuffer.ioUringSubmissionQueue();
// Lets add the eventfd related events before starting to do any real work.
addEventFdRead(submissionQueue);
for (;;) {
try {
logger.trace("Run IOUringEventLoop {}", this);
// Prepare to block wait
long curDeadlineNanos = nextScheduledTaskDeadlineNanos();
if (curDeadlineNanos == -1L) {
curDeadlineNanos = NONE; // nothing on the calendar
}
nextWakeupNanos.set(curDeadlineNanos);
// Only submit a timeout if there are no tasks to process and do a blocking operation
// on the completionQueue.
try {
if (!hasTasks()) {
if (curDeadlineNanos != prevDeadlineNanos) {
prevDeadlineNanos = curDeadlineNanos;
submissionQueue.addTimeout(deadlineToDelayNanos(curDeadlineNanos), (short) 0);
}
// Check there were any completion events to process
if (!completionQueue.hasCompletions()) {
// Block if there is nothing to process after this try again to call process(....)
logger.trace("submitAndWait {}", this);
submissionQueue.submitAndWait();
}
}
} finally {
if (nextWakeupNanos.get() == AWAKE || nextWakeupNanos.getAndSet(AWAKE) == AWAKE) {
pendingWakeup = true;
}
}
} catch (Throwable t) {
handleLoopException(t);
}
// Avoid blocking for as long as possible - loop until available work exhausted
boolean maybeMoreWork = true;
do {
try {
// CQE processing can produce tasks, and new CQEs could arrive while
// processing tasks. So run both on every iteration and break when
// they both report that nothing was done (| means always run both).
maybeMoreWork = completionQueue.process(callback) != 0 | runAllTasks();
} catch (Throwable t) {
handleLoopException(t);
}
// Always handle shutdown even if the loop processing threw an exception
try {
if (isShuttingDown()) {
closeAll();
if (confirmShutdown()) {
return;
}
if (!maybeMoreWork) {
maybeMoreWork = hasTasks() || completionQueue.hasCompletions();
}
}
} catch (Throwable t) {
handleLoopException(t);
}
} while (maybeMoreWork);
}
}先交代两个非主干逻辑的细节:
搞清楚上述两个细节,主干流程就很清晰了:
3. IOUringServerSocketChannel
Netty 对于 ServerSocket 的通用处理流程这里也不赘述了。
在 IOUringServerSocketChannel注册后回调 channelActive()时会触发了beginRead 方法:
@Override
protected void doBeginRead() {
if ((ioState & POLL_IN_SCHEDULED) == 0) {
ioUringUnsafe().schedulePollIn();
}
}
final void schedulePollIn() {
assert (ioState & POLL_IN_SCHEDULED) == 0;
if (!isActive() || shouldBreakIoUringInReady(config())) {
return;
}
ioState |= POLL_IN_SCHEDULED;
IOUringSubmissionQueue submissionQueue = submissionQueue();
submissionQueue.addPollIn(socket.intValue());
}
也就是向 io_uring 提交了一个 POLLIN 任务,在有新连接进来时 bossGroup 就能收到触发事件(注意此处不是”连接建立“的任务)。
final void pollIn(int res) {
ioState &= ~POLL_IN_SCHEDULED;
if (res == Native.ERRNO_ECANCELED_NEGATIVE) {
return;
}
scheduleFirstReadIfNeeded();
}
@Override
protected int scheduleRead0() {
final IOUringRecvByteAllocatorHandle allocHandle = recvBufAllocHandle();
allocHandle.attemptedBytesRead(1);
IOUringSubmissionQueue submissionQueue = submissionQueue();
submissionQueue.addAccept(fd().intValue(),
acceptedAddressMemoryAddress, acceptedAddressLengthMemoryAddress, (short) 0);
return 1;
}
POLLIN 任务完成后会再提交一个 IORING_OP_ACCEPT 任务,也就是”连接建立“的任务。
等连接建立完成就能收到回调:
@Override
protected void readComplete0(int res, int data, int outstanding) {
final IOUringRecvByteAllocatorHandle allocHandle =
(IOUringRecvByteAllocatorHandle) unsafe()
.recvBufAllocHandle();
final ChannelPipeline pipeline = pipeline();
allocHandle.lastBytesRead(res);
if (res >= 0) {
allocHandle.incMessagesRead(1);
try {
Channel channel = newChildChannel(
res, acceptedAddressMemoryAddress, acceptedAddressLengthMemoryAddress);
pipeline.fireChannelRead(channel);
if (allocHandle.continueReading()) {
scheduleRead();
} else {
allocHandle.readComplete();
pipeline.fireChannelReadComplete();
}
} catch (Throwable cause) {
allocHandle.readComplete();
pipeline.fireChannelReadComplete();
pipeline.fireExceptionCaught(cause);
}
} else {
allocHandle.readComplete();
pipeline.fireChannelReadComplete();
// Check if we did fail because there was nothing to accept atm.
if (res != ERRNO_EAGAIN_NEGATIVE && res != ERRNO_EWOULDBLOCK_NEGATIVE) {
// Something bad happened. Convert to an exception.
pipeline.fireExceptionCaught(Errors.newIOException("io_uring accept", res));
}
}
}创建连接:
@Override
Channel newChildChannel(int fd, long acceptedAddressMemoryAddress, long acceptedAddressLengthMemoryAddress) {
final InetSocketAddress address;
if (socket.isIpv6()) {
byte[] ipv6Array = ((IOUringEventLoop) eventLoop()).inet6AddressArray();
byte[] ipv4Array = ((IOUringEventLoop) eventLoop()).inet4AddressArray();
address = SockaddrIn.readIPv6(acceptedAddressMemoryAddress, ipv6Array, ipv4Array);
} else {
byte[] addressArray = ((IOUringEventLoop) eventLoop()).inet4AddressArray();
address = SockaddrIn.readIPv4(acceptedAddressMemoryAddress, addressArray);
}
return new IOUringSocketChannel(this, new LinuxSocket(fd), address);
}
4. IOUringSocketChannel
新连接注册到 workerGroup 执行,在注册时也会触发 beginRead 方法,也是向 io_uring 提交了一个 POLLIN 任务,在任务完成时 workerGroup 执行回调。
@Override
protected int scheduleRead0() {
assert readBuffer == null;
final IOUringRecvByteAllocatorHandle allocHandle = recvBufAllocHandle();
ByteBuf byteBuf = allocHandle.allocate(alloc());
IOUringSubmissionQueue submissionQueue = submissionQueue();
allocHandle.attemptedBytesRead(byteBuf.writableBytes());
readBuffer = byteBuf;
submissionQueue.addRead(socket.intValue(), byteBuf.memoryAddress(),
byteBuf.writerIndex(), byteBuf.capacity(), (short) 0);
return 1;
}这里才会提交一个 IORING_OP_READ 任务,也就是”读取数据“的任务。
@Override
protected void readComplete0(int res, int data, int outstanding) {
boolean close = false;
final IOUringRecvByteAllocatorHandle allocHandle = recvBufAllocHandle();
final ChannelPipeline pipeline = pipeline();
ByteBuf byteBuf = this.readBuffer;
this.readBuffer = null;
assert byteBuf != null;
try {
if (res < 0) {
// If res is negative we should pass it to ioResult(...) which will either throw
// or convert it to 0 if we could not read because the socket was not readable.
allocHandle.lastBytesRead(ioResult("io_uring read", res));
} else if (res > 0) {
byteBuf.writerIndex(byteBuf.writerIndex() + res);
allocHandle.lastBytesRead(res);
} else {
// EOF which we signal with -1.
allocHandle.lastBytesRead(-1);
}
if (allocHandle.lastBytesRead() <= 0) {
// nothing was read, release the buffer.
byteBuf.release();
byteBuf = null;
close = allocHandle.lastBytesRead() < 0;
if (close) {
// There is nothing left to read as we received an EOF.
shutdownInput(false);
}
allocHandle.readComplete();
pipeline.fireChannelReadComplete();
return;
}
allocHandle.incMessagesRead(1);
pipeline.fireChannelRead(byteBuf);
byteBuf = null;
if (allocHandle.continueReading()) {
// Let's schedule another read.
scheduleRead();
} else {
// We did not fill the whole ByteBuf so we should break the "read loop" and try again later.
allocHandle.readComplete();
pipeline.fireChannelReadComplete();
}
} catch (Throwable t) {
handleReadException(pipeline, byteBuf, t, close, allocHandle);
}
}原来的 epoll 模型是,epoll_wait 等待就绪事件,然后执行相关的 IO 系统调用;现在是先提交一个 POLLIN 任务,有响应时再提交一个具体的IO任务。虽然系统调用的次数是少了,但是多了一轮异步任务,这样操作性能会提升么?
5. iosqeAsyncThreshold 的作用
最后再看一下 iosqeAsyncThreshold 这个阈值的作用。
private int flags() {
return numHandledFds < iosqeAsyncThreshold ? 0 : Native.IOSQE_ASYNC;
}如果连接数大于该阈值,那么在提交任务时会设置上IOSQE_ASYNC 标志。如果设置了该标志,那么该任务会直接被放入 io-wq 队列;如果没有设置,那么 io_uring 会先用非阻塞模式尝试执行一次 SQE 中包含的操作。举个例子:执行 io_read 时,如果数据已经在 page cache 里面,非阻塞模式的 io_read 操作就会成功。如果成功,则直接返回。如果不成功,放入 io-wq 中。
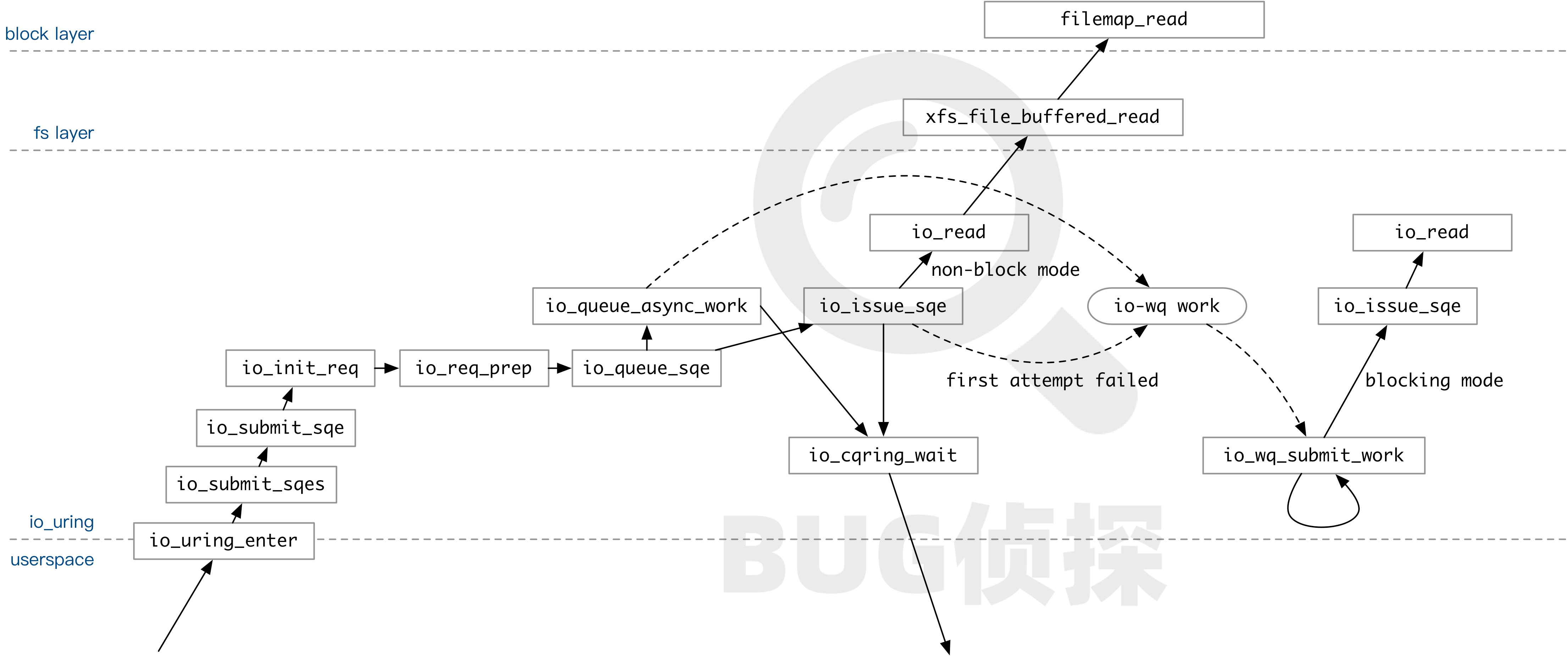
这个标志对性能的影响不太容易下定论,对于网络 IO 这种场景,如果大部分数据已经在 cache 里了,那么再强制放入 io-wq 队列,对于时延和吞吐量应该会有负面影响。
最后测试一下
申请了一台阿里云的虚拟机,安装的是 Ubuntu 20.04.2 LTS,内核升级了一下 Linux 5.12.13-051213-generic。
直接用 Netty 官方实现的 Redis 编解码,用 redis-benchmark 测试一下:
io_uring
socket.yuan@xxx-iouring-test-001:~$ redis-benchmark -c 10 -p 8080 -n 20000000 -t set -d 1024
====== SET ======
20000000 requests completed in 229.39 seconds
10 parallel clients
1024 bytes payload
keep alive: 1
100.00% <= 1 milliseconds
100.00% <= 3 milliseconds
100.00% <= 5 milliseconds
100.00% <= 5 milliseconds
87188.90 requests per secondepoll
socket.yuan@xxx-iouring-test-001:~$ redis-benchmark -c 10 -p 8080 -n 20000000 -t set -d 1024
====== SET ======
20000000 requests completed in 200.70 seconds
10 parallel clients
1024 bytes payload
keep alive: 1
99.99% <= 1 milliseconds
100.00% <= 2 milliseconds
100.00% <= 3 milliseconds
100.00% <= 5 milliseconds
100.00% <= 5 milliseconds
99653.21 requests per second连接数设为 10,请求负载 1KB,测试结果来看 io_uring 相比于 epoll 吞吐量下降了 12.5%
调大连接数,超过 iosqeAsyncThreshold 阈值再试一下:
io_uring
socket.yuan@xxx-iouring-test-001:~$ redis-benchmark -c 50 -p 8080 -n 20000000 -t set -d 1024
====== SET ======
20000000 requests completed in 293.22 seconds
50 parallel clients
1024 bytes payload
keep alive: 1
99.77% <= 1 milliseconds
99.98% <= 2 milliseconds
99.99% <= 3 milliseconds
100.00% <= 4 milliseconds
100.00% <= 5 milliseconds
100.00% <= 6 milliseconds
100.00% <= 7 milliseconds
100.00% <= 8 milliseconds
100.00% <= 9 milliseconds
100.00% <= 10 milliseconds
100.00% <= 12 milliseconds
100.00% <= 13 milliseconds
100.00% <= 14 milliseconds
100.00% <= 15 milliseconds
100.00% <= 16 milliseconds
100.00% <= 18 milliseconds
100.00% <= 23 milliseconds
100.00% <= 26 milliseconds
100.00% <= 27 milliseconds
100.00% <= 32 milliseconds
100.00% <= 32 milliseconds
68208.17 requests per second
epoll
socket.yuan@xxx-iouring-test-001:~$ redis-benchmark -c 50 -p 8080 -n 20000000 -t set -d 1024
====== SET ======
20000000 requests completed in 190.76 seconds
50 parallel clients
1024 bytes payload
keep alive: 1
99.54% <= 1 milliseconds
99.91% <= 2 milliseconds
99.98% <= 3 milliseconds
100.00% <= 4 milliseconds
100.00% <= 8 milliseconds
100.00% <= 8 milliseconds
104846.53 requests per secondio_uring 相比于 epoll 吞吐量下降了 34.9%,并且 io_uring 的 CPU 消耗是 epoll 的两倍(主要是内核处理 io-wq 的消耗)。
io_uring 在原理上有很大的优势,但是要用好还是要付出很大努力,像 Netty 这样的封装看起来是不行的。


