根据码龄来爬取CSDN博客粉丝
序
又是一周周末了,闲暇无事,很有精神, 准备看一下csdn社区中

该如何查看呢,当然是使用爬虫了。构思是爬取一位用户博客中的粉丝,然后依靠这些粉丝的粉丝,把社区中的用户都爬取一遍,筛选出码龄二十年以上的大佬。单点开花,从一到多。

但是人类是有极限的,想法很好(

所以从入门到放弃,

正文开始
IP代理
根据以前爬虫被封的经验,还是得准备一份IP来打个保险。这个保险还是有必要的,之前我学习python爬虫曾经年轻过,结果被封过IP地址,第二天幸好解封了。
# 获取IP代理
def get_ip_list(headers, page):
ip_list = []
for i in range(int(page)):
# 爬取免费的IP
url = 'https://www.kuaidaili.com/free/inha/{}/'.format(i+1)
# print("爬取网址为:", url)
#获取代理IP地址
web_data = requests.get(url, headers=headers)
if web_data.status_code == 200:
tree0 = etree.HTML(web_data.text)
ip_lists = tree0.xpath('//table/tbody/tr/td[@data-title="IP"]/text()');
port_lists = tree0.xpath('//table/tbody/tr/td[@data-title="PORT"]/text()')
type_lists = tree0.xpath('//table/tbody/tr/td[@data-title="类型"]/text()')
# print(ip_lists)
# print(port_lists)
for x,y in zip(ip_lists, port_lists):
ip_list.append(x + ":" + y)
time.sleep(3) # 防止访问频率过快,被封
# print(len(ip_list))
return ip_list
不过每次从网上查找IP太麻烦了,
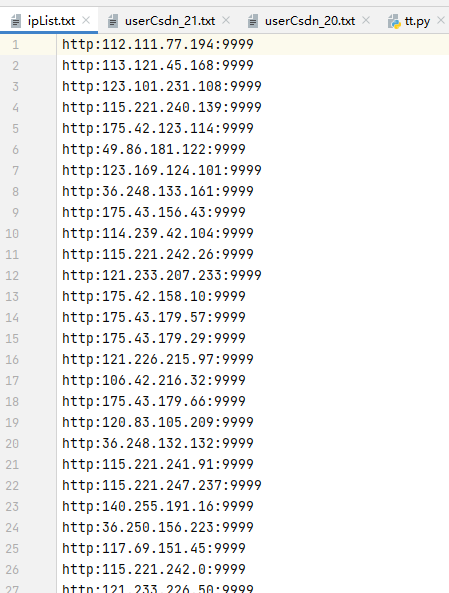
记录IP到txt中
# 记录IP到txt
def save_ip_list():
header = {'User-Agent': random.choice(user_agent_list)}
ip_list = get_ip_list(headers=header, page=3)
with open('userCsdn/ipList.txt', 'a') as fp:
for ip in ip_list:
fp.write('http:' + ip + '\n')
print('记录完成')
fp.close()
获取IP
# 读取IP——txt,返回一个随机IP
def return_ip():
with open('userCsdn/ipList.txt', 'r') as fp:
ip_list = fp.readlines()
fp.close()
ip = random.choice(ip_list)
ip = ip.strip('\n')
return ip
请求头
准备好一些请求头,之后访问时随机使用
user_agent_list=[
'Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0)',
'Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)',
'Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)',
'Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11',
'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'
]
使用方式
header = {'User-Agent': random.choice(user_agent_list)}
cookie
可以从网上找一个cookie来伪装一下,虽然未必有用ㄟ( ▔, ▔ )ㄏ
cookies = dict(uuid='b18f0e70-8705-470d-bc4b-09a8da617e15', UM_distinctid='15d188be71d50-013c49b12ec14a-3f73035d-100200-15d188be71ffd')
接口分析
准备爬取某个用户的粉丝数量信息,那就要先找到对应的入口。csdn官方博客的页面如下(
直接访问页面,获取到的结果中可是没有粉丝信息的
这样就说明了,粉丝信息是动态加载出来的,打开控制台,从Network中进行分析
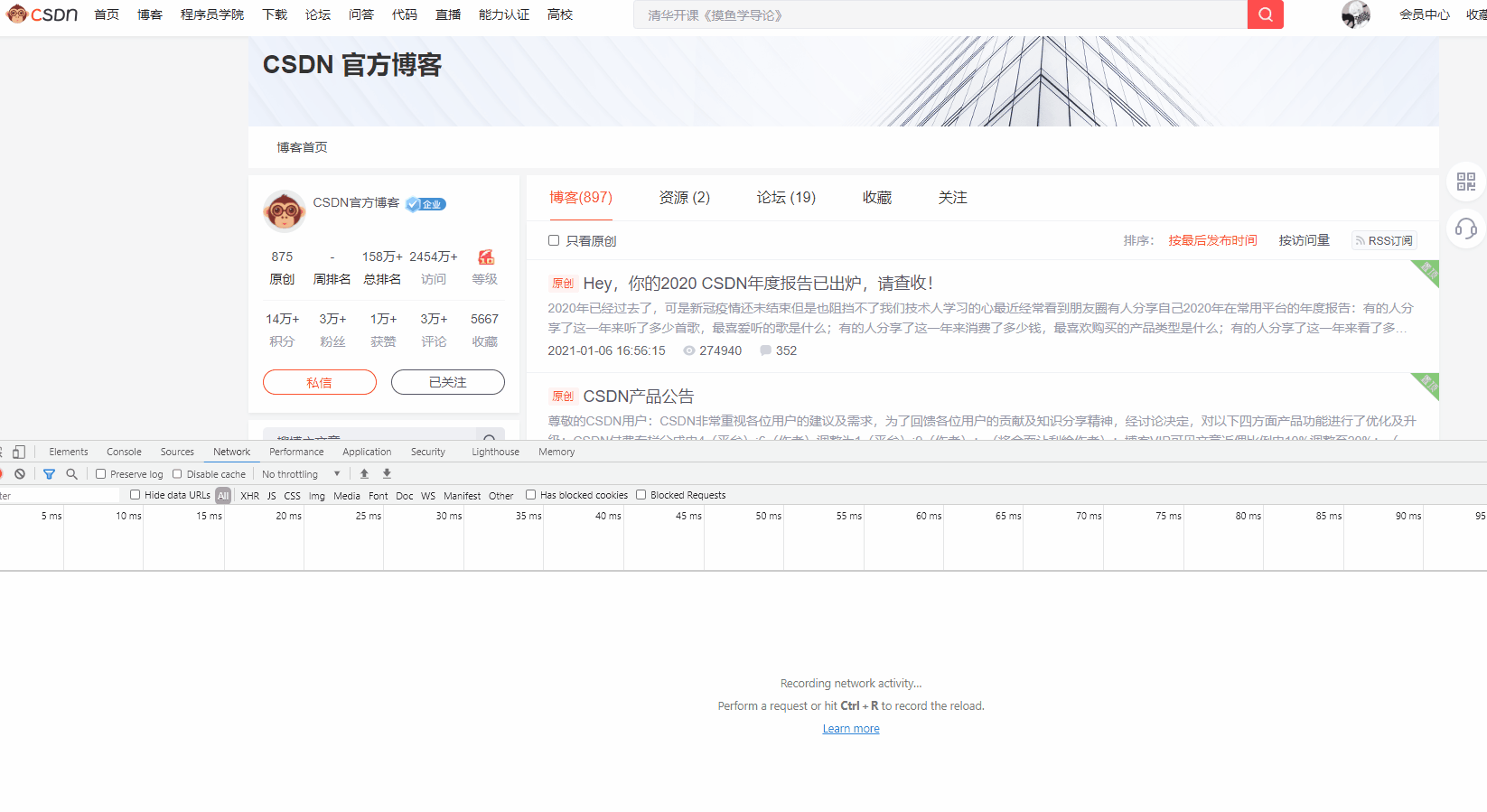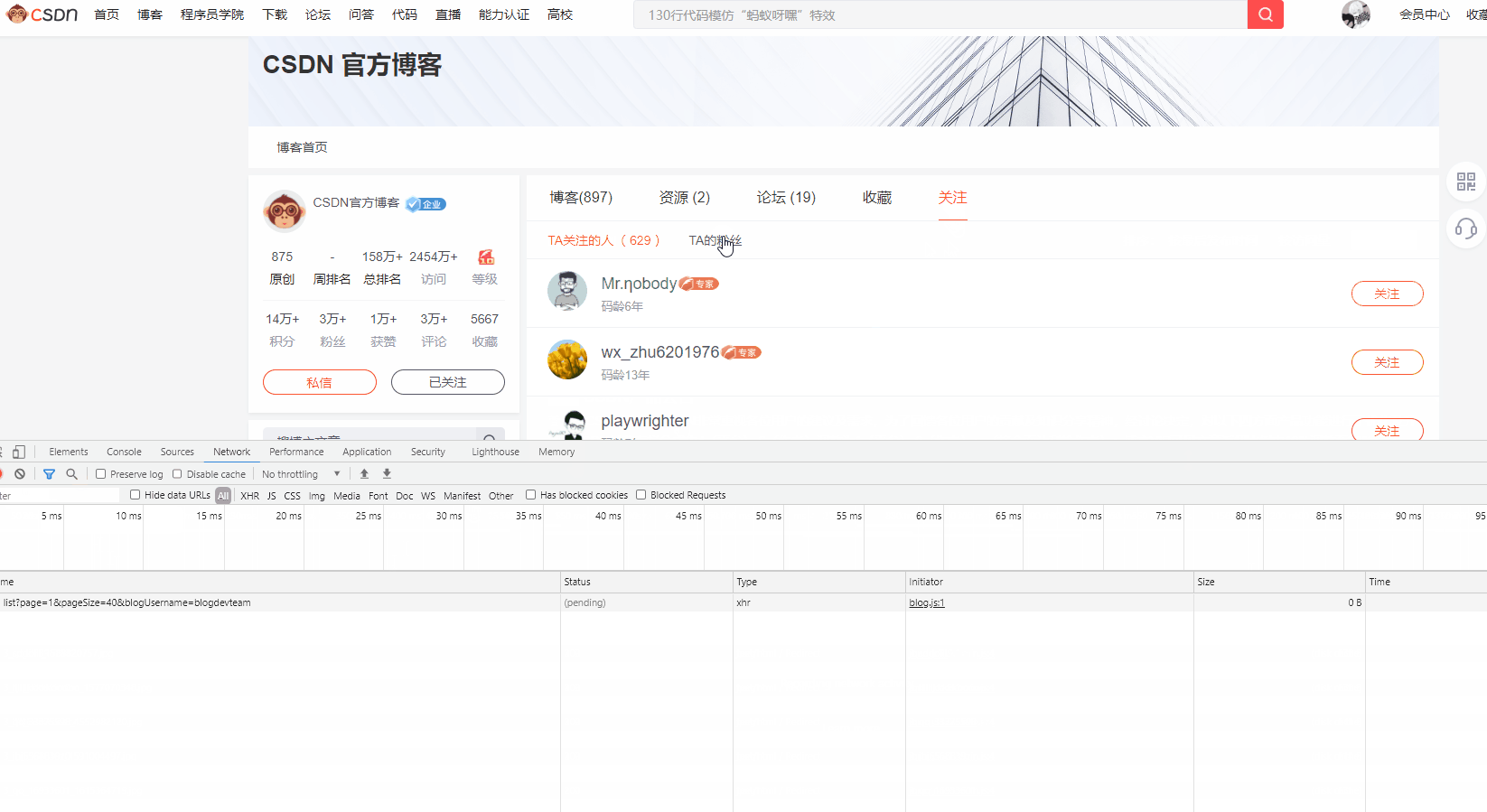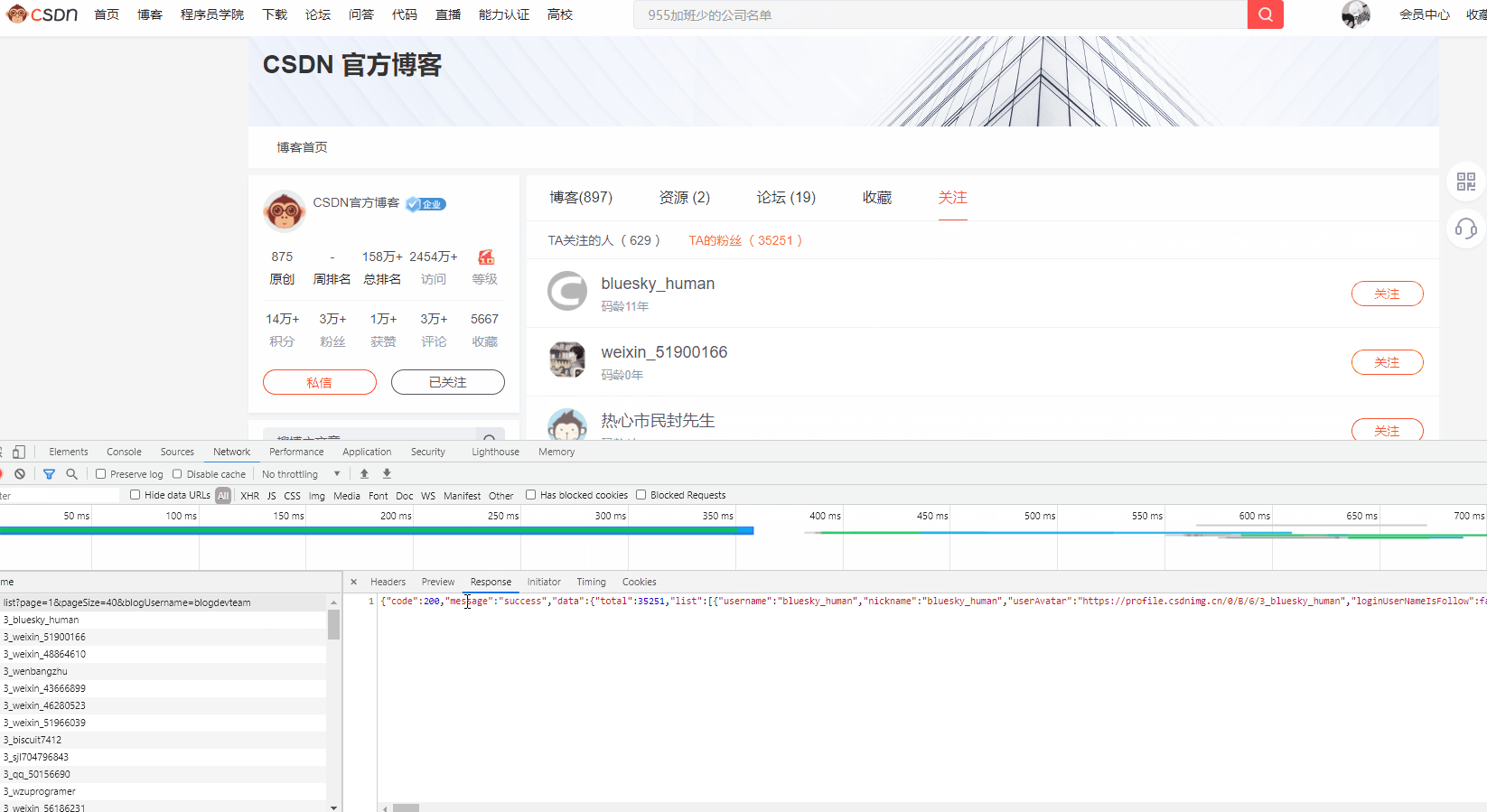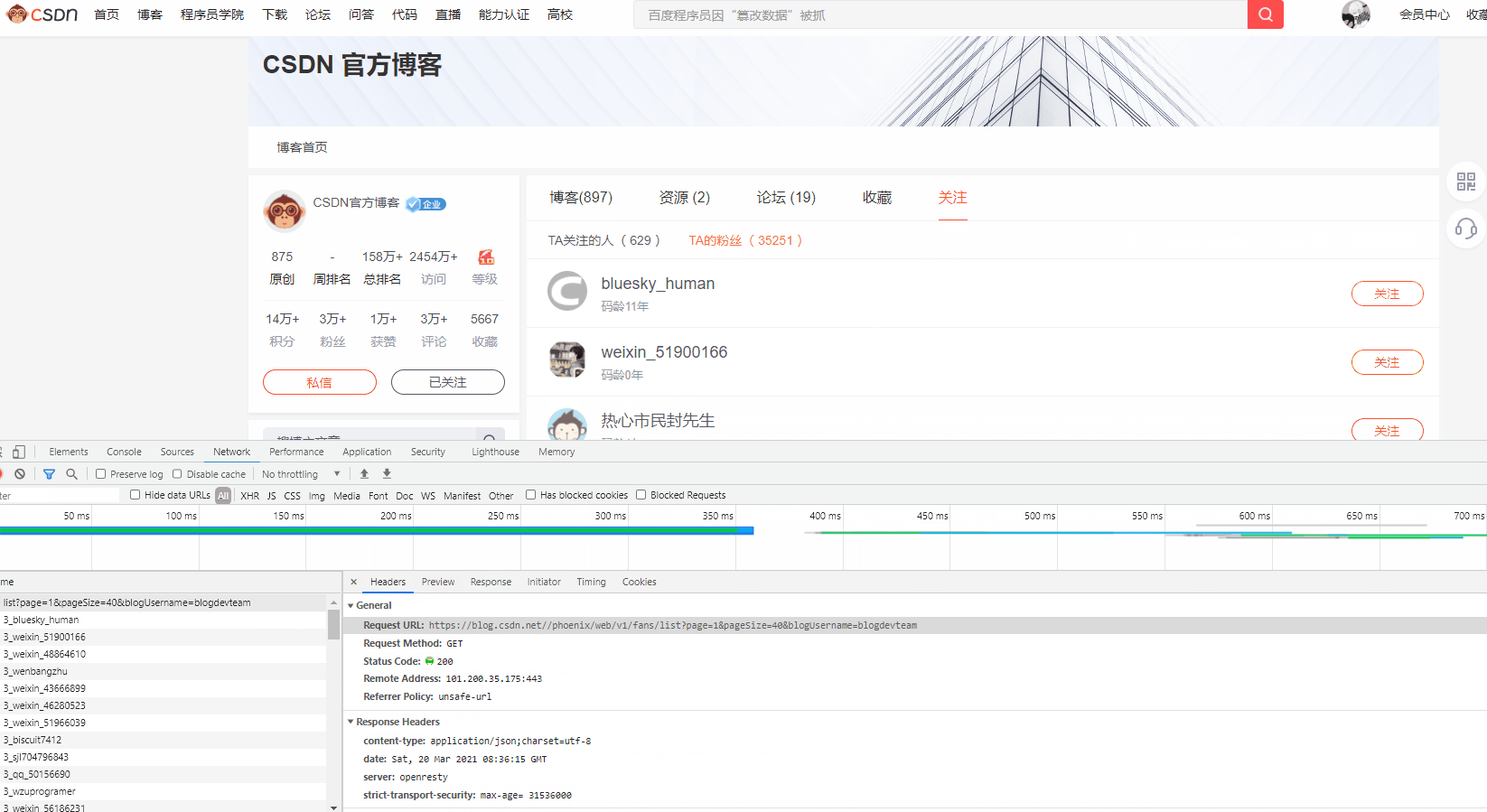
嗯,分析一下接口传参(这里没法弄表格啊!):

返回的数据
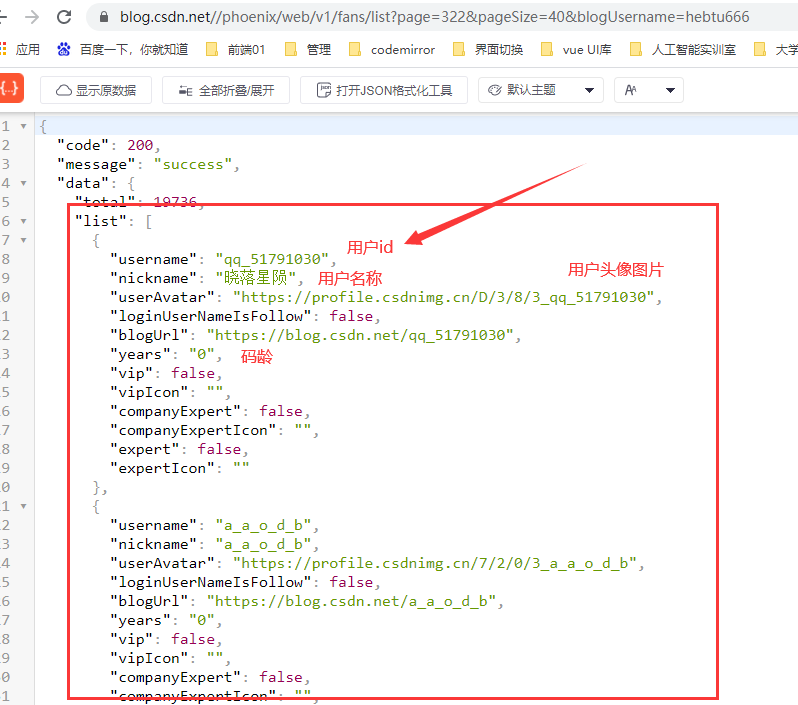
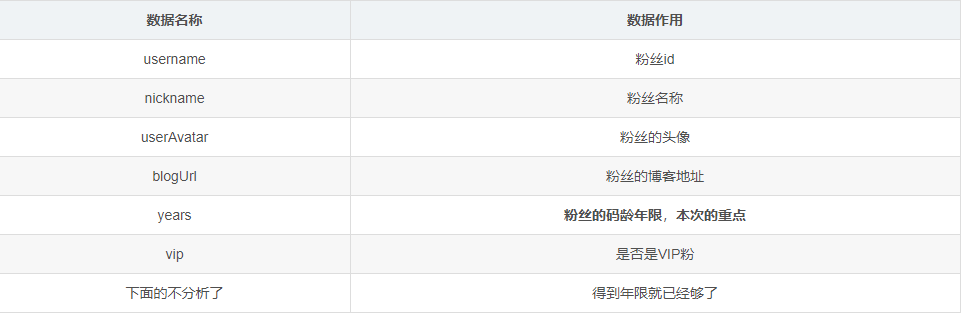
接口数据分析
爬虫数据保存
先提前准备两个方法
根据码龄创建txt文件
# 根据码龄创建txt文件
def mdtxt(year):
if not os.path.exists('./userCsdn/userCsdn_' + str(year) + '.txt'):
file = open('./userCsdn/userCsdn_' + str(year) + '.txt', 'w')
file.close()
根据码龄保存数据到txt中
# 将数据保存至txt中
def saveTxt(year, data):
with open('userCsdn/userCsdn_' + str(year) + '.txt', 'a', encoding="utf-8") as fp:
fp.write(str(data) + '\n')
fp.close()
重点,爬取数据方法
编写一个爬取上面接口分析的粉丝接口的方法函数方法的参数:博客主人的id、需要爬取第几页、一个随机ip
在方法中,
response返回的结果是json,所以使用.json()方法转换
在json数据中分析,如果years大于等于20,就根据具体码龄,判断是否有此年龄的txt文件,没有就创建,并且将数据记录到相对应的txt当中
fansNums = 0; # 找到的粉丝数
# 主要方法,寻找符合条件的粉丝
def findFans( userid, page, ip ):
global fansNums
fans_url = 'https://blog.csdn.net//phoenix/web/v1/fans/list'
param = {
'page': page,
'pageSize': '50',
'blogUsername': userid
}
cookies = dict(uuid='b18f0e70-8705-470d-bc4b-09a8da617e15', UM_distinctid='15d188be71d50-013c49b12ec14a-3f73035d-100200-15d188be71ffd')
header = {'User-Agent': random.choice(user_agent_list)}
proxies = {'http': ip}
response = requests.get(fans_url, param, headers=header, cookies=cookies, proxies=proxies)
page_json = response.json()
for item in page_json['data']['list']:
if (int(item['years']) >= 20):
mdtxt(int(item['years']))
saveTxt(int(item['years']), item)
fansNums = fansNums + 1
多线程爬取
因为要爬取的官方博客的粉丝数量有3万多个,分页的话,最多每页50个,相当于 35251/50 = 705。所以这里建议开多线程进行数据爬取,可参考:
多线程调用方法进行爬取
def forSave(range_list):
for page in range(range_list[0], range_list[1]):
findFans('blogdevteam', str(page), ip)
print('page', page,'记录完成 码龄20年以上粉丝数:', fansNums)
if __name__ == '__main__':
ip = return_ip()
header = {'User-Agent': random.choice(user_agent_list)}
range_lists = [[1, 141], [142, 283], [284, 424], [425, 564], [565, 706]]
pool = Pool(5)
pool.map(forSave, range_lists)
pool.close()
pool.join()
完整代码
import requests
import time
import random
from lxml import etree
import os
from multiprocessing.dummy import Pool
user_agent_list=[
'Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0)',
'Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)',
'Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)',
'Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11',
'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'
]
# 获取IP代理
def get_ip_list(headers, page):
ip_list = []
for i in range(int(page)):
# 爬取免费的IP
url = 'https://www.kuaidaili.com/free/inha/{}/'.format(i+1)
# print("爬取网址为:", url)
#获取代理IP地址
web_data = requests.get(url, headers=headers)
if web_data.status_code == 200:
tree0 = etree.HTML(web_data.text)
ip_lists = tree0.xpath('//table/tbody/tr/td[@data-title="IP"]/text()');
port_lists = tree0.xpath('//table/tbody/tr/td[@data-title="PORT"]/text()')
type_lists = tree0.xpath('//table/tbody/tr/td[@data-title="类型"]/text()')
# print(port_lists)
for x,y in zip(ip_lists, port_lists):
ip_list.append(x + ":" + y)
time.sleep(3) # 防止访问频率过快,被封
return ip_list
# 记录IP到txt
def save_ip_list():
header = {'User-Agent': random.choice(user_agent_list)}
ip_list = get_ip_list(headers=header, page=3)
with open('userCsdn/ipList.txt', 'a') as fp:
for ip in ip_list:
fp.write('http:' + ip + '\n')
print('记录完成')
fp.close()
# 读取IP——txt,返回一个随机IP
def return_ip():
with open('userCsdn/ipList.txt', 'r') as fp:
ip_list = fp.readlines()
fp.close()
ip = random.choice(ip_list)
ip = ip.strip('\n')
return ip
##############################################################
# 用户主页,实际上没有用到
def findCsdnPage( url, ip ):
# 伪造cookie
cookies = dict(uuid='b18f0e70-8705-470d-bc4b-09a8da617e15', UM_distinctid='15d188be71d50-013c49b12ec14a-3f73035d-100200-15d188be71ffd')
header = {'User-Agent': random.choice(user_agent_list)}
proxies = {'http': ip}
page_text = requests.get(url, headers=header, cookies=cookies, proxies=proxies)
print(page_text.text)
# 将数据保存至txt中
def saveTxt(year, data):
with open('userCsdn/userCsdn_' + str(year) + '.txt', 'a', encoding="utf-8") as fp:
fp.write(str(data) + '\n')
fp.close()
# 根据码龄创建txt文件
def mdtxt(year):
if not os.path.exists('./userCsdn/userCsdn_' + str(year) + '.txt'):
file = open('./userCsdn/userCsdn_' + str(year) + '.txt', 'w')
file.close()
fansNums = 0; # 找到的粉丝数
# 主要方法,寻找符合条件的粉丝
def findFans( userid, page, ip ):
global fansNums
fans_url = 'https://blog.csdn.net//phoenix/web/v1/fans/list'
param = {
'page': page,
'pageSize': '50',
'blogUsername': userid
}
cookies = dict(uuid='b18f0e70-8705-470d-bc4b-09a8da617e15', UM_distinctid='15d188be71d50-013c49b12ec14a-3f73035d-100200-15d188be71ffd')
header = {'User-Agent': random.choice(user_agent_list)}
proxies = {'http': ip}
response = requests.get(fans_url, param, headers=header, cookies=cookies, proxies=proxies)
page_json = response.json()
# print(page_json['data']['list'])
for item in page_json['data']['list']:
if (int(item['years']) >= 20):
mdtxt(int(item['years']))
saveTxt(int(item['years']), item)
fansNums = fansNums + 1
##############################################################
def forSave(range_list):
for page in range(range_list[0], range_list[1]):
findFans('blogdevteam', str(page), ip)
print('page', page,'记录完成 码龄20年以上粉丝数:', fansNums)
if __name__ == '__main__':
ip = return_ip()
header = {'User-Agent': random.choice(user_agent_list)}
range_lists = [[1, 141], [142, 283], [284, 424], [425, 564], [565, 706]]
pool = Pool(5)
pool.map(forSave, range_lists)
pool.close()
pool.join()
爬取结果
这些21年的用户不会是csdn建立时就存在的吧???
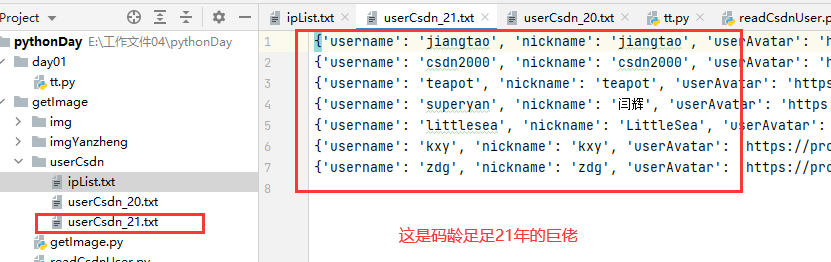
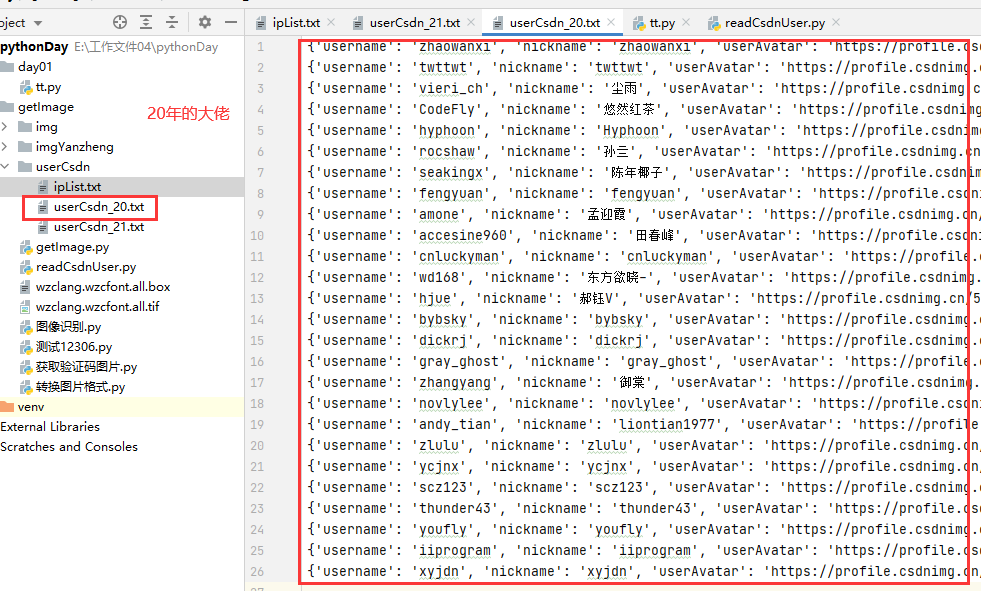
得出结论: csdn官方博客粉丝中码龄20年以上的大佬有33位,而码龄在21年的有7位
呼,终于写完了,路漫漫其修远兮。其实爬虫的功能可以更加优秀,把我一开始的目标也实现,不过还得看自己学习的怎么样啦
