导读
ebay支付账务系统FAS(Financial Accounting System)的“读模块”能将“”[1]产生的业务数据源源不断地传给FAS下游。这是各类金融财务报表、风控、查询服务和数据分析的核心数据来源。“读模块”旨在为FAS用户提供一个针对所有读场景的一站式解决方案。该模块自去年4月上线以来,总计传输账务记录超两百亿条,数据规模过百TB,并且随着业务量的不断上升,写读两端的传输延时依然能稳定维持在亚秒级别。本篇文章将讲述我们设计的“读”一无二的系统是如何构建的,以达到高数据质量、低延时、满足所有读场景和开发简单等要求。
一、背景介绍
FAS用户对于“读”的需求可以归纳为以下四点:
与其他互联网应用相比,作为一个核心金融系统,FAS和钱息息相关。这就要求:①下游收到的结果必须绝对正确,错一条记录,少一条记录,甚至多一条记录,都会带来难以估量的后果;②数据必须严格按照写入数据源的顺序来消费,否则进账出账的顺序不一样,对应业务的含义也会完全不一样。
对于高实时性的下游服务(如查询账户余额),延时越低意味着可以更快地获取到最新余额。这样许多支付业务就能更准确和及时,用户体验也就会更好。
使用FAS数据的部门有很多,每个部门都有各自的业务,业务场景不同,所需的数据也是各异的。这就需要“读模块”不仅能提供原始数据,还能支持产生对原始数据做多次加工计算出来的衍生数据。
业务开发者希望在保证项目质量的同时缩短开发周期,这就要求对外接口的设计尽可能简单。
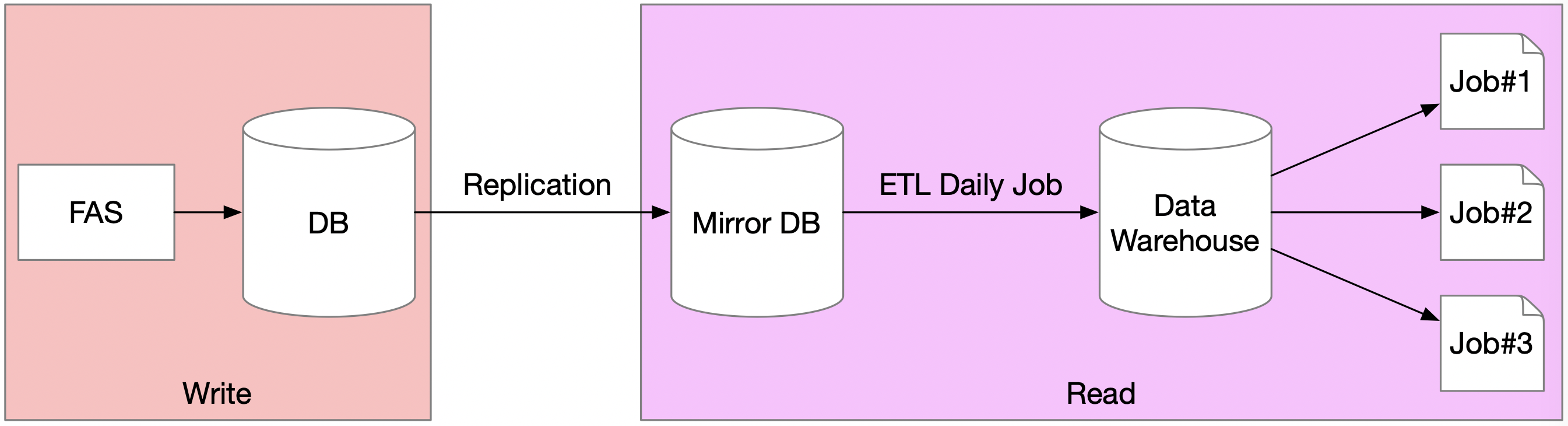
在“读模块”之前,下游获取数据的方式如下图所示。FAS先将数据写入数据库(Database,DB),DB接着把数据同步到它的镜像数据库(Mirror DB),然后ETL Job(将业务系统的数据经过抽取Extract、转换Transform之后加载Load到数据仓库)每天将数据从镜像数据库导入到数据仓库(Data Warehouse,DW)。如此一来,下游就能通过访问DB或DW来获取FAS数据。
图 1
上述方式主要存在以下三个问题:
因此“读模块”在设计时充分考虑到了上述需求,通过自研架构,我们保证FAS数据能以一种准确、有序、稳定和高效的方式被下游使用,并且学习成本低、易上手。
二、系统设计
在之前的文章中介绍了FAS系统的“写模块”被设计成了一个状态机(StateMachine),状态机对上游请求的处理结果称为事件(Event),事件为既定事实,一旦产生就无法更改(Immutable)。所有事件会以追加的方式(Append-only)写入到事件仓库(Event Store)。事件仓库即为FAS的Golden Source,它被抽象成一个只能追加且能无限延伸的一维数组,数组的每一项即为事件。
而“读模块”的主要功能是把这个数组完整无误地传递给下游。整个“读模块”,按功能可以分成复制子模块和处理子模块。
1、复制子模块
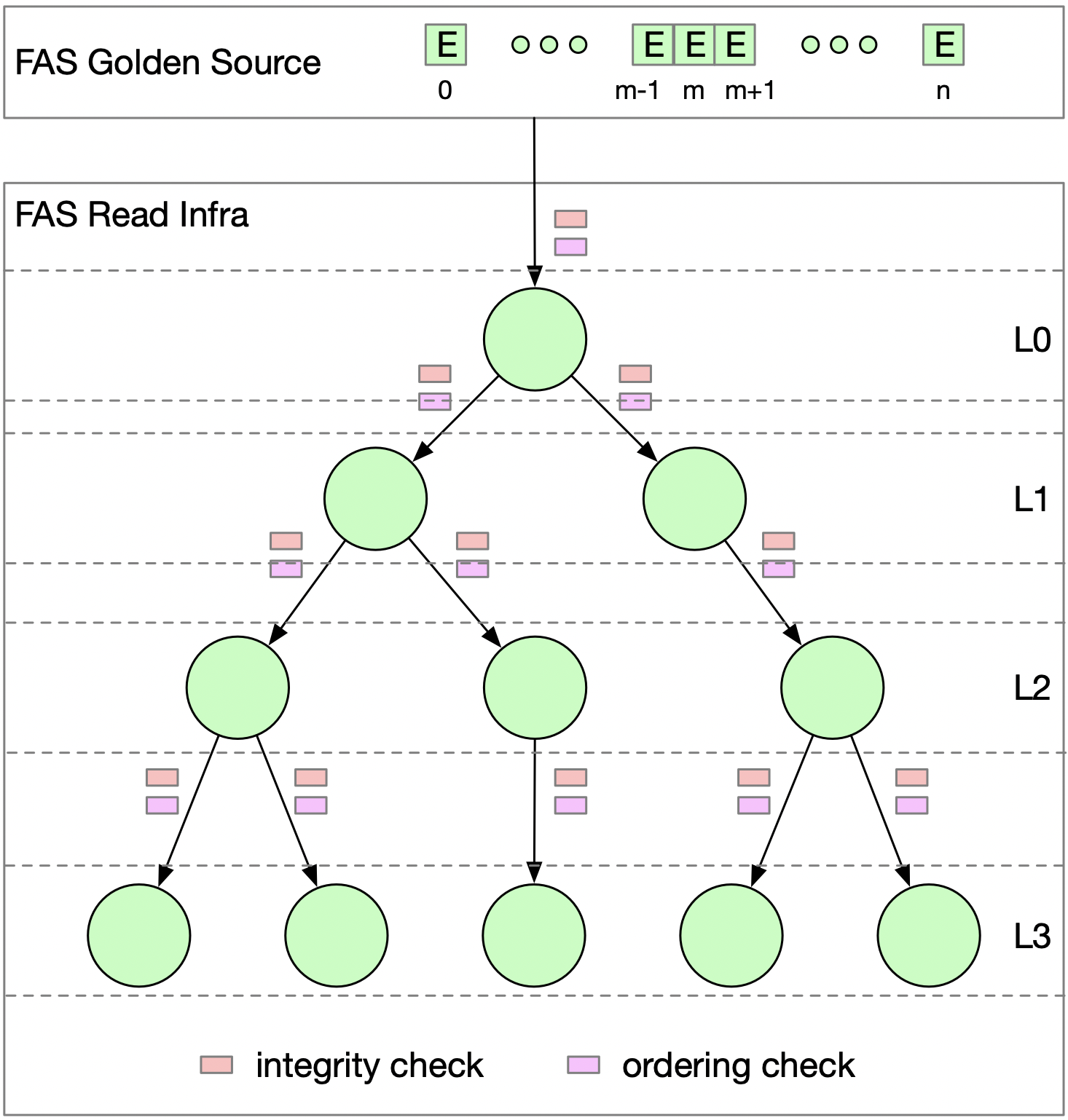
图 2
如上图所示,复制子模块被设计成一个分层的树状结构,顶层L0的节点(Root Node)直接从Golden Source获取;第N层节点从上层(N-1层)获取数据,并为下层(N+1层)提供数据。这样设计既能满足各应用对延时的不同需求,也不会对Golden Source造成太大压力。因此复制子模块有如下优点:
1)数据的高质量保证
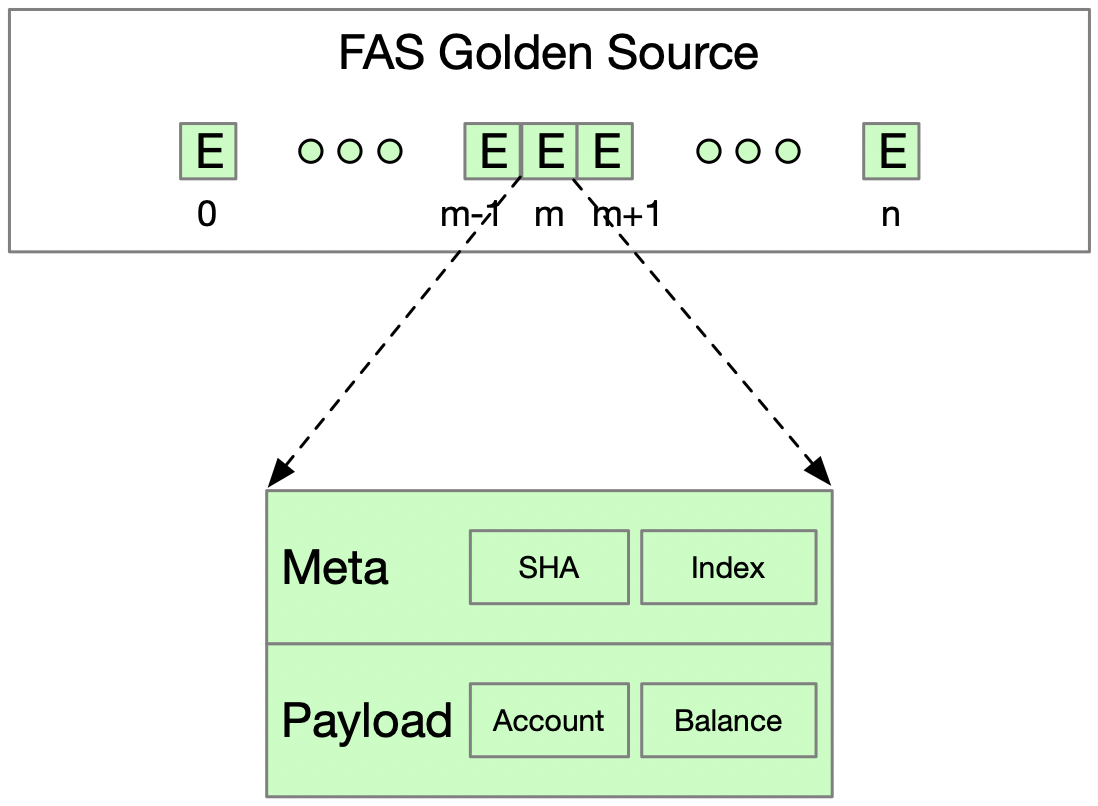
图 3
我们在FAS Golden Source的事件中采用了如上图所示的存储格式。它由两部分组成,分别是Payload和Meta。
如此设计存储格式就可以包含以下两类验证,来保证数据在每一个复制环节中的正确性和有序性:
2)稳定的低延时
我们设计了一套完备的重连和服务发现机制,即当发现父节点连接不上时,子节点会自动寻找新的父节点,整个过程不会超过一分钟。并且,由于数据分发过程没有DB和DW,其可用性不受到它们升级的影响。这两点保证了整个服务的可用性和稳定性。
为了实现稳定的低延时,我们对近期数据和历史数据的延时分别做了优化,并且提高了节点数据的恢复速度。
(i)近期数据的延时优化
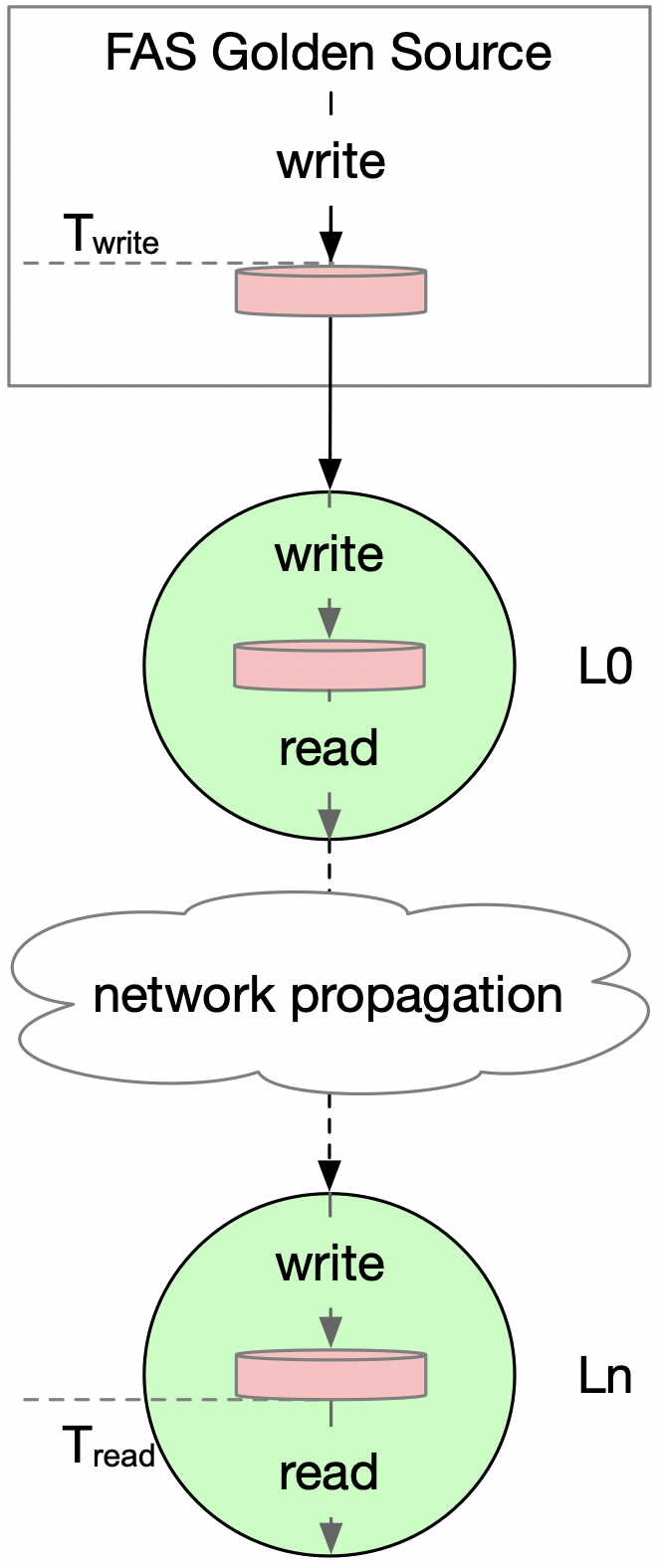
最近发生的事件都存储于本地磁盘,延时是指该事件被写入Golden Source的时刻(Twrite)和被下游读出时刻(Tread)的差值,如下公式所示。
该差值主要由两部分组成:该事件从顶层到第N层经过的网络传输时间和每一层节点写入本地磁盘到从磁盘读出的时间。
图 4
为了缩短网络传输时间,节点会按照同机房->同数据中心->同地区->异地机房的顺序寻找父节点;为了缩短本地读写时间,采用了基于mmap的(zero-copy)[2],减少了用户空间和内核空间的数据拷贝次数。
(ii)历史数据的延时优化
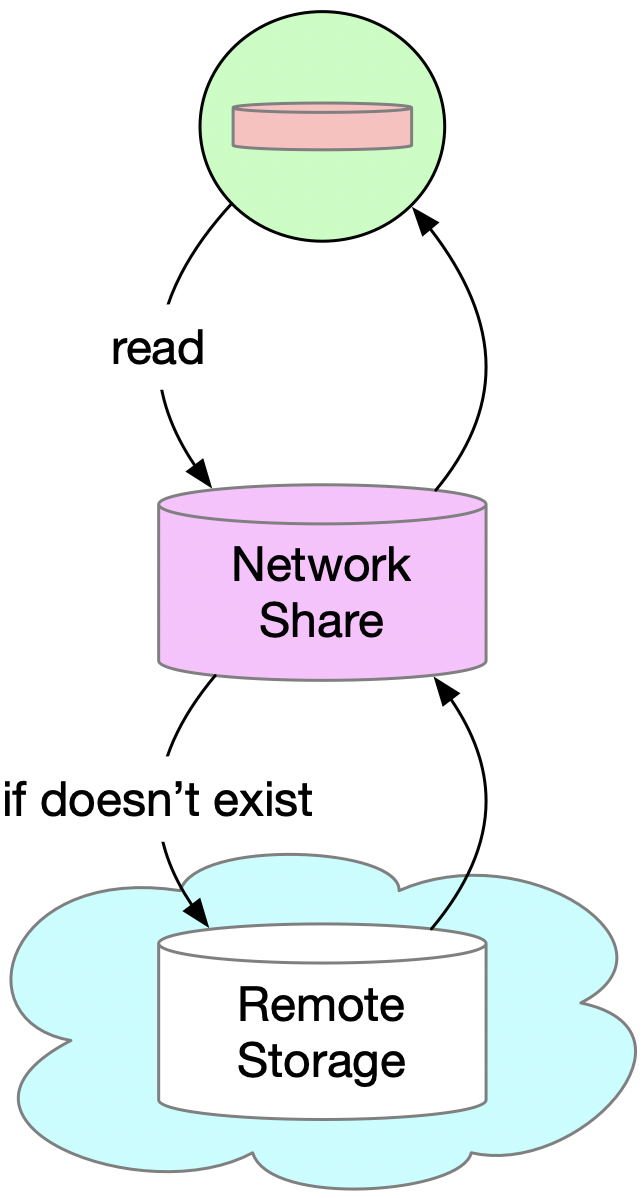
由于本地磁盘空间有限,历史事件无法一直保存在磁盘上。这些历史事件会被存入远程存储系统(Remote Storage),每一个节点都能直接访问。为了降低远程存储系统访问延时过高的影响,我们设计了一个三层存储结构,如下图所示:
图 5
本地磁盘只会保存最近几天的数据,所有的历史数据被保存在远程存储系统中,而中间的网络存储作为缓存,则保留了近期从远程存储系统访问过的历史数据。
(iii)节点数据恢复
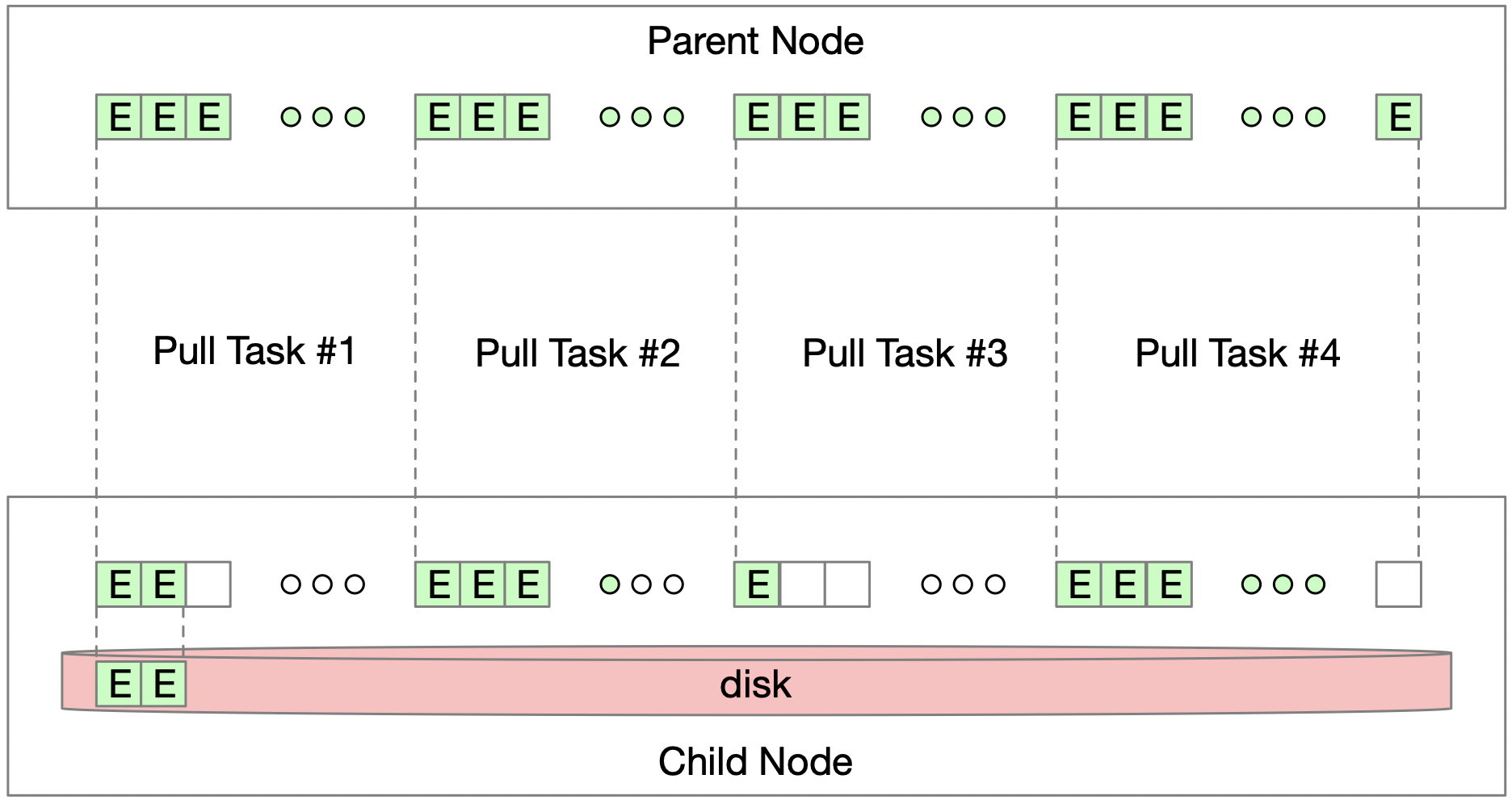
如果有新增的节点,或者由于机器故障等影响的已有节点,在重新启动后,需要从父节点恢复数据。为了缩短这一过程,采用了类似[3]的机制做并行拉取,如下图所示:
图 6
子节点会将需要恢复的数据分成若干段,每一段由一个线程去父节点拉取。这样做能极大地提高恢复速度。同时,只有前面的数据被写入之后,当前数据才能被写入磁盘,所以有序性也能得到保证。
2、处理子模块
如果将“写模块”比做发电厂的话,那么“读模块”中的复制子模块就是电网,而处理子模块就是电插头,它将电力源源不断地输送给各类电器(即读应用)。
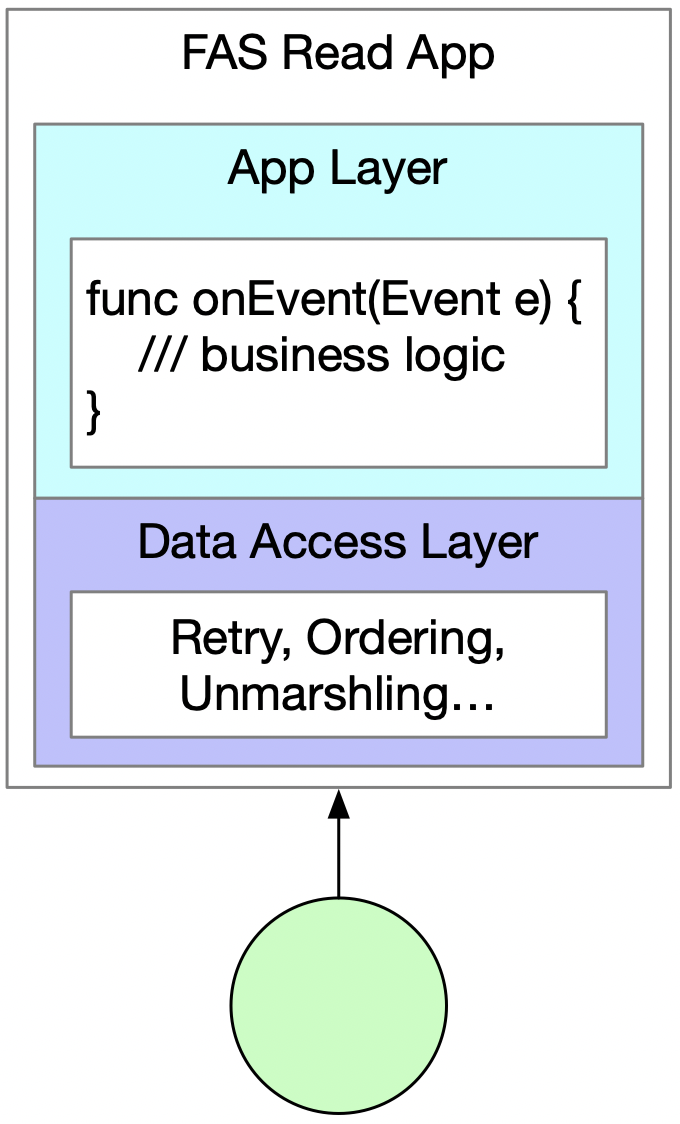
读应用的架构如下图所示。
图 7
数据访问层负责从复制子模块的节点中获取数据,对原始数据解码并构造出事件(Event)后,将它传递给应用层并执行onEvent回调函数。该函数是用户处理FAS数据的接口,由用户实现具体的处理逻辑。
这样设计有如下两大好处:
1)简单易用,开发效率高
首先,该模块对外只提供了一个简单的接口,让开发者只需聚焦在业务逻辑的实现上,而不用操心其他技术细节(如多线程获取数据、换主、重连、去重、保序等)。
其次,由于数据的存储格式是语言中立的,理论上可以支持各种编程语言来开发读应用。
2)支持所有的读场景
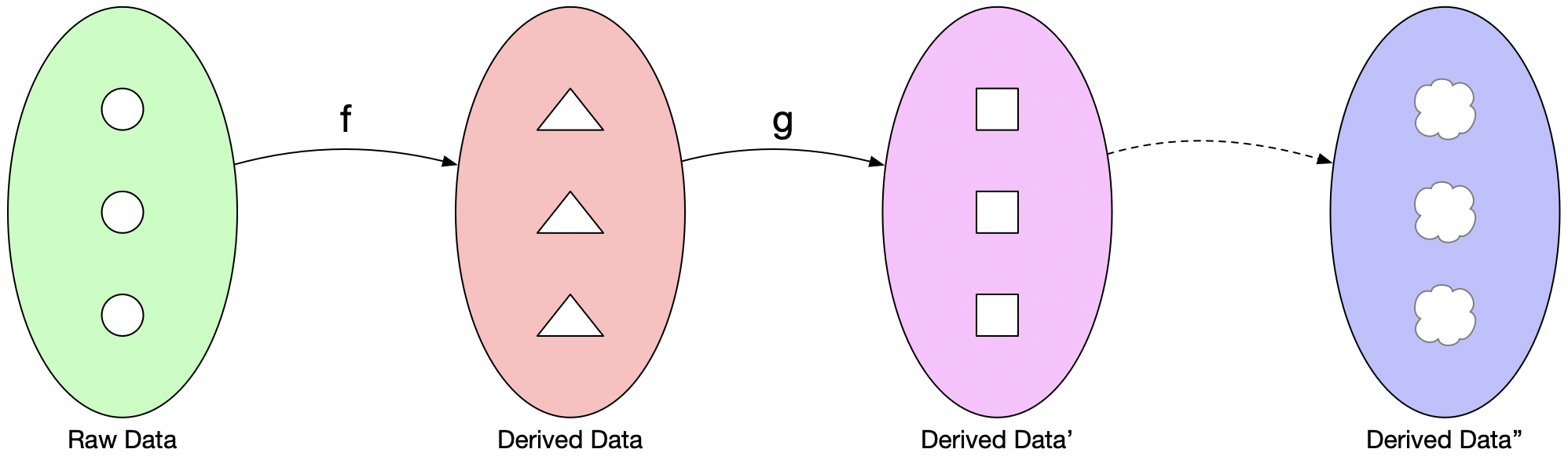
我们将读场景定义为用户能拿到的包括原始数据及基于此不断衍生出来的所有数据的全集,如图8所示。当中的f,g在集合论中被称为映射函数,可以将一个集合的元素通过计算,产生另一个集合中的元素。
图 8
映射函数对应了这里的onEvent函数。由于处理子模块本身还能作为数据节点,计算产生的数据可以作为另一个子模块的输入,进而产生新的衍生数据。
图 9
看到这里,读者可能会问,为什么不使用现有流处理架构?这个和现有的基于[4]或[5]的流处理模式有什么不一样?
这里最大的区别在于Kafka或Flink只能保留最近几天的数据,如果要访问历史数据,下游应用需要写代码去其他地方(如HDFS)拿,而FAS的读模式对外只提供单一的API接口,省去了拿历史数据的额外开发工作。
三、总结
FAS作为一个读写分离(Command Query Responsibility Segregation,)系统[6],“读”和“写”同等重要。而和“写”不同,“读”需要解决的挑战有:高数据质量、低延时、满足所有读场景和开发简单等。我们在充分考虑这些需求的基础上设计开发出了“读模块”,为FAS下游应用提供了一站式解决方案。同时,我们也希望能为对数据有同等需求的行业,例如金融、医疗等,提供一些参考。
四、展望
目前的读应用只能接受一组数据流作为输入,后续会加入对多组数据流的支持,从而丰富应用场景。未来,我们还将进一步提高读模块的通用性,将框架和数据完全解耦,使得稍作修改就可以作为其他系统读模块的解决方案。
参考文献
[1] ebay支付核心账务系统架构演进之路:
[2] 零拷贝提高IO性能:
[3] TCP Sliding Window Protocol:
[4] Kafka Streams Architecture:
[5] Flink Architecture:
[6] CQRS:
文章原载于“eBay技术荟”微信公众号,原文链接:。欢迎前往关注。