攻克MySQL-索引基础
1. 基本概念
提到MySQL,你脑海中浮现的概念是什么?锁、索引、慢SQL、分库分表等等,这些概念在我们日常的开发工作中会经常用到,比如某个应用的监控和日志显示某个SQL的执行时间超过了5秒,并导致预定的功能没有正常执行,这时候我们再分析原因后,常常给到的解决方案是“给某几个字段加个索引吧”。通常来讲,80%的时候加个索引确实能解决问题,但是也有很多时候,我们明明加了索引但是查询效果依旧很慢,这就要求技术同学必须知其然更要知其所以然——彻底搞清楚索引的概念和底层的工作原理。
简单说,索引是存储引擎用于快速找到记录的一种数据结构。
2. 数据结构
2.1 有序数组
有序数组的查询时间复杂度是O(Log(N)),同时也支持范围查询,但是它的弱点是维护成本很高,每次新插入一个数据,都要将要插入的位置之后的所有元素后移。
2.2 Hash表
hash表是数组的一种扩展,它的核心思想是:利用数组支持按照下标随机访问数据的特性,将要存储的数据的编号和数组的下标通过hash函数映射起来,即index=hash(key),key是要存储的数据的编号,index是数组的下标,hash是hash函数。hash表这种数据结构的查询复杂度是O(1),但是对于范围查询场景的支持并不好。
2.3 树
树也是一种经典的数据结构,基本的数据结构是二叉树,为了确保树的查询效率是O(Log(N)),又推演出了平衡二叉树、红黑树等数据结构。在数据库存储引擎中使用二叉树是不够的,因为这会让树的高度很高,从而导致大量的磁盘访问,为了降低树的高度(减少磁盘访问的次数),我们就应该用N叉树。
3. InnoDB的索引模型(B+树)
3.1 B+树的设计
B+ 树是一棵完全平衡的 m 阶多叉树。一个4层的B+树就可以存储非常大的数据量,假设一个元素的大小是0.01KB,一个 4K 的节点的内部可以存储 400 个元素,那么一个 4 层的 B+ 树最多能存储 400^4,也就是 256 亿个元素。
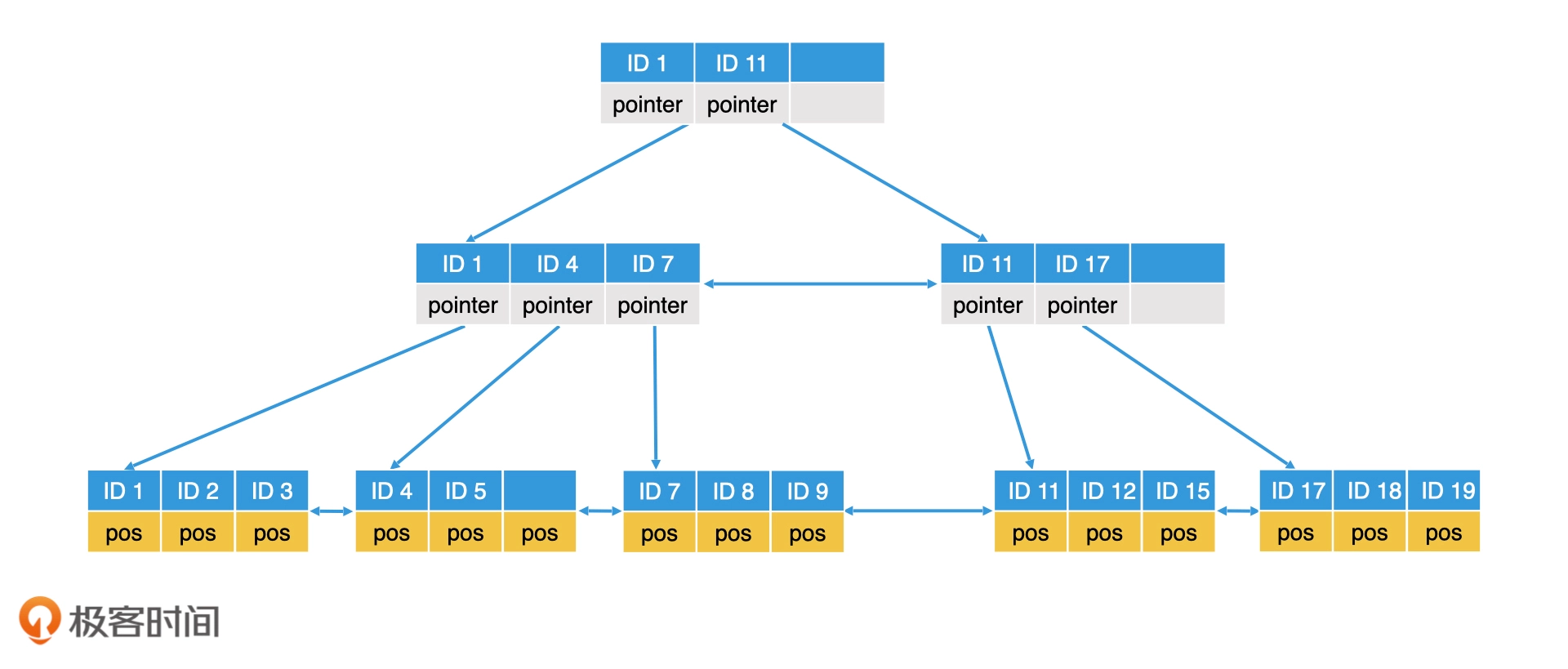
B+树的设计思路是充分考虑了磁盘+内存检索的常见的实际需要:(1)尽可能少的磁盘访问次数;(2)尽可能多得将数据在内存中访问。B+树的设计有下面几个特点:
让一个节点的大小等于一个块的大小(操作系统读取磁盘数组的最小单位) 。节点内存储的数据,不是一个元素,而是一个可以装 m 个元素的有序数组 。将所有的节点分为内部节点和叶子节点。尽管内部节点和叶子节点的数据结构是一样的,但存储的内容是不同的,
内部节点只存储指针,叶子节点只存储数据 ,将索引和数据分离。B+ 树还将
所有叶子节点串成了有序的双向链表 ,这样一来,B+ 树就同时具备了良好的范围查询能力和灵活调整的能力了
3.2 B+树的操作
3.2.1 检索
B+树的检索过程是,先在根据树形查询找到叶子节点,然后再在叶子节点的数组中进行二分查找,整体的查询耗时依然是O(Log(N))。
3.2.2 插入
B+树插入新的节点的时候,会先找到要插入的数据应该放入的叶子节点,如果发现叶子节点已经满了,这时候要先将叶子节点拆分为2个,然后再调整对应的父节点,如果发现父节点也需要调整,则持续调整,直到整个树处于稳定状态
3.2.3 删除
删除数据也类似,如果节点数组较满,直接删除;如果删除后数组有一半以上的空间为空,那为了提高节点的空间利用率,该节点需要将左右两边兄弟节点的元素转移过来。
4. 索引分类
4.1 存储方式
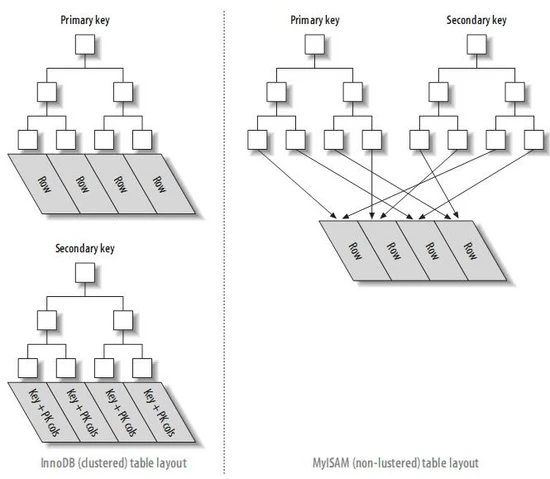
聚簇索引不是一种索引类型,而是一种数据存储方式,在InnoDB中使用的是聚簇索引,而在MyISAM中使用的是非聚簇索引。从下图中可以看出,InnoDB的数据结构中,同时保存了索引的key和对应的数据,而在MyISAM中索引和数据则是分开的。
4.2 功能逻辑
4.2.1 主键索引 VS 二级索引
4.2.2 普通索引 VS 唯一索引
4.2.3 单列索引 VS 组合索引
5. 面试问题
在工作中可能不会想这么多,但是最现实的情况来说,面试的时候对于这些底层技术原理的掌握,可以让面试官认可你的技术深度,因此广大开发同学还是要注重基础知识的掌握,基于本文的内容,我罗列了一些常见的面试问题,供大家思考。