大画 Spark :: 网络(2)-下篇-通过网络收取消息的过程
回顾
上一篇,我们从接收到消息到RpcEndpoint的过程做了简单的梳理,理清了以下几个概念
通过与SpringMVC类比的方式介绍了整个的流程,具体参看这里
图示规则
因为scala和java中的method是最重要的程序执行过程,所以这部分的描述我永远会用一种颜色,也就是绿色方框来表示,其余的类型会根据场景不同而调节展示方式
本篇主旨
对于消息收取的过程,我们搞清楚下图的第5步是怎么做的
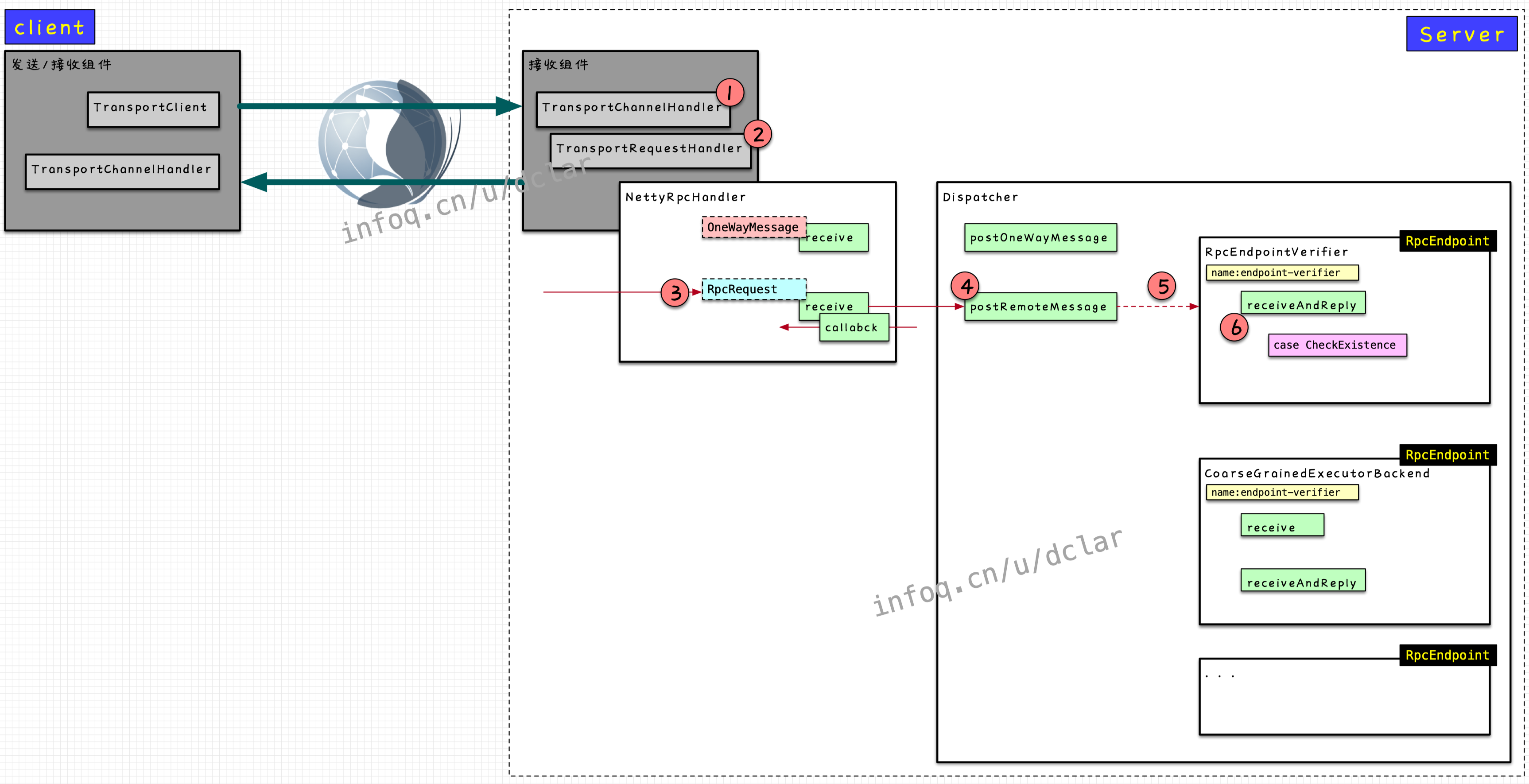
高度抽象消息发送过程
很多技术在使用和研究的时候,大家很容易一下子陷入到细节中,无法自拔,我以前也是这样的状态。在几个细节中可以熬好久,但是总是解决不了问题。这个时候,需要跳出来,从高处重新审视一下,会有不一样的收获。
所以我总结或者分享的时候也希望在细节中走一小段后,就跳出来俯视一下,这样会理解的更透彻,也会让被分享者理解的更充分。
消息机制的分层
其实,我总结的这个消息分层机制,根据或其实有些许的不同,但大概可以这么理解,方便记忆
Client端到Server端的过程,可以看到在中间处理层,传递的消息以的形式
到了网络组件层,封装成了
到达Server端后重新解成了
为了业务处理方便,又封装成了,经过方法的调用,通过一系列的处理最终触达到的实例
为什么Client端没有独立出一个业务处理层呢?
其实Client端也模糊存在这个层次,但是与所谓的中间处理层交织在了一起;并且,发送消息的过程本身比较简单,不需要很复杂的封装,也就没有划分很清晰。但是接收方对于不同消息的类型以及内容要做匹配,进入不同的的实例中,所以抽象出了一个业务处理层,我们本次探讨的也是这个层面的处理过程
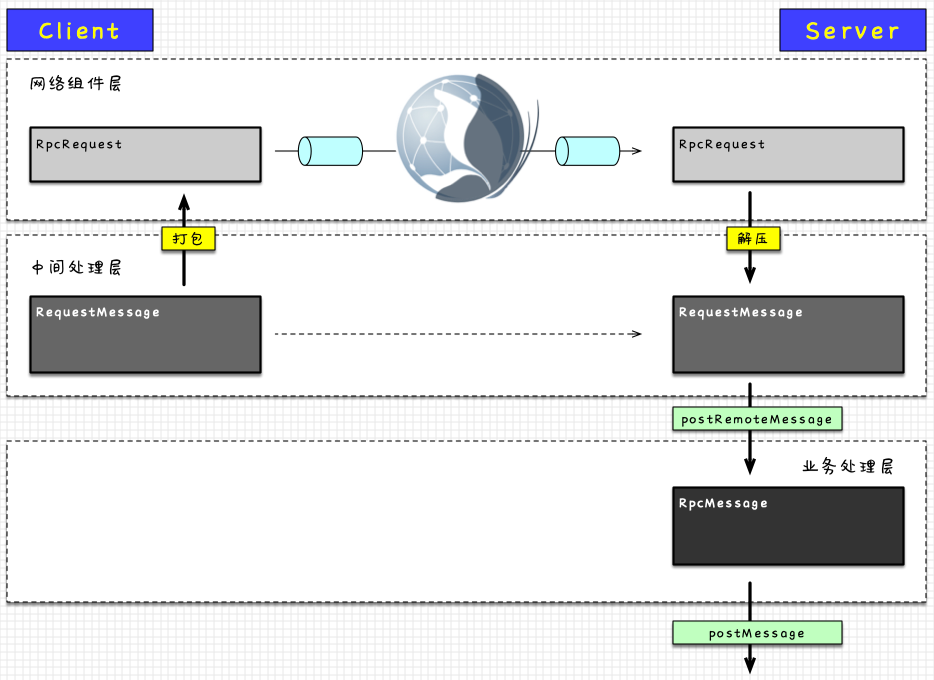
Dispatcher的消息处理模型
用一个简单过程来描述
就是利用某个实例唯一类型的name,在Dispatcher中,通过(是一个)中的(name),找到value的结构体
从结构体中找到对应的
执行的方法
中包含最终需要调用的的实例,根据消息类型不同,调用方法或方法
以上的过程不是一个线性调用的过程,的方法是通过一个线程池的生产者-消费者模式来实现的
用做的实例
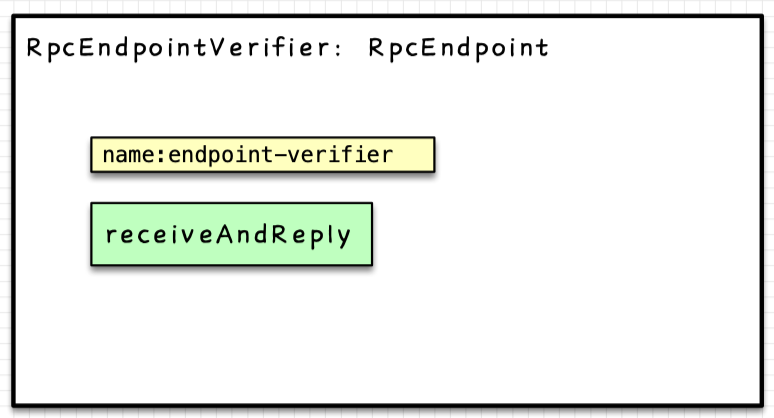
本篇,以的一个最简单实例来说明
其唯一识别名称name:enpoint-verifier
包含一个方法
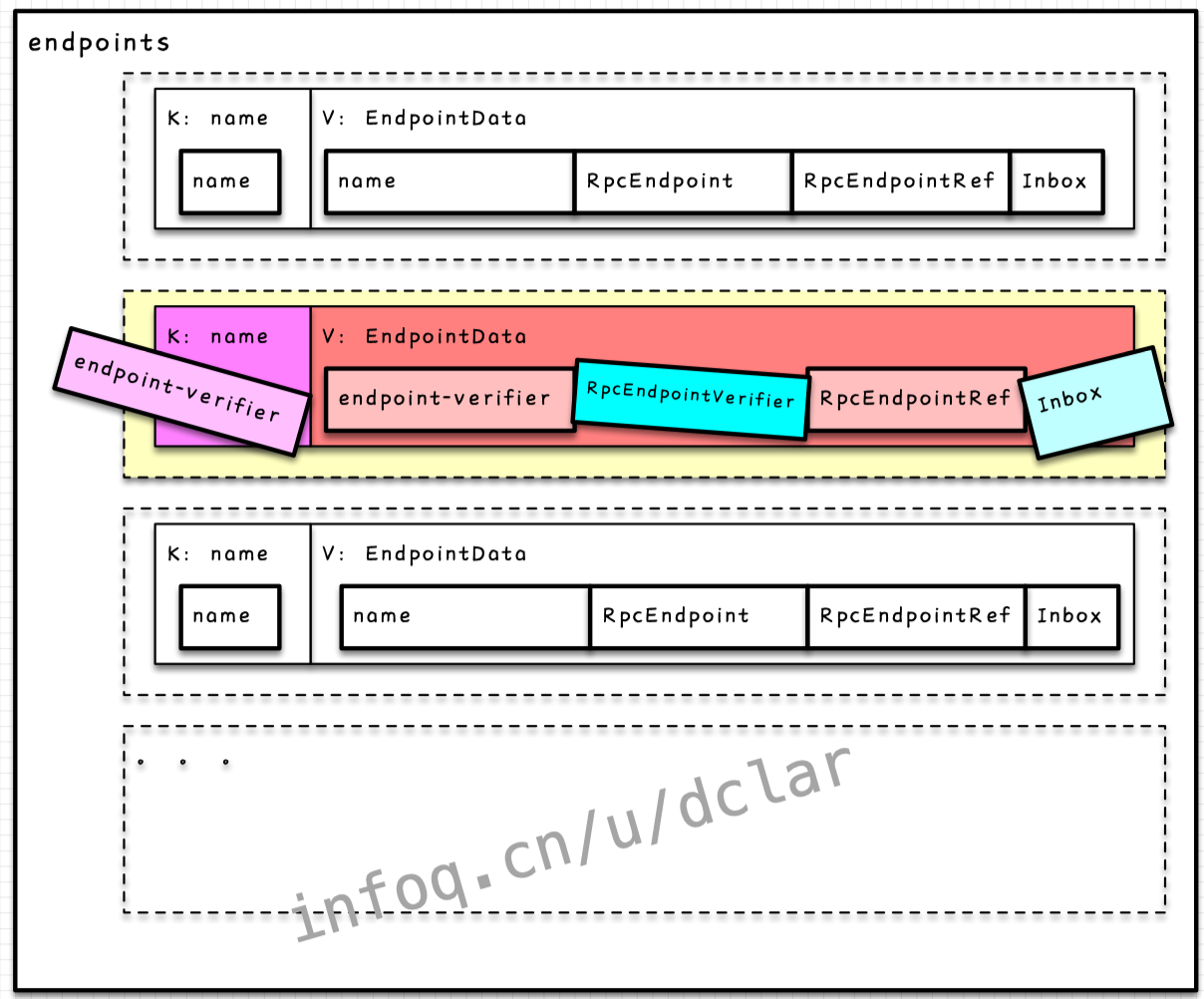
Dispatcher的endpoints
结构
endpoints是一个,,
private val endpoints: ConcurrentMap[String, EndpointData] =
new ConcurrentHashMap[String, EndpointData]
我们来看一下图示的数据结构,这个结构很简单清晰吧,以的实例来举例
作用
看到KV结构,很容易联想到就是通过key的name,获取value的结构;它本质上是一个数据存储的仓库
EndpointData
结构
如上图所示,name是每一个实例的唯一名字,如图所示,是以下数据的集合
的唯一名称
的实例
的实例
的实例
作用
存储着一个实例的所有基础信息组合,其中最重要的结构体是处理到达端消息的一个存储器+执行引擎
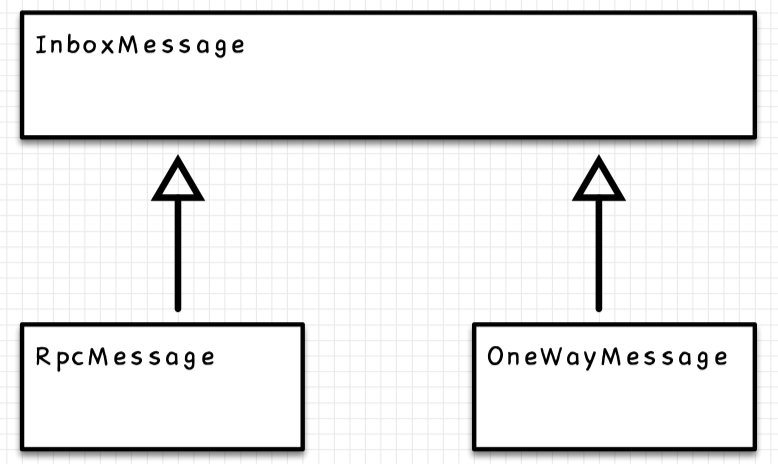
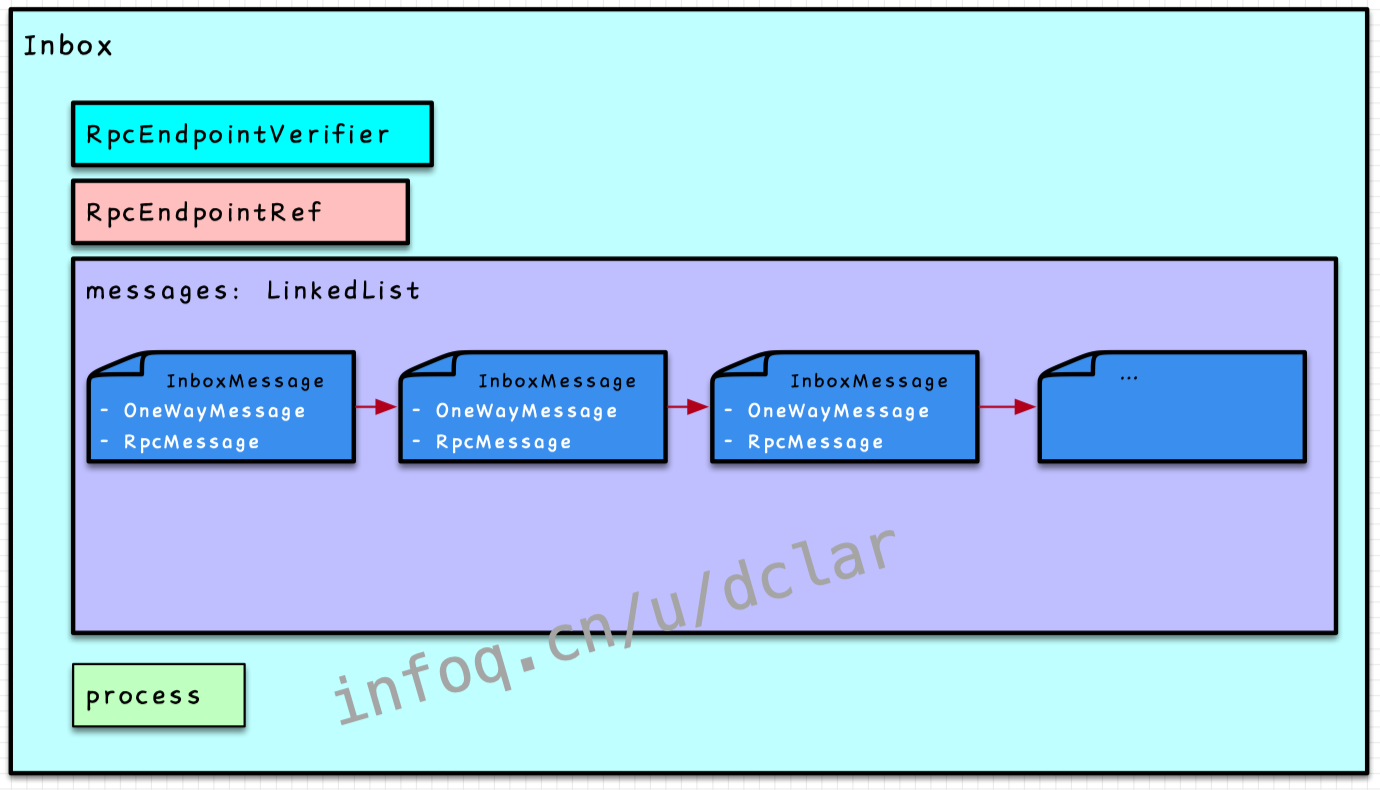
Inbox
Inbox是存储器+执行引擎
存储器:messages
这是一个串联类型的,类型就是我们前面经常见到的和的
执行引擎:process方法
执行引擎的作用就是利用中的的实例去一条条的执行中的每一个。过程是一个生产者消费者的过程,类似一个MQ。
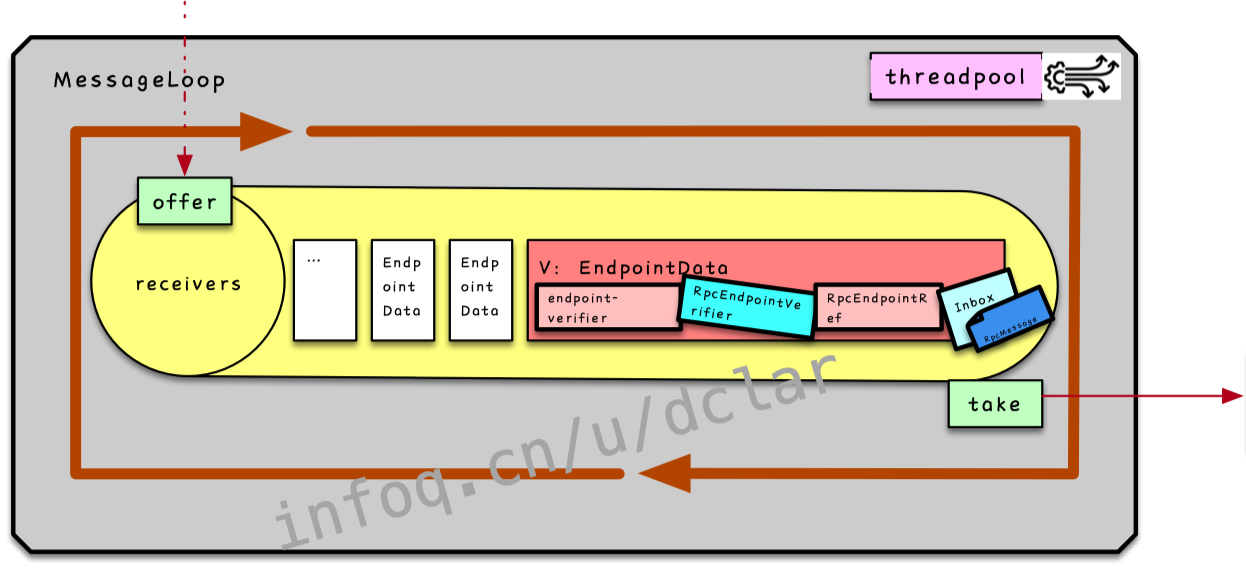
Dispatcher中的MessageLoop
说完上面的的执行引擎,再来说说中的,其实和中的执行过程如出一辙,只是,这个过程是一个线程池异步不断执行的过程
/** Thread pool used for dispatching messages. */
private val threadpool: ThreadPoolExecutor = {
val availableCores =
if (numUsableCores > 0) numUsableCores else Runtime.getRuntime.availableProcessors()
val numThreads = nettyEnv.conf.getInt("spark.rpc.netty.dispatcher.numThreads",
math.max(2, availableCores))
val pool = ThreadUtils.newDaemonFixedThreadPool(numThreads, "dispatcher-event-loop")
for (i <- 0 until numThreads) {
pool.execute(new MessageLoop)
}
pool
}
处理过程
如图所示,一个循环,不断的入数据到中,不断的出去中的,并执行其方法
重要的数据结构
:是一个,是一个FIFO的结构,每次put都需要开辟内存,有上限(),我把它画成了一个MQ的channel的形象
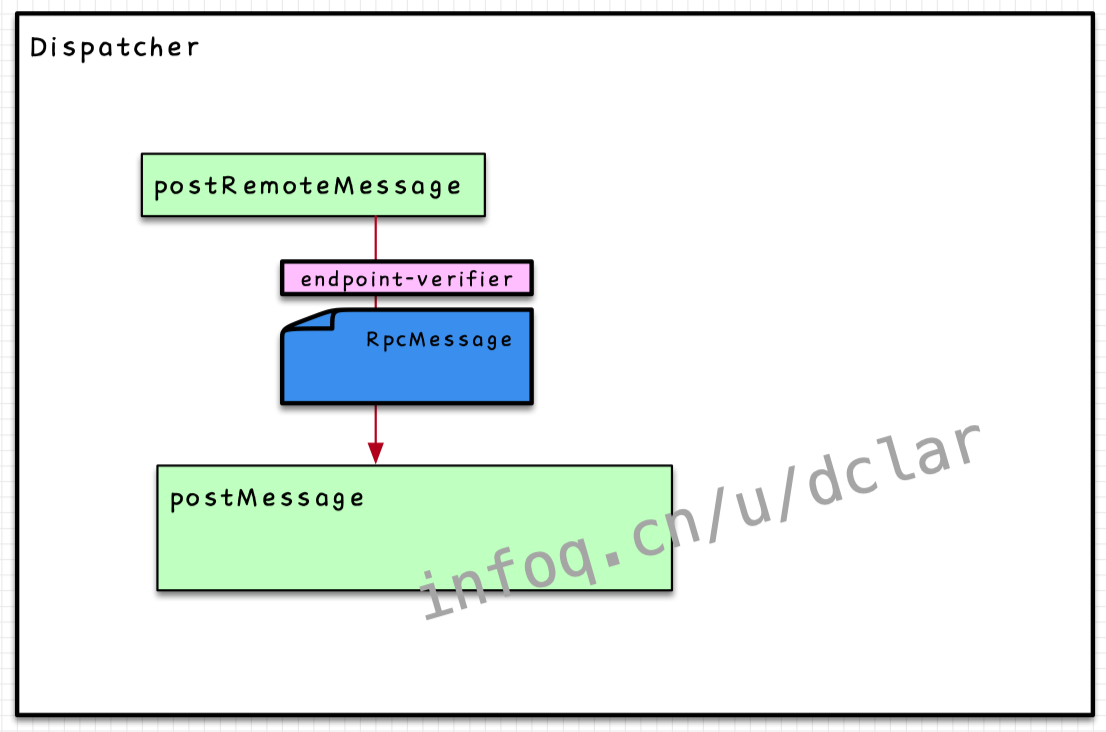
Dispatcher中的调用入口
从这张图上看出,在方法中合成了,并传递给了方法,方法间接调用到最终实例()
传递参数
在两个方法的调用中,传递了实例和的实例
串联起整个流程
根据上面的基础知识,我们可以串联起整个的细节流程
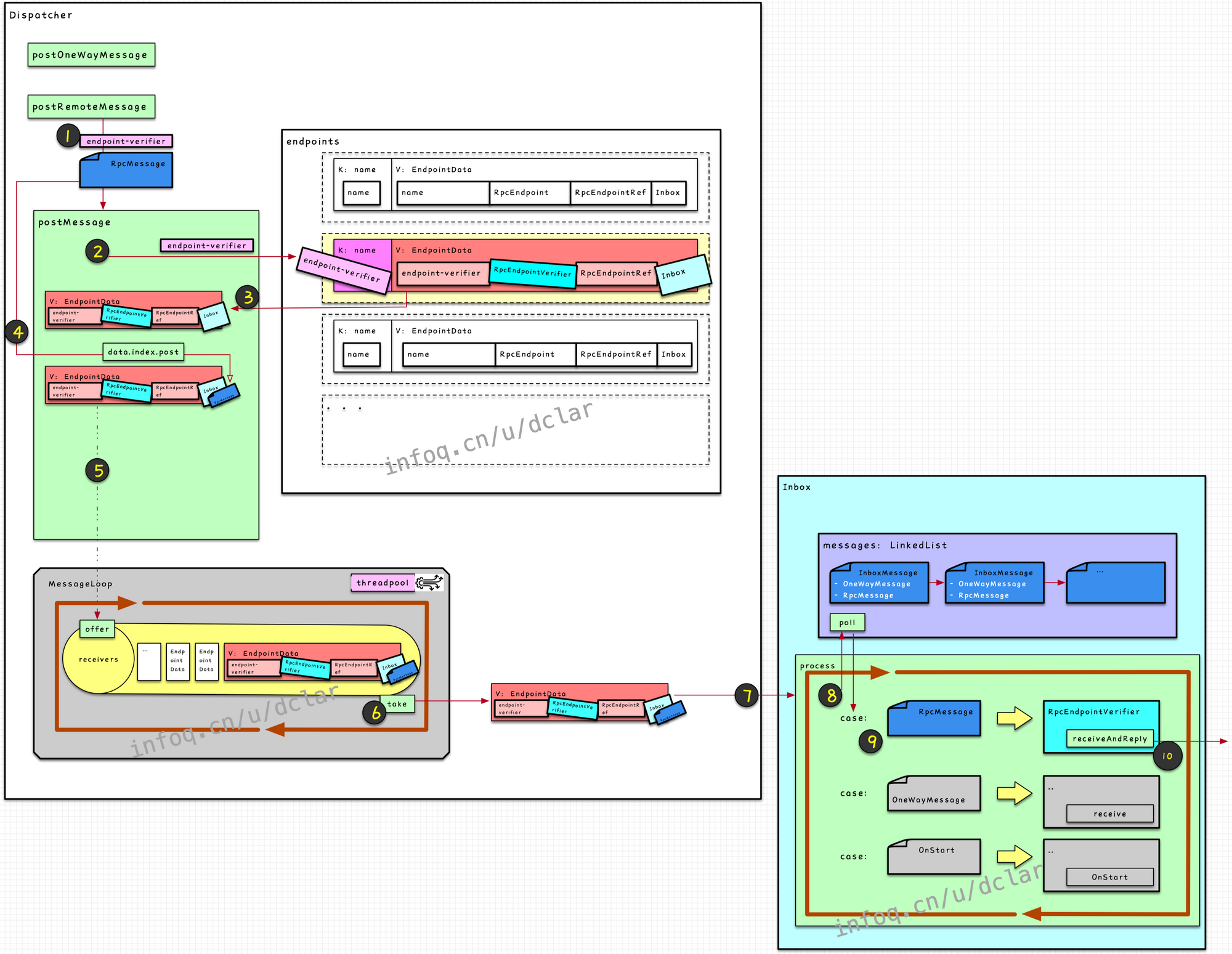
至此,一个从Dispatcher到“端”的传入+执行过程结束,但是,因为是,还存在这个的过程,这个过程,我们后续再继续聊。
总结
本篇,我们要搞明白最终如何调用到的实例,废话不多说,一副高度概括的图示来结束
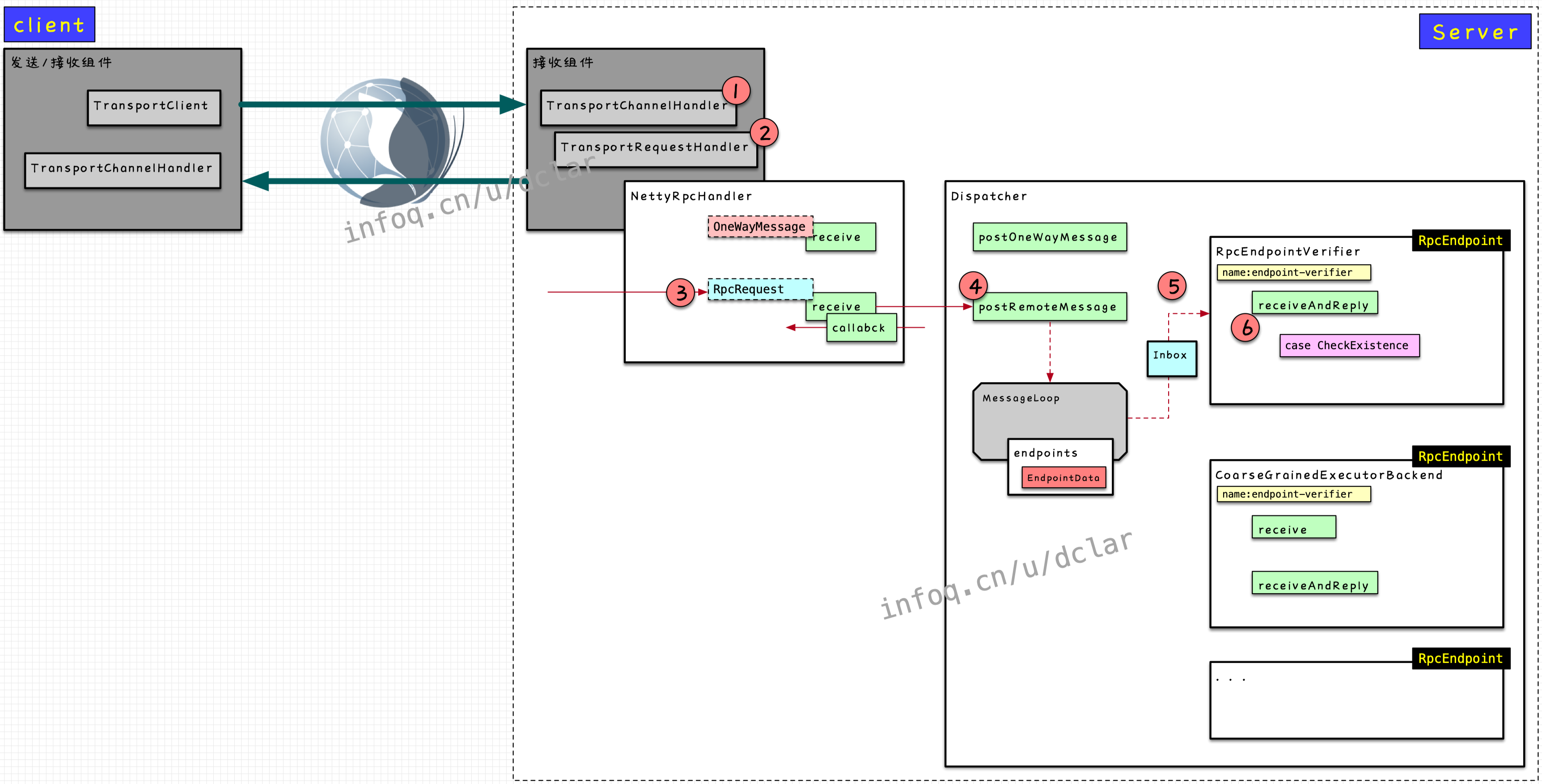
Next
下一篇,我们来看一下(也就是spark网络组件层的)的reply机制。在本篇中,我们讲述了几个数据结构,比如,肯定有小伙伴要问,它是怎么构建出来的?我们后面聊,面纱一层层的揭开,不急。