30分钟学会应用正则表达式
为什么要学习正则?
在我们开发过程,是少不了和各种数据打交道的。对于那些可以结构化的数据,我们多是用一种叫SQL的工具去检索,或者进行别的操作。那么对于相对简单的字符串,我们又有什么工具可以使用呢?其实也是有一个工具的,那就是正则表达式。
能用正则表达式干什么?
正则表达式是通过模式串与文本串的匹配来实现文本处理的各种业务功能,包括校验、切割、提取、替换等等。多用于表单的验证和敏感词的筛选,还有与爬虫相关的数据抽取。正如绝大多数流行的编程都会给SQL提供操作API,也会给正则表达式提供相应的API,因为文本处理的需求太常见了。
应该从哪开始学习正则表达式?
我不知道大家是从哪里开始学习正则表达式的,但我敢说95%的人学习路线都是舍本取末的,包括以前的我自己。也许有人觉得正则是那种需要用时就百度复制粘贴的玩意儿,但需求一变,根本无法看懂自己复制过来的正则,更别说是改了,再说了,复制粘贴过来的代码就一定是正确的吗?至少要学会怎么去阅读才行吧,可以写不出来,但一定得会看!这个十分重要。我最初也只知道一些万金油用法,比如用这种代码
正则匹配
正则匹配有分成两种类型,一类是字符匹配,另一类是位置匹配。
字符匹配
字符匹配有三个核心概念:
[]:字符集
{}:量词
():分组
正则字符匹配最重要的部分就是三对括号!如果把这三对括号都理解的话,那阅读正则基本是没任何问题的,自己也能写出一些别人看起来高大上的正则表达式。那我们正式开始吧。
[]:字符集
在字符匹配的过程中,会考量文本串中的某个字符和模式串的某个字符集中的字符是否能相匹配。
规则:
一个字符集只能匹配一个字符([abc]可以匹配a或b或c其中一个,但不能一次匹配abc)
一个字符集只有一个字符时,可以不写中括号([a]可以简写成a,也就是完全匹配)
一组编码连续的字符集可以简写([abcdef]可以简写成[a-f])
^特殊字符在中括号内的作用是取反的意思([^a-f]的意思是除了a-f以外的字符,值得强调的是[^a]和^a完全不是同一个意思)
常见的简写:
任意字符:[^\n] => . (默认匹配除换行符之外的任何单个字符)
所有数字:[0-9] => \d(所有非数字:[^0-9] => \D)
所有英文:[a-zA-Z]
所有汉字:[\u4e00-\u9fa5]
单词字符:[a-zA-Z0-9_] => \w
一般元字符(\w)的大写(\W)就是代表取反的意思
更多的特殊字符请查阅
{}:量词
量词的概念是最简单的,就是匹配的数量。一个字符集只会匹配一个字符,如果想要匹配多个字符怎么办?难道要把一个字符集复制成N个吗?当然不用,这时量词就闪亮登场了。量词前面可以是一个字符集,也可以是一个分组,但量词不能单独存在。下面以字符集为例。
规则:
[字符集]{min} :当中括号只有一个参数时表示完整匹配,[字符集]的字符一定要连续出现min次才会被匹配,连续出现min * n次时会被匹配n次
[字符集]{min, }:当中括号只有一个参数还加了逗号时,表示只要[字符集]连续出现min次以上就会匹配,而且不会截断,直到出现[字符集]以外的字符
[字符集]{min, max}:当中括号有两个参数时表示最多匹配连续max次的[字符集],最少匹配连续min次的[字符集],比如a{1,3}匹配aaaaa的时候,第一次匹配的是aaa,第二次匹配的是aa,按照max优先原则(默认贪婪模式)
常见的简写:
[字符集]{0,1} => [字符集]?
[字符集]{0, } => [字符集]*
[字符集]{1, } => [字符集]+
贪婪模式与非贪婪模式:
贪婪模式就是尽可能多地匹配字符,非贪婪模式就是尽可以少地匹配字符
任何量词默认都是贪婪模式({min,max}、*、+、?)
任何量词后面加?就是非贪婪模式({min,max}?、*?、+?、??)
??会退化成匹配所有的位置,与前面的字符集或分组无关
():分组
有[]和{}不就够了,为什么还需要有()?分组的主要作用有两点,一是把一个子表达式当成一个整体,可以为一个子表达式添加量词;二是对括号内的数据进行捕获,可以在匹配中使用在括号捕获过文本串引用。分组可以令正则表达式更加强大。
规则:
(http|ws):可以在捕获括号中使用|符号,匹配"http"或者"ws"
(?:x):匹配"x"但是不记住匹配项,这种括号叫作
非捕获括号 (abc){2}:匹配"abcabc",把abc当成一个整体看等待
(\w+)\s\1:\1是(\w+)的引用,匹配邻近两个相同单词,比如 "is is"或"cat cat"
位置匹配
起始末尾
^
$
单词边界
\b
\B
正向断言
(?= )
(?! )
反向断言
(?<= )
(?
起始末尾
规则:
^:匹配文本串的起始位置, 如果开启多行匹配,可以匹配每行的起始位置。
$:匹配文本串的末尾位置,如果开启多行匹配,可以匹配每行的末尾位置。
单词边界
规则:
\b:匹配单词边界的位置,以文本"a cat"为例,会匹配"|a| |cat|"四个位置。
\B:匹配非单词边界的位置,以文本"a cat"为例,会匹配"a c|a|t"两个位置。
JavaScript的正则表达式引擎将定义为“字”字符。不在该集合中的任何字符都被认为是一个断词。这组字符相当有限:它只包括大写和小写的罗马字母,十进制数字和下划线字符。不幸的是,重要的字符,例如所有中文字符,都被视为断词。
断言
规则:
(?=a):匹配所有右边是a的位置,以文本"a cat"为例,会匹配"|a c|at"两个位置。
(?!a):匹配所有右边不是a的位置,以文本"a cat"为例,会匹配"a| |ca|t|"四个位置。
(?<=a):匹配所有左边是a的位置,以文本"a cat"为例,会匹配"a| ca|t"两个位置。
(?
上面的a可以是一个子表达式。
应用
校验:test
前端训练营第二周作业:JavaScript数字直接量
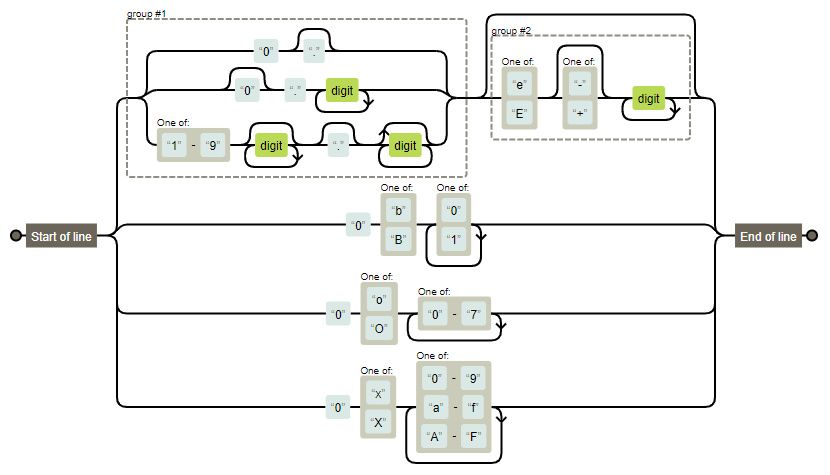
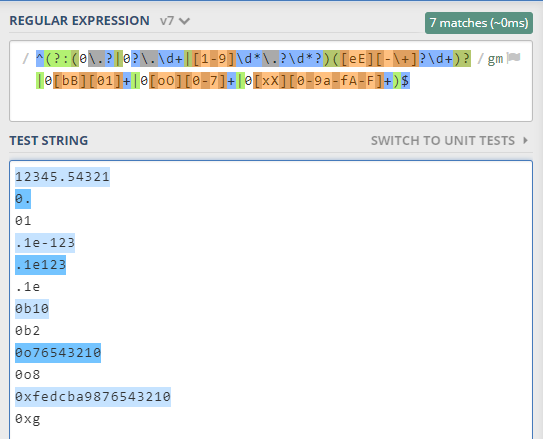
切割:split
前端训练营第六周作业:ToyBrowser-切割简单选择器
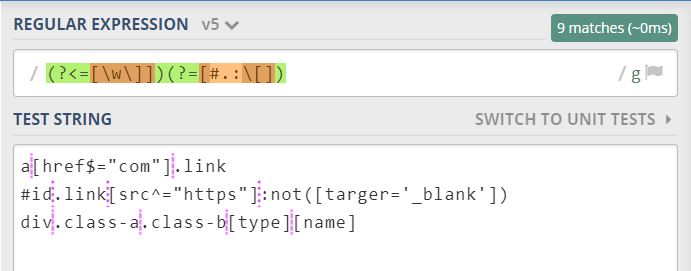
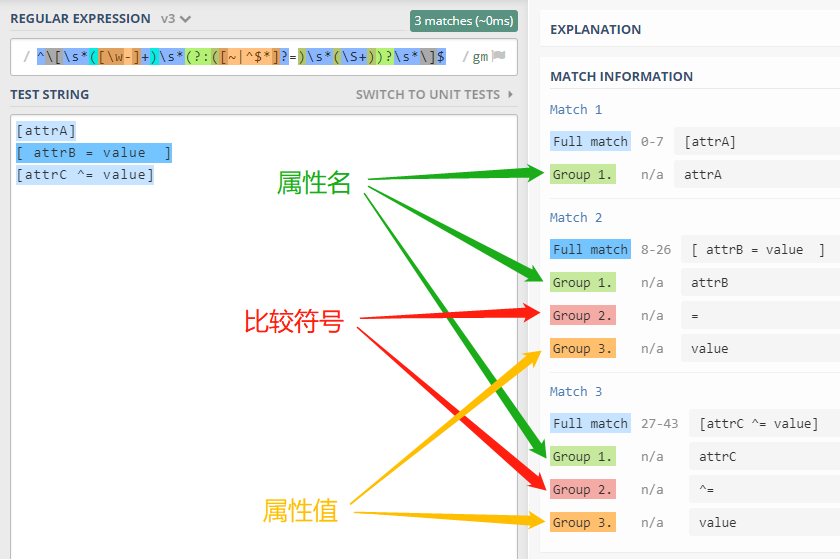
提取:match
前端训练营第八周作业:选择器匹配器-提取属性选择器的属性名,比较符号,属性值
替换:replace
前端训练营第六周作业:ToyBrowser-CSS属性转小驼峰命名
// 转驼峰命名:'flex-direction' -> 'flexDirection'
property = property.replace(/-([a-z])/g, (_, char) => char.toUpperCase())总结
由上面的例子可以看出,正则表达式在文本处理方面的应用场景非常广泛,而且是一种独立于编程语言的另一种语言,当你学习正则表达式的语法,你可以在大多数编程语言中使用它处理文本。有很多人会觉得正则表达式很难学,因为有太多需要记忆的东西了,各种元字符,各种匹配模式。其实用另一个角度去看待正则表达式,它非常单纯,干得只是处理文本的活,就只有两种匹配方式,字符匹配和位置匹配,字符匹配只有三个括号;位置匹配也就是起始末尾还有断言(单词边界比较少用),这几乎就是正则表达式的所有内容了,剩下只有练习了。下面出了一道练习题,大家不妨尝试做一下。
练习
function printf (template, params) {
// TODO
}
console.log(printf('I am ${name}', { name: 'moling' })) // I am moling