混沌工程缓存实战系列一Redis
作者:阿里巴巴|银桑
Redis 是一个开源高性能的 Key-Value 存储系统,虽然 Redis 本身具备了非常高的可用性,但是在实际应用中也会随着系统业务的复杂性以及不合理的使用,而导致很多的问题。本文将讲述如何通过混沌工程来暴露可能存在的使用风险,提升缓存问题的应急能力。
缓存重要性
Redis 是一个开源高性能的 Key-Value 存储系统,因为其极高的读写性能,丰富的数据类型,原子性的操作以及其他特性而被广泛运用。
Redis的应用场景包括且不限于以下场景:
用来做分布式缓存。
用来做分布式锁。
用来处理某些特定高并发业务,例如秒杀等。
示例架构
在实施混沌工程之前,先了解业务是如何使用 Redis 的。由于 Redis 最常用来做分布式缓存,本文以简单的商品查询场景为例,涉及的基本信息如下:
业务场景是查询商品信息,首先查询缓存;如果没有查询到,则查询数据库。
使用 Jedis 连接 Redis ,并且使用了 Jedis-pool 的技术。
Redis 是自建的集群(当然也可以使用云服务),并且使用 Sentinel 技术来提升集群的高可用性。更多信息,请参见。
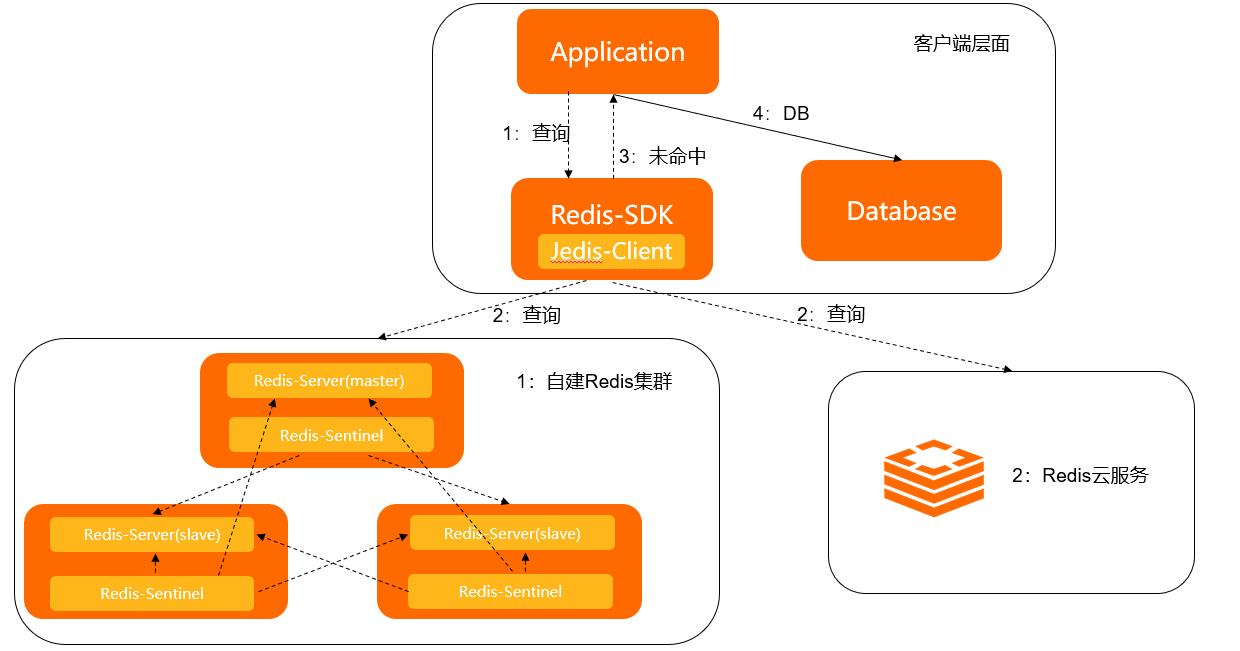
示例架构图如下:
从架构图可以看出,在Jedis配置、缓存查询、网络传输、服务端处理这条链路上,每个环节都有可能出现问题。借助混沌工程可以了解到问题发生时对系统、业务的影响面是否符合预期。
梳理演练场景
对于示例应用,可以按照以下思路来梳理演练场景:
缓存监控指标
目前支持的可监控的缓存指标如下:

影响因素
由于影响系统的因素有很多,例如机房、电源、集群服务、操作系统、应用配置等。
本文主要梳理操作系统层面和应用层面的影响因素:
系统层面的影响因素有网络、磁盘、IO、内存、CPU等因素。
应用层面的影响有超时配置、连接池配置、查询不合理等因素。
结合缓存监控指标、操作系统层面和应用层面的影响因素,本文从客户端和服务端两个角度来分析最终影响系统的因素和后果(假设业务请求QPS保持稳定)。
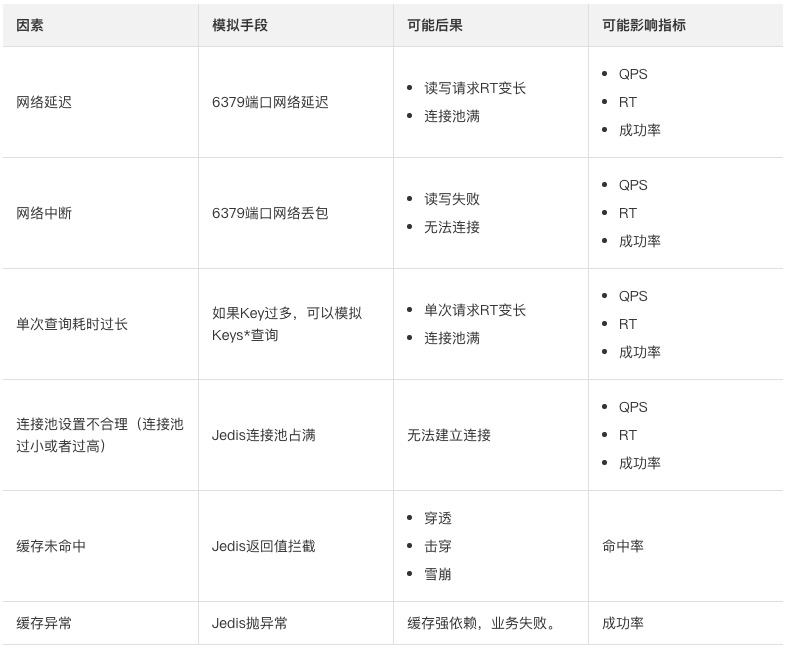
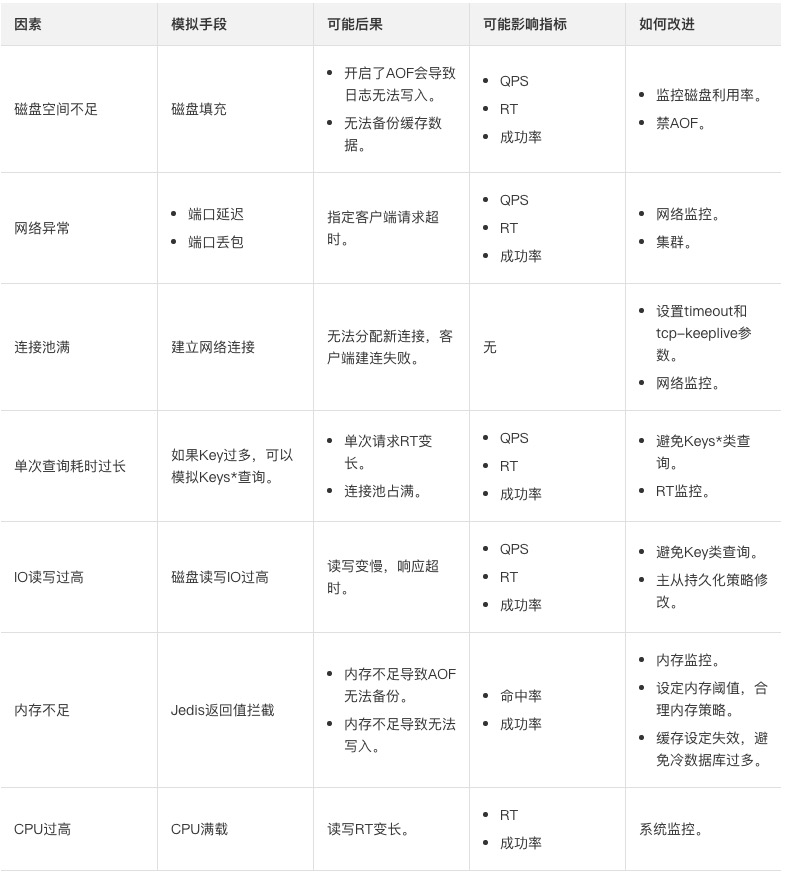
实战演练
下面通过Chaos故障演练平台从客户端层面来评测业务对Redis的合理使用。
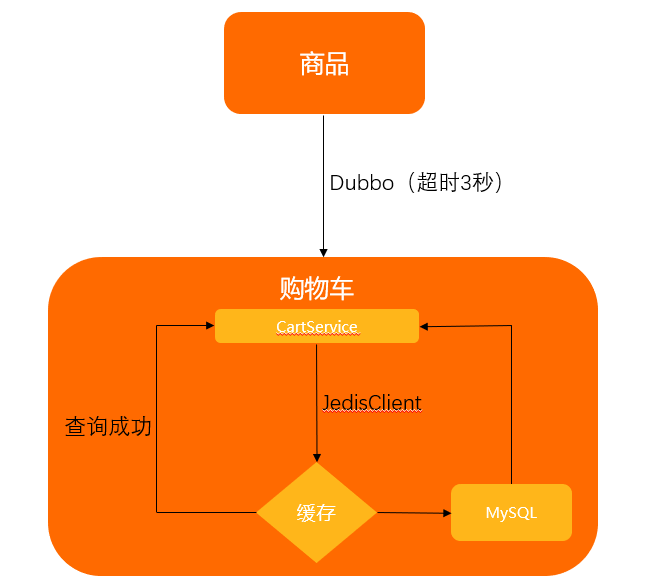
本文示例的业务场景是简单的商品购物车查询,为了便于理解,对该系统做了逻辑简化,同时为了尽可能的模拟真实情况,您可以制定相关的业务指标如下:
整个系统分为首页和购物车页面。
首页通过Dubbo来调用购物车接口,购物车服务端的接口超时设置为3000 ms。
每一次购物车的内部查询,都需要查询50次的缓存(为了更好观看演练效果,次数稍微放大),每次缓存的操作约10 ms。
购物车的内部查询优先经过缓存,失败了以后再使用数据库。
连接缓存的SDK使用Java的JedisClient,设置的超时时间为100 ms。
核心查询代码如下:
//弱依赖缓存。
@Override
public List viewCart(String userId) {
try {
for (int i = 0; i < 50; i++) {
logger.info("query redis,count:" + i);
redisRepository.getUserCartItems(userId);
}
return redisRepository.getUserCartItems(userId);
} catch (Exception exception) {
logger.error("get data from redis failed ,use local data", exception);
}
logger.info("get data from redis failed ,query from db");
return cartDBRepository.findByUserId(userId).stream().map(this::fromCart).collect(Collectors.toList());
} 相关的架构图如下:
从影响因素里可以看到影响Redis使用稳定性有很多原因,这里挑选一个场景:评测网络延迟对Redis使用的影响,来观察RT变化之后业务能否继续保持正常服务。基于网络延迟这个场景,可以提出这样的假设
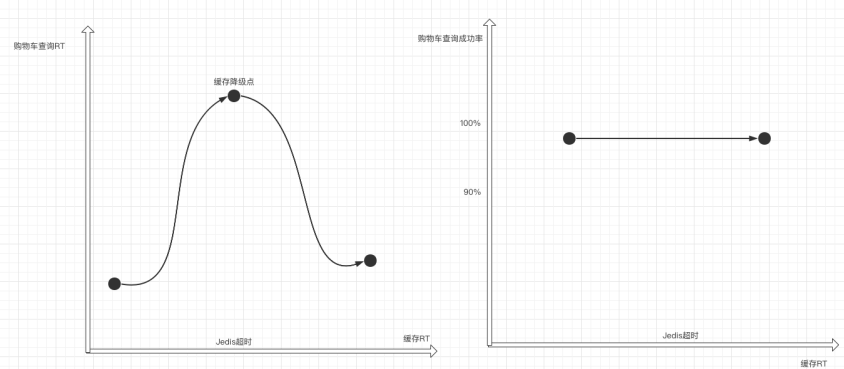
缓存的RT变化不应该影响到购物车查询的成功率。
由于缓存RT的增加导致购物车查询RT会先增加,接着缓存RT增加到一定的值使得缓存彻底无法访问,此时会触发缓存降级,购物车会查询数据库,这样又会使得查询RT回落。
虽然RT变化了,但是因为操作了强弱依赖治理,购物车查询成功率不会有很明显的变化。
针对上面的假设结合系统特征,可以设计出以下的演练场景:
Redis延迟增加20 ms,缓存累计耗时50*20=1000 ms,此时CartServiceRT小于配置的接口超时3000 ms,业务正常。
Redis延迟增加80 ms,缓存累计耗时50*80=4000 ms,购物车内部查询继续,但此时CartServiceRT大于配置的接口超时3000 ms,购物车查询失败。
Redis延迟增加10000 ms,此时缓存超出了Jedis的超时配置时间100 ms,使得查询缓存故障,导致查询路径切换至数据库,此时业务正常。
通过阿里云Chaos演练平台可以快速的配置以上的演练场景,并且结合平台提供的业务探活功能,可以快速实现整个故障演练的自动化评测。通过以上的演练证明了以下几点:

(2)创建演练场景。
本示例创建网络延迟的故障场景。
在我的空间页面,单击新建演练。
在新建演练对话框,选择从空白创建。
(3)增加业务探活的节点。
由于要观测演练前和故障注入后系统的业务情况,因此除了故障注入节点之外,还需要增加业务探活的节点。故障演练提供了类似K8s的探活功能,可以通过访问指定接口来判断业务是否可用。参数配置说明如下:
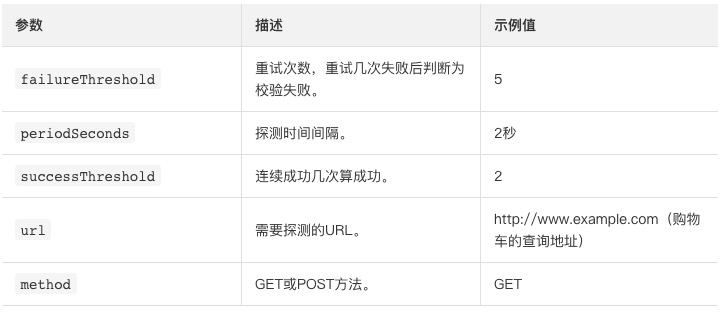

注意在演练前需要确保业务系统处于正常状态,所以在故障注入前需要判断下应用是否可用。
配置完毕之后,可以发起自动演练、自动探测,最终得出结论(故障演练支持演练节点自动推进,也支持手动一步步推进)。

(5)验证结果。
从演练执行结果可以看出,最终的运行结果和假设一致,当延迟注入80 ms之后,购物车不可用。但当延迟注入20 ms和10000 ms时候,虽然购物车可用,但还需要进一步验证是否如预期:一个是RT延长但是接口未超时,一个是缓存降级导致的业务成功。
可以通过单击校验购物车是否可用的节点来查看业务成功的原因:
a、查看演练开始的探活节点,单击购物车校验是否可用,查看探活记录。发现查询RT处于正常范围内。

b、查看注入20 ms之后的探活节点。发现业务RT明显增长,但是还是在超时的3秒内,因此业务正常。

c、查看注入80 ms之后的探活节点,发现业务异常。

d、查看注入10000 ms之后的探活节点,发现RT回落,此时业务正常。
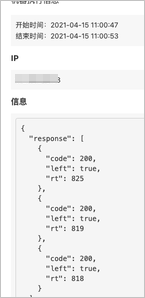
说明 但RT相比正常值还是有所延长。这是由于缓存出现故障,导致购物车查询缓存失败,此时购物车则需再去查询数据库。这个查询路径切换的过程导致RT相较于正常值有所延长。
通过以上的演练证明了以下几点:
缓存RT轻微增长,对业务影响可控。但是如果业务内部存在多次的缓存查询,会导致整体RT增加明显,就像本示例RT延长处于客户端连接超时范围内,无法触发弱依赖降低,但是整个接口RT超时,最终导致业务受损。
在缓存RT增长很明显的情况下,缓存降级策略能够正常生效,使得业务正常访问。当然在实际情况中,这种兜底策略可能导致数据库直接崩溃。
演练价值
通过对不同网络延迟的演练,可以了解到缓存RT变化对系统造成的影响,以及防护策略有效性。随着业务规模的不断增长,这个简单的业务系统也会面临新的问题:
在某次重构中,又新增加了缓存查询,结果导致20 ms的延迟使得接口整体超时。
业务逻辑简单的时候,能够很好的分析强弱依赖。但是随着微服务的膨胀,以及代码多次重构,可能原有的弱依赖在某次变更中变成了强依赖,这种通过功能测试是无法发现的。
本示例Jedis设置的超时时间是100 ms,不同业务对RT的要求不同,您可以根据实际情况设置合理的超时时间。
上述的一些问题都要通过故障演练来发现。在日常的发布、架构升级中除了功能测试、性能测试的回归,还需要进行常态化的故障演练,同时演练的形态和场景复杂性也要不断扩充。对于故障演练来说,难的不是注入手段,而是对业务架构、业务场景的理解。故障注入不是目的,演练的目的是加深对系统的理解,这样当真实的问题来临时候,才能更加有信心的去处理。