MongoDB的几个常见问题
一 背景
最近在整理过去的项目经历,其中有两个项目都是用了mongoDB作为存储引擎。对于mongoDB,大家可能多少有一些了解,例如知道是文档数据库,不太适合多表关联查询,事务支持较弱等等。同时,也知道mongoDB也有它的适用场景,以及它使用的是B树索引,这与Mysql的B+树索引之间的区别也是面试中经常考察的问题之一。
二 为什么会使用MongoDB?
MongoDB 的设计目标是高性能、可扩展、易部署、易使用,存储数据非常方便。
2.1 常用数据库
业务中的存储引擎,除了传统行业(例如银行等)会更倾向于Oracle、SQL Server、DB2等商业数据库之外,Mysql、MongoDB、PostgreSQL可能是使用最多的几种。另外HBase在空间数据和某些其他的场景也是常用的存储方案。
2.2 使用mongoDB原因
mongoDB的主要优势:MongoDB 的主要目标是在键/值存储方式(提供了高性能和高度伸缩性)和传统的RDBMS 系统(具有丰富的功能)之间架起一座桥梁,它集两者的优势于一身。
回归我们的业务,使用mongoDB往往有以下几个原因:
2.2.1 文档型数据库在业务早期的变更优势
业务早期,表、字段变更非常频繁,如果使用mysql等传统关系型数据库,频繁的建表、修改表、增加、减少、调整字段类型这些操作就会消耗不少精力。mongoDB作为文档型数据库,其存储的数据更接近于JSON,我们只需要维护对象-JSON关系即可,增减字段非常方便。另外,建表(mongoDB中是集合-collection)也可以直接在业务使用中自动创建,而不必一定事先建表。这在需要按日期分表时会非常容易。
2.2.2 性能优势
mongoDB优秀的读写性能。尤其是写多读少的场景(当然,这里的“写多”指的是万级的写入qps)。
2.3 mongoDB局限
不过也必须清楚地知道,mongoDB的使用局限:
2.3.1 事务支持较弱
高度事务性的系统不适合使用mongoDB。例如,银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。
2.3.2 较多实时统计的业务场景
尽管mongoDB提供了类似map-reduce的统计方案,但效率并不高。所以例如传统的商业智能应用,针对特定问题的BI数据库会产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。
三 mongoDB的分片集群
分片机器——Sharded Cluster,是mongoDB通过横向扩展,来提高数据吞吐性能、增大数据存储量的集群部署模式。
3.1 组成结构
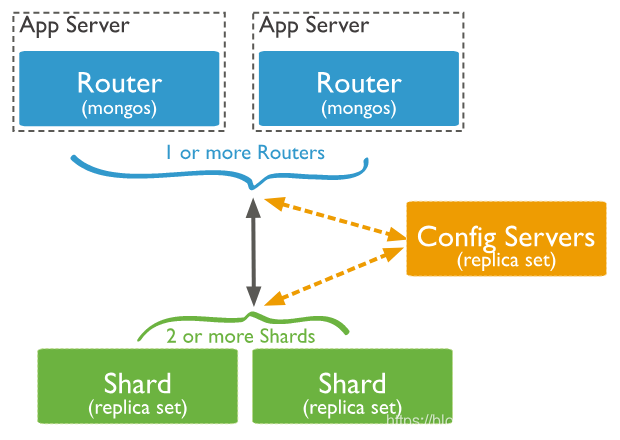
包括三个组件:mongos, config server,shard。
1)mongos:数据库请求路由。负责接收所有客户端应用程序的连接查询请求,并将请求路由到集群内部对应的分片上。"mongos"可以有1个或多个。
2)config server: 配置服务,负责保存集群的元数据信息,比如集群的分片信息、用户信息。
MongoDB 3.4 版本以后,“config server” 必须是副本集!
3)shard: 分片存储。将数据分片存储在多个服务器上。
有点类似关系数据库"分区表"的概念,只不过分区表是将数据分散存储在多个文件中,而sharding将数据分散存储在多个服务器上。一个集群可以有一个或多个分片。
MongoDB 3.6以后,每个分片都必须是副本集!