使用MLlib进行机器学习(十-上)
写在前面:
大家好,我是强哥,一个热爱分享的技术狂。目前已有 12 年大数据与 AI 相关项目经验, 10 年推荐系统研究及实践经验。平时喜欢读书、暴走和写作。
业余时间专注于输出大数据、AI 等相关文章,目前已经输出了 40 万字的推荐系统系列精品文章,今年 6 月底会出版「构建企业级推荐系统:算法、工程实现与案例分析」一书。如果这些文章能够帮助你快速入门,实现职场升职加薪,我将不胜欢喜。
想要获得更多免费学习资料或内推信息,一定要看到文章最后喔。
内推信息
如果你正在看相关的招聘信息,请加我微信:liuq4360,我这里有很多内推资源等着你,欢迎投递简历。
免费学习资料
如果你想获得更多免费的学习资料,请关注同名公众号【数据与智能】,输入“资料”即可!
学习交流群
如果你想找到组织,和大家一起学习成长,交流经验,也可以加入我们的学习成长群。群里有老司机带你飞,另有小哥哥、小姐姐等你来勾搭!加小姐姐微信:epsila,她会带你入群。
到目前为止,我们一直专注于Apache Spark的数据工程工作负载。数据工程通常是为机器学习(ML)任务准备数据的前期步骤,而机器学习将是本章的重点。我们生活在一个机器学习和人工智能应用普及的时代。不管我们是否意识到这一点,每天我们都有可能会出于各种目的(例如在线购物推荐和广告,欺诈检测,分类,图像识别,模式匹配等)接触ML模型。这些ML模型为许多公司制定了重要的业务决策。根据麦肯锡的这项研究,其中35%的消费者在Amazon购买的商品和75%的Netflix购买的商品受到基于机器学习的产品推荐的推动。建立一个表现良好的模型可以决定公司的成败。
在本章中,我们将帮助你开始使用MLlib(Apache Spark中的核心组件中的机器学习库)来构建ML模型。我们将从机器学习的简要介绍开始,然后涵盖大规模ML和功能设计的最佳实践(如果你已经熟悉机器学习的基础知识,则可以直接跳至“设计机器学习管道”)。通过此处提供的简短代码段以及该书的GitHub仓库中提供的笔记(notebook),你将学习如何构建基本的ML模型和使用MLlib。
本章介绍了Scala和Python API。如果你有兴趣在Spark 中使用R语言(sparklyr)进行机器学习,我们建议你查看Javier Luraschi,Kevin Kuo和Edgar Ruiz(O'Reilly)的著作《Mastering Spark with R》。
什么是机器学习?
如今,机器学习正在大肆宣传,但是它到底是什么呢?广义上讲,机器学习是一个使用统计,线性代数和数值优化从数据中抽取模式的过程。机器学习可以应用于诸如预测功耗,确定视频中是否有猫,或将具有类似特征的项目聚类的问题。
机器学习有几种类型,包括监督、半监督、无监督和强化学习。本章将主要关注有监督的机器学习,而仅涉及无监督的学习。在深入探讨之前,让我们简要讨论有监督和无监督机器学习之间的区别。
监督学习
在有监督的机器学习中,你的数据由一组输入记录组成,每个输入记录都具有关联的标签,并且目标是在给定新的无标签输入的情况下预测输出标签。这些输出标签可以是
在分类问题中,目标是将输入分为一组离散的类或标签。对于

使用

在回归问题中,要预测的值是连续数字,而不是标签。这意味着你可能会预测模型在训练期间未看到的值,如图10-3所示。例如,你可以构建一个模型来预测在给定温度下的每日冰淇淋销量。你的模型可能得到会预测值$ 77.67,即使训练数据中没有包含该值的输入/输出对。
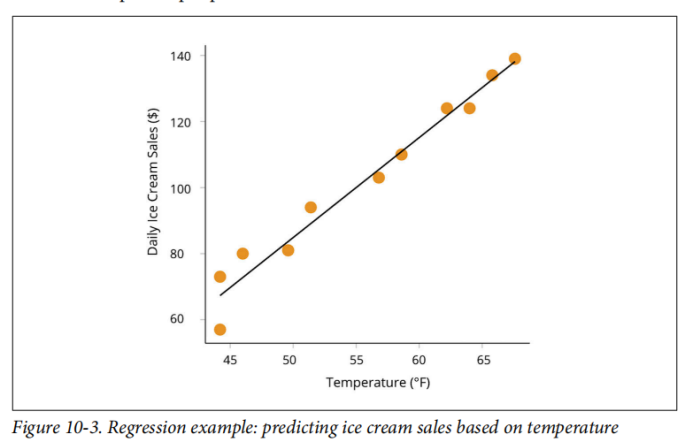
下面的表10-1列出了Spark MLlib中可用的一些常用的监督ML算法,并注明了它们是否可用于回归,分类或同时用于回归和分类。

无监督学习
获得监督式机器学习所需的标记数据可能需要付出昂贵的代价甚至有时候是不可行的。这就是无监督机器学习发挥作用的地方。无需预测标签,无监督的机器学习可以帮助你更好地理解数据的结构。
例如,请观察图10-4左侧的原始非聚类数据。对于每个数据点(
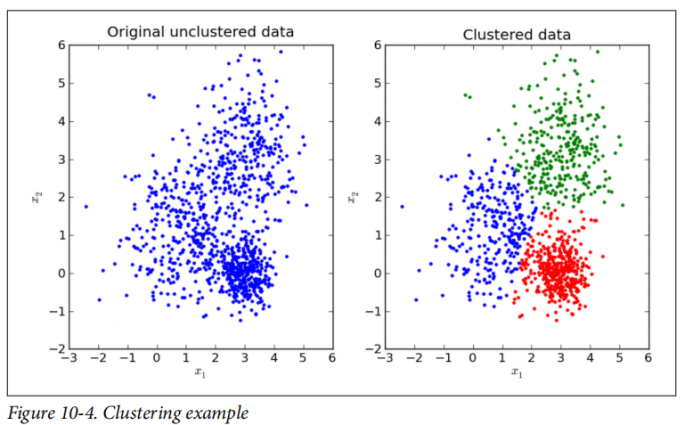
无监督机器学习可用于异常值检测或用作监督机器学习的预处理步骤,例如,减少数据集的维数(即每个样本点的维数),这对于减少存储需求或简化下游操作很有用。MLlib中的一些无监督机器学习算法包括
为什么使用Spark进行机器学习?
Spark是一个统一的分析引擎,为数据摄取,工程设计,模型训练和部署提供了一个生态系统。如果没有Spark,开发人员将需要许多不同的工具来完成这组任务,并且可能仍难以应对可伸缩性的问题。
Spark有两个机器学习包:spark.mllib和spark.ml。spark.mllib是基于RDD API(从Spark 2.0开始处于维护模式)的原始机器学习API,而spark.ml是基于DataFrames的较新API。本章的其余部分将重点介绍spark.ml如何使用该软件包以及如何在Spark中设计机器学习管道。但是,我们使用“ MLlib”作为总称来指代Apache Spark中的两个机器学习库包。
使用spark.ml,数据科学家可以在同一个生态系统中进行数据准备和模型构建,而无需对数据进行下采样以使其适合一台计算机。spark.ml着重于O(n)向外扩展,其中模型随你拥有的数据点数线性扩展,因此可以扩展至大量的数据。在下一章中,我们将讨论在诸如的分布式框架spark.ml和scikit-learn(sklearn)的单节点框架之间进行选择时需要进行的一些权衡。如果你以前使用过scikit-learn,很多spark.ml API都会感觉很熟悉,但是也会存在一些细微的差异,下面我们将进行讨论。
设计机器学习管道
在本节中,我们将介绍如何创建和调整机器学习管道。管道的概念在许多机器学习框架中很常见,是一种组织一系列操作以应用于你的数据的方式。在MLlib中,管道API提供了一个基于DataFrames的高级API,用来组织你的机器学习工作流程。Pipeline API由一系列转换器和预估器组成,我们将在后面详细讨论。
在本章中,我们将使用Inside Airbnb提供的旧金山住房数据集。它包含有关Airbnb在旧金山的租金的信息,例如卧室数量,位置,评论评分等,我们的目标是建立一个模型来预测该城市房源的每晚租金价格。这是一个回归问题,因为价格是一个连续变量。我们将指导你完成数据科学家用来解决此问题的工作流程,包括特征工程,构建模型,超参数调整和评估模型质量。该数据集非常混乱,并且可能很难建模(就像大多数现实世界中的数据集一样!),因此,如果你自己进行实验,则如果早期的模型不好,也不需要感到焦虑。
本章的目的不是向你展示MLlib中的每个API,而是让你掌握使用MLlib来构建端到端管道的技能和知识。在详细介绍之前,让我们定义一些MLlib术语:
转换器(
接受一个DataFrame作为输入,并返回一个新的DataFrame并追加一个或多个列。转换器无法从你的数据中学习任何参数,而只是应用基于规则的转换来准备用于模型训练的数据,或使用经过训练的MLlib模型生成预测。他们有一个 .transform() 方法。
预估器(Estimator)
通过.fit() 方法从你的DataFrame中读取(或“拟合”)参数,并返回一个模型 ,这个模型是一个转换器。
管道(pipeline)
将一系列转换器和预估器组织到一个模型中。管道本身是预估器,而pipeline.fit()方法返回的输出是一个 PipelineModel,是一个转换器。
尽管这些概念现在看起来似乎还很抽象,但是本章中的代码段和示例将帮助你理解它们是如何组合在一起的。但是,在构建机器学习模型并使用转换器,预估器和管道之前,我们需要加载数据并执行一些数据准备。
数据提取与研究
我们对示例数据集中的数据进行了稍微的预处理,以删除异常值(例如,发布价为$ 0 / night的Airbnb),将所有整数都转换为双精度,并选择了一百多个字段中的信息量很大的子集。此外,对于数据列中所有缺失的数值,我们估算了中位数并添加了一个指标列(列名后跟_na,例如bedrooms_na)。这样,ML模型或人工分析人员就可以将该列中的任何值解释为推定值,而不是真实值。你可以在本书的GitHub repo中看到数据准备笔记。请注意,还有许多其他方法可以处理缺失值,对于那些方法本书不做介绍。
让我们快速浏览一下数据集和相应的数据结构(输出仅显示列的子集):
In Python
filePath = """/databricks-datasets/learning-spark-v2/sf-airbnb/
sf-airbnb-clean.parquet/"""
airbnbDF = spark.read.parquet(filePath)
airbnbDF.select("neighbourhood_cleansed", "room_type", "bedrooms", "bathrooms",
"number_of_reviews", "price").show(5)
// In Scala
val filePath =
"/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquet/"
val airbnbDF = spark.read.parquet(filePath)
airbnbDF.select("neighbourhood_cleansed", "room_type", "bedrooms", "bathrooms",
"number_of_reviews", "price").show(5)
+----------------------+---------------+--------+---------+--------
|neighbourhood_cleansed|room_type|bedrooms|bathrooms|number_...|price|
+----------------------+---------------+--------+---------+----------
| Western Addition|Entire home/apt| 1.0| 1.0| 180.0|170.0|
| Bernal Heights |Entire home/apt| 2.0| 1.0| 111.0|235.0|
| Haight Ashbury | Private room | 1.0| 4.0| 17.0 | 65.0|
| Haight Ashbury | Private room | 1.0| 4.0| 8.0 | 65.0|
| Western Addition|Entire home/apt| 2.0| 1.5| 27.0 |785.0|
+----------------------+---------------+--------+---------+--------
鉴于我们的功能,我们的目标是预测租赁物业每晚的价格。
在数据科学家可以进行模型构建之前,他们需要探索和理解他们的数据。他们通常会使用Spark对数据进行分组,然后使用数据可视化库(例如matplotlib)来可视化数据。我们将把数据探索作为练习留给读者。
创建训练和测试数据集
在开始进行特征工程和建模之前,我们将数据集分为两组:
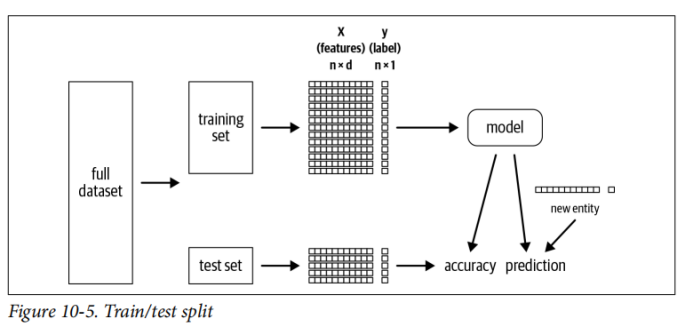
我们的训练集由一组特征X和一个标签y组成。在这里,我们用大写字母X表示尺寸为
使用不同的度量标准来衡量模型的效果。对于分类问题,标准度量是正确预测的
对于我们的Airbnb数据集,我们将保留80%的数据作为训练集,并保留20%的数据用于测试集。此外,我们将为数据可重复性设置一个随机种子,这样,如果我们重新运行此代码,我们可能分别在训练数据集和测试数据集中生成重复的数据。种子本身的价值
的答案:
In Python
trainDF, testDF = airbnbDF.randomSplit([.8, .2], seed=42)
print(f"""There are {trainDF.count()} rows in the training set,
and {testDF.count()} in the test set""")
// In Scala
val Array(trainDF, testDF) = airbnbDF.randomSplit(Array(.8, .2), seed=42)
println(f"""There are ${trainDF.count} rows in the training set, and
${testDF.count} in the test set""")
这将产生以下输出:
训练集中有5780行,测试集中有1366行
但是,如果我们更改Spark集群中执行程序(Executor)的数量会怎样?Catalyst优化器根据群集资源和数据集的大小确定最佳的数据分区方法。假设Spark DataFrame中的数据是按行分区的,并且每个工作节点都独立于其他工作节点执行拆分,如果分区中的数据发生更改,则拆分结果(by random Split())将不相同。
虽然你可以修复集群配置和随机种子以确保获得一致的结果,但是我们建议你一次性拆分数据,然后将其写到其自己的训练/ 测试文件夹中,这样就不会出现这些可重复性问题。
在探索性分析期间,你应该缓存训练数据集,因为你将在整个机器学习过程中多次访问它。请参考上一节“缓存和数据的持久性”的第七章。
使用转换器准备特征
现在,我们已将数据分为训练集和测试集,让我们准备数据以建立一个线性回归模型,该模型可以在给定卧室数量的情况下预测价格。在后面的示例中,我们将包括所有相关特征,但是现在让我们确保已具备相应的机制。线性回归(与Spark中的许多其他算法一样)要求所有输入特征都包含在DataFrame中的单个向量内。因此,我们需要
Spark中的转换器接受一个DataFrame作为输入,并返回一个新DataFrame并追加一个或多个列。他们不会从你的数据中学习,而是使用该transform()方法应用基于规则的转换。
为了将我们所有的特征放到一个向量中,我们将使用VectorAssembler Transformer。VectorAssembler接受一个输入列的列表,并创建一个带有追加列的新DataFrame,我们将其称为特征(features)。它将这些输入列的值组合到一个向量中:
In Python
from pyspark.ml.feature import VectorAssembler
vecAssembler = VectorAssembler(inputCols=["bedrooms"], outputCol="features")
vecTrainDF = vecAssembler.transform(trainDF)
vecTrainDF.select("bedrooms", "features", "price").show(10)
// In Scala
import org.apache.spark.ml.feature.VectorAssembler
val vecAssembler = new VectorAssembler()
.setInputCols(Array("bedrooms"))
.setOutputCol("features")
val vecTrainDF = vecAssembler.transform(trainDF)
vecTrainDF.select("bedrooms", "features", "price").show(10)
+--------+--------+-----+
|bedrooms|features|price|
+--------+--------+-----+
| 1.0| [1.0]|200.0|
| 1.0| [1.0]|130.0|
| 1.0| [1.0]| 95.0|
| 1.0| [1.0]|250.0|
| 3.0| [3.0]|250.0|
| 1.0| [1.0]|115.0|
| 1.0| [1.0]|105.0|
| 1.0| [1.0]| 86.0|
| 1.0| [1.0]|100.0|
| 2.0| [2.0]|220.0|
+--------+--------+-----+
你会注意到,在Scala代码中,我们必须实例化新VectorAssembler对象以及使用setter方法更改输入和输出列。在Python中,你可以选择将参数直接传递给的构造函数VectorAssembler或使用setter方法,但是在Scala中,你只能使用setter方法。
接下来我们将介绍线性回归的基础知识,但是如果你已经熟悉算法,请跳至“使用预估器来构建模型”。
了解线性回归
线性回归建模因变量(或标签)与一个或多个自变量(或特征)之间的线性关系。在我们的案例中,我们希望拟合线性回归模型来预测在给定卧室数量的情况下Airbnb租金的价格。
在图10-6中,我们有一个特征
这些点表示来自我们的数据集中真实的(
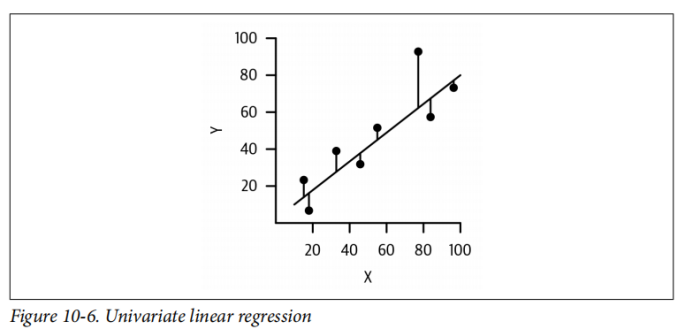
线性回归还可以扩展为处理多个自变量。如果我们有三个特征作为输入,x = [x1 , x2 , x3 ],那么我们就可以建模y作为y ≈ w0 + w1x1 + w2x2 + w3x3 + ε.。在这种情况下,每个特征都有一个单独的系数(或权重)和一个截距(这里是
使用预估器建立模型
设置完vectorAssembler之后,我们准备好数据并将其转换为线性回归模型期望的格式。在Spark中,LinearRegression是一种预估器——接受DataFrame并返回模型。预估器从你的数据中学习参数,有一个estimator_name.fit()方法,并进行急切的评估计算(即,启动Spark作业),而对转换器的评估则比较滞后。其他一些估计器的例子包括输入器、决策树分类器和随机森林回归器。
你会注意到,线性回归(特征)的输入列是我们vectorAssembler的输出:
In Python
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(featuresCol="features", labelCol="price")
lrModel = lr.fit(vecTrainDF)
// In Scala
import org.apache.spark.ml.regression.LinearRegression
val lr = new LinearRegression()
.setFeaturesCol("features")
.setLabelCol("price")
val lrModel = lr.fit(vecTrainDF)
lr.fit()返回LinearRegressionModel(lrModel),它是一个转换器。换句话说,预估器fit()方法的输出是一个转换器。一旦预估器了解了参数,转换器就可以将这些参数应用于新的数据点以生成预测。让我们检查一下它学到的参数:
In Python
m = round(lrModel.coefficients[0], 2)
b = round(lrModel.intercept, 2)
print(f"""The formula for the linear regression line is
price = {m}*bedrooms + {b}""")
// In Scala
val m = lrModel.coefficients(0)
val b = lrModel.intercept
println(f"""The formula for the linear regression line is
price = $m%1.2f*bedrooms + $b%1.2f""")
打印:
线性回归线的公式为:价格= 123.68 *卧室数量+ 47.51
创建管道
如果我们想将模型应用于测试集,则需要以与训练集相同的方式来准备数据(即,将其通过向量装配器传递)。通常,数据准备管道会包含多个步骤,并且不仅要记住要应用哪些步骤,而且要记住这些步骤的顺序也变得很麻烦。这是Pipeline API的动机:你只需按顺序指定希望数据通过的阶段,Spark会为你处理。它们为用户提供了更好的代码可重用性和组织性。在Spark中,Pipelines是预估器,而PipelineModels(拟合的Pipelines)是转换器。
让我们现在构建管道:
In Python
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[vecAssembler, lr])
pipelineModel = pipeline.fit(trainDF)
// In Scala
import org.apache.spark.ml.Pipeline
val pipeline = new Pipeline().setStages(Array(vecAssembler, lr))
val pipelineModel = pipeline.fit(trainDF)
使用Pipeline API的另一个好处是,它可以确定哪些阶段是你的预估器/转换器,因此你不必担心为每个阶段指定name.fit()与相对name.transform()。
由于pipelineModel是转换器,因此也很容易将其应用于我们的测试数据集:
In Python
predDF = pipelineModel.transform(testDF)
predDF.select("bedrooms", "features", "price", "prediction").show(10)
// In Scala
val predDF = pipelineModel.transform(testDF)
predDF.select("bedrooms", "features", "price", "prediction").show(10)
+--------+--------+------+------------------+
|bedrooms|features| price| prediction|
+--------+--------+------+------------------+
| 1.0| [1.0]| 85.0|171.18598011578285|
| 1.0| [1.0]| 45.0|171.18598011578285|
| 1.0| [1.0]| 70.0|171.18598011578285|
| 1.0| [1.0]| 128.0|171.18598011578285|
| 1.0| [1.0]| 159.0|171.18598011578285|
| 2.0| [2.0]| 250.0|294.86172649777757|
| 1.0| [1.0]| 99.0|171.18598011578285|
| 1.0| [1.0]| 95.0|171.18598011578285|
| 1.0| [1.0]| 100.0|171.18598011578285|
| 1.0| [1.0]|2010.0|171.18598011578285|
+--------+--------+------+------------------+
在这段代码中,我们仅使用一个功能就构建了一个bedrooms模型(你可以在本书的GitHub repo中找到本章的笔记本)。但是,你可能希望使用所有特征来构建模型,其中某些特征可能是类别特征,例如host_is_superhost。类别特征采用离散值,没有内在顺序——例如,职业或国家/地区名称。在下一节中,我们将考虑一种解决方案,该方法用于处理这类变量,称为“独热编码
独热编码
在我们刚刚创建的管道中,我们只有两个阶段,而线性回归模型仅使用一个功能。让我们看一下如何构建一个稍微更复杂的管道,其中包含我们所有的数字和分类功能。
MLlib中的大多数机器学习模型都希望数值作为输入,以向量表示。要将分类值转换为数值,我们可以使用一种称为独热编码(简称:OHE)的技术。假设我们有一个名为列Animal,我们有三种类型的动物:Dog,Cat和Fish。我们不能将字符串类型直接传递到ML模型中,因此我们需要分配一个数字映射,例如:
Animal = {"Dog", "Cat", "Fish"}
"Dog" = 1, "Cat" = 2, "Fish" = 3
但是,使用这种方法,我们在数据集中引入了一些以前没有的虚假关系。例如,为什么我们分配Cat两倍的值Dog?我们使用的数值不应在我们的数据集中引入任何关系。相反,我们想为列中的每个不同值创建一个单独的Animal列:
"Dog" = [ 1, 0, 0]
"Cat" = [ 0, 1, 0]
"Fish" = [0, 0, 1]
如果动物是狗,则在第一列中记录为1,在其他列记录为0。如果是猫,则在第二列中记录为1,在其他列记录为0。列的顺序无关紧要。如果你以前使用过pandas,你会注意到它的作用与pandas.get_dummies()是相同的。
如果我们有一个拥有300只动物的动物园,那么OHE是否会大量增加内存/计算资源的消耗?使用Spark不是问题!当大多数条目0为时,Spark在内部使用SparseVector ,这在OHE很常见,因此它不会浪费存储0值的空间。让我们看一个例子,以更好地了解如何SparseVector是如何工作的:
DenseVector(0,0,0,7,0,2,0,0,0,0)
SparseVector(10,[3,5],[7,2])
在本实施例中DenseVector包含的10个值,除2个非0值之外,其他值都为0。要创建一个SparseVector,我们需要跟踪向量的大小,非零元素的索引以及这些索引处的对应值。在此示例中,向量的大小为10,在索引3和5处有两个非零值,在这些索引处的对应值是7和2。
有几种方法可以使用Spark对数据进行独热编码。常用的方法是使用StringIndexer和OneHotEncoder。使用这种方法,第一步是应用StringIndexer预估器将类别值转换为类别索引。这些类别索引按标签频率排序,因此最频繁使用的标签的索引为0,这为我们在相同数据的各种运行中提供了可重复的结果。
创建类别索引后,你可以将其作为输入传递给OneHotEncoder(如果使用Spark 2.3 / 2.4对对应OneHotEncoderEstimator)。该OneHotEncoder映射将一列类别索引映射到一列二进制向量。查看表10-2了解Spark 2.3 / 2.4与3.0版本在StringIndexer和OneHotEncoder API上的区别。
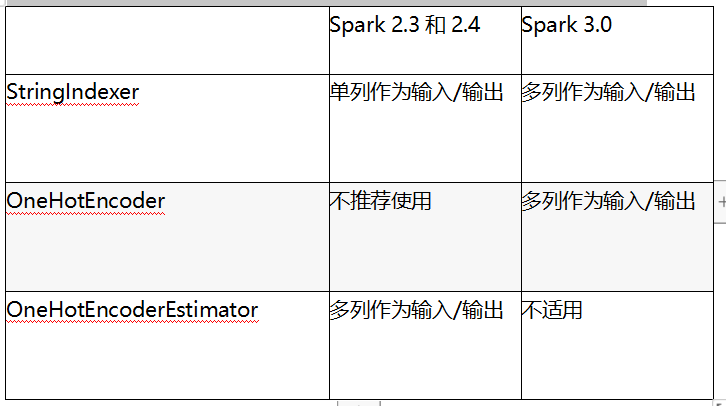
以下代码演示了如何对我们的分类功能进行独热编码。在我们的数据集中,任何string类型的列都被视为分类特征,但有时你可能希望将数字特征视为分类特征,反之亦然。你需要仔细确定哪些列是数字列,哪些是类别列:
In Python
from pyspark.ml.feature import OneHotEncoder, StringIndexer
categoricalCols = [field for (field, dataType) in trainDF.dtypes
if dataType == "string"]
indexOutputCols = [x + "Index" for x in categoricalCols]
oheOutputCols = [x + "OHE" for x in categoricalCols]
stringIndexer = StringIndexer(inputCols=categoricalCols,
outputCols=indexOutputCols,
handleInvalid="skip")
oheEncoder = OneHotEncoder(inputCols=indexOutputCols,
outputCols=oheOutputCols)
numericCols = [field for (field, dataType) in trainDF.dtypes
if ((dataType == "double") & (field != "price"))]
assemblerInputs = oheOutputCols + numericCols
vecAssembler = VectorAssembler(inputCols=assemblerInputs,
outputCol="features")
// In Scala
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer}
val categoricalCols = trainDF.dtypes.filter(_._2 == "StringType").map(_._1)
val indexOutputCols = categoricalCols.map(_ + "Index")
val oheOutputCols = categoricalCols.map(_ + "OHE")
val stringIndexer = new StringIndexer()
.setInputCols(categoricalCols)
.setOutputCols(indexOutputCols)
.setHandleInvalid("skip")
val oheEncoder = new OneHotEncoder()
.setInputCols(indexOutputCols)
.setOutputCols(oheOutputCols)
val numericCols = trainDF.dtypes.filter{ case (field, dataType) =>
dataType == "DoubleType" && field != "price"}.map(_._1)
val assemblerInputs = oheOutputCols ++ numericCols
val vecAssembler = new VectorAssembler()
.setInputCols(assemblerInputs)
.setOutputCol("features")
现在你可能想知道,“StringIndexer如何处理出现在测试数据集中而不是训练数据集中的新类别?” 有一个handleInvalid参数指定你要如何处理它们。选项包括skip(过滤掉无效数据的行),error(引发错误)或keep(将无效数据放入numLabels索引处的特殊追加桶中)。对于此示例,我们只是跳过了无效的记录。
这种方法的一个难题是你需要明确告诉StringIndexer指出哪些特征应被视为类别特征。你可以使用VectorIndexer来自动检测所有类别变量,但是由于它必须遍历每一列并检测其值是否少于maxCategories唯一值,因此在计算成本是非常高的。maxCategories是用户指定的参数,确定此值也可能很困难。
另一种方法是使用RFormula。其语法受R编程语言的启发。使用RFormula,你可以提供标签以及要包括的功能。它支持一个有限的R运算符的子集,包括~,.,:,+和-。例如,你可能指定formula = "y ~ bedrooms + bathrooms",这表示给定bedrooms和bathrooms预测y值,或者formula = "y ~ .",表示使用所有可用特征(并自动从特征中排除y)。RFormula将自动StringIndex和OHE所有字符串列,将数字列转换为double类型,并将所有这些组合成一个VectorAssembler的向量。因此,我们可以用一行替换所有前面的代码,并且我们将得到相同的结果:
In Python
from pyspark.ml.feature import RFormula
rFormula = RFormula(formula="price ~ .",
featuresCol="features",
labelCol="price",
handleInvalid="skip")
// In Scala
import org.apache.spark.ml.feature.RFormula
val rFormula = new RFormula()
.setFormula("price ~ .")
.setFeaturesCol("features")
.setLabelCol("price")
.setHandleInvalid("skip")
RFormula自动组合StringIndexer和OneHotEncoder,OneHotEncoder的缺点是,并非所有算法都要求或不建议使用独热编码。例如,如果仅将StringIndexer用作分类功能,则基于树的算法可以直接处理类别变量。你无需对基于树的方法独热编码类别特征,这通常会使基于树的模型变得更糟糕。不幸的是,没有一种适合所有人的解决方案,而理想的方法与你计划应用于数据集的下游算法紧密相关。
如果其他人为你执行特征工程,请确保他们记录了他们是如何生成这些特征的。
一旦编写了用于转换数据集的代码,就可以使用所有特征作为输入来添加到线性回归模型。
在这里,我们将所有特征准备和模型构建放入管道中,并将其应用于我们的数据集:
In Python
lr = LinearRegression(labelCol="price", featuresCol="features")
pipeline = Pipeline(stages = [stringIndexer, oheEncoder, vecAssembler, lr])
Or use RFormula
pipeline = Pipeline(stages = [rFormula, lr])
pipelineModel = pipeline.fit(trainDF)
predDF = pipelineModel.transform(testDF)
predDF.select("features", "price", "prediction").show(5)
// In Scala
val lr = new LinearRegression()
.setLabelCol("price")
.setFeaturesCol("features")
val pipeline = new Pipeline()
.setStages(Array(stringIndexer, oheEncoder, vecAssembler, lr))
// Or use RFormula
// val pipeline = new Pipeline().setStages(Array(rFormula, lr))
val pipelineModel = pipeline.fit(trainDF)
val predDF = pipelineModel.transform(testDF)
predDF.select("features", "price", "prediction").show(5)
+--------------------+-----+------------------+
| features|price| prediction|
+--------------------+-----+------------------+
|(98,[0,3,6,7,23,4...| 85.0| 55.80250714362137|
|(98,[0,3,6,7,23,4...| 45.0| 22.74720286761658|
|(98,[0,3,6,7,23,4...| 70.0|27.115811183814913|
|(98,[0,3,6,7,13,4...|128.0|-91.60763412465076|
|(98,[0,3,6,7,13,4...|159.0| 94.70374072351933|
+--------------------+-----+------------------+
如你所见,features列表示为SparseVector。独热编码后有98个特征,然后是非零索引,然后是值本身。如果你将truncate=False参数传入show()方法中,你可以看到所有的输出。
我们的模型表现如何?你可以看到,尽管有些预测可能被认为是“接近”,但其他的预测却相距遥远(存在租金为负数!!)。接下来,我们将评估数值模型在整个测试集中的效果。
评估模型
现在我们已经建立了一个模型,我们需要评估它的表现。在spark.ml有分类,回归,聚类和排序预估(在Spark 3.0引入)。鉴于上面的案例是一个回归问题,我们将使用均方根误差(RMSE)和R²( R平方)来评估模型的性能。
RMSE
RMSE是从零到无穷大的度量。距离零越近越好。
让我们逐步介绍一下数学公式:
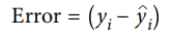
2.

3.然后,我们对所有

4.但是,SSE会随着数据集中的记录n的数量的增加而增长,所以我们希望根据记录的数量来对其进行规范化。它给了我们均方误差(MSE),一个非常常用的回归指标:

5.如果我们停在MSE,那么我们的误差项将处在预测变量单位的平方的规模。我们通常会采用MSE的平方根来使误差恢复到原始单位的比例,从而得出均方根误差(RMSE):

让我们使用RMSE评估我们的模型:
In Python
from pyspark.ml.evaluation import RegressionEvaluator
regressionEvaluator = RegressionEvaluator(
predictionCol="prediction",
labelCol="price",
metricName="rmse")
rmse = regressionEvaluator.evaluate(predDF)
print(f"RMSE is {rmse:.1f}")
// In Scala
import org.apache.spark.ml.evaluation.RegressionEvaluator
val regressionEvaluator = new RegressionEvaluator()
.setPredictionCol("prediction")
.setLabelCol("price")
.setMetricName("rmse")
val rmse = regressionEvaluator.evaluate(predDF)
println(f"RMSE is $rmse%.1f")
这将产生以下输出:
RMSE是220.6
解释RMSE的价值
那么,我们如何知道220.6是否对RMSE来说是一个比较好的值呢?有多种方法可以解释此值,其中一种方法是建立简单的基准模型并计算其RMSE进行比较。回归任务的常见基准模型是计算训练集上标签的平均值
如果这是分类问题,则你可能希望将预测最流行的类别作为基线模型。
请注意,标签的单位会直接影响你的RMSE。例如,如果你的标签是高度,那么如果使用厘米而不是米作为度量单位,则RMSE会更高。你可以通过使用其他单位来任意降低RMSE,这就是将RMSE与基准进行比较的原因。
当然,还有一些指标可以使你直观地了解自己在基准方面的表现,例如
R²
尽管名称
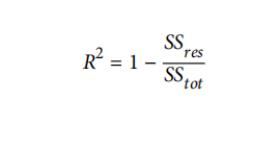
如果总是预测
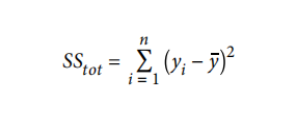
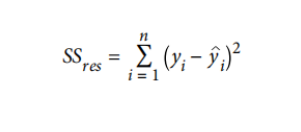
如果你的模型完美地预测了每个数据点,那么你的
但是,如果你的模型的性能比总是预测ȳ还糟糕,并且
如果要更改回归评估器以使用
In Python
r2 = regressionEvaluator.setMetricName("r2").evaluate(predDF)
print(f"R2 is {r2}")
// In Scala
val r2 = regressionEvaluator.setMetricName("r2").evaluate(predDF)
println(s"R2 is $r2")
输出为:
R2为0.159854
我们的
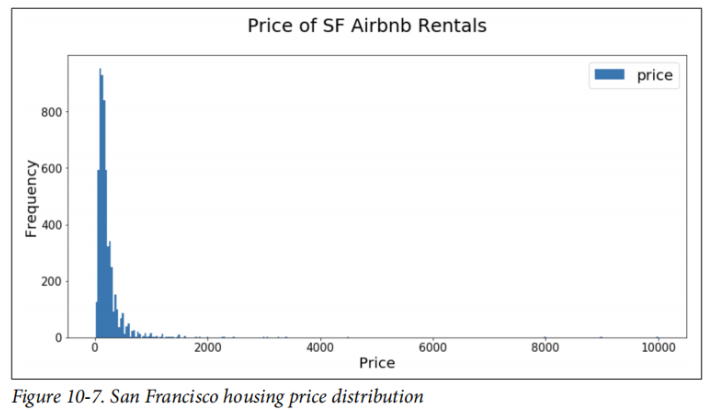
如果我们查看价格的对数,请看一下结果分布(图10-8)。
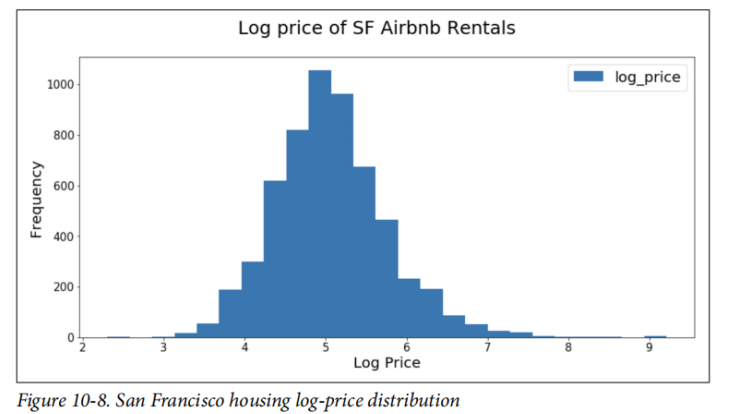
你可以在此处看到我们的对数价格分布看起来更像是正态分布。作为练习,尝试构建模型以预测对数刻度上的价格,然后对预测取幂并评估模型。该代码也可以在该书的GitHub repo库中的本章笔记本中找到。你应该看到此数据集的RMSE降低而
保存和加载模型
现在,我们已经建立并评估了一个模型,让我们将其保存到持久性存储中以备后用(或者,如果我们的集群出现故障,我们就不必重新计算模型)。保存模型与编写DataFrames 非常相似——也就是API中的model.write().save(path)。你可以选择提供overwrite()命令来覆盖该路径中包含的任何数据:
In Python
pipelinePath = "/tmp/lr-pipeline-model"
pipelineModel.write().overwrite().save(pipelinePath)
// In Scala
val pipelinePath = "/tmp/lr-pipeline-model"
pipelineModel.write.overwrite().save(pipelinePath)
加载保存的模型时,需要指定要重新加载的模型的类型(例如,是LinearRegressionModel还是LogisticRegressionModel)。因此,我们建议你始终将转换器/预估器放在Pipeline中,这样对于所有模型,你都可以加载PipelineModel,而只需更改模型的文件路径即可:
In Python
from pyspark.ml import PipelineModel
savedPipelineModel = PipelineModel.load(pipelinePath)
// In Scala
import org.apache.spark.ml.PipelineModel
val savedPipelineModel = PipelineModel.load(pipelinePath)
加载后,可以将其应用于新的数据点。但是,你不能使用该模型中的权重作为训练新模型的初始化参数(与从随机权重开始相反),因为Spark没有“热启动”的概念。如果数据集稍有变化,则必须从头开始重新训练整个线性回归模型。
通过构建和评估线性回归模型,让我们探究其他一些模型如何在我们的数据集上执行。在下一节中,我们将探索基于树的模型,并查看一些常见的超参数以进行调整以提高模型效果。