实时计算应用及技术选型
1. 实时计算在公司的用处
公司内已经采用MR与spark之类的技术,做离线计算,为什么用实时计算?
离线的伤痛就是数据出的太慢
有对实时数据要求高的场景
实时计算技术选型
Spark streaming、 Struct streaming、Storm、JStorm(阿里)、Kafka Streaming、Flink技术栈这么多,到底选哪个?
公司员工的技术基础
流行
技术复用
场景

如果对延迟要求不高的情况下,可以使用 Spark Streaming,它拥有丰富的高级 API,使用简单,并且 Spark 生态也比较成熟,吞吐量大,部署简单,社区活跃度较高,从 GitHub 的 star 数量也可以看得出来现在公司用 Spark 还是居多的,并且在新版本还引入了 Structured Streaming,这也会让 Spark 的体系更加完善。
如果对延迟性要求非常高的话,可以使用当下最火的流处理框架 Flink,采用原生的流处理系统,保证了低延迟性,在 API 和容错性方面做的也比较完善,使用和部署相对来说也是比较简单的,加上国内阿里贡献的 Blink,相信接下来 Flink 的功能将会更加完善,发展也会更加好,社区问题的响应速度也是非常快的,另外还有专门的钉钉大群和中文列表供大家提问,每周还会有专家进行直播讲解和答疑。
2. 项目实施环境
2.1 数据
目前已经存在订单数据,业务系统会将订单写入到mysql
流量日志数据(访问日志)
2.2 硬件
4台物理服务器
服务配置
2.3 人员
4人
2.4 时间
一个月左右
阶段
3. 需求分析
3.1 项目需求
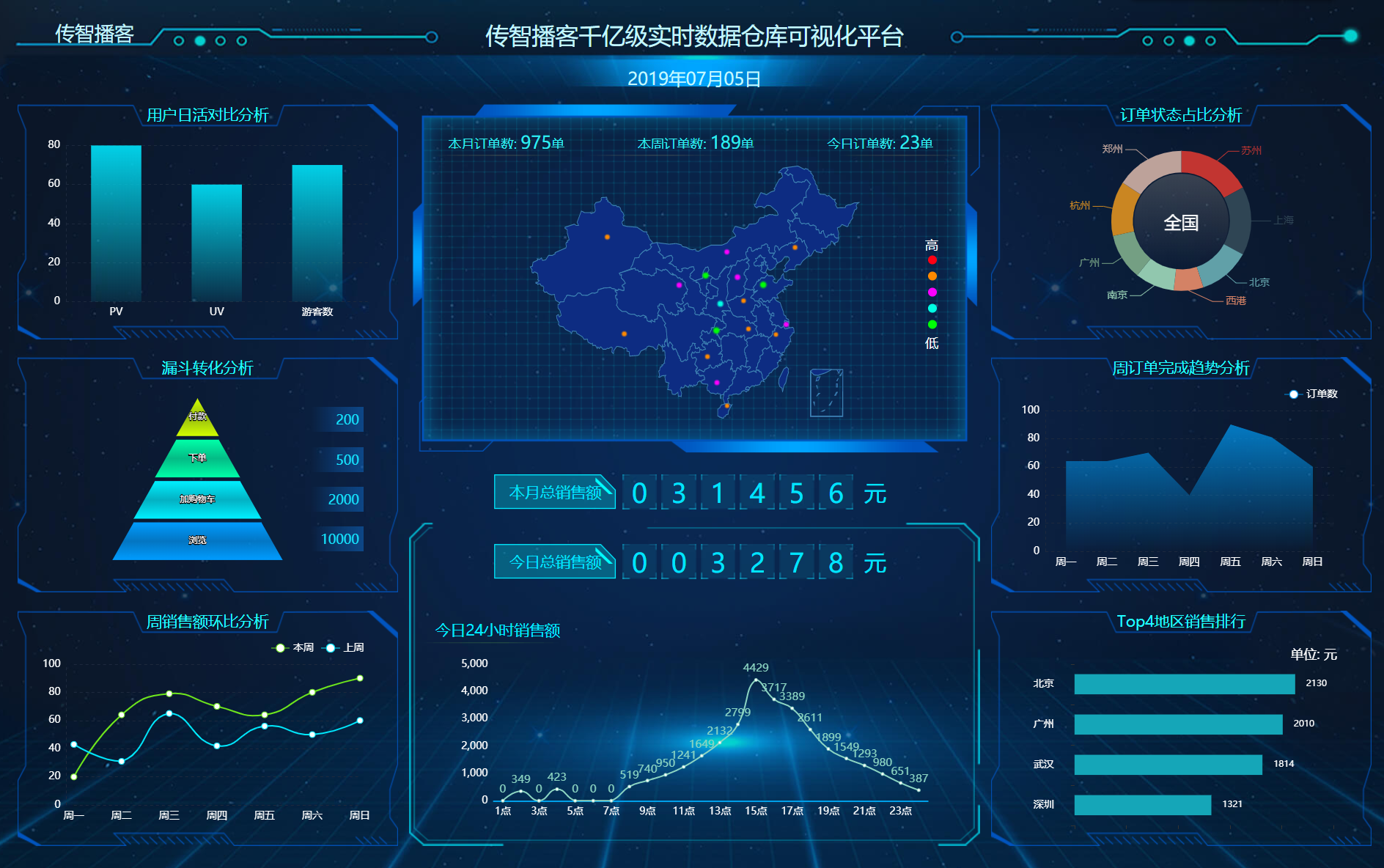
目前已经有前端可视化项目,公司需要大屏用于展示订单数据与用户访问数据
3.2 数据来源
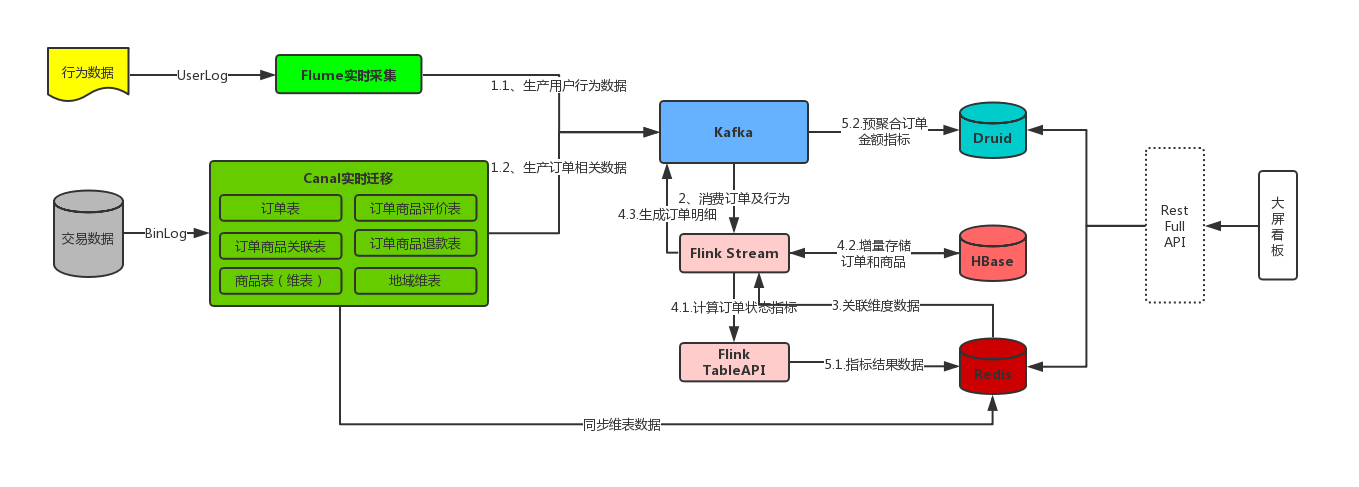
3.2.1 PV/UV数据来源
来自于页面埋点数据,将用户访问数据发送到web服务器
web服务器直接将该部分数据写入到kafka的click_log topic 中
3.2.2 销售金额与订单量数据来源
订单数据来源于mysql
订单数据来自binlog日志,通过canal 实时将数据写入到kafka的order的topic中
4. 常见的软件工程模型
4.1 瀑布模型
在一些银行、政府、等传统行业系统中,该模式应用较多

特点
使用范围
优点
缺点
4.2 原型

优点
缺点
4.3 敏捷开发
介绍
以用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发
把一个大项目分为多个相互联系,但也可独立运行的小项目,并分别完成
在开发过程中软件一直处于可使用状态
优点
敏捷确实是项目进入实质开发迭代阶段,用户很快可以看到一个基线架构版的产品
注重市场快速反应能力,也即具体应对能力,客户前期满意度高
缺点
敏捷注重人员的沟通,忽略文档的重要性,若项目人员流动大太,又给维护带来不少难度,特别项目存在新手比较多时,老员工比较累
需要项目中存在经验较强的人,要不大项目中容易遇到瓶颈问题
5. 实现方案
5.1 JAVA 方式实现
一些中小企业当中,由于数据量较小(比如核心总量小于20万条),可通过Java程序定时查询mysql实现
比较简单,但是粗暴实用
仅仅需要对mysql做一些优化即可,比如增加索引、分库分表、读写分离
5.2 通过flink方案实现
数据量特别大、无法直接通过mysql查询完成,有时候根本查询不动
要求实时性高,比如阿里巴巴双十一监控大屏,要求延迟不超过1秒
5.3 实时数仓项目架构