【并发编程的艺术】JVM体系与内存模型
内容参考来源:《Java并发编程的艺术》,有需要可私聊获取资料。
一 JVM体系结构
先看一张JVM体系结构图:
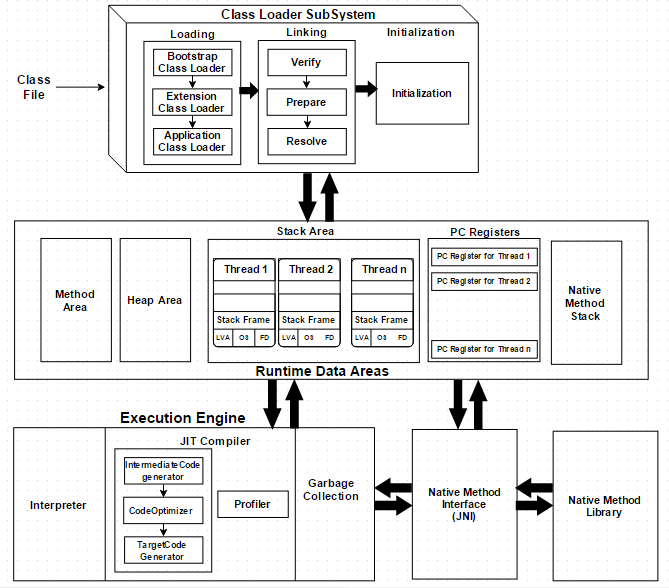
通过上图可见,JVM由类加载器、运行时数据区和执行引擎三个子系统组成。
简单介绍下三个子系统的功能,以便后续介绍中有更明确的理解:
1.1 类加载器
类加载器的功能,是处理类的动态加载(Loading),链接(Linking),并且在第一次引用类时进行初始化(Initialization)。
Loading->Linking->Initialization 也是通常类的加载过程。
1.2 运行时数据区
运行时数据区约定了在运行时程序代码的数据比如变量、参数等等的存储位置,包括:
PC 寄存器(程序计数器):保存正在执行的字节码指令的地址;
栈:在方法调用时,创建一个叫栈帧的数据结构,用于存储局部变量和部分过程的结果
堆:存储类实例对象和数组对象,垃圾回收的主要区域
方法区:也被称为元空间,还有个别名 non-heap(非堆),使用本地内存存储 class meta-data 元数据(运行时常量池,字段和方法的数据,构造函数和方法的字节码等),在 JDK 8 中,把 interned String 和类静态变量移动到了 Java 堆
运行时常量池:存储类或接口中的数值字面量,字符串字面量以及所有方法或字段的引用,基本上涉及到方法或字段,JVM 就会在运行时常量池中搜索其具体的内存地址
本地方法栈:与 JVM 栈类似,只不过服务于 Native 方法
1.3 执行引擎
运行时数据区存储着要执行的字节码,执行引擎将会读取并逐个执行。包括:
解释器(Interpreter),JIT编译器(JIT Compiler),垃圾收集器(Garbage Collector。
此外,还有执行引擎所需的本地库
感兴趣想继续深入研究的朋友可以查询JVM相关文档,或等待后续文章中对此进行详细描述。
二 关于内存结构与内存模型
提起内存结构 和 内存模型,可能很多人会搞混。这里再明确一下。
2.1 内存结构
描述的是内存被划分为多个数据区域,各区域都有对应的功能,重点是组成结构;简单来说,就是大家都了解过的下面这张图(来自《深入理解Java虚拟机(第2版)》):

以及堆内存的分代结构(Jvm1.8以前,1.8后永久代改为元数据区,以下仅用于示例):

2.2 内存模型
内存模型是一个比较复杂的概念,基于(JSR-133)的描述,Java内存模型(Java Memory Model-JMM)与线程规范紧密相关,通过下面的内容目录,我们可以看到其涵盖了锁(Locks),可见性(Visibility),顺序(Ordering)、原子性(Atomicity)、顺序一致性(Sequential Consistency)、Final字段(Final Fields)等一系列我们熟知的概念。
简单来说,Java内存模型描述了一组规范,来解决Java多线程对共享内存进行操作的时候,会出现的一些如可见性、原子性和顺序性的问题。

三 并发的典型场景与分析
3.1 并发代价
首先提几个经典的问题:
1、多线程一定比单线程快吗? 或者,并发一定比串行快吗?
答案:不一定,并发执行可能会比串行慢。原因?线程有创建和上下文切换的开销。
那么由此带来的直接问题,如何减少上下文切换?
无锁并发、CAS、使用最少线程和使用协程。
其中,无锁并发和CAS都是从“锁”的角度来减少开销。
无锁并发编程:多线程竞争锁时,会引起上下文切换,所以考虑通过避免使用锁的方式。例如根据数据id,做hash算法取模后分段,不同线程处理不同的段来避免争用;
CAS:Java提供Atomic包,使用CAS来更新数据,而不需要加锁。(这里实际是不显示使用锁,根据Linux x86架构下的cas源码,仍然有LOCK_IF_MP)。
使用最少线程:避免创建过多线程,这会导致造成大量线程处于等待状态。
协程:在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。
3.2 资源限制
执行程序时,通常需要考虑的资源包括:网络带宽、磁盘(大小&iops性能)、内存、cpu,这些可归类为硬件资源,此外还有软件资源,例如数据库连接数,socket连接数等。
使程序跑的更快,在资源的角度可以考虑两个方向,一是考虑资源扩充(扩容):单机->集群,并行执行程序,软件资源限制,考虑池化方式来实现资源复用;另一个方向,在固定的资源限制下,并发编程,尽可能对并行度调优。例如下载文件任务,主要依赖带宽和硬盘读写速度两个资源;涉及数据库读写操作时,连接数需要考虑;如果SQL执行很快且线程数比数据库连接数大很多,那么某些线程会被阻塞,等待数据库连接,我们就需要调整线程数来避免这种情况。
附:CAS底层实现
程序会根据当前处理器的类型来决定是否为cmpxchg指令添加lock前缀。如果程序是在多处理器上运行,就为cmpxchg指令加上lock前缀(lock cmpxchg)。反之,如果程序是在单处理器上运行,就省略lock前缀(单处理器自身会维护单处理器内的顺序一致性,不需要lock前缀提供的内存屏障效果)。
// Adding a lock prefix to an instruction on MP machine
// VC++ doesn't like the lock prefix to be on a single line
// so we can't insert a label after the lock prefix.
// By emitting a lock prefix, we can define a label after it.
#define LOCK_IF_MP(mp) __asm cmp mp, 0 \
__asm je L0 \
__asm _emit 0xF0 \
__asm L0:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}intel的手册对lock前缀的说明如下: