Spring Cloud 微服务实践(8) - 部署
本文就 Spring Cloud 微服务项目的部署进行实践探索,从手工部署到脚本化、容器化部署,对于测试环境或者小规模的生产环境来说,具有一定的借鉴意义。
应用的部署比较“接地气”,对没有专门运维团队的公司来说,应该还是开发去搞定。即使开发的职责比较专一不用操心部署的事情,但是从系统架构角度来看,技术框架的选择在关注开发效率、系统性能的同时,也需要考虑对运维的支持,能够简便快捷地进行系统监控、升级和扩容。
1、Spring Boot 对部署的支持
从 Spring Boot 项目的Maven配置pom.xml来看,可以直接打包为jar文件,然后java可以直接运行(以我们前面讲到的eureka-server为例,相信大家已经很熟悉了):
cd target
java -jar eureka-server-0.0.1-SNAPSHOT.jar这是借助了Maven和Java对jar包的支持来实现应用的部署。
另外 Spring Boot 还可以针对不同的环境进行不同的配置,通过设置spring.profiles.active参数来指定启用的profile,在application.yml文件中是这样:
spring:
profiles:
active: dev这里表示激活(active)的profile是dev,一般一个应用的工作环境有:dev、test、prod,分别表示开发、测试和生产。
指定了profile时,Spring Boot会去加载对应的配置,比如profile=dev会加载application-dev.yml,如果没有则还是application.yml。所以可以针对不同的运行环境分别进行配置,比如:
application-dev.yml
application-test.yml
application-prod.yml
事实上Spring Boot还有一个默认的配置文件bootstrap.yml,它比application.yml优先加载,所以可以配置一个bootstrap.yml来指定profile,然后结合多个application-*.yml来工作。
也可以在运行时指定profile:
java -jar somenoe.jar --spring.profiles.active=prodmvn运行时指定profile:
mvn spring-boot:run -Dspring-boot.run.profiles=prod注:这是Spring boot 2.x指定profile的方式,如果是Spring Boot 1.x则是-Drun.profiles=prod
2、应用监控(Actuator)
在应用的监控上,Spring Boot Actuator 提供了很多生产级的特性。Actuator 提供很多的Web接口(endpoint),通过这些接口可以获取应用程序运行时的内部状况。
/autoconfig,获取自动配置的信息
/configprops,获取配置属性
/beans,获取应用程序里Bean的信息
/dump,获取线程快照
/env,获取环境变量,也可以指定具体的环境变量名称:/env/{name}
/health,获取应用程序的健康状态
/info,获取应用程序的信息
/mappings,获取全部的URI路径
/metrics,获取应用程序的统计信息,也可以指定具体的名称:/metrics/{name}
/shutdown,关闭应用程序
/trace,获取HTTP请求跟踪信息
这里只是简单罗列了Actuator提供的Web接口,获取到的具体信息大家可以去实际测试一下,做更深入的研究,然后结合实际的生产环境中要解决的具体问题,再来决定需要开启哪些接口。
看一下在前面的文章中的相关的配置代码:
#Spring Boot监控Actuator的配置,对运维帮助很大,开发时很少用到
management:
endpoints:
web:
exposure:
#开启哪些endpoint
include: ["health", "info", "shutdown"]
endpoint:
health:
show-details: always
shutdown:
enabled: true
server:
#使用内部端口,不要对外开放
port: 7761Actuator涉及了很多敏感数据,像shutdown这样的接口甚至可以直接把应用关闭,所以在配置时要考虑安全问题。
把eureka-server启动起来,在端口7761上测试一下从Actuator开启的Web接口上获取数据(默认路径是actuator,如果要修改可以在application.yml中指定management.endpoints.web.base-path):
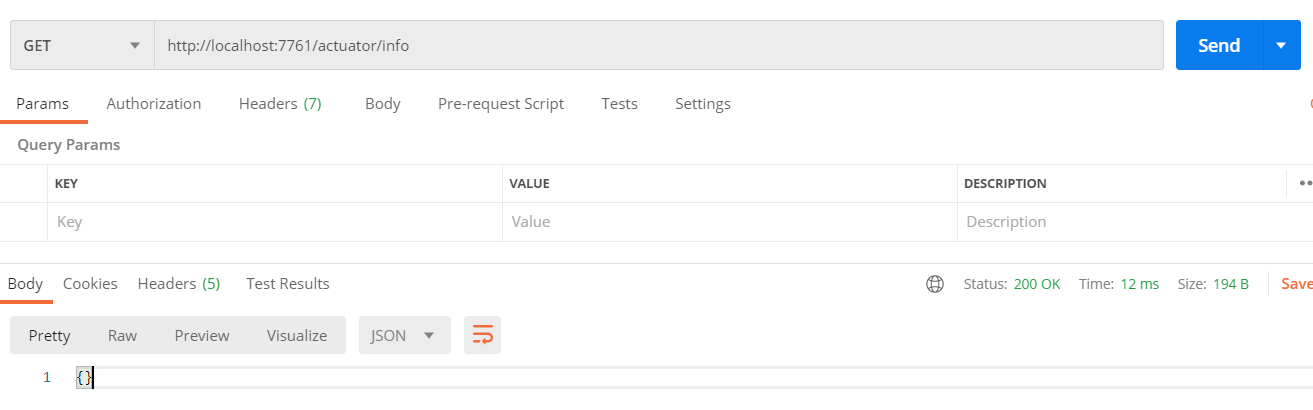
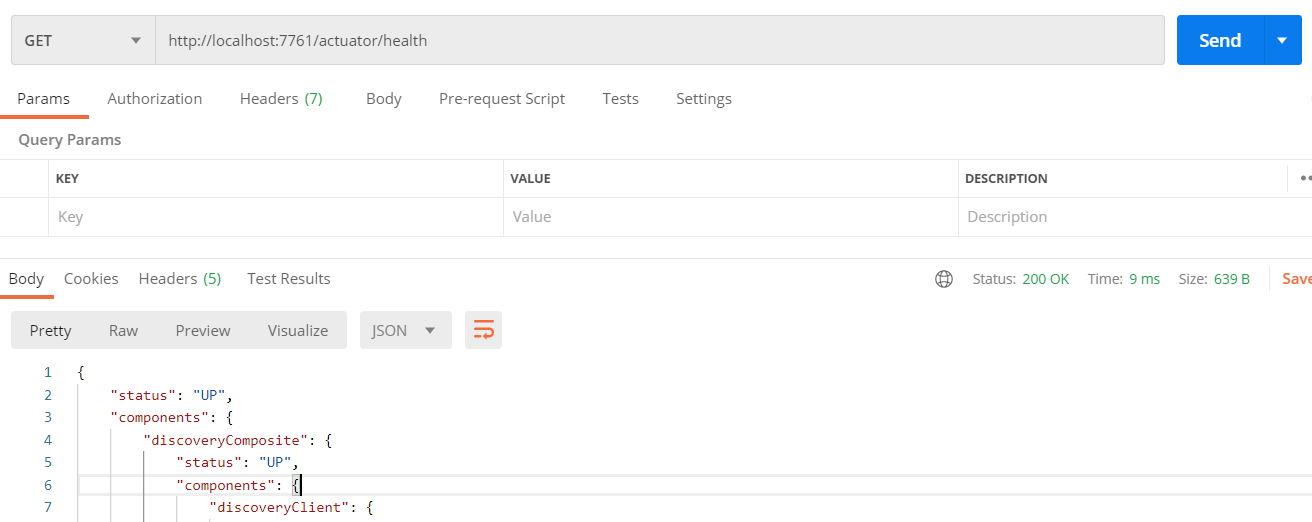
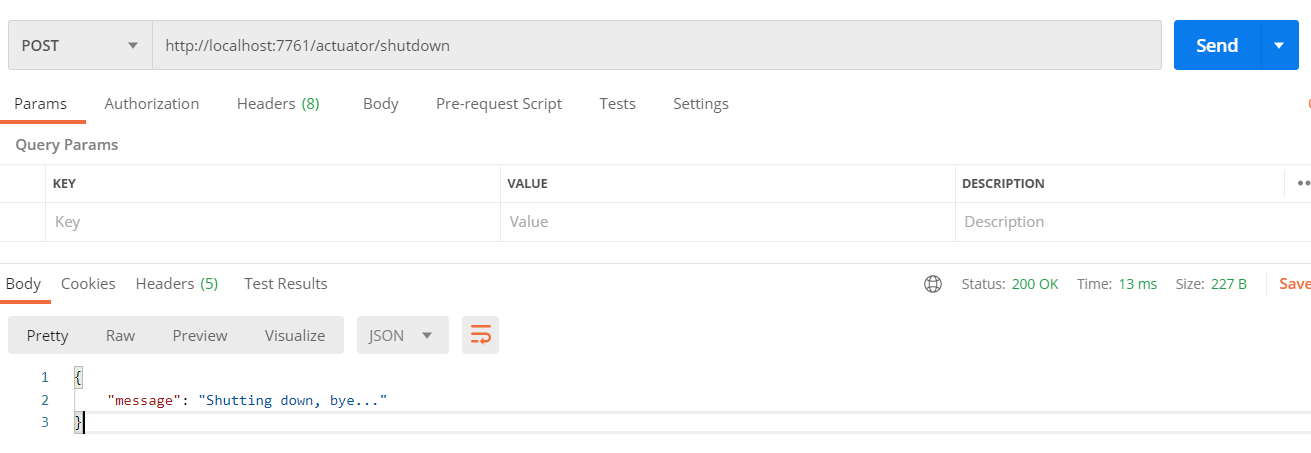
调整一下actuator的配置,打开所有的endpoint:
management:
endpoints:
web:
exposure:
include: '*'{
"_links": {
"self": {
"href": "http://localhost:7761/actuator",
"templated": false
},
"archaius": {
"href": "http://localhost:7761/actuator/archaius",
"templated": false
},
"beans": {
"href": "http://localhost:7761/actuator/beans",
"templated": false
},
"caches-cache": {
"href": "http://localhost:7761/actuator/caches/{cache}",
"templated": true
},
"caches": {
"href": "http://localhost:7761/actuator/caches",
"templated": false
},
"health": {
"href": "http://localhost:7761/actuator/health",
"templated": false
},
"health-path": {
"href": "http://localhost:7761/actuator/health/{*path}",
"templated": true
},
"info": {
"href": "http://localhost:7761/actuator/info",
"templated": false
},
"conditions": {
"href": "http://localhost:7761/actuator/conditions",
"templated": false
},
"shutdown": {
"href": "http://localhost:7761/actuator/shutdown",
"templated": false
},
"configprops": {
"href": "http://localhost:7761/actuator/configprops",
"templated": false
},
"env": {
"href": "http://localhost:7761/actuator/env",
"templated": false
},
"env-toMatch": {
"href": "http://localhost:7761/actuator/env/{toMatch}",
"templated": true
},
"loggers": {
"href": "http://localhost:7761/actuator/loggers",
"templated": false
},
"loggers-name": {
"href": "http://localhost:7761/actuator/loggers/{name}",
"templated": true
},
"heapdump": {
"href": "http://localhost:7761/actuator/heapdump",
"templated": false
},
"threaddump": {
"href": "http://localhost:7761/actuator/threaddump",
"templated": false
},
"metrics-requiredMetricName": {
"href": "http://localhost:7761/actuator/metrics/{requiredMetricName}",
"templated": true
},
"metrics": {
"href": "http://localhost:7761/actuator/metrics",
"templated": false
},
"scheduledtasks": {
"href": "http://localhost:7761/actuator/scheduledtasks",
"templated": false
},
"mappings": {
"href": "http://localhost:7761/actuator/mappings",
"templated": false
},
"refresh": {
"href": "http://localhost:7761/actuator/refresh",
"templated": false
},
"features": {
"href": "http://localhost:7761/actuator/features",
"templated": false
},
"service-registry": {
"href": "http://localhost:7761/actuator/service-registry",
"templated": false
}
}
}注:Actuator支持的endpoint和通过这些endpoint获取的信息或执行的操作,各个版本不一样,并且跟相关服务的具体实现也有关,比如服务注册与发现就有Eureka Server和zookeeper等,所以建议大家搭建环境实际测试一下。
3、手工部署(FTP+Shell)
有了jar文件和actuator的加持,要部署和监控基于 Spring Cloud 开发的微服务,在技术上已经可行了。
我们看看最原始的手工部署方式是怎样的:
编译打包:
FTP上传jar文件到生产环境的服务器上,一般是Linux服务器
运行:
但是实际的情况却涉及到更多的细节需要处理,比如说:
应用程序的配置: 开发环境、测试环境和生产环境的应用配置(application.yml)是不一样的,比如数据库连接参数、消息中间件的连接参数等,甚至logback的配置在不同的场景下也是不一样的;通过指定profile的方式可以解决这个问题,但是容易乱,并且把生产环境的数据库账号密码这样的敏感数据放在开发环境来维护,很不靠谱。
每次升级和调整都是把整个jar文件通过FTP上传,即使是eureka-server这种最简单的应用,打包后也是40M+,所以传输性能不理想,大多数情况下,我们只需要上传修改那部分代码生成的class文件。
所以我们改进一下,写一点脚本进行jar文件的处理。
解压jar文件到当前目录下:
jar -xvf someone.jar打包target目录下的所有文件到jar:
jar -cvfM0 someone.jar -C ./target .注:都是用jdk自带的jar程序来进行解包和打包,可以输入jar命令不带参数来查看它支持的参数及用法。
假设把解压后的文件放target目录下,编写一个打包脚本,先删除存在的jar文件再打包(pack.sh):
#!/bin/bash
if [ -f "./someone.jar" ]; then
rm -f "./someone.jar"
fi
jar -cvfM0 someone.jar -C ./target .这样放在target里的配置文件,可以用vi等命令编辑,或者用FTP上传文件进行替换,class文件、其他的依赖文件都可以进行替换,然后运行pack.sh打包,得到新的jar文件:
sh pack.sh注:用这种方式在生产环境进行升级,除了FTP上传只涉及更新的文件可以更快,也可以确保生产环境的配置不会被轻易修改。想一想我们的日常工作吧,如果没有专门的运维team,都是开发人员身兼数职的话,在开发环境打包整个jar再FTP到生产环境进行替换,出错的概率有多大!
2021-11-09,回来打个补丁。把jar包解开再重新打包的这种方式,并不是最完善的解决方案,因为各个项目build时的jar打包参数,可能会是多样化的,这里统一用jar -cvfM0来打包,会导致某些jar无法运行。
比较完善的方案是先提取文件(jar -xvf someone.jar BOOT-INF/classes/application.yaml),修改后再更新回去(jar -uvf someone.jar BOOT-INF/classes/application.yaml),这样就不会破坏jar的整体结构。
运行jar的命令也可以写成脚本(startup.sh):
#!/bin/bash
nohup java -jar -Xms64m -Xmx512m someone.jar >> ./logs/nohup.out 2>&1 &注:上述脚本指定了java程序的内存参数,使用nohup让程序在后台运行,并且将nohup的输出重定向到nohup.out文件。
关闭应用的脚本(shutdown.sh):
#!/bin/bash
echo "shutdown..."
curl -d "a=1" "http://localhost:7761/actuator/shutdown"注:脚本中的端口7761跟actuator的配置要对应起来,即management.server.port的值;a=1是随便写的一个参数,只是为了发送POST请求。
有了这些脚本的帮助,我们的手工发布流程就是这样了(第一次发布):
升级或者配置调整的流程:
4、配置中心(zookeeper)
在微服务应用数量不多的情况下,手工配合脚本的方式,其实已经可以胜任日常的部署工作。但微服务数量多的时候,要一个一个去修改应用的配置参数,再打包运行,实在是繁琐,并且容易失误。
Spring Cloud提供了配置中心来集中进行配置,解决配置分散不方便维护的问题。
在上一篇关于日志记录的文章中,我们已经接触到了kafka,kafka还有一个搭档就是zookeeper,所以我们把服务注册与发现也换成zookeeper,并且配置中心也可以用zookeeper。这里就以zookeeper为例来实现配置中心。
添加maven依赖(pom.xml):
org.springframework.cloud
spring-cloud-starter-zookeeper-discovery
org.springframework.cloud
spring-cloud-starter-zookeeper-config
bootstrap.yml:
spring:
...
cloud:
zookeeper:
connect-string: localhost:21810
config:
enabled: true
root: /config/someone
profile-seperator: ","
watcher:
# 配置变更后更新
enabled: false注:因为要从配置中心获取应用的配置,所以必须在bootstrap.yml文件中配置zookeeper的连接参数和开启config能力,否则不会生效。
zookeeper的安装这里就不讲了,另外了还需要安装一个工具zkui,在网页上维护zookeeper中保存的参数。zkui只是在参数维护的时候才需要运行,它内部也是连接的zookeeper。建议使用Docker方式安装zookeeper和zkui。
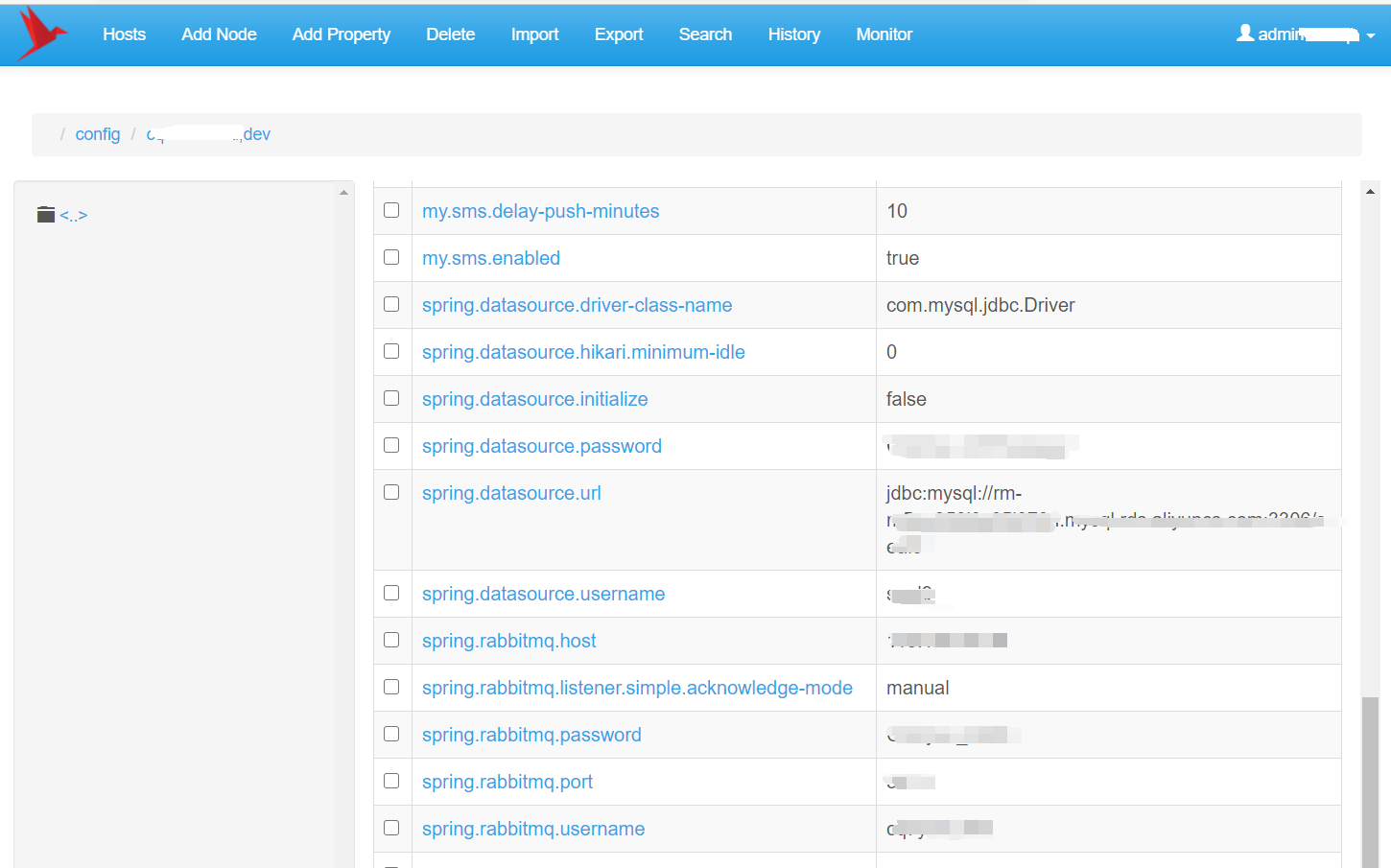
配置中心就这样了,其他代码都不需要修改,Spring Cloud对配置中心进行了集成和抽象,统一了编程模型,把底层的具体实现隔离开来,使得我们从Eureka Server更换到Zookeeper的改动很小,更多的工作是在zookeeper的安装上。
当然把配置放到zookeeper集中配置后,原来application.yml中就不用配置了,具体哪些参数放配置中心哪些放bootstrap.yml和application.yml,就看具体情况来分析判断了。
5、容器化部署(Docker)
在前面的文章已经提了几次Docker,就目前的情况来看,尽管容器化是大势所趋,但是容器化也带来了新的问题,至少对我们学习来说就增加了学习成本,特别是容器编排kubernetes和网格Istio,学习难度一个比一个大,基本上小公司很难有人力物力去掌握和部署。
容器化的发展方向,个人认为会逐渐像操作系统提供的磁盘、网络等基础服务一样,慢慢变成云服务的基础能力。现在很多云厂商也在推serverless和托管的kubernetes,但是使用难度和成本依然不小,所以需要时间来完善和演进。
Docker 是一个开源的应用容器引擎,可以让开发者打包应用以及依赖包到一个轻量级、可移植的容器中。容器使用沙箱机制,相互之间没有接口,并且容器的性能很高,碾压虚拟机。
使用Docker进行容器化部署,解决了软件开发、测试和部署时的环境配置差异问题,应用需要的相关环境都已经在容器中安装配置就绪。另外,对开发人员来说,用Docker来安装MySql数据库,以及Zookeeper、Kafka等中间件是很方便快捷的,并且因为Docker的沙箱隔离机制,使得安装和删除这些应用对操作系统没额外的影响,这对喜欢折腾的开发人员来说实在是“居家旅行必备”的工具。
5.1、在Windows 10上安装
Docker官网上Windows 10以上推荐安装docker-desktop,下载地址: 。需要Windows专业版才能安装,因为专业版才能开启Hyper-V(Windows 的虚拟机),另外还需要在BIOS中把虚拟化支持打开。
Windows家庭版安装Docker则麻烦一点,首先必须要在BIOS中启用硬件虚拟化支持,然后可以考虑两个方式:一是升级Windows到比较新的版本,然后开启WSL 2(使用于Linux的Windows子系统第2版),再安装Linux和Docker;二是想办法绕开Windows的限制在家庭版上开启Hyper-V。
5.2、在Centos上安装
为添加yum软件源做准备:
sudo yum update
sudo yum install -y yum-utils device-mapper-persistent-data lvm2添加docker的yum软件源:
sudo yum-config-manager \
--add-repo https://download.docker.com/linux/centos/docker-ce.repo安装Docker:
sudo yum update
sudo yum install docker-ce启动Docker:
sudo systemctl start docker开机启动:
sudo systemctl enable docker验证安装:
docker version返回的信息应该包括Client和Server两部分信息:
Client: Docker Engine - Community
Version: 19.03.12
API version: 1.40
Go version: go1.13.10
Git commit: 48a66213fe
Built: Mon Jun 22 15:46:54 2020
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 19.03.12
API version: 1.40 (minimum version 1.12)
Go version: go1.13.10
Git commit: 48a66213fe
Built: Mon Jun 22 15:45:28 2020
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.2.13
GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429
runc:
Version: 1.0.0-rc10
GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd
docker-init:
Version: 0.18.0
GitCommit: fec36835.3、镜像下载加速
Docker把应用程序及其依赖打包在镜像(Image)文件里,可以把Image看着是容器的模板,可以直接下载Image来运行应用程序,也可以基于某个Image来扩展生成新的Image。Docker官方维护了一个Image的共享网站: ,可以查找Image并查看文档。
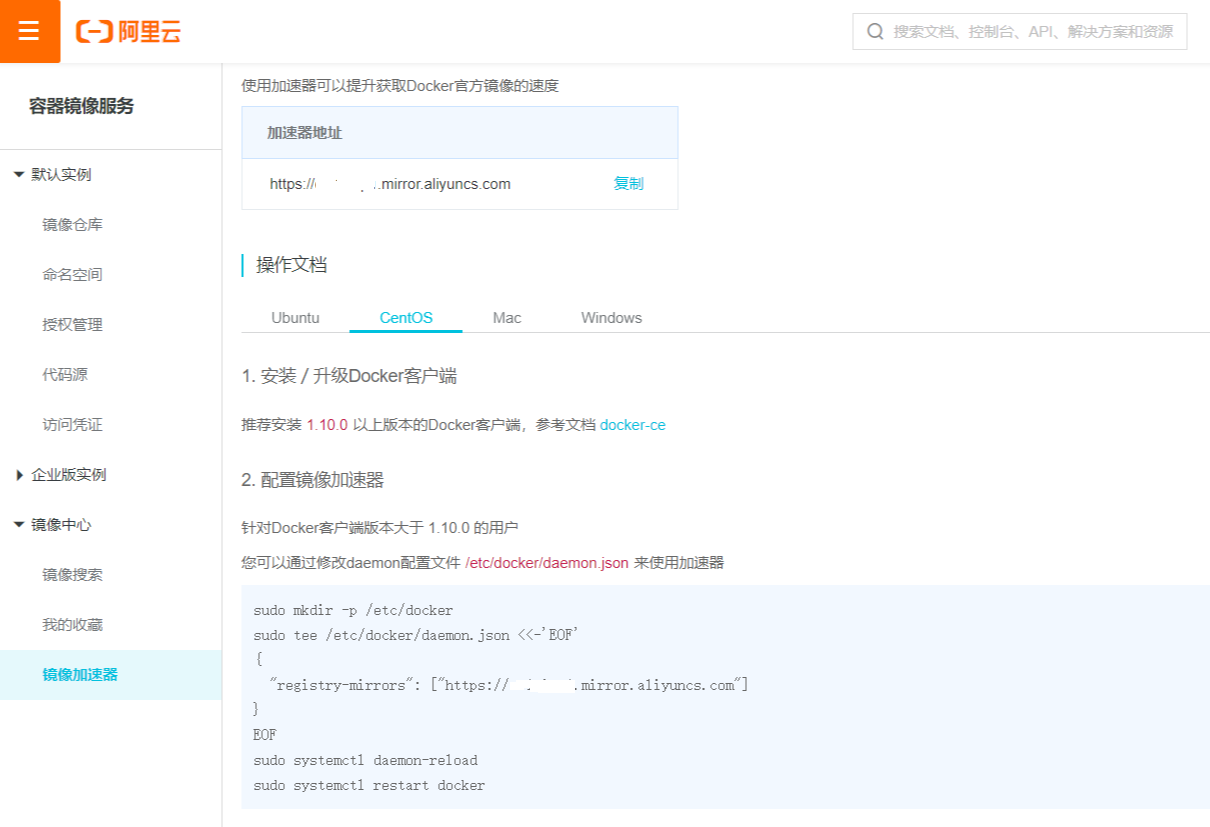
从Docker官方下载镜像,在国内可能有点慢,国内的一些大厂和大学提供了镜像加速服务,比如。注册账号登录后,在控制台里搜索“容器镜像服务”,在最下面的“镜像中心”有一个“镜像加速器”,对各种情况的加速都做了详尽说明:
5.4、镜像管理
通过docker命令查找Image(以MySql为例):
docker search mysql下载Image:
docker pull mysql:5.7注:在镜像名称后不指定具体的版本,则表示最新版(latest)。建议在生产环境指定具体的版本,因为latest具有不确定性,在Image发布了新的版本后,此时的latest就非彼时的latest了,出现问题后不好排查。
查看系统中的Image:
docker images删除Image:
docker rmi mysql:5.7有了镜像后,就可以创建容器,也就是把应用跑起来。在创建容器的时候,可以指定一些参数,比如环境变量、端口映射和文件挂载等。
5.5、安装MySql
下面看一个具体的实例,用MySql官方提供的Image来创建一个MySql容器:
docker run \
-v /your-data/mysql5.7-data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=YourPwd \
-p 33060:3306 \
-d mysql:5.7注: 为了方便大家阅读,这里特意用换行的形式来书写,linux下换行是“\enter”,即“\”+回车,Windows的PowerShell下则是“`enter”。
-v,挂载文件目录,把主机上的目录挂载到容器里。上述例子中的“-v /your-data/mysql5.7-data:/var/lib/mysql”,把主机上的mysql5.7-data目录挂载为容器里的/var/lib/mysql,这样就把数据持久化到主机上了;
-p,端口映射,通过访问主机的端口(33060)来访问容器(3306);
-e,设置环境变量,这跟具体的Image有关,这里的MYSQL_ROOT_PASSWORD是设置MySql的root用户的密码;
-d 是后台运行运行容器。
5.6、容器管理
查看正在运行的容器:
docker ps用docker run创建的容器,不管是后台守护模式运行,还是运行完成已经退出(Exited),只要没有显示地删除(--rm),该容器就还在。即使相同的docker run命令,每一次运行都会创建一个新的容器。
查看所有容器:
docker ps -a删除容器:
docker rm ${CONTAINER_ID}
或者:
docker rm ${NAME}注:这里的容器ID(${CONTAINER_ID})和容器名称(${NAME})对应查看容器时获得的ID和NAME。
停止容器:
docker stop ${CONTAINER_ID}
或者:
docker stop ${NAME}启动容器:
docker start ${CONTAINER_ID}
或者:
docker start ${NAME}5.7、跟容器交互
以交互模式运行容器里的程序:
docker exec -it ${CONTAINER_ID} sh注:这相当于以shell的方式“进入”了容器,可以在容器内部进行各种操作。
5.8、安装Zookeeper
docker run \
-p 2181:2181 \
-v /usr/local/zookeeper/data:/data \
-v /usr/local/zookeeper/datalog:/datalog \
-d zookeeper:3.5.55.9、安装Kafka
docker run -d --name kafka -p 8092:9092 \
--env 'KAFKA_ZOOKEEPER_CONNECT=192.168.18.231:2181' \
--env 'KAFKA_ADVERTISED_HOST_NAME=192.168.18.231' \
--env 'KAFKA_ADVERTISED_PORT=8092' \
wurstmeister/kafka:2.13-2.6.05.10、创建Java应用的镜像
可以通过Dockerfile来构建自定义镜像,Dockerfile是文本文件,包含了构建镜像所需的指令和说明。这里以构建Java应用为例:
# 以openjdk:8-jdk-alpine为基础镜像进行构建
FROM openjdk:8-jdk-alpine
# 挂载点
VOLUME /tmp
# 设置环境变量
ENV APP_HOME=/spring-boot
# 设置命令的运行目录,为后续的RUN、CMD、ADD、ENTRYPOINT等指令配置工作目录
WORKDIR $APP_HOME
# 把源系统的someone-0.0.1-SNAPSHOT.jar文件复制到目标容器并改名为app.jar。
# 如果源是一个URL,则从该URL下载并复制到容器中。
# 如果文件是可识别的压缩格式,则docker会自动解压缩。jar文件不在它的识别范围内,不会解压。
ADD someone-0.0.1-SNAPSHOT.jar app.jar
# 暴露的端口,这个要跟容器里应用的端口对应起来
EXPOSE 8080
# 设置时区
ENV TZ=Asia/Shanghai
# 配置容器启动后执行的命令。每个Dockerfile中只能有一个ENTRYPOINT,当存在多个时,执行最后一个
# -XX:+UseContainerSupport,允许JVM从主机读取cgroup限制,包括可用的CPU和RAM等信息,这里主要配置内存
# -XX:InitialRAMPercentage=50.0,初始内存为容器内存的50%
# -XX:MaxRAMPercentage=75.0,最大内存为容器内存的75%,为其他进程留下足够的内存空间
ENTRYPOINT ["java","-XX:+UseContainerSupport","-XX:InitialRAMPercentage=50.0","-XX:MaxRAMPercentage=75.0","-Djava.security.egd=file:/dev/./urandom","-jar","/spring-boot/app.jar"]注1:从这个例子可以看出来,Dockerfile的指令大部分跟 的参数是相关的;
注2:-XX:+UseContainerSupport,从Java 8u191开始支持这个特性
构建镜像的命令是,是镜像名称,是镜像的TAG(版本)。下面的记录在构建前用列了一下目录上的文件,确认有Dockerfile和jar文件,构建后用查看新生成的镜像:
PS E:\docker\someone> ls
目录: E:\docker\someone
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---- 2020-10-13 9:37 270 Dockerfile
-a---- 2020-10-13 9:35 69144663 someone-0.0.1-SNAPSHOT.jar
PS E:\docker\someone> docker build -t someone:1.0.1 .
Sending build context to Docker daemon 69.15MB
Step 1/7 : FROM openjdk:8-jdk-alpine
---> a3562aa0b991
Step 2/7 : VOLUME /tmp
---> Using cache
---> d460a3d40a44
Step 3/7 : ENV APP_HOME=/spring-boot
---> Using cache
---> 94f1c0a35ef1
Step 4/7 : WORKDIR $APP_HOME
---> Using cache
---> ea74d1840269
Step 5/7 : ADD someone-0.0.1-SNAPSHOT.jar app.jar
---> Using cache
---> 3c0e5a78a979
Step 6/7 : ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/spring-boot/app.jar"]
---> Using cache
---> fabfb0dd0983
Step 7/7 : EXPOSE 8092
---> Using cache
---> 9db7d8e2ee3f
Successfully built 9db7d8e2ee3f
Successfully tagged someone:1.0.1
...
PS E:\docker\someone> docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
someone 1.0.1 9db7d8e2ee3f 42 minutes ago 174MB
...5.11、创建微服务的镜像
有了前面创建Java应用镜像的基础,我们再来创建Spring Cloud微服务应用的镜像。
微服务应用的特点是把业务拆分为细粒度的微服务,分布式部署,再通过服务注册与发现进行协作,通过网关向外提供完整的系统能力(服务)。而Docker容器的特点是用沙箱机制把应用进行隔离,Expose端口给外部调用,内部则是一个“独立”的系统。所以用Docker来容器化部署微服务,主要解决的问题就是在沙箱隔离机制下,微服务怎么相互发现并进行协作?
好在docker可以在启动容器(docker run)时传递环境变量,而Spring Boot也提供了在配置文件中获取环境变量的能力。另外Spring Cloud的服务注册中心也考虑到了客户端网络方面的问题,允许客户端在注册时指定自己的IP地址和端口。
Spring Boot应用以jar包的形式部署,构建为Docker的镜像(Image)后更多了一层外壳,并且Image是“容器模板”,相对应该固定不要轻易改变,至少把参数配置这部分剥离出来,只是在逻辑修改时发布新的Image。配置中心可以完成参数配置的剥离,集中管理应用的参数,但是应用必须找到配置中心,跟配置中心建立连接。
这里以zookeeper作服务发现与注册中心,通过环境变量来解决服务发现问题,bootstrap.yml:
spring:
...
cloud:
zookeeper:
connect-string: ${ZOOKEEPER1_IP:zookeeper}:${ZOOKEEPER1_PORT:2181},${ZOOKEEPER2_IP:zookeeper}:${ZOOKEEPER2_PORT:2181}
discovery:
# 告诉zookeeper,让其他服务通过下述地址和端口来找我
instance-host: ${INSTANCE_HOST:localhost}
instance-port: ${INSTANCE_PORT:${server.port}}注1:Spring Boot在yml配置文件里可以用${ENV_NAME}的形式获取系统的环境变量,后面跟冒号表示没有获取到对应的环境变量时的默认值。
注2:instance-host和instance-port的设置很关键,默认情况下,Spring Cloud应用向注册中心注册的IP地址和端口,都是容器内部的地址和端口,其他服务不能连接。
启动docker容器时传递环境变量:
docker run \
-e ZOOKEEPER1_IP=192.168.1.110 \
-e ZOOKEEPER1_PORT=2181 \
-e INSTANCE_HOST=192.168.1.120 \
-e INSTANCE_PORT=8081 \
...这样就让Image的适应性更强一些,在zookeeper变化时只需要调整参数就可以,也为容器编排做好准备。
5.12、使用工具创建镜像
以Dockerfile文件为基础,各种开发工具顺理成章地发展出了自动生成docker镜像的功能。
Maven的docker插件可以看看这个:,这个插件只是一个辅助,在Maven和Dockerfile之间起了桥梁作用,需要编写Dockerfile,在发布Image时可以省一些工作量。如果日常需要构建Image并往镜像仓库上推送,可以考虑使用它,否则没有多大必要。毕竟有了Dockerfile,构建Image只是执行一条命令而已。
IntelliJ IDEA等集成开发工具(IDE)也提供了对Docker的支持,基本上也是让填一些信息来生成Dockerfile。
如果用Jenkins来进行持续集成,则可以在Jenkins上通过配置将编译、打包、生成镜像等各个步骤串联起来,大致的流程是:
5.13、容器编排
容器化部署讲到现在,除了使用Docker安装MySql、Zookeeper和Kafka,让我们开发时享受到了容器化带来的便利,就部署微服务来说,它的好处和优势给我们的感知并不那么明显,反而把部署复杂化了。
这就必须说容器的编排,也就是对容器化应用的管理,包括应用的部署、规划、更新和维护等。部署前面我们已经讲了很多了,主要的关注点就是保证应用运行的环境跟预期一致,Docker容器提供了很好的解决方案;而规划呢,就是对微服务资源的分配规划,比如微服务系统中的认证中心,你的规划是运行5个实例,每个实例2G内存;更新方面要考虑的问题则是新旧系统并行、回滚等问题;维护则主要是对系统的监控,及时发现问题并进行处理,比如磁盘满了,内存不够了,服务宕了等。
Docker在容器化应用的管理方面推出了docker-compose,以及后续的swarm,都是试图把前面讲的这些部署、规划、更新和维护等操作自动化,这样就大大减少了维护的工作量,也提高了系统的稳定性,毕竟机器比人靠谱嘛^_^。
docker-compose的重点“compose”,就是把原来分离的一些容器,集中到一起来进行编排管理。需要写一个编写一个docker-compose.yml文件,把相关的一组应用结合起来,先启动被依赖的应用,并且可以调整(Scale)某些应用的实例数量。
举个例子(docker-compose.yml):
version: '3.1'
#创建定义网络 hoxton-net
networks:
hoxton-net:
driver: bridge
services:
#注册中心
zookeeper:
image: zookeeper:3.5.5
restart: always
hostname: zookeeper
networks:
- hoxton-net
ports:
- 2181:2181
volumes:
- ./zookeeper/data:/data
- ./zookeeper/datalog:/datalog
#网关
gateway:
#如果Image不存在就去这个路径构建(路径下需要有对应的Dockerfile等文件)
build: ./gateway
image: gateway
restart: always
hostname: gateway
networks:
- hoxton-net
ports:
- 8080:8080
#依赖
depends_on:
- zookeeper
oauth2-server:
build: ./oauth2-server
image: oauth2-server
restart: always
hostname: oauth2-server
networks:
- hoxton-net
ports:
- 8090
depends_on:
- zookeeper
oauth2-client:
build: ./oauth2-client
image: oauth2-client
restart: always
hostname: oauth2-client
networks:
- hoxton-net
ports:
- 8091
depends_on:
- zookeeper
oauth2-one:
build: ./oauth2-one
image: oauth2-one
restart: always
hostname: oauth2-one
networks:
- hoxton-net
ports:
- 8092
depends_on:
- zookeeper注:如果容器使用docker创建的network,就可以相互通信,如同在一个局域网内。所以这里所有应用都是在一个network,能直接相互访问,就不需要用环境变量来达成服务发现。
启动:
docker-compose -p hoxton up -d注:-p,指定项目名称,如果不指定则会用当前的文件夹名称作项目名;-d,后台运行
扩容(Scale):
docker-compose -p hoxton up -d --scale oauth2-server=4停止:
docker-compose -p hoxton down注:不像,容器只是停止运行但还在;不仅停止容器,还会把容器删除掉,类似 +
一次启动的应用比较多时,docker-compose还是很爽的。但在微服务的部署方面,不建议用docker-compose,除非你的微服务系统都部署在一台服务器上。docker swarm据说可以解决跨主机通信的问题,但是现在是Kubernetes的天下,有那个时间和精力还是折腾Kubernetes吧。
6、总结
从直接运行jar包,到编写脚本执行部署,到容器化部署(Docker)和容器编排(Kubernetes),在应用的部署上,我们算是走得越来越远了(越来越复杂)。大家还是结合自己团队的情况综合考虑吧,切忌浮沙筑高台,适合的就是最好的。
下一篇: 待续