ELK 日志收集简易教程
简介
ELK 是 Elasticsearch, Logstash, 和 Kibana 的首字母缩写,这里还会涉及一个文件日志的收集工具 Filebeat。
收集流程如封面图所示:
Filebeat: 会监控文件的变化,将文件的内容按行(可配置多行合并)收集,并发送到 Logstash。
Logstash:对 Filebeat 发送过来的数据进行加工处理,然后再发送给 Elasticsearch。
Elasticsearch:对日志进行存储、检索。
Kibana:提供 web 查询界面。
本教程在 Linux 平台安装,提供可以跑通流程的配置。
安装Elasticsearch
下载地址:https://www.elastic.co/cn/downloads/elasticsearch ,下载最新的版本
我这里下载的是 elasticsearch-7.6.2-linux-x86_64.tar.gz
解压后如果端口不冲突,直接运行即可
# 解压
tar -xvf elasticsearch-7.6.2-linux-x86_64.tar.gz
# 运行
bin/elasticsearch -d由于我这里是公共的测试环境,JDK 版本是1.6 ES 要在更高的版本下运行,其实下载的 ES 中已经自带 JDK 在
elasticsearch-7.6.2/jdk/ 这个目录下。为了不影响其他人使用,执行下面两条命令,临时修改下环境变量:
export JAVA_HOME=/home/work/elk/elasticsearch-7.6.2/jdk export PATH=$JAVA_HOME/bin:$PATH
安装Kibana
下载地址:https://www.elastic.co/cn/downloads/kibana
我这里下载的是:kibana-7.6.2-linux-x86_64.tar.gz
解压运行即可
# 解压
tar -xvf kibana-7.6.2-linux-x86_64.tar.gz
# 运行,让进程后台运行
nohup ./bin/kibana&默认 Kibana 监听的是 127.0.0.1 这个 ip 的,也就是只能通过 http://127.0.0.1:5601 来进行访问,这里可以通过配置 Nginx 来转发,或者修改 Kibana 配置:
vim kibana-7.6.2-linux-x86_64/config/kibana.yml
# 将 server.host 前面的注释打开,然后值改为 0.0.0.0 ,这样任何ip就可以访问了(线上不要轻易这样设置)。
server.host: 0.0.0.0在 Kibana 下 Dev Tools 下可以执行 HTTP 请求来查看 ES 的状态。
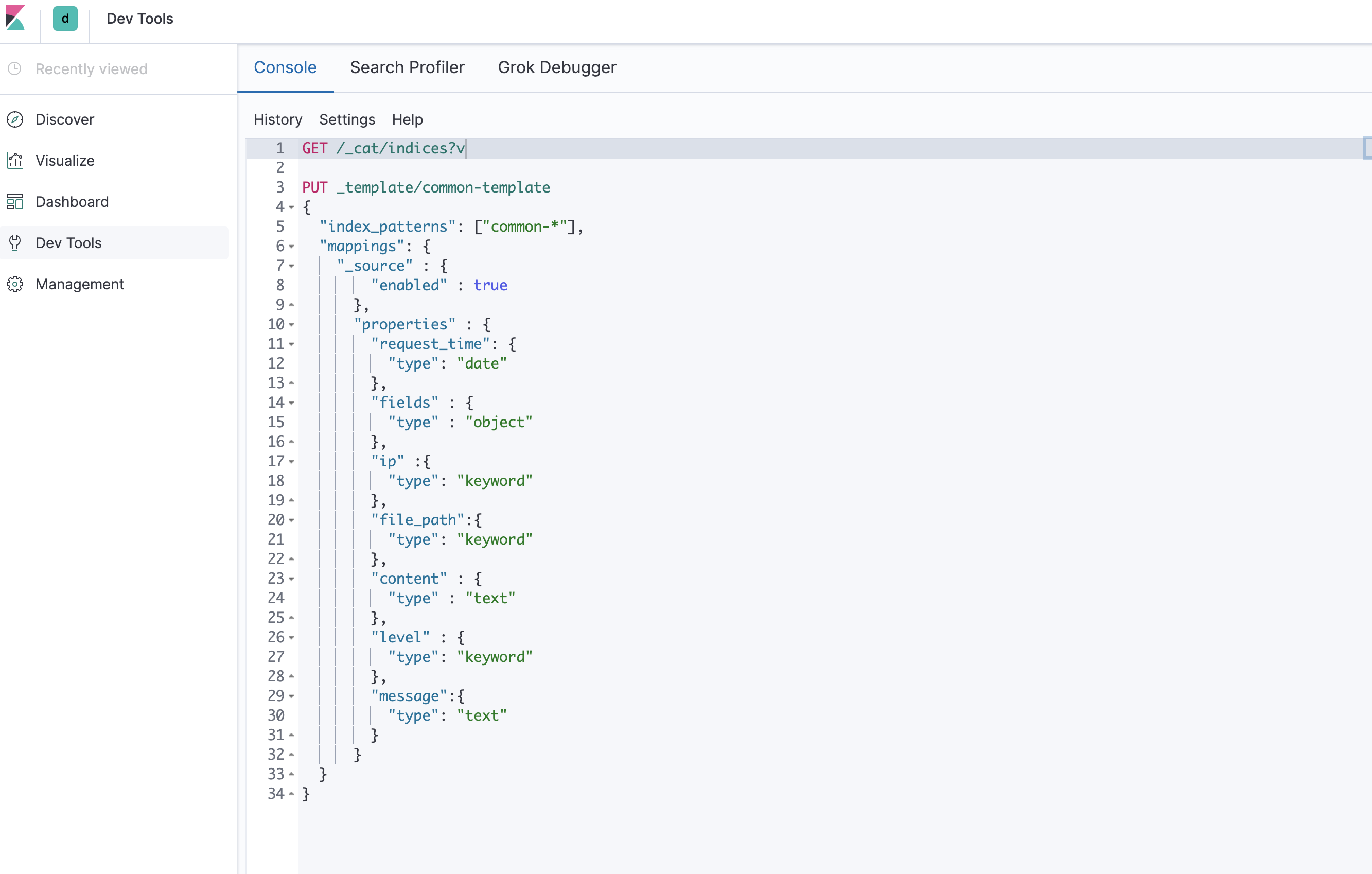
// 查看 ES 状态
GET /_cat/indices?v
// 创建模板,这一步也可以不用,ES 会自动识别帮你创建 mapping
PUT _template/common-template
{
"index_patterns": ["common-*"], // 指定匹配的索引前缀,符合条件的会自动按照下面的 mapping 创建
"mappings": {
"_source" : {
"enabled" : true
},
"properties" : {
"request_time": { // 请求时间
"type": "date"
},
"fields" : {
"type" : "object"
},
"ip" :{ // 机器ip
"type": "keyword"
},
"file_path":{ // 日志路径
"type": "keyword"
},
"content" : { // 解析出来的内容
"type" : "text"
},
"level" : { // 日志等级
"type": "keyword"
},
"message":{// 原始日志内容,可以拿掉
"type": "text"
}
}
}
}安装Logstash
下载地址:https://www.elastic.co/cn/downloads/logstash
我这里下载的是:logstash-7.6.2.tar.gz
解压,然后这里要写自己的日志处理配置。
# 解压
tar -xvf logstash-7.6.2.tar.gz
# 运行
nohup bin/logstash -f common-pipeline.conf --config.reload.automatic &配置文件示例如下:
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "(?[0-9\-]{10}\s[0-9:]{8}([0-9.,]{4})?)\s+(?(DEBUG|INFO|WARN|ERROR))\s+(?.*)"}
}
date {
match => [ "request_time", "yyyy-MM-dd HH:mm:ss.SSS", "yyyy-MM-dd HH:mm:ss,SSS", "yyyy-MM-dd HH:mm:ss" ]
target => "request_time"
timezone => "+08:00"
}
if !([content]) {
mutate {
copy => { "message" => "content" }
copy => { "@timestamp" => "request_time"}
}
}
mutate {
rename => { "[log][file][path]" => "file_path" }
rename => { "[host][ip][0]" => "ip" }
remove_field => ["input","tags","ecs","agent","log","host","@version"]
}
}
output {
elasticsearch {
hosts => [ "127.0.0.1:9200" ]
index => "common-%{+yyyy.MM.dd}"
path => "/"
}
#stdout { codec => rubydebug }
} beats.port 是配置后面 Filebeat 收集数据发送到 Logstash 的端口。
grok.match 是 grok 来处理日志的(具体使用方式可以参考),Kibana 页面 Dev Tools 下有对应的调试界面。如下:
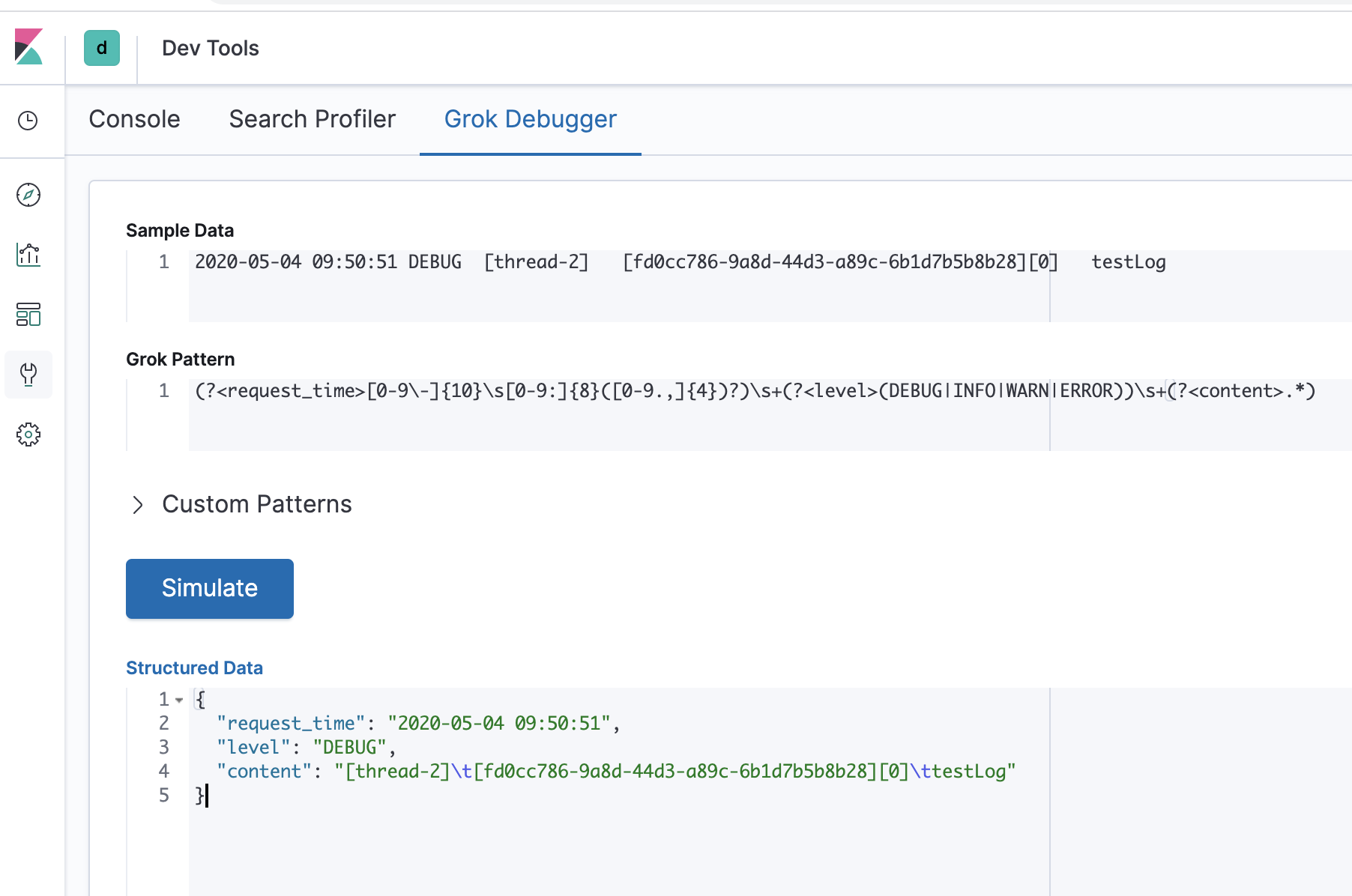
date.match 匹配时间,匹配完成后对时间添加 8 个小时,避免 Kibana 显示的时候由于时区问题差8个小时。
if !([content]) 这里对于有些不符合 grok 规则的日志 直接将原始内容复制给 content 字段,时间也取日志收集的时间。
mutate 可以对一些字段进行重命名,丢弃。
output 配置输出方式,下面的 stdout 在调试的时候使用,调试完可以注释掉
安装Filebeat
下载地址:https://www.elastic.co/cn/downloads/beats/filebeat
我这里下载的是:filebeat-7.6.2-linux-x86_64.tar.gz
解压,运行
# 解压
tar -xvf filebeat-7.6.2-linux-x86_64.tar.gz
# 运行
nohup ./filebeat-7.6.2-linux-x86_64/filebeat &修改 Filebeat 配置
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/a.log
fields:
yun_cluster: ${Cluster:""}
multiline.pattern: '^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:'
multiline.negate: false
multiline.match: after
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
output.logstash:
hosts: ["127.0.0.1:5044"]
processors:
- add_host_metadata:
netinfo.enabled: true
cache.ttl: 5mfields 下的 yun_cluster,取值是从环境变量 Cluster 中取,如果没有的话默认给空字符串,这个可以根据自己需求修改。
Exception in thread "main" java.lang.IllegalStateException: A book has a null property
at com.example.myproject.Author.getBookIds(Author.java:38)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
Caused by: java.lang.NullPointerException
at com.example.myproject.Book.getId(Book.java:22)
at com.example.myproject.Author.getBookIds(Author.java:35)
... 1 more