【Knative系列】看完这篇还不懂 Knative Serving,你来打我~(史上最详细)
本文主要讲解 Knative serving 系统及组件:
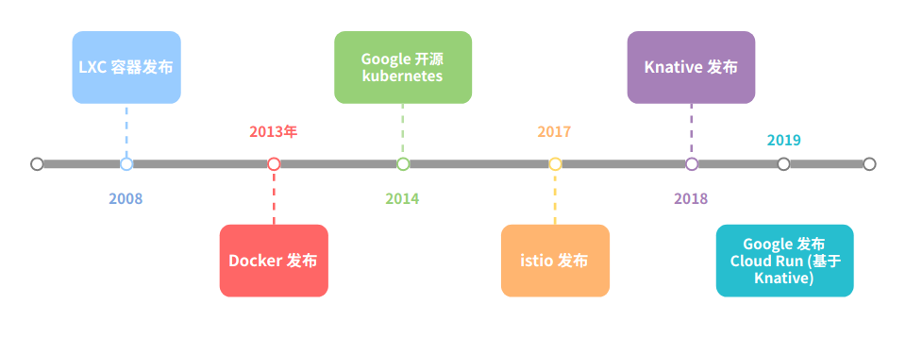
发展历程
Knative 是谷歌开源的 serverless 架构方案,旨在提供一套简单易用的 serverless 方案,把 serverless 标准化。目前参与的公司主要是 Google、Pivotal、IBM、Red Hat,2018年7月24日才刚刚对外发布,当前还处于快速发展的阶段(3.4k star, 3.3k issue)。
Knative 包含 build(已被tekton取代),serving,event三个部分,本文主要介绍serving。
先看下Knative的发展里历程
前言 有了 ”k8s,为什么还要 knative”
通常情况下 Serverless = Faas + Baas,Faas 无状态(业务逻辑),Baas 有状态(通用服务:数据库,认证,消息队列)。
既然有了 k8s (paas), 为什么还需要 Knative (Serverless),下面从四个方面来进行解释:资源利用率,弹性伸缩,按比例灰度发布,用户运维复杂性
1. 资源利用率
讲资源利用率之前先看下下面两个应用,左边应用 A 这个是典型的中长尾应用,中长尾应用就是那些每天大部分时间都没有流量或者有很少流量的应用。
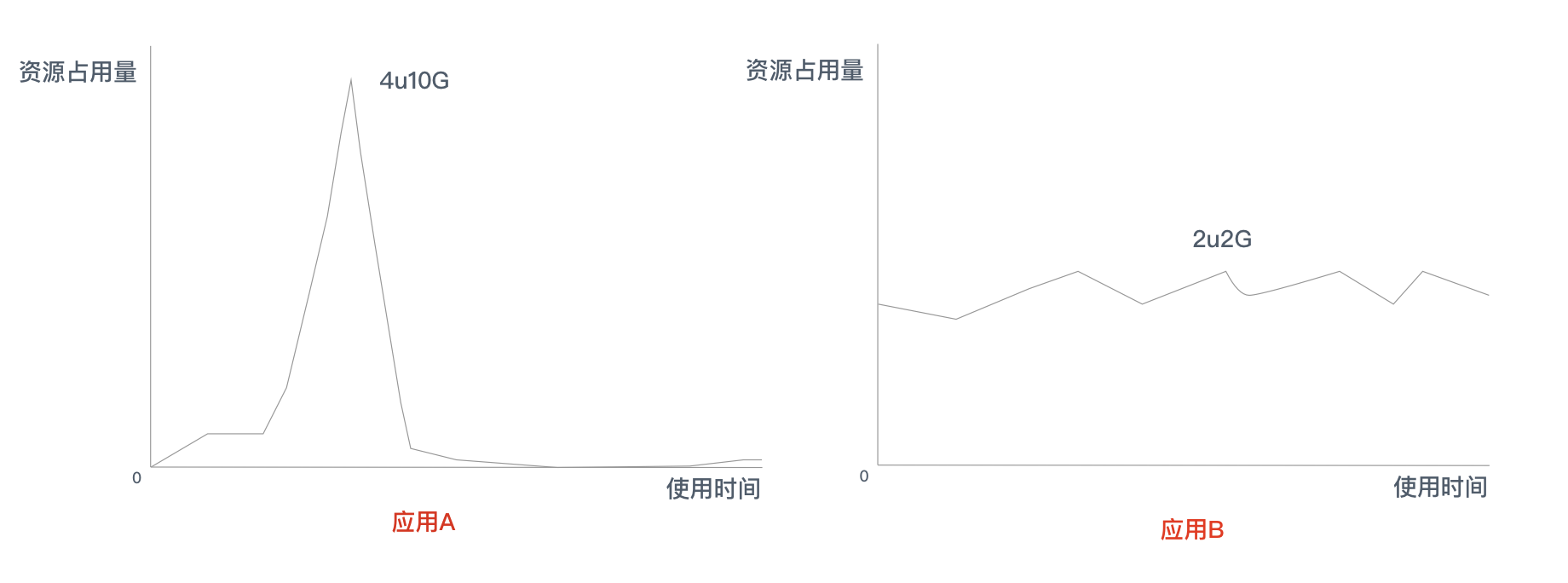
想一下,如果用 来实现的话,对于应用 A,需按照资源占用的资源最高点来申请规格,也就是 4U10G, 而且 paas 最低实例数**>=1**, 长此以往, 当中长尾应用足够多时,资源利用率可想而知。有可能会出现 大部分边缘集群资源被预占,但是利用率却很低。
而 Knative,恰恰可以解决应用A的资源占用问题,因为 Knative 可以将实例缩容为0,并根据请求自动扩缩容,缩容到零可以大大增加集群的资源利用率,因为中长尾应用都是按需所取,不会过度空占用资源。
比较合理的是对应应用A 用 ,对于应用 B 用
2. 弹性伸缩
大家可能会想到,k8s 也有 hpa 进行扩缩容,但是 Knative 的 kpa 和 k8s 的 hpa 有很大的不同:
• Knative 支持缩容到 0 和从 0 启动,反应更迅速适合流量突发场景;
• K8s HPA 不支持缩容到 0 ,反应比较保守
具体比较如下

3. 按比例灰度发布
设想一下,假如通过 k8s来进行灰度发布怎么做,只能是通过两个Deployment和两个service,如果灰度升级的话只能通过修改两个 Deployment 的rs,一个逐渐增加,一个逐渐减少,如果想要按照百分比灰度,只能在外部负载均衡做文章,所以要想 Kubernetes 原生实现,至少需要一个按流量分发的网关,两个 service,两个 deployment ,两个 ingress , hpa,prometheus 等,实现起来相当复杂。
使用 Knative 就可以很简单的实现,只需一个 ksvc 即可
4. 用户运维复杂性
使用 Knative 免运维,低成本:用户只关心业务逻辑,由工具和云去管理资源,复杂性由平台去做:容器镜像构建,Pod 的管控,服务的发布,相关的运维等。
k8s 本质上还是基础设施的抽象,对应pod的管控,服务的发布,镜像的构建等等需要上层的包装。
1. 相关概念介绍
资源介绍: knative 资源
1.
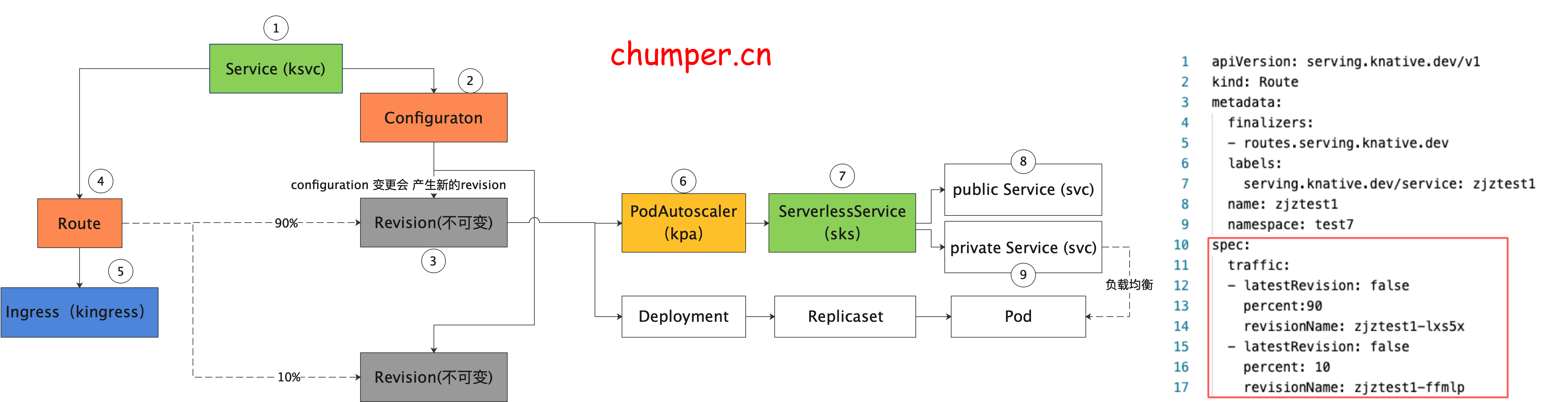
ksvc 是 Knative 中 最顶层的 CR 资源,用于定义 Knative 应用 ,包含镜像以及 traffic 百分比等等(本例配了 两个版本,流量百分比是 10%,90%), 可以接管 route 和 configuration 的配置
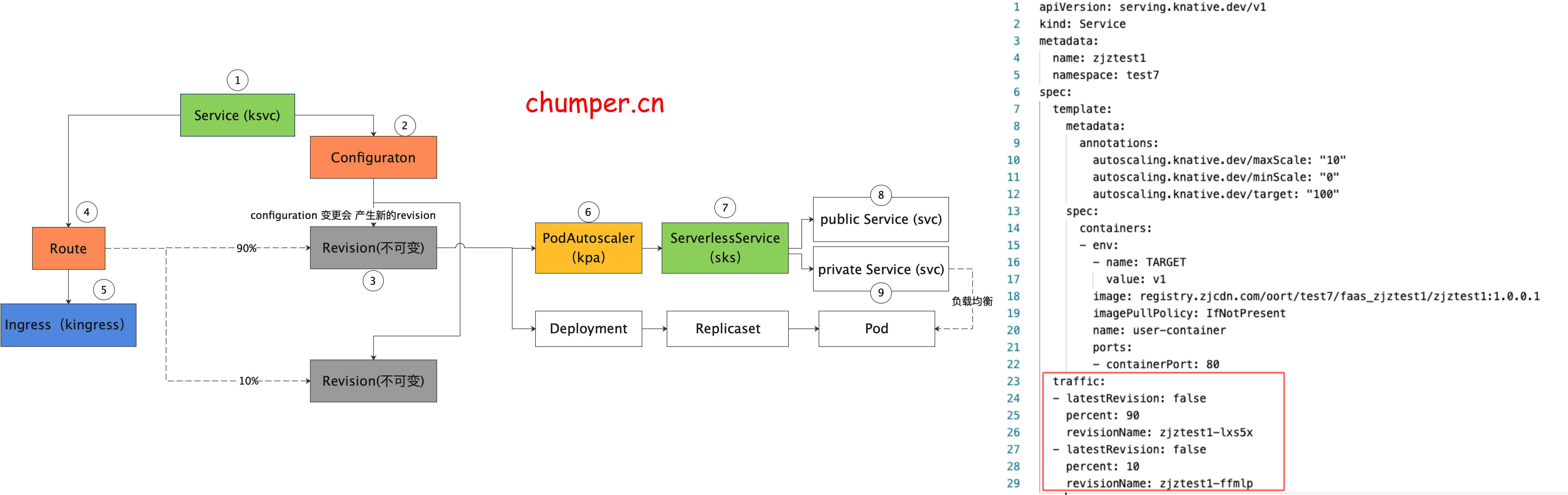
2.
configuration 是 Knative 应用的最新配置,也就是应用目前期望的状态。configuration 更改会产生快照 revision
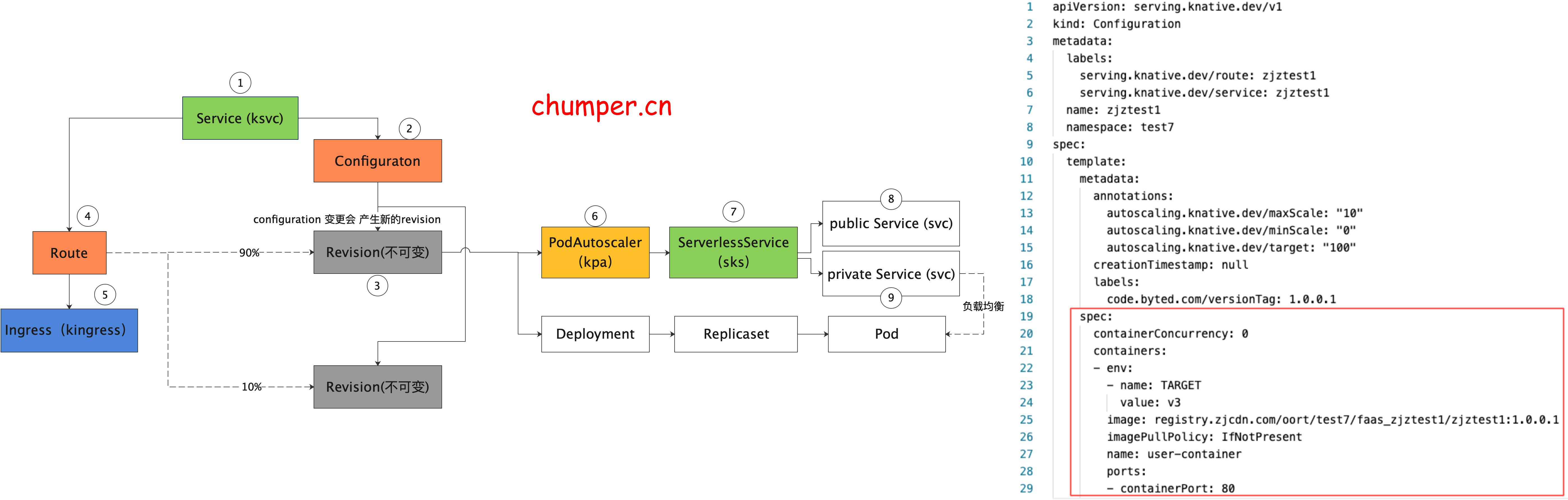
3.
revision 是 Knative 应用的快照,Knative 的设计理念中 revision 是不可更改的,可以看做是 git 的 历史 commit 记录
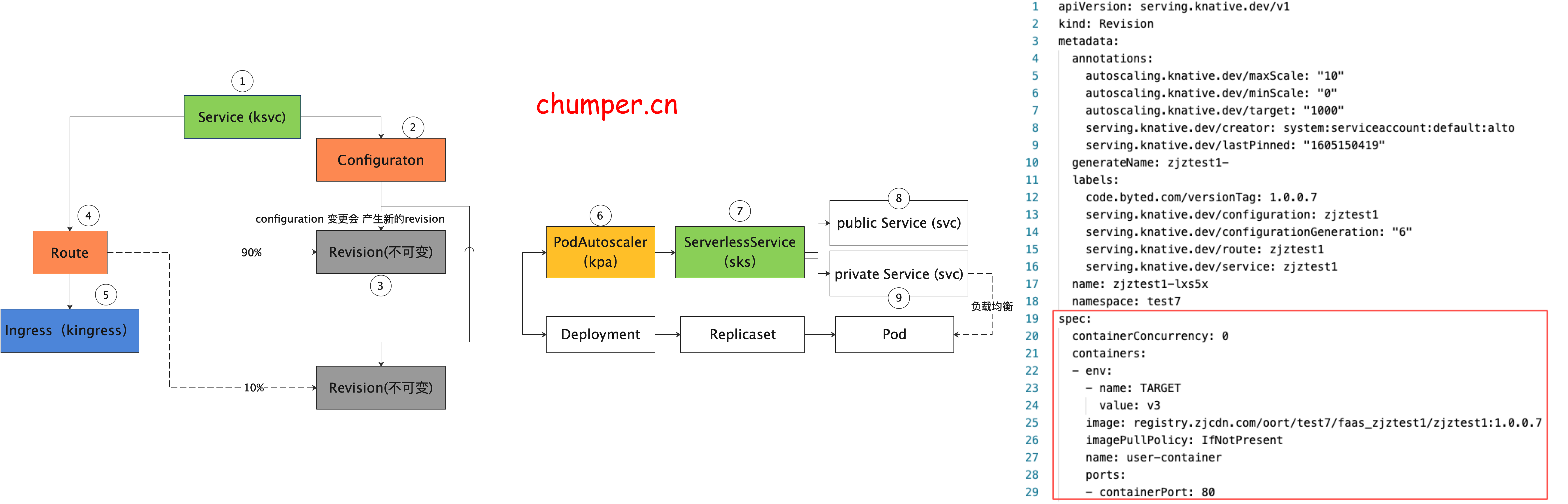
4.
route 是 Knative 蓝绿发布,金丝雀发布的关键,用于声明不同版本之间流量的百分比。
5.
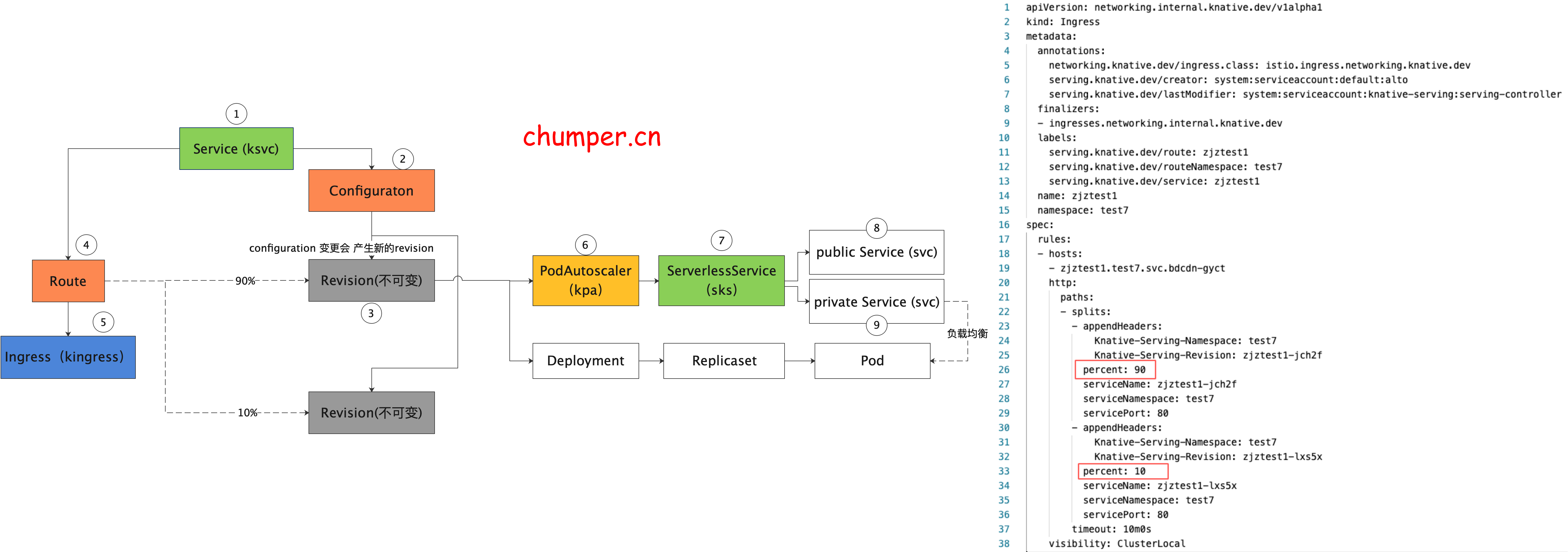
Knative 的流量入口网关 是通过 kingress 抽象的。详情可以看第二节 Knative 网关
6.
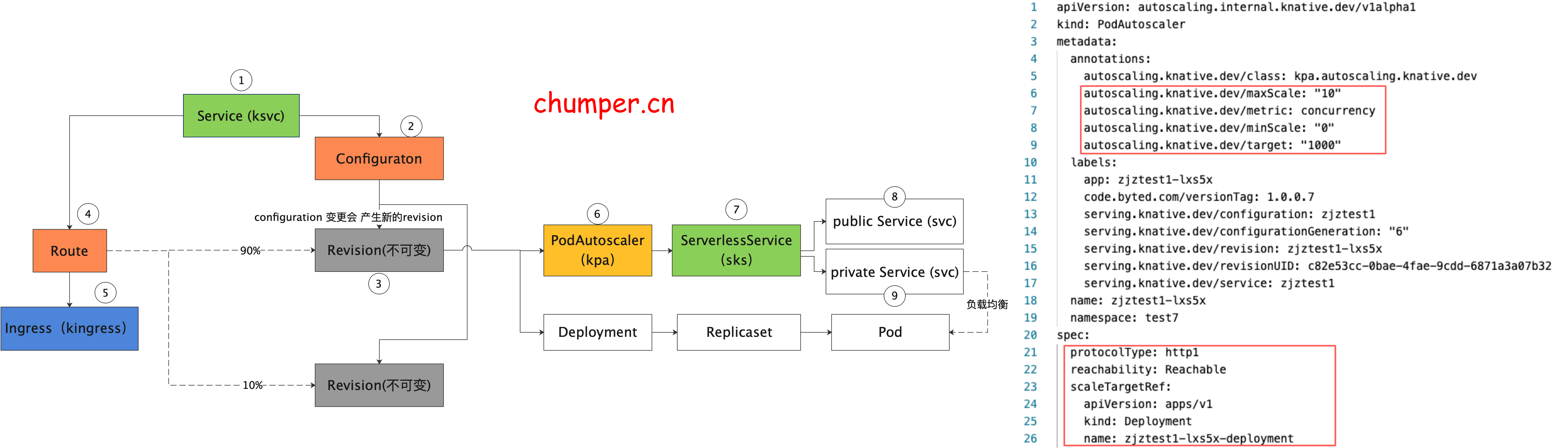
7.
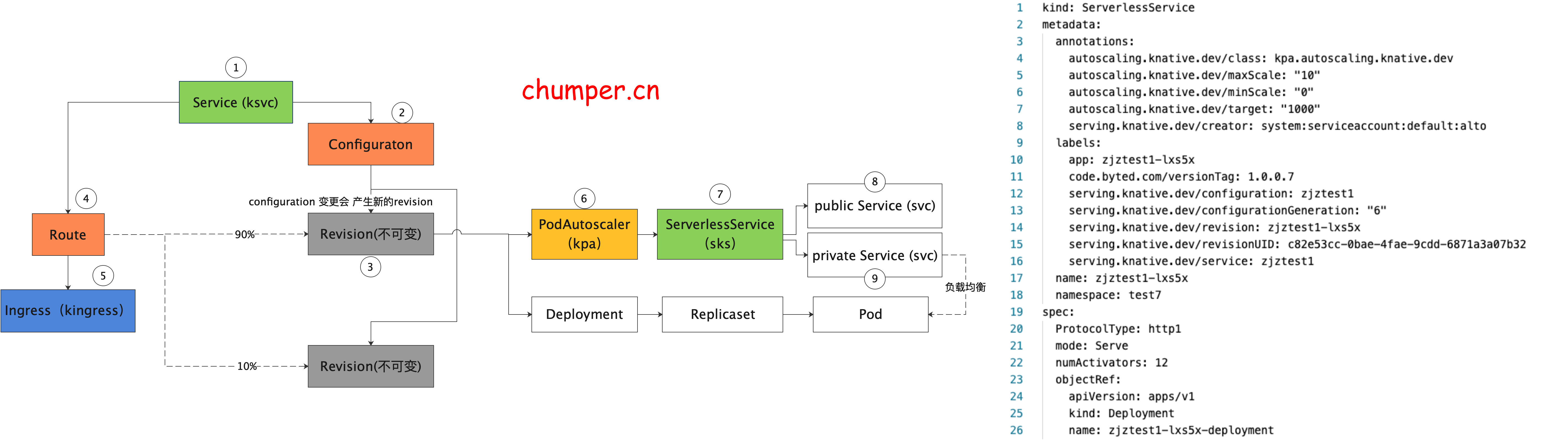
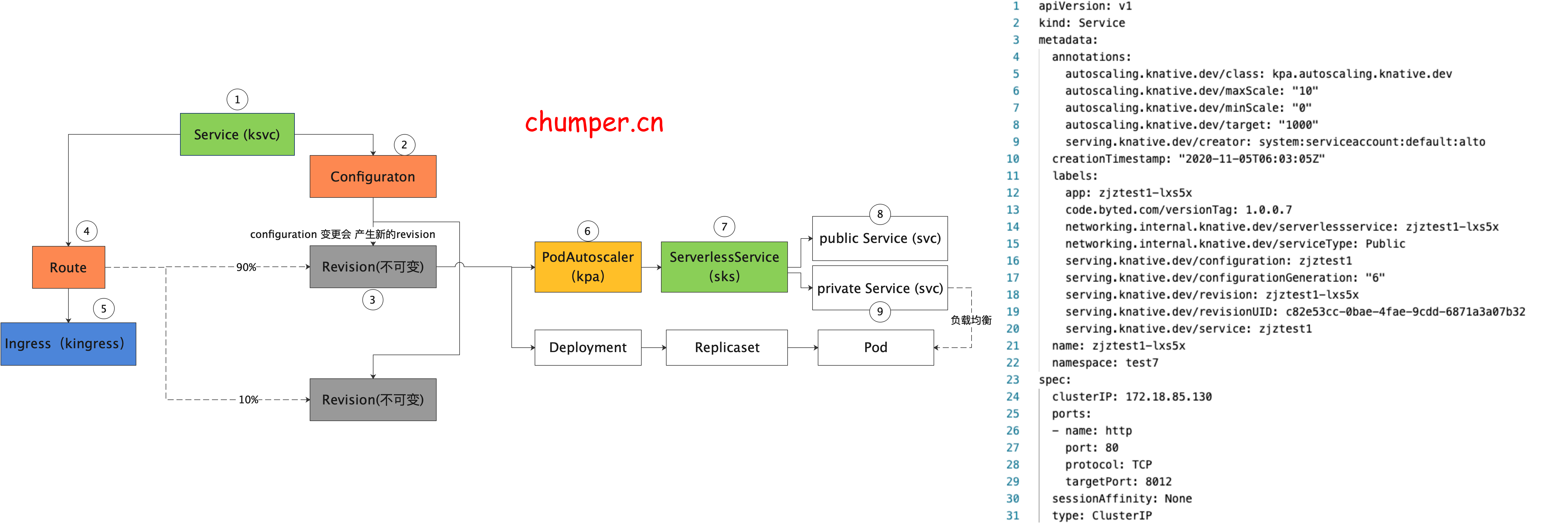
8.
注意,此处的 k8s service 没有 label selector,说明这个 service 的后端 endpoint 不是由 k8s 自动控制的,实际上这个 svc 的后端 endpoint 是 由 knative 自己来控制的,(是取 activator 的pod ip 还是 服务真实实例的pod ip)
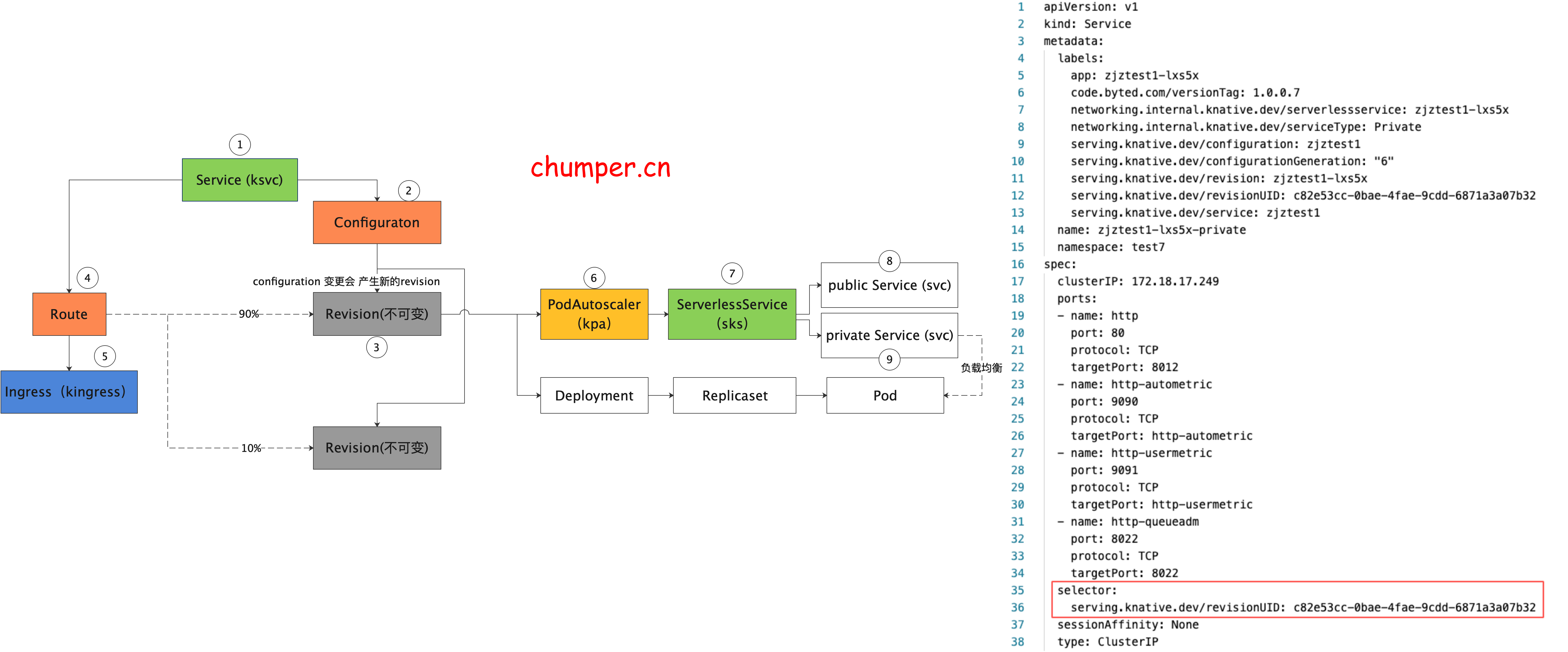
9.
private 类型 的 svc 不同于 public 类型的 svc,这个 svc 是通过label selector 来筛选后端 endpoint 的,这里后端指向的永远是 服务真实实例的 pod ip
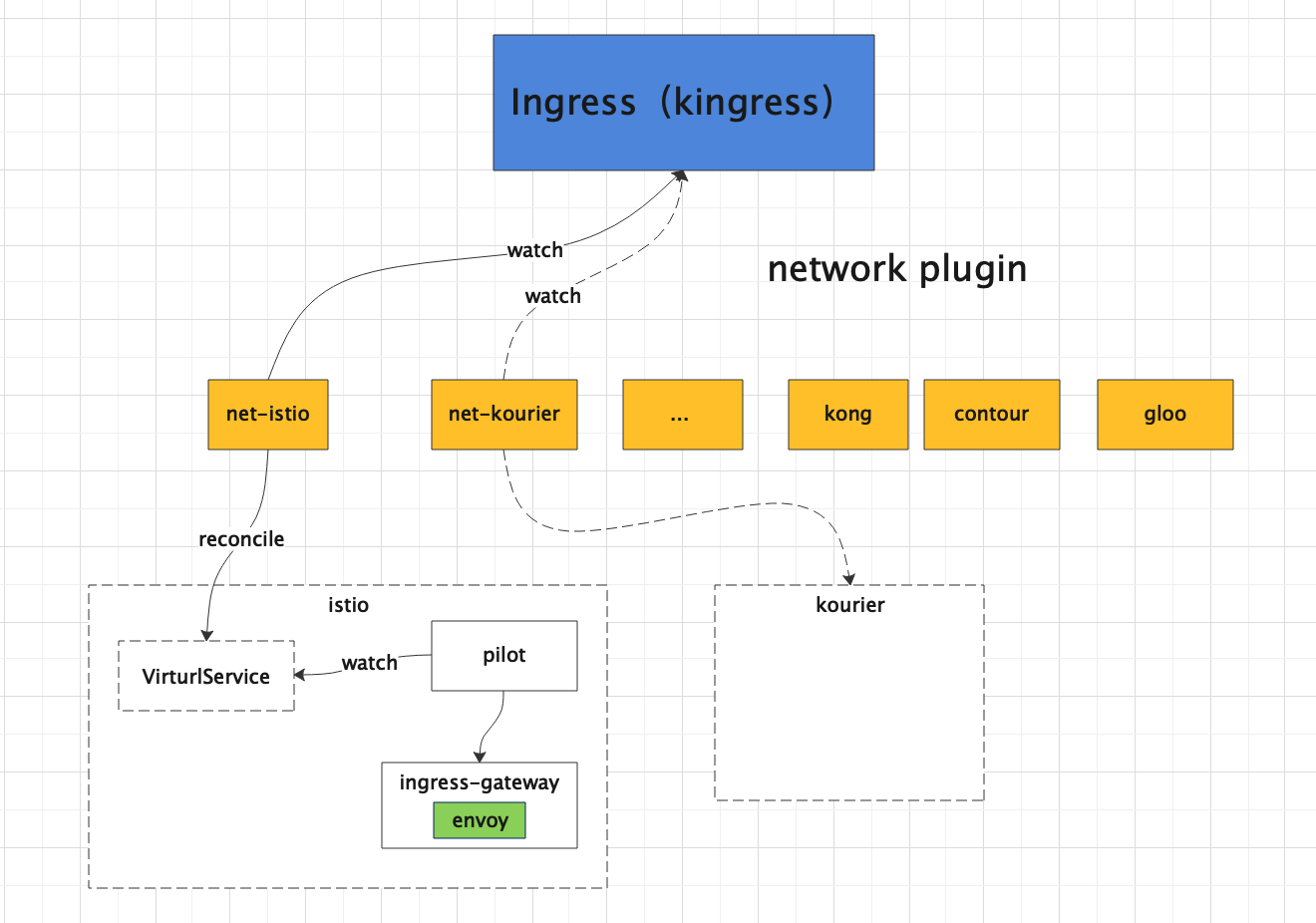
2. Knative 网关
Knative 从设计之初就考虑到了其扩展性,通过抽象出来 Knative Ingress (kingress)资源来对接不同的网络扩展:Ambassador、Contour、Gloo、Istio、Kong、Kourier
这些网络插件都是基于 Envoy 这个新生的云原生服务代理,关键特性是可以基于流量百分比进行分流。
感兴趣的可以研究下 https://www.servicemesher.com/envoy/intro/what_is_envoy.html
3. Knative 组件
1. Queue-proxy
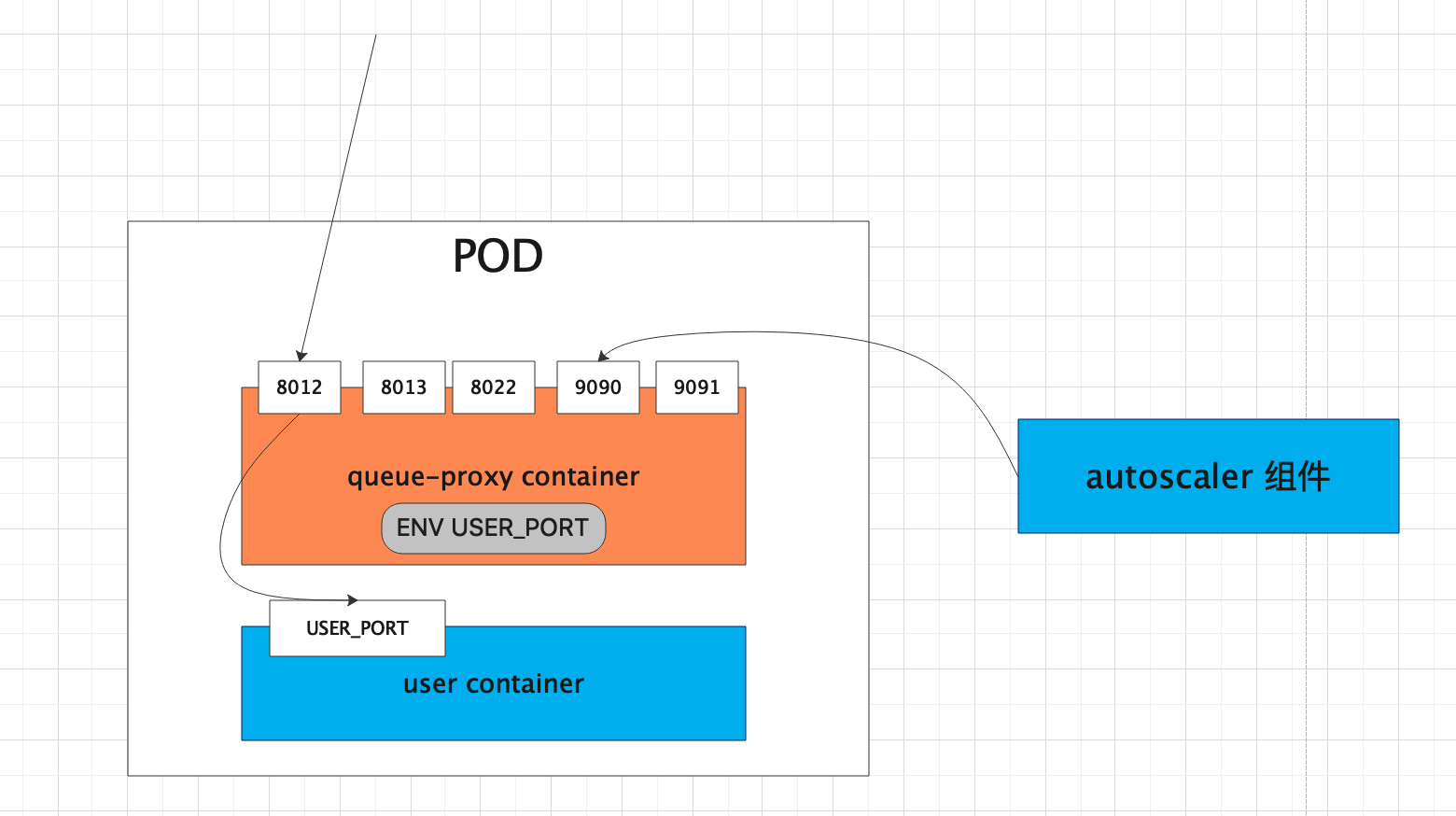
Queue-proxy 是每个业务 pod 中都存在的 sidecar,每个发到业务pod的请求都会先经过 queue-proxy
queue-proxy 的主要作用是 收集和限制 业务应用的并发量,比如当一个 revision 设定了并发量为 5 ,那么 queue-proxy 会保证每次到达业务容器的请求数不会大于 5. 如果多于 5 个请求到达,queue-proxy 会将请求暂存在本地队列中。
几个端口表示如下:
• 8012, queue-proxy 代理的http端口,流量的入口都会到 8012• 8013, http2 端口,用于grpc流量的转发• 8022, queue-proxy 管理端口,如健康检查• 9090, queue-proxy的监控端口,暴露指标供 autoscaler 采集,用于kpa扩缩容• 9091, prometheus 应用监控指标(请求数,响应时长等)• USER_PORT, 是用户配置的容器端口,即业务实际暴露的服务端口,ksvc container port 配置的
2. Autoscaller
AutoScaller 主要是 Knative 的扩缩容实现,通过request指标来决定是否扩缩容实例,指标来源有两个:
• 通过获取每个 pod queue-proxy 中的指标• Activator 通过 websocket 主动上报
扩缩容算法如下:
autoscaler 是基于每个 Pod(并发)的运行中请求的平均数量。系统的默认目标并发性为 100,但是我们为服务使用了 10。我们为服务加载了 50 个并发请求,因此自动缩放器创建了 5 个容器( 50 个并发请求/目标 10 = 5 个容器)。
算法中有两种模式,分别是 panic 和 stable 模式,一个是短时间,一个是长时间,为了解决短时间内请求突增的场景,需要快速扩容。
Stable Mode(稳定模式)
在稳定模式下,Autoscaler 根据每个pod期望的并发来调整Deployment的副本个数。根据每个pod在60秒窗口内的平均并发来计算,而不是根据现有副本个数计算,因为pod的数量增加和pod变为可服务和提供指标数据有一定时间间隔。
Panic Mode (恐慌模式)
KPA会在 60 秒的窗口内计算平均并发性,因此系统需要一分钟时间才能稳定在所需的并发性级别。但是,自动缩放器还会计算一个 6秒 的紧急窗口,如果该窗口达到目标并发性的 2 倍,它将进入紧急模式。在紧急模式下,自动缩放器在较短,更敏感的紧急窗口上运行。一旦在 60 s秒内不再满足紧急情况,autoscaler 将返回到最初的 60 秒稳定窗口。

3. Activator
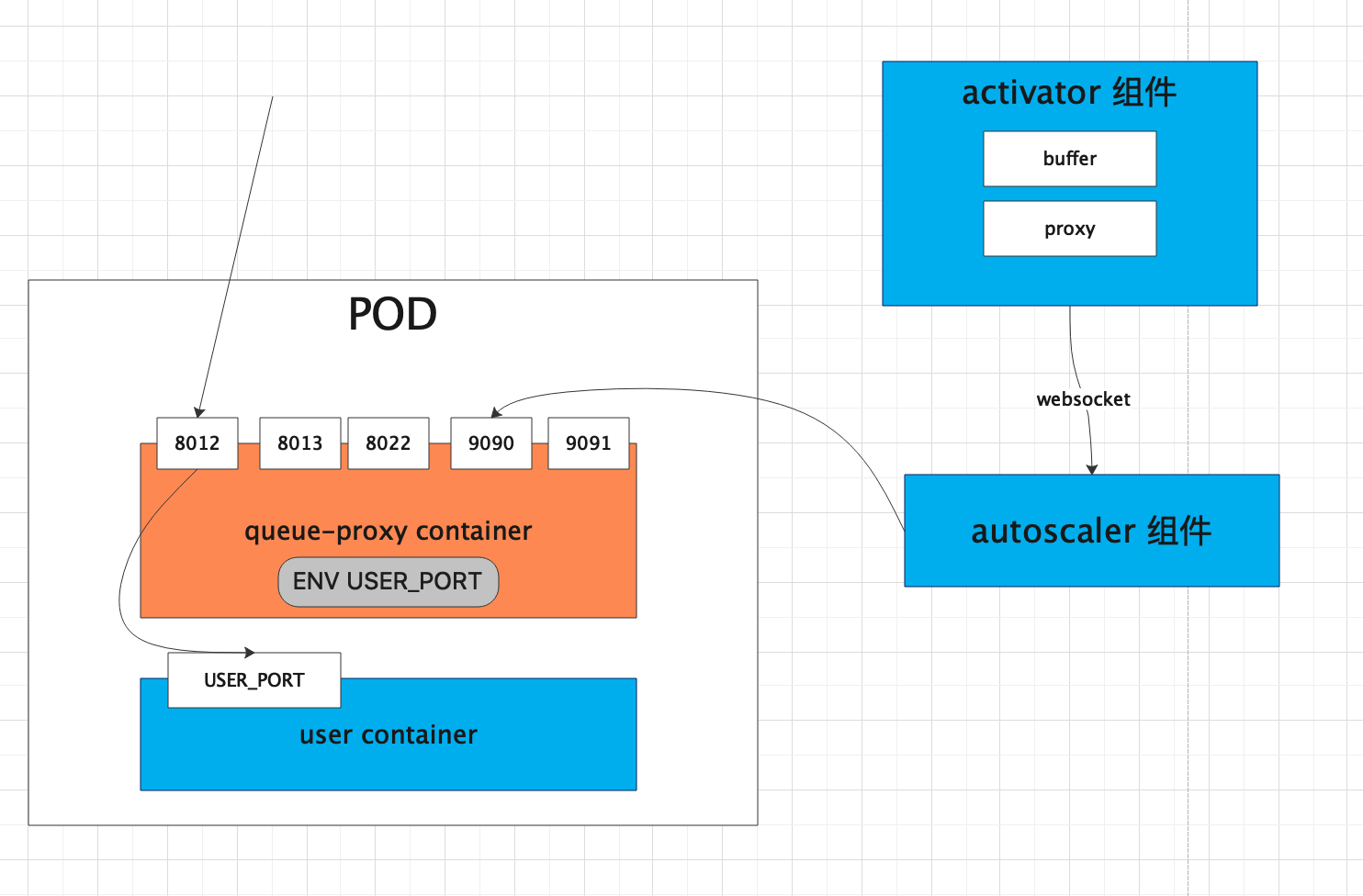
Activator 的作用:流量的负载和缓存,是Knative能缩容到 0 的关键
实例为0 时(冷启动),流量会先转发到 Activator,由 Activator 通过 websocket 主动触发 Autoscaler 扩缩容。
Activator 本身的扩缩容通过 hpa 实现
root@admin03.gyct:~# kubectl get hpa -n knative-serving
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
activator Deployment/activator 8%/100% 1 20 1 73d
可以看到 Activator 默认最大可以扩缩容到 20
Activator 只在 冷启动阶段是 proxy 模式,当当实例足够时,autoscaler 会更新 public service 的endpoints 指向 revision对应的pod,将请求导向真正的后端,这时候处理请求过程中 activator 不在起作用
详细步骤如下:
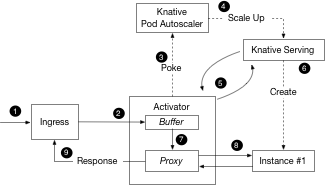
冷启动时 activator 的角色
4. 扩缩容原理
1. 正常扩缩容场景(非 0 实例)
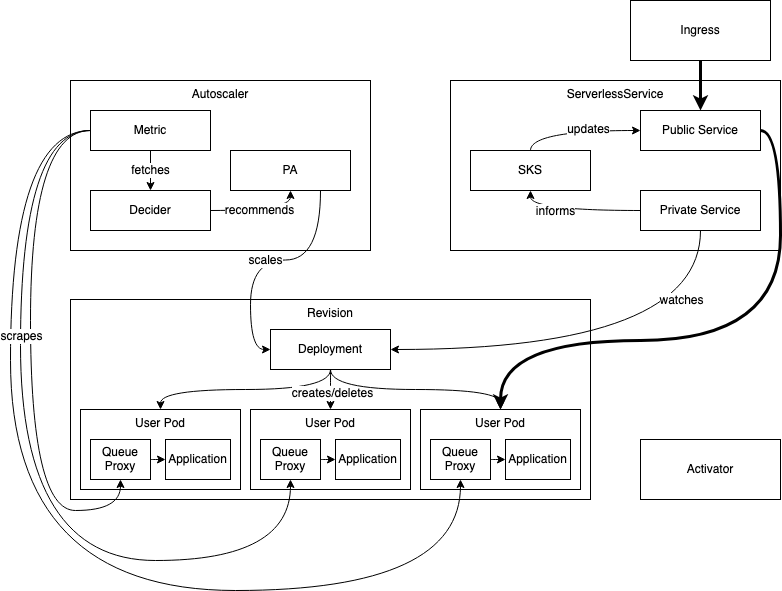
稳定状态下的工作流程如下:
2. 缩容到 0 的场景
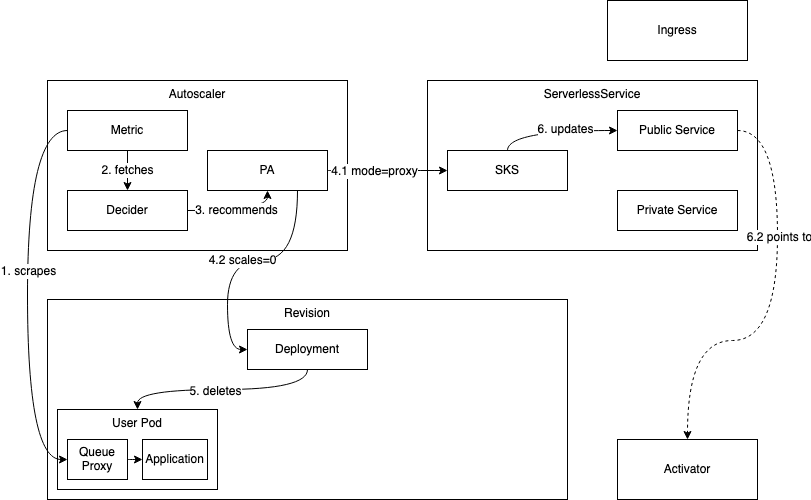
缩容到零过程的工作流程如下:
3. 从 0 启动的场景
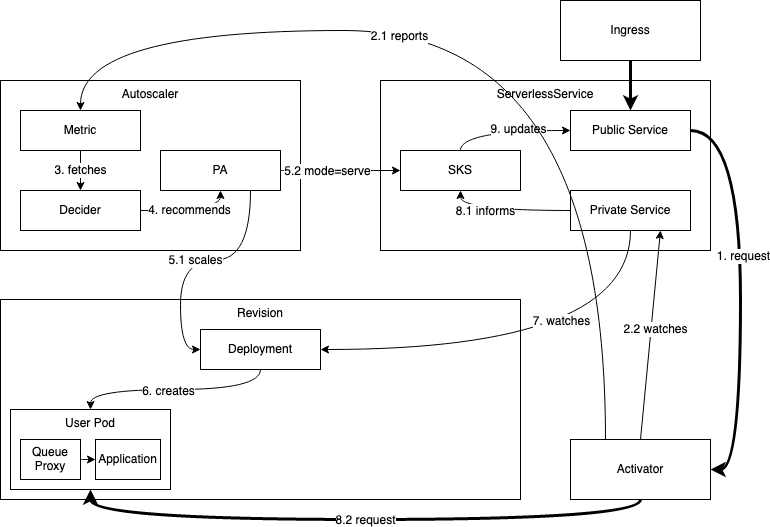
冷启动过程的工作流程如下:
当 revision 缩容到零之后,此时如果有请求进来,则系统需要扩容。因为 SKS 在 proxy 模式,流量会直接请求到 Activator 。Activator 会统计请求量并将 指标主动上报到 Autoscaler, 同时 Activator 会缓存请求,并 watch SKS 的 private service, 直到 private service 对应的endpoints产生。
Autoscaler 收到 Activator 发送的指标后,会立即启动扩容的逻辑。这个过程的得出的结论是至少一个Pod要被创造出来,AutoScaler 会修改 revision 对应 Deployment 的副本数为为N(N>0),AutoScaler 同时会将 SKS 的状态置为 serve 模式,流量会直接到导到 revision 对应的 pod上。
Activator 最终会监测到 private service 对应的endpoints的产生,并对 endpoints 进行健康检查。健康检查通过后,Activator 会将之前缓存的请求转发到健康的实例上。
最终 revison 完成了冷启动(从零扩容)。