批注MYSQL开发规范,助你了解其背后的“道”
无论做软件开发的菜鸟还是老司机,都不可避免的要和数据库打交道,对sql规范都不陌生。特别是阿里的Mysql开发规范,不少公司特别是电商公司,以此为基础定义了自己的数据库开发规范,对于这些大家或多或少都能侃侃而谈。进一步追问一下为什么要这么定义?不少人都一脸茫然,这不就是规范吗,遵守就行。其实不然,老子《道德经》有云:道生一,一生二,二生三,三生万物,可见事务都是千变万化的,不解其“道”,永远都处于被动状态,现在被一块方形的石头绊倒,后面还会不停的被别的形状的石头绊倒,非聪明人所为也。下面通过两部分介绍,助大家理解这些规范背后的“道”。
时间影响
批注:上面列举的一些的sql规范相信大家都耳熟能详,都会导致TABLE ACCESS FULL即全表扫描。那到底是什么原因导致查询条件列上明明都加了索引,但是就是没起作用呢?本质上都可以归结为索引的左匹配命中原则,可以从索引的数据结构中窥探一二
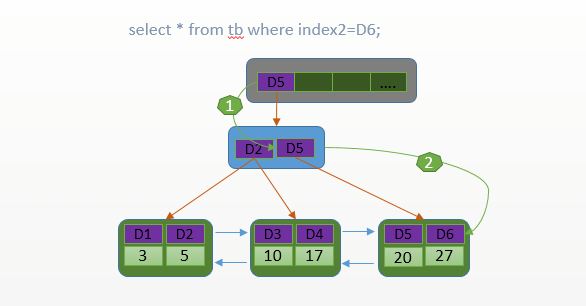
上面的B+树就是索引的数据结构,索引的命中的过程我们可以形象的看成一个数据筛选的过程,每一层的节点都是筛选模板。这是不是和现实生活中的水果分级有点像,第一层我们放一个直径10cm的模具,把10cm+的水果筛选出去,第二层再放一个8cm直径的模具,第三层6cm,这样很快就把水果按几个等级筛选出来了,如果硬要把水果带着包装盒去筛选,只能先去掉包装再和模具匹配,速度就可想而知了,筛选数据一样的原理。上面7种索引失效的场景,都是对表字段做了加工(运算,类型转换,隐式类型转换等等),导致每次和索引数据匹配都要做额外的工作,优化器也不傻啊,盘算下还不如全表扫描来的快,结果就可想而知了。
IO影响
批注:上面列的7条规范,更多的是推荐和建议。因为数据库中数据达不到一定的量级,正常情况下即使你不按建议去做,不会有任何问题,也就不会受到影响。但是一旦数据量级达到一定程度,上述规范对某些业务场景的影响很可能是致命的。至于为什么会这样,我们还是从Mysql的架构图入手,探究背后的根源。
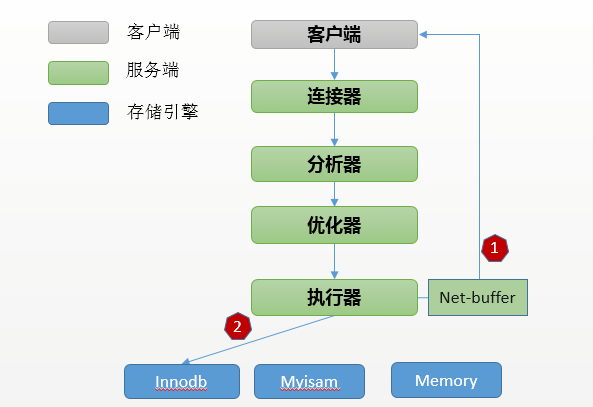
对IO的影响主要还是在执行器,从存储引擎获取数据,筛选出符合条件的数据集合再返回给客户端。上面提到的7条规范本质上都是对操作的数据的大小进行优化,也不难理解同样的服务器和网络带宽,传输10k数据的速度肯定比1M要快很多,也占用更少的资源和带宽。这么明显的道理摆在眼前了,聪明的你知道怎么操作了吧,那必然是业务需要5个字段,结果集决不会放10个返回。存储引擎取一次数据能返回需要的结果,何必无谓的多次执行。上面有就几条规范因一些特性,需要单独说明一下。
统计总数的sql,使用count(*)或者count(1)不要count具体列即使是主键id。Count列的特性是执行器从存储引擎获取到数据以后,还要判断是否有null值的,最终把统计列null值的过滤出去,count(*)或者count(1)则不存在。虽然计算的时间微不足道,但是放到亿级的表中就相当可观了。
Text和clob等大对象类型的数据,不要和其余业务数据一起查询。这些大对象类型数据往往都存长度很长的数据,innodb的一些特性,单个字段列超过767的长度都会用溢出页保存。道理很明显了,本来从一个篮子里可以拿到想要的东西,现在要多拿一次了。这类的数据都建议用另外的表单独存,取数据也做异步加载,用到再去查询。
查询考虑使用覆盖索引。InnoDB的一个特性,表的数据都存放在主键索引的叶子节点,普通索引的叶子节点都存在的是主键索引的值,走普通索引要取出数据就要有一个回表取数的过程,虽然innoDB对这块做了优化,可以多值或者缓存批量获取,覆盖索引可以完全免去回表,何乐而不为?