Greenplum内核源码分析-分布式事务(一)
目录
前言
一致性算法
Steal/Force和WAL协议
前言
Greenplum 公司是2003年成立的,在2010年被EMC公司收购。Greenplum是从开源的PostgreSQL二次开发出来的, 早期的Greenplum(version 3.x)是改写的Postgresql(version 8.0)。所以,我们能看到Greenplum用的基础架构都是来自PostgreSQL。 到了5.x版本,Greenplum基本到达了一个稳定的阶段,中间经历了十多年。Greenplum现在完全开源,而且也不停的在进步。 社区的策略是从PostgreSQL上游获取新的feature,经过小改动直接拿到Greenplum里面使用。目前主要维护的是6.x版本的Greenplum, 已经使用了Postgresql 9.4。从5.x到6.x,Greenplum不但把上游的PostgreSQL 换成了9.4,而且做了很多大的改动,算是一个很大的进步。
作者对Greenplum源码的分析会使用,读者可以去github上面自行获取。
一致性算法
目前主要的一致性算法包括: 2PC(两阶段提交), 3PC(三阶段提交) , Paxos和Raft。
2PC:Two-Phase Commit ( 二阶段提交 ) 分两个阶段,Prepare,Commit Prepare。
第一阶段提交事务请求(投票阶段),第二阶段:执行事务提交(执行阶段)。
算法优点是原理简单,实现方便。
缺点是有单点故障,会有同步阻塞,会出现数据不一致,脑裂。
协调者coordinator就是单点故障,如果协调者fail了,而且恢复不了,那么部分的参与者participants就再也不能把事务执行下去了。
对于参与者participants,当它发送了Yes Vote给协调者以后,就必须一直等待协调者发送Commit Prepare或者Rollback。中间这段过程是阻塞的。
尽管有缺点,绝大部分的分布式数据库都还是采用二阶段提交协议来完成分布式事务处理。
协调者 参与者
QUERY TO COMMIT
-------------------------------->
VOTE YES/NO prepare*/abort*
<-------------------------------
commit*/abort* COMMIT/ROLLBACK
-------------------------------->
ACKNOWLEDGMENT commit*/abort*
<--------------------------------
end3PC:Three- Phase Commit ( 三阶段提交 ) 有 Prepare、PreCommit、Commit Prepare 三个阶段。
与2PC相比,增加了PreCommit阶段。3PC想解决的问题是一种2PC里面的极端情况,就是协调者coordinator和有的参与者participants,同时fail。这时候剩下的参与者participants,就不知道自己该回滚还是强制commit了。
3PC和2PC相比,在参与者participants方面也加上了timeout。
当然,3PC也可能出现和2PC一样的情况,在最后一步也可能发生异常行为。所以也没有从根本上解决脑裂或者数据不一致的问题。只是将脑裂或者数据不一致的问题在一定的程度上缓解了。
Paxos算法的目标是让整个集群对某个变更达成一致。对于某个变更,当Proposer收到半数以上的回复,那么变更就被Accept。
Raft算法把Paxos算法理论清晰化,简明化了,还提供了伪代码。
Greenplum自己实现了2PC协议,后续的文章会结合内核源码深入分析。
Steal/Force和WAL协议
我们都知道Greenplum和PostgreSQL使用了MVCC技术,WAL(Write Ahead Log)技术,使用这个技术背后的原因是什么?数据库的事务提交,为什么最后的落盘是Xlog的提交,而不是数据本身的提交?
数据库里面有个著名的算法叫做ARIES算法(Algorithms for Recovery and Isolation Exploiting Semantics),这个算法描述了如何用WAL(Write Ahead Logging)协议和log来恢复crash掉的数据库。
这个定义来自维基,
"In computer science, Algorithms for Recovery and Isolation Exploiting Semantics, or ARIES is a recovery algorithm designed to work with a no-force, steal database approach;"。
上面的描述里面,什么又是no-force和steal呢?围绕下面的图解释下这些概念。
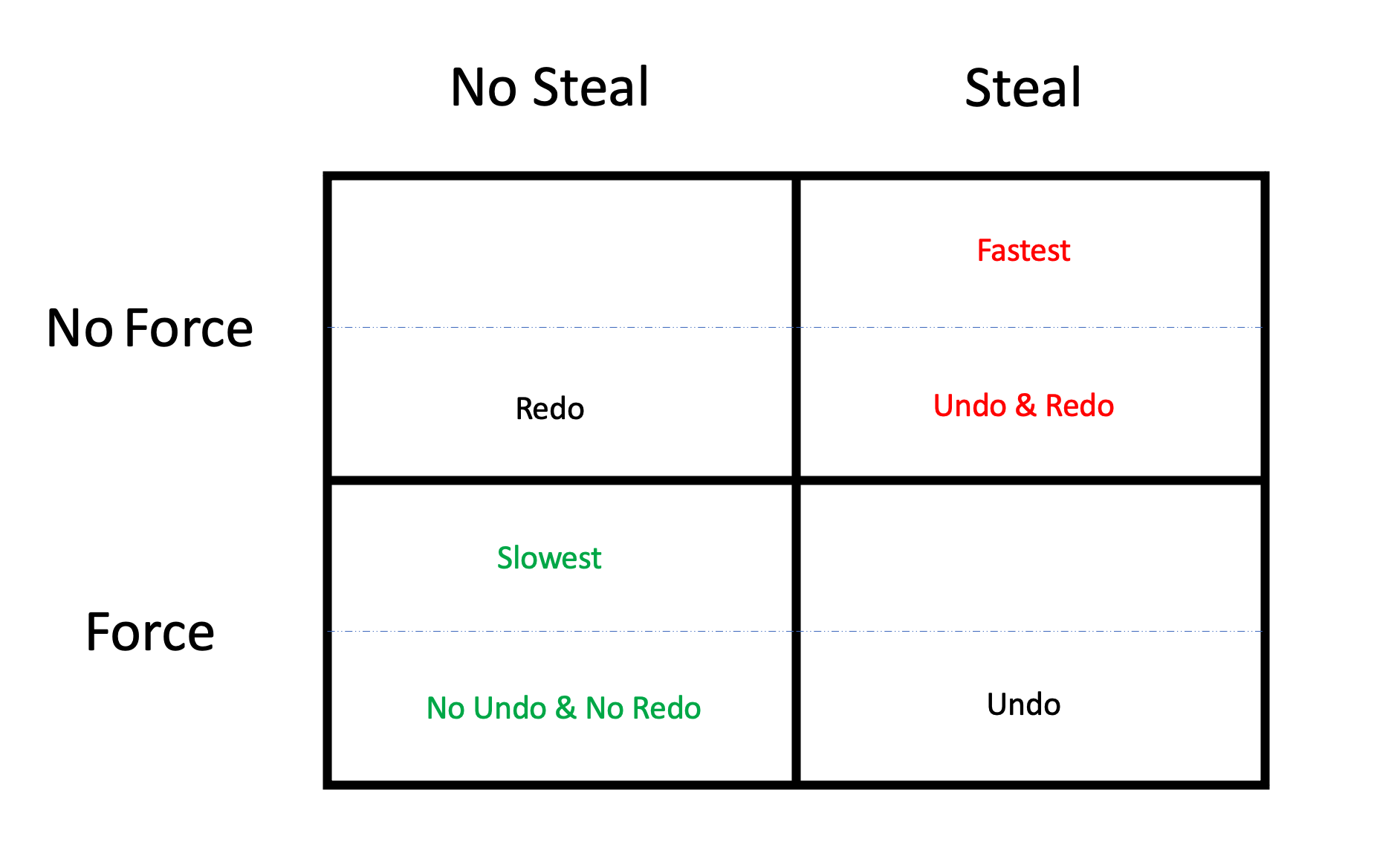
数据库的数据最终会存放在磁盘里,但是在事务进行的过程中,中间数据是要存放在内存的buffer里面的。 关于磁盘和内存buffer,或有甚者cpu的缓存,有方方面面的策略。这些策略,总体来说,无非是在速度和可靠性这两个方面取折衷。
steal和force就是在表述这样的策略问题。 那么有steal和force,就有no-steal和no-force。
结合上面的图,四个大方框代表四种策略组合。
steal: 对于未提交的事务,buffer里面被修改过的脏页面可以被刷回持久存储。
no-steal: 对于未提交的事务,buffer里面被修改过的脏页面不可以被刷回持久存储。
force: 在事务提交的时候,这个事务修改的数据页面强制被刷回持久存储。
no-force: 在事务提交的时候,这个事务修改的数据页面不需要强制刷回持久存储。从直观上看steal 和 force这两个策略很清楚,为了保证数据库的ACID的原则,我们在实现数据库的时候,肯定会使用force 和 no-steal 这个策略组合。
那为什么要提出来讲呢?因为我们的工程实现和理论不一样,会遇到种种问题。
force策略的问题: 每次提交都要把数据刷回持久存储,那么持久存储的访问会非常频繁,导致数据库性能低下。
no-steal策略的问题: 因为实际的数据库,系统的并发量有限,存储数据页面的buffer大小也是有限的。假设我们有一个很大的sql, 这个sql请求修改的页面把所有的buffer都占满了,但是这个sql一直不提交。那么其他的sql就无法进行了。
所以图上,Force & No Steal 对应的方框标示的是Slowest,代表使用这种策略组合的数据库运行执行效率是最低的。相反,它的对角线的方框代表的策略组合执行效率是最高的。
当然,还有另外一个考虑就是数据库在崩溃以后的recoevry恢复的效率,恢复效率和当前的运行执行效率是反过来的。以后有机会讲Greenplum数据库recovery的时候,再慢慢给大家讲。
上面的两个问题,是工程实现上向数据库提出的两个非常实际的问题。 那么怎么解决这样的问题呢?
工程上给出的答案是通过日志系统。
和摩尔定律一样,工程上面肯定是追求更高更快更强的策略的,所以选择的是图里面右上角的Fastest,也就是Steal & No Force策略组合。
Steal 对应一种叫做 undo log的日志文件,允许buffer里面被修改过的脏页面刷回持久存储,但是为了保证原子性,要先把 undo log写入日志文件中。 undo log里面记录了被修改的对象的旧值。
No Force 对应一种叫做 redo log的日志文件,在事务提交的时候,这个事务修改的数据页面不需要强制刷回持久存储,但是为了保证持久性, 要先把 redo log写入日志文件中。 redo log里面记录了被修改的对象的新值。
这样记录的日志怎么使用呢?
就是在系统崩溃的时候使用。根据系统崩溃的时间点不同,使用方式也不同。
对于undo log(它记录的是旧值),系统在任何时候发生崩溃,恢复时是对undo log日志从后往前扫描,对未提交的事务的日志做undo操作。 这样就可以撤销那些未提交事务的修改,保证数据恢复到原来的值。
对于redo log(它记录的是新值), 系统在任何时候发生崩溃,恢复时就对redo log日志从前往后扫描,对已提交的事务的日志做redo操作。 这样就可以把已经提交的事务恢复过来,保证数据变成新的值。
在使用的时候,把undo log和redo log的结合,既记录旧值,也记录新值。 恢复时,第一个阶段是分析阶段,第二个阶段是redo操作,第三个阶段是undo操作。
记录redo/undo log的日志,叫做WAL日志。它是按照WAL(Write Ahead Logging)协议开发的,这个协议提出来以后,工程实现还是会遇到各种问题, 比如恢复过程中的异常,checkpoint,并发控制等等,后来IBM DB2的研发人员提出了一种叫做 ARIES的恢复算法,这个算法提出来以后,才奠定了数据库按日志恢复的模型。
另外,数据库为了保证并发,都是用了 MVCC(Multi-Version Concurrency Control)技术,但是不同数据库实现MVCC是不一样的。
Greenplum/Postgresql 实现的MVCC,更新元组操作不是in-place update,而是重新创建tuple。是在相同的存储空间里另外创建一个新的tuple,把新值写到tuple里。 这样新值和久值都存储在一起,而且链接起来了。
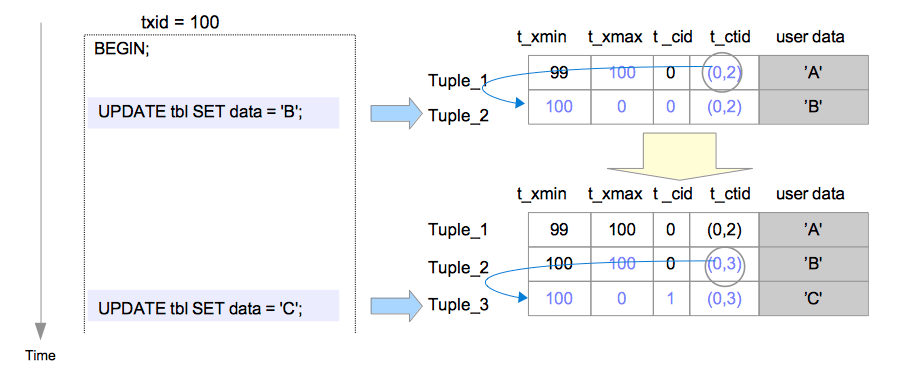
就是因为这样的特点,Greenplum/Postgresql不用记录undo log,而且做undo的时候,是很快的。因为当事务的扫描到一个tuple时,可以通过可见性的判断来决定这个tuple是否对当前的事务可见。
与Oracle/Mysql 比较,他们是有undo log段的,undo操作的时候,也需要控制并发等等,也需要用ARIES的恢复算法来实现。

参考文献
https://en.wikipedia.org/wiki/Two-phase_commit_protocol
https://en.wikipedia.org/wiki/Algorithms_for_Recovery_and_Isolation_Exploiting_Semantics