ScheduledThreadPoolExecutor源码解读(一)DelayedWorkQueue高度定制延迟阻塞优先工作队列
一、前言
继承自,所以其内部的数据结构和基本一样,并在其基础上增加了按时间调度执行任务的功能,分为延迟执行任务和周期性执行任务。
二、构造函数
的构造函数只能传3个参数、、,默认为。
工作队列是高度定制化的延迟阻塞队列,其实现原理和基本一样,核心数据结构是二叉最小堆的优先队列,队列满时会自动扩容,所以操作永远不会阻塞,也就用不上了,所以线程池中永远会保持至多有个工作线程正在运行。
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
三、DelayedWorkQueue延迟阻塞队列
1、基本架构
的实现原理中规中矩,内部维护了一个以类型数组实现的最小二叉堆,初始容量是16,使用和实现生产者和消费者模式。
static class DelayedWorkQueue extends AbstractQueue
implements BlockingQueue {
private static final int INITIAL_CAPACITY = 16;
private RunnableScheduledFuture[] queue =
new RunnableScheduledFuture[INITIAL_CAPACITY];
private final ReentrantLock lock = new ReentrantLock();
private int size = 0;
private Thread leader = null;
private final Condition available = lock.newCondition();
}
2、offer添加元素
提交任务时调用的是,而、等一些对外提供的添加元素的方法都调用了,其基本流程如下:
其作为生产者的入口,首先获取锁。
判断队列是否要满了(),满了就扩容。
队列未满,size+1。
判断添加的元素是否是第一个,是则不需要堆化。
添加的元素不是第一个,则需要堆化。
如果堆顶元素刚好是此时被添加的元素,则唤醒take线程消费。
最终释放锁。
public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture e = (RunnableScheduledFuture)x;
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = size;
if (i >= queue.length)
//扩容
grow();
size = i + 1;
if (i == 0) {
//如果是入的是第一个元素,不需要堆化
queue[0] = e;
setIndex(e, 0);
} else {
//堆化
siftUp(i, e);
}
if (queue[0] == e) {
//如果堆顶元素刚好是入队列的元素,则唤醒take
leader = null;
available.signal();
}
} finally {
lock.unlock();
}
return true;
}
如图为基本流程图:

(1)扩容grow
可以看到,当队列满时,不会阻塞等待,而是继续扩容。新容量在旧容量的基础上扩容50%(相当于)。最后,先根据创建一个新的空数组,然后将旧数组的数据复制到新数组中。
private void grow() {
int oldCapacity = queue.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // grow 50%
if (newCapacity < 0) // overflow
newCapacity = Integer.MAX_VALUE;
queue = Arrays.copyOf(queue, newCapacity);
}
(2)向上堆化siftUp
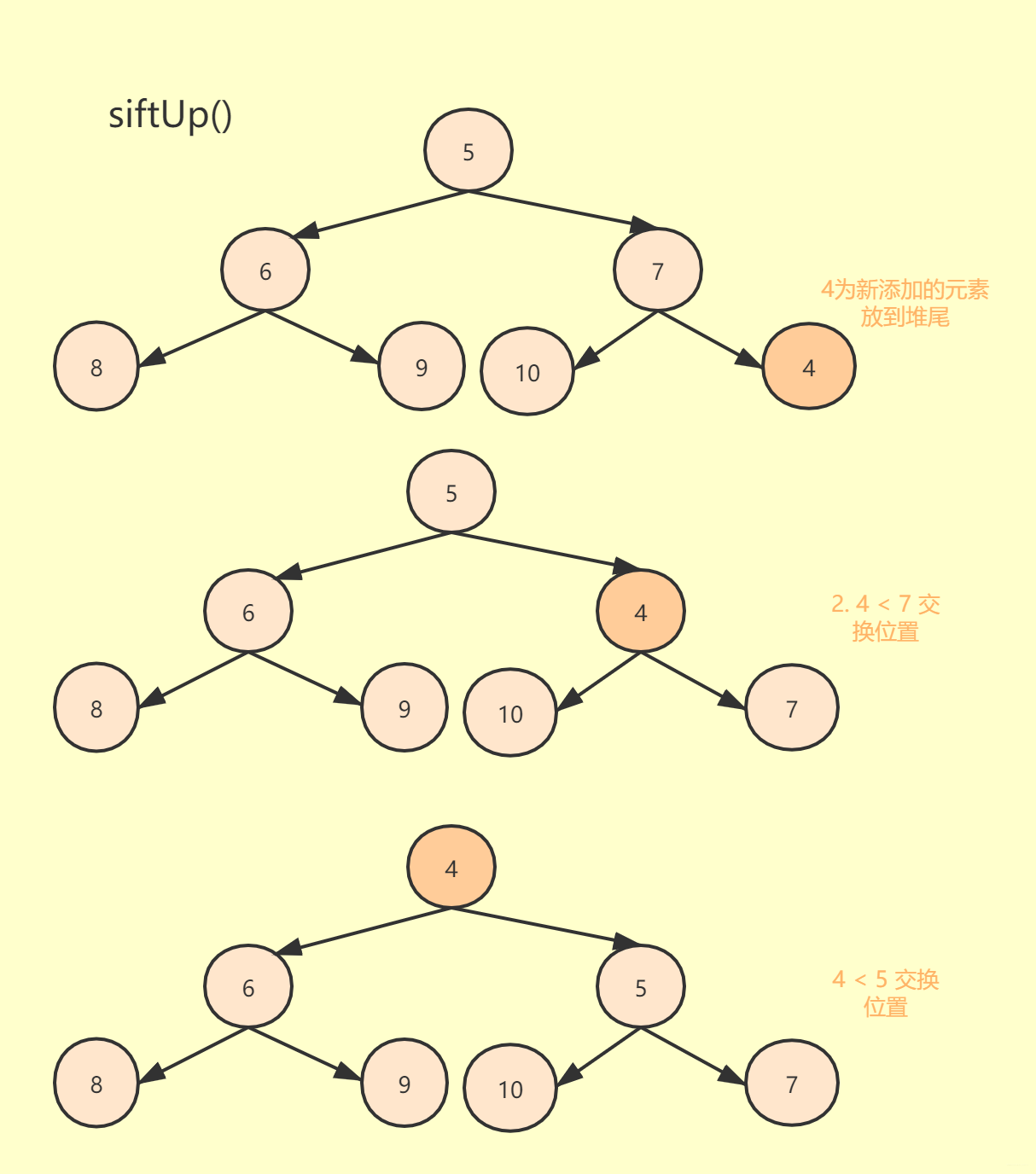
新添加的元素先会加到堆底,然后一步步和上面的父亲节点比较,若小于父亲节点则和父亲节点互换位置,循环比较直至大于父亲节点才结束循环。
private void siftUp(int k, RunnableScheduledFuture key) {
while (k > 0) {
//找到父亲节点
int parent = (k - 1) >>> 1;
RunnableScheduledFuture e = queue[parent];
if (key.compareTo(e) >= 0)
// 添加的元素 大于父亲节点,则结束循环
break;
//添加的元素小于父亲节点,则位置互换
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}
如下图为向上堆化过程图:
3、take消费元素
工作线程启动后就会循环消费工作队列中的元素,因为的,所以消费任务其只调用了。take基本流程如下:
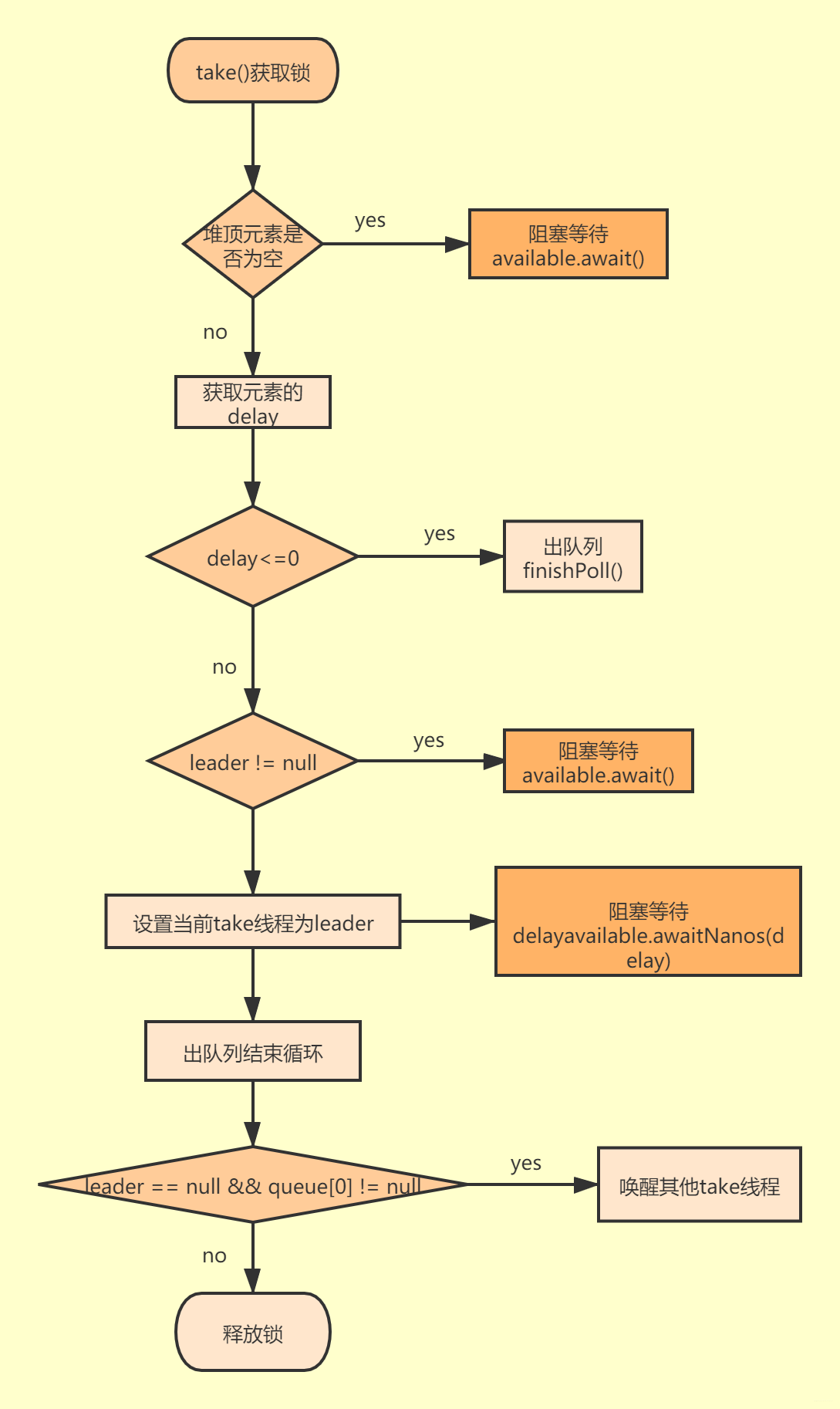
首先获取可中断锁,判断堆顶元素是否是空,空的则阻塞等待。
堆顶元素不为空,则获取其延迟执行时间,说明到了执行时间,出队列。
还没到执行时间,判断线程是否为空,不为空则说明有其他take线程也在等待,当前take将无限期阻塞等待。
线程为空,当前take线程设置为,并阻塞等待时长。
当前leader线程等待delay时长自动唤醒护着被其他take线程唤醒,则最终将设置为。
再循环一次判断出队列。
跳出循环后判断leader为空并且堆顶元素不为空,则唤醒其他take线程,最后是否锁。
public RunnableScheduledFuture take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture first = queue[0]; //取出堆顶元素
if (first == null)
//堆为空,等待
available.await();
else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
//到了执行时间,出队列
return finishPoll(first);
first = null; // don't retain ref while waiting
//还没到执行时间
if (leader != null)
//此时若有其他take线程在等待,当前take将无限期等待
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
如下图为take基本流程图:
(1)take线程阻塞等待
可以看出这个生产者take线程会在两种情况下阻塞等待:
堆顶元素为空。
堆顶元素的delay>0。
(2)finishPoll出队列
堆顶元素,执行时间到,出队列就是一个向下堆化的过程。
private RunnableScheduledFuture finishPoll(RunnableScheduledFuture f) {
int s = --size;
RunnableScheduledFuture x = queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
setIndex(f, -1);
return f;
}
(3)siftDown向下堆化
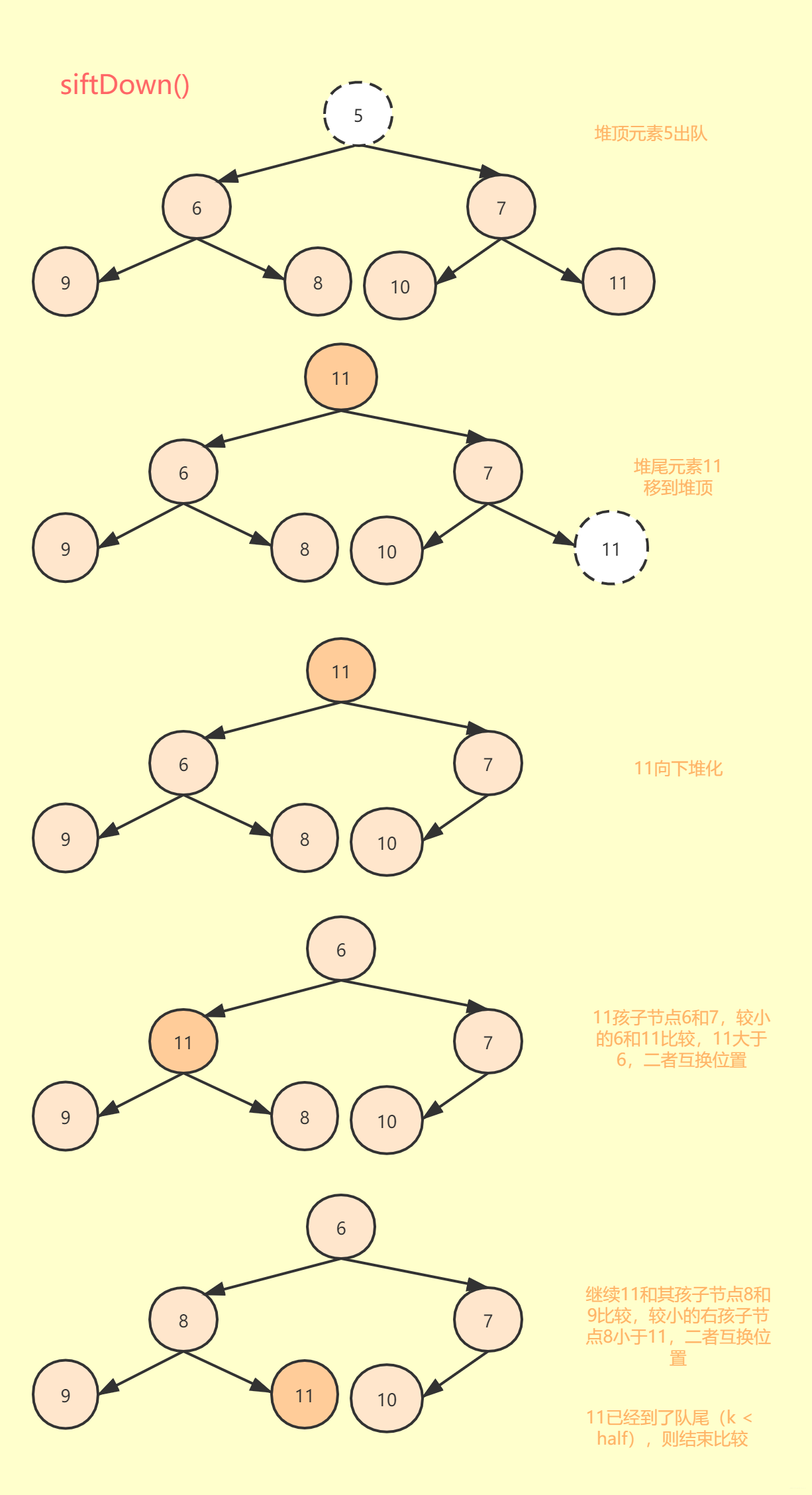
由于堆顶元素出队列后,就破坏了堆的结构,需要组织整理下,将堆尾元素移到堆顶,然后向下堆化:
从堆顶开始,父亲节点与左右子节点中较小的孩子节点比较(左孩子不一定小于右孩子)。
父亲节点小于等于较小孩子节点,则结束循环,不需要交换位置。
若父亲节点大于较小孩子节点,则交换位置。
继续向下循环判断父亲节点和孩子节点的关系,直到父亲节点小于等于较小孩子节点才结束循环。
private void siftDown(int k, RunnableScheduledFuture key) {
//k = 0, key = queue[size-1]
//无符号右移,相当于size/2
int half = size >>> 1;
while (k < half) {
//只需要比较一半
//找到左孩子节点
// child = 2k + 1
int child = (k << 1) + 1;
RunnableScheduledFuture c = queue[child];
//右孩子节点
int right = child + 1;
//比较左右孩子大小
if (right < size && c.compareTo(queue[right]) > 0)
//c左孩子大于右孩子,则将有孩子赋值给左孩子
c = queue[child = right];
//比较key和孩子c
if (key.compareTo(c) <= 0)
//key小于等于c,则结束循环
break;
//key大于孩子c,则key与孩子交换位置
queue[k] = c;
setIndex(c, k);
k = child;
}
queue[k] = key;
setIndex(key, k);
}
代码中使用移位运算,需要说明:
无符号右移,相当于,只比较一般的元素,即左子树,因为左右子树比较后较小元素会在左边。
相当于。
如下图为siftDown向下堆化过程图:
(4)leader线程
线程的设计,是模式的变种,旨在于为了不必要的时间等待。当一个线程变成线程时,只需要等待下一次的延迟时间,而不是线程的其他线程则需要等线程出队列了才唤醒其他线程。
4、remove删除指定元素
删除指定元素一般用于取消任务时,任务还在阻塞队列中,则需要将其删除。当删除的元素不是堆尾元素时,需要做堆化处理。
public boolean remove(Object x) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = indexOf(x);
if (i < 0)
return false;
//维护heapIndex
setIndex(queue[i], -1);
int s = --size;
RunnableScheduledFuture replacement = queue[s];
queue[s] = null;
if (s != i) {
//删除的不是堆尾元素,则需要堆化处理
//先向下堆化
siftDown(i, replacement);
if (queue[i] == replacement)
//若向下堆化后,i位置的元素还是replacement,说明四无需向下堆化的,
//则需要向上堆化
siftUp(i, replacement);
}
return true;
} finally {
lock.unlock();
}
}
四、总结
PS: 如若文章中有错误理解,欢迎批评指正,同时非常期待你的评论、点赞和收藏。我是徐同学,愿与你共同进步!