Hbase内核剖析
前言:
这是我第一次在InfoQ这个平台写文章,由于InfoQ这个平台的文章质量都比较高,希望这次自己也能贡献一篇合格的文章。这里就和各位聊一聊分布式数据库hbase,hbase是hadoop生态圈最常用也是使用最广泛的Nosql数据库,本文将对hbase的内核展开分析,一起探讨一下hbase的底层实现原理,这里先放一张hbase的架构图:
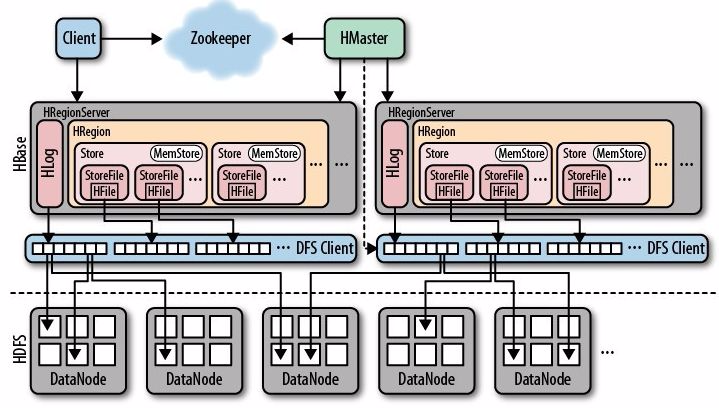
Hbase基本介绍:
这里首先说一下hbase的几个明显的优点:
因为hbase的架构底层的存储是hdfs分布式文件系统,所以天生就具有了分布式特点,如下图所示,另自己的内部架构也是支持regionserver级别的横向扩展的,正是良好的扩展性让hbase非常适合海量数据的存储。
对于RDBMS关系型数据库来而言,底层的存储结构是Row-Store行式存储,而hbase采用的是Column-Store列式存储,这里稍微提一下行存和列存的区别,如下图所示:行式存储下一张表的数据都是放在一起的,即一行记录是一条完整的信息,但列式存储下都被分开保存了,一列数据仅代表一条记录的部分信息,可以明显看出使用列式存储相对于个别列查询操作时,能够有效减少IO,当然缺点就是读取完整记录或者进行更新操作时,比较繁琐。
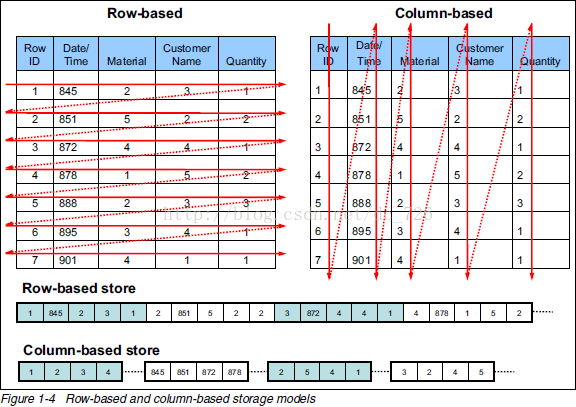
具体行存储和列存储的区别可以参考这篇文章《Column-Stores vs. Row-Stores: How Different Are They Really?》或者网上大牛的博客,这方面文章蛮多的,讲的会比我清晰很多,就不作展开。
Hbase采用列式存储主要原因有两个:
1)在OLAP的场景下,如果还是使用行式存储,会导致大量的无谓的遍历,比如想要对某个列进行所有数据的统计,因为是行式存储,需要遍历所有的实体的所有的属性;如果列式存储,则只需要按照列进行查询即可,因为列式存储是以列一个物理存储单元,所以遍历只要遍历相应列的物理存储文件即可;
2)另一个就是可以方便的进行编码和压缩,因为一列中的值大概率是有大量重复的,可以对于这些重复的值进行编码以及压缩,节省存储空间。
hbase的高可用特点可以从hbase架构图中看到,主要基于两个大数据组件实现:1)hdfs分布式文件系统保证了hbase底层数据高可用性;2)zookeeper分布式协同服务保证了hbase服务的高可用性。当然hbase也有明显的缺点:
目前,这两个问题已经有很好的解决方案了,对于sql操作而言,可以通过开源的sql引擎实现,譬如:phoenix,hive,sparksql,calcite等等;对于二级索引可以依赖es实现,JanusGraph图数据库的底层存储就是hbase+es,hbase用来存储具体的图数据,而es给hbase中的点边创建二级索引,来加快了检索效率。
小结:上面稍微对hbase的几个特点进行了简要的描述,这些特点让hbase成为大数据存储引擎的不二法宝,但是hbase是如何在海量数据存储中崭露头角呢,下面将从几个方面展开描述。
HBase内核剖析

为什么hbase能够适用于海量数据的存储,这里将它的底层原理来进行分析,hbase能给完成海量数据处理主要依赖以下几个点:LSM(Log-Structured-Merge-Tree)树,SkipList跳表,Bloom Filter布隆过滤器,BlockCache块缓存。
LSM树
LSM-tree并不属于一个具体的数据结构,它更多是一种数据结构的设计思想。它起源于 1996 年的一篇论文《The Log-Structured Merge-Tree (LSM-Tree)》,没错这个论在1996年就提出了,而目前在 NoSQL 领域已经广泛使用,基本已经成为必选方案了。从英文全称可以看到有Log-Structured日志结构和Merge-Tree合并树两个单词,而这两个单词的实现就是LSM树的关键。
LSM-tree 最大的特点就是写入速度快,主要利用了磁盘的顺序写,这点与RDBMS有着显著不同,正是这个原因致使hbase的写入速度明显优于关系型数据库,但就像孟子《鱼我所欲也》中那句话“鱼和熊掌不可兼得”,LSM-tree是在牺牲了读取速度换来了高效的写入速度,这里就与关系型数据库的b+树稍作对比,来了解LSM-tree为啥写入快,读取慢。
首先,从磁盘的读写原理来分析,LSM树采用的是顺序读写,b+树采用的是随机读写,二者的区别是:随机读写以理解为数据被存储到磁盘不同的区域,那就是逻辑上相离很近但物理却可能相隔很远,进行读取的时候,由于存储空间不是连续的,所以需要多次寻道和旋转延迟,主要时间耗费在寻道和磁盘旋转这块,而顺序读写主要时间则花费在了传输时间。
对于LSM树的写入流程如下:
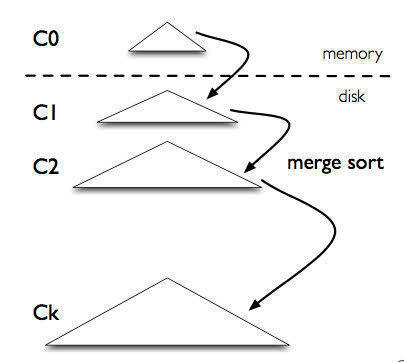
1)首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,达到一定大小时,批量flush到磁盘上这样大大的减少了磁盘I/O。在hbase的写入过程中,数据首先写入到内存的MemStore,当达到默认值128M时,就会触发flush操作,将这批数据进行落盘持久化,当然这个过程可能会涉及到split和compaction操作(hbase的一个自身优化操作),具体这里不作展开;
2)同时为了防止数据在内存丢失,会先写到一个log文件中,确保数据不会丢失,而这个log文件采用的写入方式是append形式,即把最新记录直接写到记录文件的末尾,所以也非常快。在hbase中,这个日志叫WAL(Write Ahead Log)。因此,可以理解LSM树使用日志文件和一个内存存储结构把随机写操作转换为顺序写,充分利用一次I/O。
3)随着小树越来越多,读的性能会越来越差,因此需要在适当的时候,对磁盘中的小树进行merge,多棵小树变成一颗大树,在hbase中,这个操作称为compact(minor compact和major compact)
小结:通过以上步骤可以深入体会LSM树的精髓:Log-Structured 和 Merge-Tree这两个单词,也不得不佩服1996年就提出这么前沿的思想,当时可还没有大数据这个概念!可能大家也看到这个结构除了读取性能上,还有一个很大的缺点就是:由于树的合并,导致写被放大。
SkipList跳表
跳表全称为跳跃列表,它允许快速查询,插入和删除一个有序连续元素的数据链表。跳跃列表的平均查找和插入时间复杂度都是O(logn)。它的查询速度很高,主要是通过维护一个多层次的链表,且每一层链表中的元素是前一层链表元素的子集,也可以理解上层是下层1/2元素的索引。在查询的时候从最上层的稀疏层开始,然后采用一种类似“二分”的算法,确定查找数据的范围,再像下查找,直到找到所需元素,典型的空间换时间的思想。
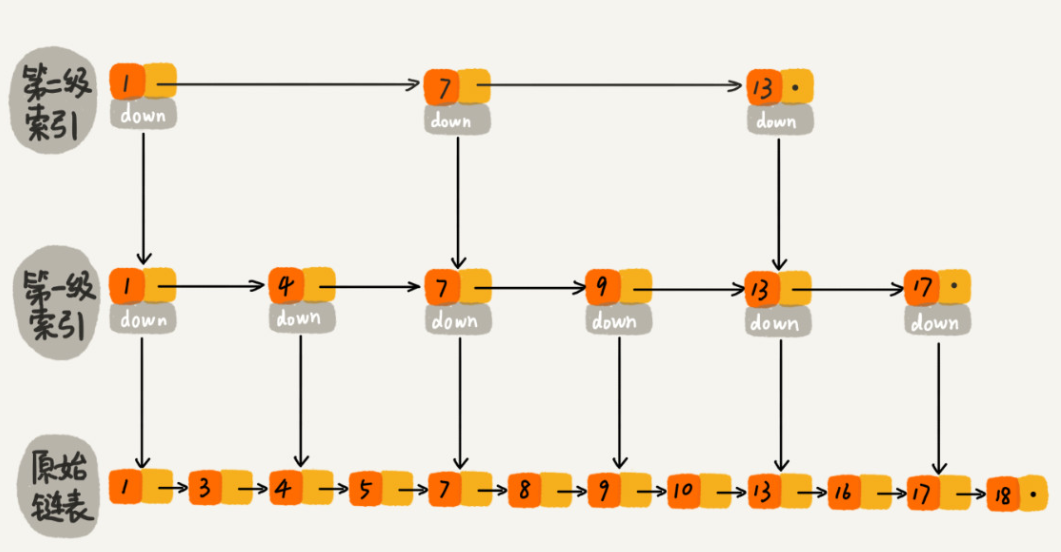
可以看出,跳跃表是按照层次构造的,最底层是一个全量有序链表,依次向上都是它的精简版,而在上层链表中节点的后续下一步的节点是以随机化的方式进行的,因此在上层链表中可以跳过部分列表,因此称谓之为跳表。很多大数据组件的内部查询逻辑都用到了这个数据结构,主要原因就是查询效率高,且实现复杂度低于红黑树。
在hbase源码中,很多处代码使用了ConcurrentSkipListMap,下面列举几个类
1.CachedBlocksByFile
public static class CachedBlocksByFile {
private int count;
private int dataBlockCount;
private long size;
private long dataSize;
private final long now = System.nanoTime();
/**
* How many blocks to look at before we give up.
* There could be many millions of blocks. We don't want the
* ui to freeze while we run through 1B blocks... users will
* think hbase dead. UI displays warning in red when stats
* are incomplete.
*/
private final int max;
public static final int DEFAULT_MAX = 1000000;
CachedBlocksByFile() {
this(null);
}
CachedBlocksByFile(final Configuration c) {
this.max = c == null? DEFAULT_MAX: c.getInt("hbase.ui.blockcache.by.file.max", DEFAULT_MAX);
}
/**
* Map by filename. use concurent utils because we want our Map and contained blocks sorted.
*/
private transient NavigableMap> cachedBlockByFile =
new ConcurrentSkipListMap<>(); 2.PrefetchExecutor
public final class PrefetchExecutor {
private static final Logger LOG = LoggerFactory.getLogger(PrefetchExecutor.class);
/** Futures for tracking block prefetch activity */
private static final Map> prefetchFutures = new ConcurrentSkipListMap<>();
/** Executor pool shared among all HFiles for block prefetch */
private static final ScheduledExecutorService prefetchExecutorPool;
/** Delay before beginning prefetch */
private static final int prefetchDelayMillis;
/** Variation in prefetch delay times, to mitigate stampedes */
private static final float prefetchDelayVariation; 3.ServerManager
public class ServerManager {
public static final String WAIT_ON_REGIONSERVERS_MAXTOSTART =
"hbase.master.wait.on.regionservers.maxtostart";
public static final String WAIT_ON_REGIONSERVERS_MINTOSTART =
"hbase.master.wait.on.regionservers.mintostart";
public static final String WAIT_ON_REGIONSERVERS_TIMEOUT =
"hbase.master.wait.on.regionservers.timeout";
public static final String WAIT_ON_REGIONSERVERS_INTERVAL =
"hbase.master.wait.on.regionservers.interval";
/**
* see HBASE-20727
* if set to true, flushedSequenceIdByRegion and storeFlushedSequenceIdsByRegion
* will be persisted to HDFS and loaded when master restart to speed up log split
*/
public static final String PERSIST_FLUSHEDSEQUENCEID =
"hbase.master.persist.flushedsequenceid.enabled";
public static final boolean PERSIST_FLUSHEDSEQUENCEID_DEFAULT = true;
public static final String FLUSHEDSEQUENCEID_FLUSHER_INTERVAL =
"hbase.master.flushedsequenceid.flusher.interval";
public static final int FLUSHEDSEQUENCEID_FLUSHER_INTERVAL_DEFAULT =
3 * 60 * 60 * 1000; // 3 hours
public static final String MAX_CLOCK_SKEW_MS = "hbase.master.maxclockskew";
private static final Logger LOG = LoggerFactory.getLogger(ServerManager.class);
// Set if we are to shutdown the cluster.
private AtomicBoolean clusterShutdown = new AtomicBoolean(false);
/**
* The last flushed sequence id for a region.
*/
private final ConcurrentNavigableMap flushedSequenceIdByRegion =
new ConcurrentSkipListMap<>(Bytes.BYTES_COMPARATOR); 4.RegionStates
public class RegionStates {
private static final Logger LOG = LoggerFactory.getLogger(RegionStates.class);
// This comparator sorts the RegionStates by time stamp then Region name.
// Comparing by timestamp alone can lead us to discard different RegionStates that happen
// to share a timestamp.
private static class RegionStateStampComparator implements Comparator {
@Override
public int compare(final RegionState l, final RegionState r) {
int stampCmp = Long.compare(l.getStamp(), r.getStamp());
return stampCmp != 0 ? stampCmp : RegionInfo.COMPARATOR.compare(l.getRegion(), r.getRegion());
}
}
public final static RegionStateStampComparator REGION_STATE_STAMP_COMPARATOR =
new RegionStateStampComparator();
private final Object regionsMapLock = new Object();
// TODO: Replace the ConcurrentSkipListMaps
/**
* RegionName -- i.e. RegionInfo.getRegionName() -- as bytes to {@link RegionStateNode}
*/
private final ConcurrentSkipListMap regionsMap =
new ConcurrentSkipListMap<>(Bytes.BYTES_COMPARATOR); 5.RAMCache
static class RAMCache {
/**
* Defined the map as {@link ConcurrentHashMap} explicitly here, because in
* {@link RAMCache#get(BlockCacheKey)} and
* {@link RAMCache#putIfAbsent(BlockCacheKey, BucketCache.RAMQueueEntry)} , we need to
* guarantee the atomicity of map#computeIfPresent(key, func) and map#putIfAbsent(key, func).
* Besides, the func method can execute exactly once only when the key is present(or absent)
* and under the lock context. Otherwise, the reference count of block will be messed up.
* Notice that the {@link java.util.concurrent.ConcurrentSkipListMap} can not guarantee that.
*/
final ConcurrentHashMap delegate = new ConcurrentHashMap<>(); 其他还有很多类同样用到了这个集合,可见SkipList跳表这个数据结构的强大之处,而上述代码中的ConcurrentSkipListMap具体操作这里就不作展开,我也没有进一步的学习研究,感兴趣的同学可以下载hbase-master源码进行学习,我的版本是hbase-2.4.0,对应的源码下载链接:。
小结:SkipList跳表广泛使用于KV数据库中,Hbase同样在代码中使用,并借此来实现高效的插入、删除、查找等操作。
Bloom Filter布隆过滤器
在一般场景下,判断一个元素是否在集合里面,最简单的方法就是遍历一遍,就可以得知答案,但是海量数据的场景下,百万亿或千万亿的数据的全部遍历,显然是不允许的,而bloom过滤器就能很好的解决这个问题。 bloom算法类似一个hash set,可以用来判断一个元素是否在一个集合中,优点就是查询效率非常高,缺点就是存在误判。
基本思想就是,把集合中的每一个值按照提供的 hash 算法算出对应的 hash 值,由于hash冲突的问题不可避免,所以建议一个元素通过多个hash算法来计算,降低误判率,然后将 Hash 值对数组长度取模后得到需要计入数组的索引值,并且将数组这个位置的值从 0 改成 1。
在判断一个元素是否存在于这个集合中时,你只需要将这个元素按照相同的算法计算出索引值,如果这个位置的值为0,则该元素一定不存在集合中,如果为1,则代表这个数有可能存在集合中,记住是有可能(hash冲突的原因)。
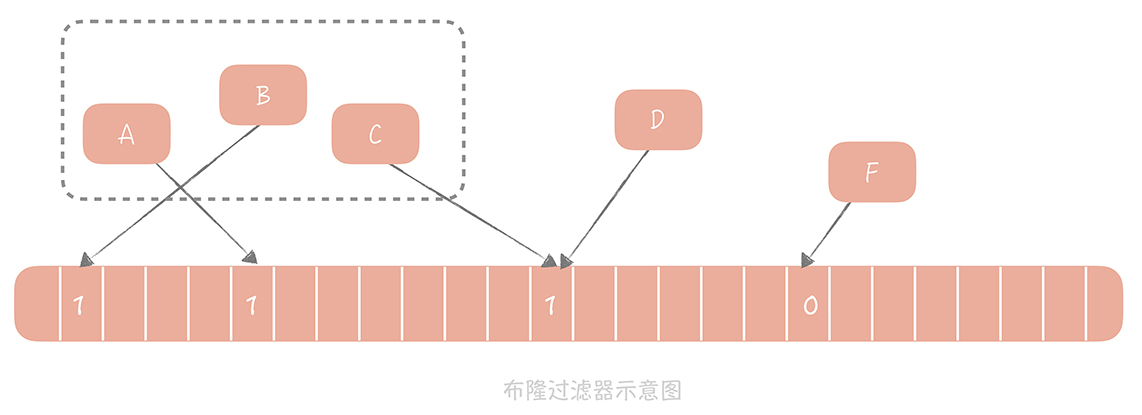
上图中,F的值计算为0,则可以认为F元素不在该集合中,而A,B,C,D值为1,则有可能存在集合中。接下来看看hbase是如何使用bloom过滤器的。
hbase中数据存储形式最终以一个个hfile进行存储,hfile中是一个列族的部分数据。当进行get查找时,hbase会通过blockindex块索引机制,即通过块索引来确定哪些块可能包含这个rowkey,regionServer需要加载每一个块来检查该块中是否真的包含该行的单元格,由于块索引的覆盖范围太大,就会导致加载很多文件,为了减少不必要的文件加载和I/O操作,可以通过bloom过滤器进行优化,增大hbase的吞吐率。因此,hbase会在生成StoreFile(Hfile)时包含一份布隆过滤器结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。
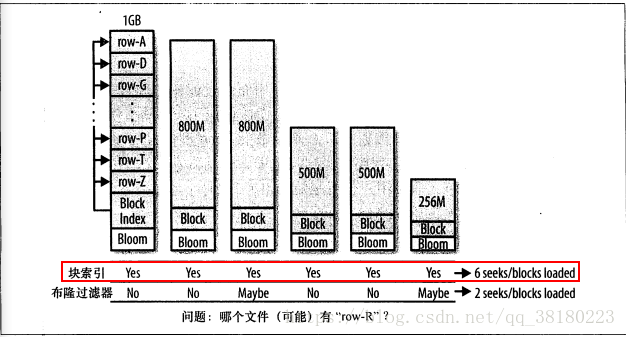
开启bloomfilter后,hbase的get数据流程就会先从布隆过滤器中查找,根据布隆过滤器的查询结果再会有一定的存储及内存cache开销,但是能够带来查询性能的提高。hbase中bloomfilter接口代码如下,其中核心方法就是contains方法
public interface BloomFilter extends BloomFilterBase {
/**
* Check if the specified key is contained in the bloom filter.
* @param keyCell the key to check for the existence of
* @param bloom bloom filter data to search. This can be null if auto-loading
* is supported.
* @param type The type of Bloom ROW/ ROW_COL
* @return true if matched by bloom, false if not
*/
boolean contains(Cell keyCell, ByteBuff bloom, BloomType type);
/**
* Check if the specified key is contained in the bloom filter.
* @param buf data to check for existence of
* @param offset offset into the data
* @param length length of the data
* @param bloom bloom filter data to search. This can be null if auto-loading
* is supported.
* @return true if matched by bloom, false if not
*/
boolean contains(byte[] buf, int offset, int length, ByteBuff bloom);
/**
* @return true if this Bloom filter can automatically load its data
* and thus allows a null byte buffer to be passed to contains()
*/
boolean supportsAutoLoading();
}CompoundBloomFilter为对应的实现类:
public class CompoundBloomFilter extends CompoundBloomFilterBase
implements BloomFilter {
/** Used to load chunks on demand */
private HFile.Reader reader;
private HFileBlockIndex.BlockIndexReader index;
private int hashCount;
private Hash hash;
private long[] numQueriesPerChunk;
private long[] numPositivesPerChunk;
/**
* De-serialization for compound Bloom filter metadata. Must be consistent
* with what {@link CompoundBloomFilterWriter} does.
*
* @param meta serialized Bloom filter metadata without any magic blocks
* @throws IOException
*/
public CompoundBloomFilter(DataInput meta, HFile.Reader reader)
throws IOException {
this.reader = reader;
totalByteSize = meta.readLong();
hashCount = meta.readInt();
hashType = meta.readInt();
totalKeyCount = meta.readLong();
totalMaxKeys = meta.readLong();
numChunks = meta.readInt();
byte[] comparatorClassName = Bytes.readByteArray(meta);
// The writer would have return 0 as the vint length for the case of
// Bytes.BYTES_RAWCOMPARATOR. In such cases do not initialize comparator, it can be
// null
if (comparatorClassName.length != 0) {
comparator = FixedFileTrailer.createComparator(Bytes.toString(comparatorClassName));
}
hash = Hash.getInstance(hashType);
if (hash == null) {
throw new IllegalArgumentException("Invalid hash type: " + hashType);
}
// We will pass null for ROW block
if(comparator == null) {
index = new HFileBlockIndex.ByteArrayKeyBlockIndexReader(1);
} else {
index = new HFileBlockIndex.CellBasedKeyBlockIndexReader(comparator, 1);
}
index.readRootIndex(meta, numChunks);
}
@Override
public boolean contains(byte[] key, int keyOffset, int keyLength, ByteBuff bloom) {
int block = index.rootBlockContainingKey(key, keyOffset, keyLength);
if (block < 0) {
return false; // This key is not in the file.
}
boolean result;
HFileBlock bloomBlock = getBloomBlock(block);
try {
ByteBuff bloomBuf = bloomBlock.getBufferReadOnly();
result = BloomFilterUtil.contains(key, keyOffset, keyLength, bloomBuf,
bloomBlock.headerSize(), bloomBlock.getUncompressedSizeWithoutHeader(), hash, hashCount);
} finally {
// After the use, should release the block to deallocate byte buffers.
bloomBlock.release();
}
if (numPositivesPerChunk != null && result) {
// Update statistics. Only used in unit tests.
++numPositivesPerChunk[block];
}
return result;
}
private HFileBlock getBloomBlock(int block) {
HFileBlock bloomBlock;
try {
// We cache the block and use a positional read.
bloomBlock = reader.readBlock(index.getRootBlockOffset(block),
index.getRootBlockDataSize(block), true, true, false, true, BlockType.BLOOM_CHUNK, null);
} catch (IOException ex) {
// The Bloom filter is broken, turn it off.
throw new IllegalArgumentException("Failed to load Bloom block", ex);
}
if (numQueriesPerChunk != null) {
// Update statistics. Only used in unit tests.
++numQueriesPerChunk[block];
}
return bloomBlock;
}
@Override
public boolean contains(Cell keyCell, ByteBuff bloom, BloomType type) {
int block = index.rootBlockContainingKey(keyCell);
if (block < 0) {
return false; // This key is not in the file.
}
boolean result;
HFileBlock bloomBlock = getBloomBlock(block);
try {
ByteBuff bloomBuf = bloomBlock.getBufferReadOnly();
result = BloomFilterUtil.contains(keyCell, bloomBuf, bloomBlock.headerSize(),
bloomBlock.getUncompressedSizeWithoutHeader(), hash, hashCount, type);
} finally {
// After the use, should release the block to deallocate the byte buffers.
bloomBlock.release();
}
if (numPositivesPerChunk != null && result) {
// Update statistics. Only used in unit tests.
++numPositivesPerChunk[block];
}
return result;
}Hbase支持的bloom过滤器的类型:
public enum BloomType {
/**
* Bloomfilters disabled
*/
NONE,
/**
* Bloom enabled with Table row as Key
*/
ROW,
/**
* Bloom enabled with Table row & column (family+qualifier) as Key
*/
ROWCOL,
/**
* Bloom enabled with Table row prefix as Key, specify the length of the prefix
*/
ROWPREFIX_FIXED_LENGTH
}小结:hbase根据rowkey进行查询的时候,一般情况下就会将包含该rowkey的hfile全部加载,但这种粗粒度的查询方式就会加载了很多不必要文件数据,浪费I/O。因此,hbase为了减少不必要hfile文件的加载,引入了bloomfilter,即采用特定的算法获取数据的key的值,通过“0”或“1”,快速反馈数据不存在于该文件或可能存在该文件中,大大减少了“不存在“情况下的文件加载操作,进而加大吞吐率。
BlockCache块缓存
在上述bloom过滤器的介绍中,提及到LRUBlockCache这个词,没错这个就是缓存,在加快数据处理过程,缓存是一个不可缺少的利器。hbase的缓存主要包括两部分,一个是MemStore用于提高hbase的写入性能,即写缓存,另一个就是BlockCache用于提高hbase的读取性能,即读缓存。BlockCache与MemStore最大的不同之处就是,一个regionserver对应一个BlockCache和多个MemStore(一个Store一个MemStore)。在hbase中BlockCache的实现方式有两种,一种实现方式是on-heap堆内内存模式,另一种实现方式是off-heap堆外内存模式。默认采用的是前者,实现是LRUBlockCache。
LRUBlockCache:
核心就是页面淘汰算法,在hbase中包括三种优先级,以适应于于:scan-resistance 以及 in-memory ColumnFamilies场景:
BucketCache
hbase提供BucketCache 是将数据存在堆外内存(off-heap),因此这块数据就不受JVM内存管理,能够有效减少hbase由于cms gc算法产生的内存碎片而触发full gc的问题。 BucketCache 通过配置可以工作在三种模
式下:
heap: 这些 Bucket 是从 JVM Heap 中申请;
offheap: 使用 DirectByteBuffer 技术实现堆外内存存储管理
file: 使用类似 SSD 的高速缓存文件存储数据块。
无论哪种模式, BucketCache 都会申请许多带有固定大小标签的 Bucket。可在 hbase-site.xml文件中配置。
具体LRUBlockCache和BucketCache相关细节可在hbase源码中可见,这块本人没有深入研究学习,感兴趣的朋友可以阅读LruBlockCache和BucketCache两个类源码:
//LRUBlockCache
public class LruBlockCache implements FirstLevelBlockCache{...}
//BucketCache
public class BucketCache implements BlockCache, HeapSize{...}小结:hbase与其他数据库一样,同样采用了缓存机制来提高查询效率。在读缓存方面,hbase提供了on-heap和off-heap的两种缓存配置方式,hbase支持HBase将BucketCache和LRUBlockCache搭配使用,称为CombinedBlockCache,其中LRUBlockCache中主要存储Index Block和Bloom Block,而将Data Block存储在BucketCache中。这样一次随机读, 首先会去 LRUBlockCache 中查到对应的索引块Index Block,然后再到 BucketCache 查找对应数据块Data Block,能够极大降低了JVM GC对业务请求的实际影响。
总结

在此对hbase的内核底层原理作了简要的分析,其中很多的思想是值得我们借鉴学习的,上文提到的内容仅仅是hbase的冰山一角,里面还有很多的技术需要我深入的挖掘和学习,作为coder的我们希望能在每一次技术革新中都得到成长,实现自我价值,加油!最后,感谢各位耐心阅读,希望在hbase上的了解对大家有所帮助,上文描述若有不正确的地方,欢迎拍砖指出!