记一次MHA切换故障踩的坑
MHA简单架构如下
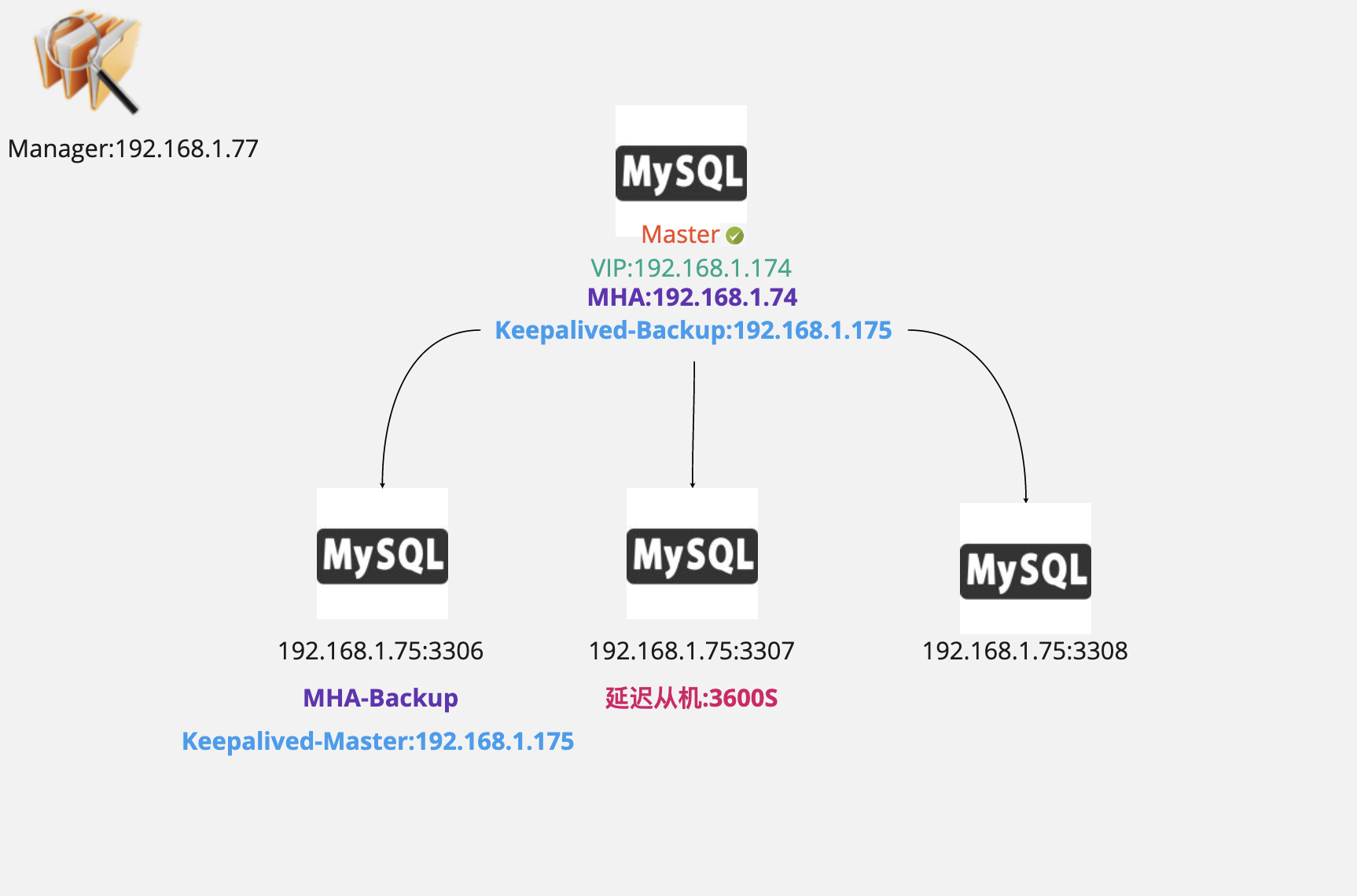
主机高可用(MHA)
Master1:192.168.1.74
Master-bak:192.168.1.75:3306
Master-vip:192.168.1.174
Manager:192.168.1.77
其他用途
Delay:192.168.1.75:3307
Slave:192.168.1.78:3307
故障演练
早上 07:05分开始操作
停掉主库192.168.1.74:3306
New Master: 192.168.1.75:3306
Slave2:192.168.1.75:3308

一开始都是正常的,切换IP漂移,到了主从身份切换的时候就出现问题了。
主从的复制环境是GTID模式,肯定是复制的时候出现错误。登上去从机看此时的主从情况

原因是Master上已经清除了Slave所需要的binary logs 。有点不知其然,明明都是实时同步的,不知道怎么的就突然缺失了。
一时之间解决不了,想到把停掉的
旧主74:3306 重新启动起来change to New master ,看看会不会报同样的错误
早上 07:52分重新执行change
由于
旧主74:3306 之前是主机,并没有开启read_only ,所以在配置文件里面把read_only=on开启 (这点很重要!)重新change
结果还是一样。
失败之后还发生了有异样的事情

此时我重新启动的旧主机有进程进来。此时不应该有的, 因为在研发那边,业务层代码应该把IP改为了高可用IP 于是询问下了研发,那边说已经全部修改完毕。我觉得可能是由于缓存之类的,涉及到查询select之类的,并不会对数据进行修改,于是便继续排查主从复制失败的原因。由于这一次大意导致了我接下来跟研发惨无人道的数据修复之路

早上 10:20分发现权限不对
研发那边反馈查的数据好像不一致,我隐隐约约觉得不太对劲,他们说还有写的业务是连接 的,我说我在74这边有开 你们的写入操作都进不来的。但是由于职业性的要求,比较敏感。去排查了一下进来的业务用户的权限。发现了一个权限


早上 10:34分关站,切IP
此时数据完全都不一致了,有两台机子同时写入。紧急关站
把用户权限 remove 同时把74停掉,叫研发把业务暂时全部切过去高可用IP
中午11:15分用户投诉订单丢失
说十点多的刚下的订单 涉及金额一千多块钱,刚付款,订单就消失了。
这个数据应该在 上,目前74都已经停了, 所以读写基本都是在 上
事态紧急,连忙把 起来,同时把 10:34分-11:15分这个期间在 上的Binlog在74上进行重灌,想把74恢复成一台数据完整的机子,然后再切回去。
由于太急,处理突发事故的经验也不足,并没有考虑到Binlog里面有 语句, 认为都是
BInlog导入之后。认为数据一致,重新把业务切回去 上
下午15:12分四笔订单离奇失踪
开发反馈,有四笔订单,在 上找不到 在 上也找不到,业务逻辑上并没有删除 的逻辑
此时发现重灌的Binlog里面有 ,已经把之前存在 的数据给update掉了。数据丢失
流程梳理
PS:ID是主键而且是自增的
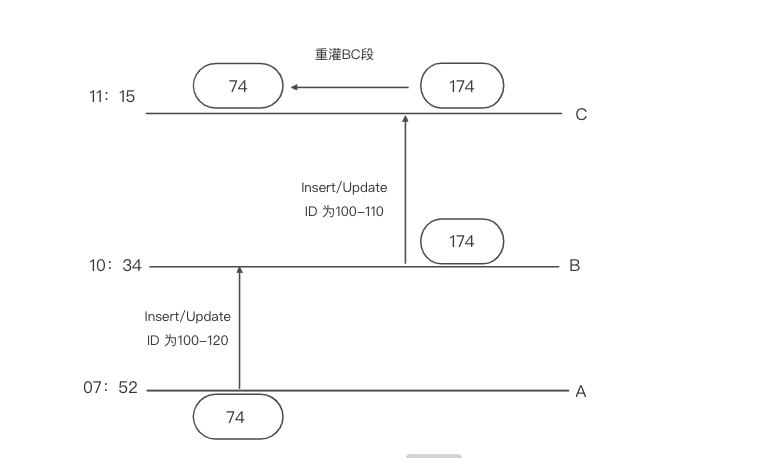
假如上在AB段已经的数据
ID=100 values=A
ID=101 values=B
ID=102 values=C
后来在在BC段已经的数据
ID=100 values=D
ID=101 values=E
ID=102 values=F
在重灌的时候把数据A、B、C改为D、E、F (因为ID一致)
修复数据
在查找binlog的过程当中,筛选出07:52-10:34中在 中数据(根据10:34-11:15中在筛选出被的ID)查找的语句,过滤出来重新插入
接下来就是重复无止境的重复修复操作了。
····