Apache Calcite:异质数据源优化查询框架
该篇文章是研究Apache Calcite时看到的一篇论文:https://dl.acm.org/doi/abs/10.1145/3183713.3190662,其对Apache Calcite的方方面面作了整体的介绍。为细细研究,故将其翻译成中文,以供后续学习。
摘要
Apache Calcite是一个基础的软件框架,能够为许多流行的开源数据处理系统提供查询处理、优化和查询语言的能力支持,例如:Apache Hive,Apache Storm,Apache Flink,Druid 以及 MapD等。Calcite包含查询优化器、查询处理器以及适配器等组件,模块化的查询优化器可支持扩展,其内置上百种优化规则;查询处理器,能够支持各种各样的查询语言;而适配器的设计,可以支持各种异质数据模型或存储的适配,诸如:关系型、半结构化、流式以及地理空间数据等。这种灵活(flexible)、可嵌入(embeddable)且可扩展的架构设计使得Apache Calcite在大数据处理框架上,成为一个很好的选择。
关键词
Apache Calcite,语义关系(Relational Semantics),数据管理(Data Management),查询代数(Query Algebra),模块化查询优化(Modular Query Optimization),存储适配器(Storage Adapters)
1 引言
常规关系数据引擎依然主导了数据处理领域。早在2005年,Stonebraker and Çetintemel已经预言,我们将会见到一系列专用引擎,比如,列式存储、流处理引擎、文本处理引擎等。他们认为专用引擎能够提供更好的性能且能终结“one size fits all”范式。今天,他们的愿景似乎比以往任何时候都更加重要。事实上,很多专用的开源数据系统已经很流行,像Apache Storm 和 Apache Flink(流处理),Elasticsearch(文本检索),Apache Spark, Druid 等等。
基于专用需求量身定制的数据处理系统,存在以下两方面的问题:
专用系统的开发者遇到一些问题,例如查询优化(query optimization)、基于SQL的查询语言及相关扩展能力支持,以及由LINQ启发的语言集成查询框架。在没有统一的框架情况下,会导致工程师各自独立开发相类似的查询优化和语言支持,导致重复工作,浪费人力。
开发者经常需要将多个专用引擎整合起来。一个系统可能依赖Elasticsearch、Apache Spark、Druid,这样的情况就得需要需要支持跨异质数据源查询能力。
Apache Calcite开发的初衷就是来解决这些问题。Calcite是一个完整的查询处理系统,能够提供任何数据管理系统支持的多种通用功能,包括查询执行、优化以及查询语言。但是Calcite有两个方面没有实现,一是数据存储,二是数据管理,这两方面的功能留给了专用引擎来实现。Calcite可以快速地被Hive,Drill,Strom和很多其他的数据处理引擎集成,为其提供高级的查询优化以及查询语言支持。举个例子,Hive是一个构建在Apahce Hadoop上的流行的数据仓库项目。随着Hive方向从批处理转向基于SQL的交互式查询,其最需要解决的就是强大的查询优化器。因此,Hive采用Apahce Calcite作为其优化器且集成度越来越高。许多其他的项目和产品也跟Hive类似,集成了Apache Calcite的能力,包括Flink,MapD等等。
此外,通过向多种系统暴露标准接口,Apache Calcite能够提供跨平台优化支持。为了提高效率,优化器需要提供全局来处理的能力,比如在不同的系统上做物化视图选择的判断。
构建一个通用的框架有很多的挑战,特别是该框架要有足够的灵活性和可扩展性,且能够适配集成的系统。我们相信以下特性能够有助于Apache Calcite在开源社区和行业中的广泛采用:
开源友好性。在过去的10年中,大部分主要的数据处理平台要么是开源要么就是大部分基于开源研制的。Apache Calcite是一个Apache 的开源框架。此外,Apache Calcite是由Java语言开发,使其能够与其他由Java或Scala实现的开源数据处理系统更好地集成,尤其是Hadoop生态系统。
多数据模型。Apache Calcite提供流式和常规数据处理范式的查询优化和查询语言的能力支持。Calcite把流当成是记录或事件的时间顺序集合,这些数据和传统的数据处理系统不一样,其并不持久化到磁盘。
灵活的查询优化器。从规则到成本模型,每一个优化器的组件均是可插拔且可扩展的,另外,Calcite支持多个计划引擎。所以,优化可以被拆分到不同的优化阶段,这样可以找到更适合的优化规则来进行优化。
跨系统支持。Calcite框架可以跨多个查询处理系统和数据库进行查询和优化。
可靠性。Calcite具有很好的可靠性,在被采用的这些年,其经受住了各类平台详尽的测试。同样地,Calcite本身包含详尽的测试套件,用以测试检验查询优化器的规则以及数据源集成的组件。
支持SQL及扩展。很多系统不提供自己的查询语言,而是更愿意依赖于现有的查询语言,例如SQL。对于这些情况,Calcite提供了支持ANSI标准的SQL以及各种SQL方言和扩展的支持,例如基于流或者嵌套数据的查询。另外,Calcite提供了符合Java API(JDBC)的驱动程序。
2 相关工作
在hadoop生态大数据分析领域,Calcite目前是被广泛采用的优化器,其实Calcite背后的实现并不新颖。例如,查询优化器的思路来自于Volcano和Cascades框架,并结合其他被广泛使用的优化技术,如物化视图重写。有很多其他的系统跟Calcite类似。
Orac是一款模块化的查询优化器,其目前被应用于Greenplum和HAWQ数据管理产品中。Orac引入一个数据交换语言(Data eXchange Language)框架,其实现了优化器与执行引擎两者的分离。除此之外,Orac还对其生成的查询计划提供一个校验正确性和性能的能力。与之相比,Calcite可以被当作一个独立的查询执行引擎,能够适配多个存储和处理后端,包括可插拔的计划器和优化器。
Spark SQL扩展Apache Spark以支持SQL化查询执行。该查询也可以像Calcite一样,对多个数据源执行查询。然而,尽管Spark SQL中的Catalyst优化器也尝试最小化查询执行成本,但是其缺乏类似于Calcite中的动态编程方法,且容易陷入局部极小值的风险。
Algebricks是一种查询编译器体系架构,为大数据查询提供了数据模型无关的代数层和编译器框架。高级语言被编译成Algebricks 逻辑代数。然后,Algebricks生成针对Hyracks并行处理后端的优化作业。虽然Calcite与Algebricks一样,采用了相同的模块化方法,但是Calcite在此基础上还提供了成本优化支持。在Calcite当前版本中,查询优化器架构基于Volcano采用了动态编程计划,并同样具备Orca多阶段优化的扩展能力。尽管Algebricks能够支持多个处理后端(例如:Apache Tez、Spark),但是多年来,Calcite已经经受住各种后端的良好测试考验。
Garlic是一个异构数据管理系统,其基于统一的对象模型表示来自多个系统的数据。但是Garlic无法根据不同的系统来提供查询优化支持,而是依赖系统本身来优化查询。
FORWARD是一个联邦查询处理器,该查询处理器实现了一种叫SQL++的查询语言,该查询语言为SQL的超集。SQL++将JSON和关系数据模型整合在一起,形成半结构化数据模型,而Calcite则是在查询计划阶段,用关系数据模型来表示半结构化数据模型。FORWARD将基于SQL++的联邦查询拆解为子查询,并根据查询计划在具体的数据库执行,而数据的合并则在FORWARD引擎中。
另外一个联邦数据存储和处理系统是BigDAWG,该系统抽象了各类数据模型,包括关系、时间序列以及流。在BigDAWG中,具体抽象单元称之为信息岛(island of information)。每一个信息岛包含查询语言、数据模型以及一个或多个存储系统的连接。只有在单个信息岛内,跨存储系统的查询才能支持。而Calcite提供了统一的关系抽象,该抽象支持跨不同数据模型的后端进行查询。
Myria是一个通用的大数据分析引擎,其支持Python语言。该引擎为各类后端引擎生成查询计划,比如Spark和PostgreSQL。
3 架构
Apache Calcite包含了许多典型数据库管理系统具备的组件,但是也放弃了一些关键的组件,例如:数据存储、数据处理算法和元数据存储。放弃这些其实是Calcite有意为之,这使得Calcite成为一种更好的选择,用于衔接多数据存储以及多数据处理引擎,同时也为构建定制化的数据处理系统提供坚实的基础。
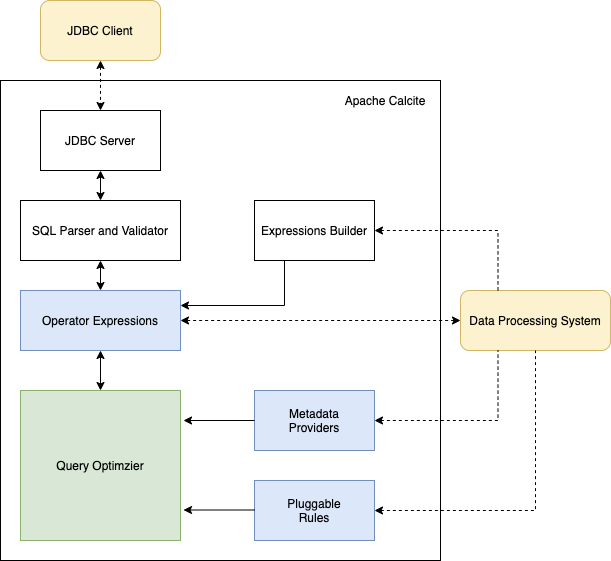
图1展示了Apache Calcite架构的主要组件。Calcite采用关系操作树作为其内部表示。内部优化引擎主要包括三个组件:规则,元数据和计划引擎,我们将在第6部分详细讨论这些组件。图中,虚线表示与外部框架的交互。Caclcite提供了多种方式与外部框架交互。
首先,Calcite包含一个查询处理器和校验器能够将SQL查询语句转换成关系操作树。Calcite不支持存储功能,而是通过适配器,提供了在外部存储引擎中定义数据表schemas和视图的标准。因此,可以在这些引擎上使用Calcite。
其次,Calcite不仅为需要数据库语言支持的系统提供了优化的SQL支持,而且对那些本身具体语言解析与解释的系统,Calcite也能提供优化支持:
有些系统支持SQL查询,但是没有或者只是有限的SQL查询优化。例如,Hive和Spark最初均提供了对SQL查询的支持,但是它们并没有优化器的能力。对于这些情况,一旦查询被优化后,Calcite可以将关系表达式转回SQL。这种功能使得Calcite能够作为独立的系统模块,构建在那些有SQL接口,但无优化器的数据管理系统上。
Calcite架构不仅仅面向SQL查询优化。通常数据处理系统会选择自己的查询语言和相应的解析器。对于这种情况,Calcite也能起作用。事实上,Caclite利用内置的关系表达式构建接口,也能通过直接初始化关系操作符类,来构建操作树。例如,假设我们使用表达式构建器来表示以下Apache Pig脚本。
emp = LOAD 'employee_data' AS (deptno, sal);
emp_by_dept = GROUP emp by (deptno);
emp_agg = FOREACH emp_by_dept GENERATE GROUP as deptno, COUNT(emp.sal) AS c, SUM(emp.sal) as s;
dump emp_agg;使用Calcite构建器来表示,具体如下:
final RelNode node = builder.scan("employee_data")
.aggregate(builder.groupKey("deptno"),
builder.count(false, "c"),
builder.sum(false, "s", builder.field("sal")))
.build();该接口展示了构建关系表达式的方式。当优化阶段结束后,应用程序可以检索优化后的关系表达式,然后将其映射回系统查询单元。
4 查询代数
操作符(Operators)。关系代数是Calcite的核心部分。除了最常见的诸如过滤(filter)、映射(project)、关联(join)等,Calcite提供了额外的操作符来满足不同的需求,比如能够简单表示复杂操作或者更有效识别优化时机。
举例来说,对于OLAP,决策支持和流应用来说,使用窗口函数来表达复杂分析功能已经变得很常见(例如,按时间段、数值或行数进行窗口滑动)。为此,Calcite引入了窗口(window)操作符来封装窗口的定义(上下限,分区等)以及窗口上执行的聚合函数。
特质(Traits)。Calcite没有使用不同的实体来表示逻辑和物理操作符。相反,其使用特质来描述与操作相关的物理属性。这些特质能够帮助优化器来评估不同替代计划的执行成本。修改特质的值并不会改变需要评估的逻辑表达式,即,指定操作符生成的行仍然是一样的。
在优化过程中,Calcite会尝试在一些关系表达式上强制执行指定的特质,例如,某些列的排序顺序。关系操作符实现了一个转换接口,用来标识如何将将表达式的特质从一个值转换为另一个值。
Calcite包含了常用的一些特质,这些特质描述了关系表达式生成的数据物理属性,例如排序(ordering),分组(grouping)和分区(partitioning),和SCOPE优化器类似,Calcite优化器可以推理这些属性,并且利用这些推理来找到不必要的操作计划。例如,若排序操作符的输入已经正确排序(行排序与后台系统的行排序相同),那么排序操作就可以移除。
除了这些特性,Caclite还包括一个重要的特质,即调用约定(calling convention)。本质上,特质表示表达式执行的数据处理系统。将调用约定当作特质,可以使Calcite能够保持透明的优化查询,对于跨引擎执行而言,该约定被看作是其他物理属性。
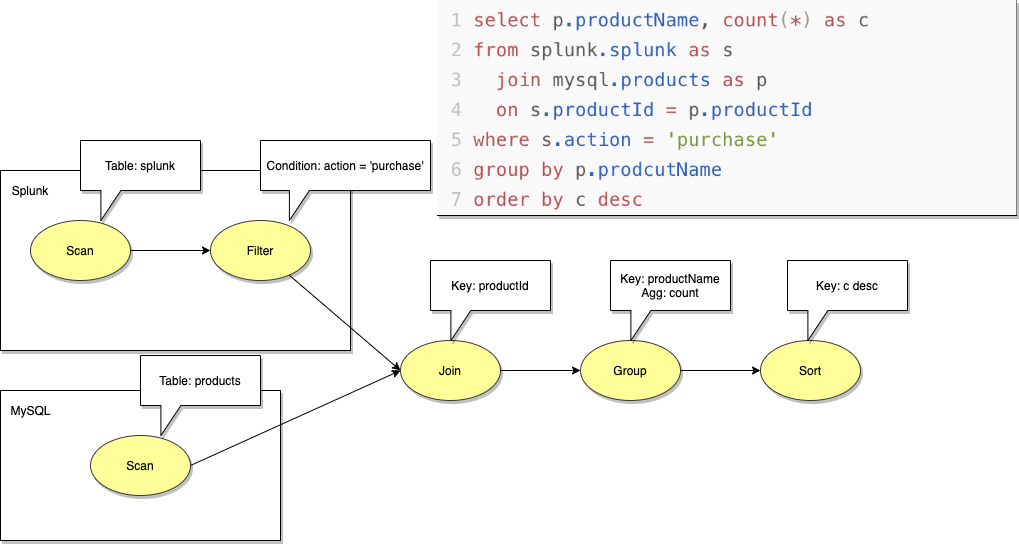
我们拿具体的示例来说明下,如图2所示,做 和 的跨存储关联, 保存在MySQL中,而 表则保存在Splunk中。首先, 在Splunk中扫描 表,在Mysql中扫描 表,而关联操作在逻辑上没有选择具体的执行引擎。而且,图2上的SQL查询包含过滤操作,该操作通过适配器具体的规则,详见第5节,将过滤操作下推至splunk中执行。对于关联操作,一种可行的解决方案是将关联操作转成Spark实现,且将MySQL和Splunk的输入也转换至Spark实现。还一种更有效的实现方式,Splunk利用ODBC方式执行MySQL表的查询,如此就可以实现整个操作在Splunk引擎中执行。
5 适配器
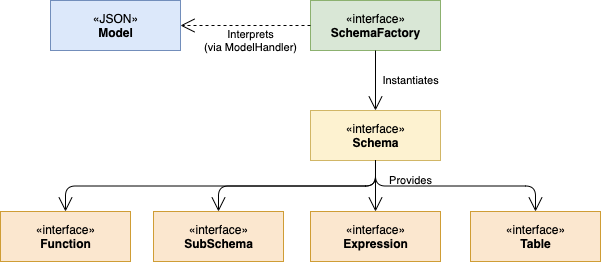
Calcite中的适配器一种架构模式,其定义了对各种数据源如何进行访问。图3描绘了适配器的组件,从图上我们可以看出,适配器主要由模型(model),Schema和SchemaFactory组成。模型定义了访问数据源所需要属性的结构,Schema则是模型中数据的定义,包括数据格式和布局。数据本身则是通过表进行访问,Calcite借助适配器中关于表的定义来读取数据,查询的执行都会依赖表的定义。另外,适配器可以向计划器中添加自己的一组规则,例如如何从将各种类型的逻辑关系表达式向具体适配器约定的关系表达式转换。SchemaFactory则从模型中获取元数据信息并生成schema。
如第4节讨论的那样,Calcite使用调用约定特质来识别关系操作符并与指定数据库对应。这些物理操作符为每个适配器中潜在的表提供访问路径。当SQL被解析完并转换成关系代数表达式时,将为每个表创建一个基于表的scan操作符。scan操作符是适配器必须实现的最小接口。若某个适配器实现了表scan操作符,Calcite优化器就能够使用排序(sorting)、过滤(filtering)和关联(joins)操作符来对这些表执行任意SQL查询。
表scan操作符包含了适配器所需要必要信息,这些信息可以用来扫描适配器的数据库。为了扩展适配器的功能,Calcite以枚举的方式定义了调用约定。调用约定的关系操作符通过迭代器接口对元组进行操作。这种约定可以让适配器定制自己的操作符,例如,枚举关联(EnumverableJoin)操作符通过收集其子节点的行数据,然后在指定的属性上进行关联。
对于具体表中小数据量级数据的查询,如果Calcite需要枚举所有的元组,这种效率较低。对此种情况,可以使用基于规则的优化器来对指定的适配规则进行优化,例如,某个查询涉及到对表进行过滤和排序。适配器能够实现将逻辑过滤转换成适配器的调用约定,使其能够在存储侧进行过滤,该规则将逻辑过滤转换成另一个过滤实例。这种具体较低成本关联的过滤节点可以让Calcite根据适配器来优化查询。
适配器的抽象非常强大,其不仅可以优化具体存储的查询,同时也可以跨多个存储进行优化。通过将所有可能的逻辑下推到具体存储,然后对结果数据进行关联和聚合,这使得Calcite能够很好支持跨存储表数据的查询。实现自定义的适配器跟实现一个表scan操作符一样简单。关系代数中使用的表达式都可以使用优化器规则将其下推到适配器中。
6 查询处理与优化
查询优化器是Calcite框架中的主要组件,通过重复应用计划规则于关系表达式上来达到优化查询的目的。Calcite成本模型指导整个流程,而计划引擎尝试生成与原表达式相同语义且成本更低的可替代表达式。
优化器中每个组件都是可扩展的,用户可以添加关系操作、规则、成本模型和统计。
计划规则(Planner rules)。Calcite包含一系列计划规则用于转换表达式树。特别地,规则匹配表达式树的指定模式并执行表达式的转换,该转换过程会保留原有表达式的语义。Calcite内置了数百个优化规则,对于依赖Calcite进行优化的数据处理系统来说,也可以定制或重写已有的规则。例如,Calcite为Apache Cassandra提供了一个适配器,Cassandra是一个宽列式存储,其按表中列的子集对数据进行分区,然后在每个分区中根据其余列的子集进行排序。如第5节中所述,对于适配器来说,尽可能将查询下推至具体存储执行能够提高效率。将排序规则推入Cassandra必须满足两个条件:
1、该表已经被过滤到单个分区(因为在单分区内才能支持排序),
2、Cassandra中分区排序必须具备公共的前缀。
这就要求需要重写CassandraFilter来覆盖LogicalFilter以保证分区过滤被下推至Cassandra库中。将规则从LogcialSort转换至CassandraSort是简单的,但是在复杂场景下,保证下推操作符规则的灵活性很难。考虑如下有复杂影响规则的查询语句:
SELECT products.name, COUNT(*)
FROM sales JOIN products USING (productId)
WHERE sales.discount IS NOT NULL
GROUP BY products.name
ORDER BY COUNT(*) DESC;上面查询对应的关系代数表达式如图4中的左图,由于 子句只包含sales表的过滤,我们可以将过滤下推,如此就变成图4中右图所显示的关系代数表达式,这种优化可以显著减少查询的执行时间,因为我们无需对谓词匹配的行执行关联操作。此外,如果sales表和pruducts表保存在各自的存储中,将filter调至join之前可以使适配器filter下推至具体的存储。Calcite通过FilterIntoJoinRule规则实现了这样的优化,该规则检测Filter节点的父节点是否为JOIN,如果是则执行前文说到的优化。这种的优化方式使得Calcite的优化方法非常灵活。

元数据(Metadata providers)。元数据是Calcite优化器的重要组成部分,其有两个主要目的:1、指导优化器如何降低整体查询开销成本;2、当应用优化规则时,元数据为这些规则提供相应的信息。
元数据主要职责是为优化器提供相应的信息。特别是,Caclite中默认元数据提供了函数实现,包括:操作树中执行子表达式的成本开销、执行行数、执行表达式结果数据的大小以及执行的最大并行度。反过来,其还可以提供有关计划结构的信息,例如,存在具体树结点下的过滤条件。
Calcite为数据处理系统提供了注入自定义元数据的接口。这些系统可以重写Calcite原有的元数据提供者(providers),或是提供自定义的新元数据函数以用于优化阶段。然而,对于大多数人而言,提供输入数据统计信息就已经足够,包括表的行数、表的大小以及给定列的值是否唯一。其余工作交给Calcite来完成即可。
由于元数据提供是可插拔的,所以其编译和执行是使用janino来完成,janino是Java的一个轻量级编译器。该实现包括可显著提高性能的元数据结果缓存。例如当我们需要计算多种类型的元数据(指定关联的基数、平均行大小以及可选择性)时,,且这些计算需要依赖其输入。
计划引擎(Planner engines)。计划引擎的主要功能是不断触发优化规则,直至达到最优结果。当前,Calcite默认提供了两种计划引擎,用户也可以按照Calcite规范,自定义计划引擎。
第一种是基于成本的计划引擎,该计划引擎以降低整个查询的执行成本为目标。该计划引擎使用的动态编程算法,类似于Volcanno,可以创建和跟踪不同可选计划,这些计划由规则触发而生成。首先,需要向计划引擎注册表达式以及基于表达式的属性和输入摘要。当在表达式 上触发某规则,那么该规则会生成新的表达式 ,然后计划引擎会将 添加至 所属的等价表达式集合 中。此外,计划引擎会为该新的表达式生成一个摘要,该摘要将会与之前注册的其他表达式摘要进行比较。如果发现与一个 的表达式摘要相似,而这个表达式 属于 集合,那么计划引擎会合并 和 两个集合。该过程直至达可配置的固定点才会停止。需要指出的是,计划引擎会搜索所有的规则空间以保证所有的规则都应用至整个表达式,或者采用启发式的方法来停止优化,当再进行计划迭代时,所花的成本不超过指定阈值。借助元数据提供的信息,成本函数可以判定选择使用哪个优化规则。Calciter提供的默认成本函数实现,将给定表达式所需要CPU、IO以及内存资源也考虑进来。
第二种计划引擎是一个穷举计划引擎,该计划引擎穷举计划规则直至生成一个不再发生变化的表达式。这种计划引擎有助于快速执行规则,不需要考虑每个表达式的执行成本。
用户可以根据具体的需求场景来选择采用哪种计划引擎,当需求发生变化时,也可以在两个计划引擎之间进行切换。或者,用户可以选择生成多个阶段优化逻辑,并将之应用到优化过程中的衔接阶段。重要的是,该两种计划引擎通过检索不同查询计划,能够帮助Calcite用户减少整体的优化时间。
物化视图(Materialized views)。数据仓库中加速查询速度的最强大技术之一就是相关摘要的预计算或物化视图。Calcite的适配器以及依赖Calcite的项目在物化视图上也有相应的解决方案。例如,Cassandra允许用户基于已有表自定义物化视图,且物化视图由系统自动来维护。
类似Cassandra的引擎,将其视图暴露给Calcite。Calcite的优化器可以使用这些视图来重写查询语句,而不是查询原始表。且Calcite提供了两种物化视图重写算法的实现。
第一种方法是基于视图替换算法。该算法的目的是利用了物化视图表达式来替代关系代数树中的等价部分。算法过程如下:1、将物化视图的scan操作符以及物化视图定义计划注册到计划引擎中;2、尽量统一计划中触发的转换规则。视图不需要与被替换的查询表达式完成匹配,因为该替换算法可以实现部分重写,其中包括额外的操作符来计算所需的表达式,例如:残留谓词条件过滤器。
另外一种算法是基于 。一旦数据源被声明为 ,Calcite会将每一个物化表示为一个 ,优化器能够利用来优化查询。一方面,在星型模式组织的数据源上,该重写算法匹配表达式非常有效,星型模式组织的数据源在OLAP中则很常见。另一方面,因其对底层架构有限制,导致其比视图替换的限制性更高。
7 Calcite扩展
如前文所提到的,Calcite不仅仅适用于SQL处理。在其他数据源上,Calcite也提供了SQL查询能力支持,例如半结构化、流式以及地理空间数据。Calcite内置了操作符来适配这些查询。除了可扩展的SQL外,Calcite还包括语言集成的查询语言。我们将在下文描述这些扩展并提供相应的示例。
7.1 半结构化数据
Calcite支持几种复杂的列数据类型,这些类型可以将关系型和半结构化数据存储在表中。具体来说,列类型包括 , , 或者 。此外,这些复杂类型还支持嵌套,比MAP数据类型,其值的类型为ARRAY。我们可以使用[]操作符来提取ARRAY和MAP以及其内嵌套的数据,且这些复杂类型中值的具体类型不需要预先定义。我们举个具体的示例,Calcite提供了MongoDB的适配器,MongoDB是一个文件存储引擎,其数据文件格式类似于JSON文件。为了能让Calcite查询到MongoDB的数据,我们需要为每一个文档集合创建一张表,且该表只有一列,列名为_MAP:文档标识符到数据的映射。表示邮政编码的文档集合可能包含城市名称、纬度和经度的列,这种将提取出来的数据作为关系型数据表非常有用,在Calcite中,当抽取出期望的值以及将之转换成合适的类型后,就可以转换成视图了。
SELECT CAST(_MAP['city'] AS varchar(20)) AS city,
CAST(_MAP['loc'][0] AS float) AS longitude,
CAST(_MAP['loc'][1] AS float) AS latitude
FROM mongo_raw.zips;以这种方式在半结构化数据上创建视图,可以让我们很容易无缝操作半结构化数据与结构化数据。
7.2 流式数据
Calcite提供了非常好的流式查询支持,在标准SQL的基础上,Calcite定制了一组流式扩展,包括窗口扩展(windowing extensions),关联查询。这些扩展的思路来源于连续查询语言(Continuous Query Language)的启发,并试图跟标准SQL有效集成起来。 明确告诉诉用户对新增的记录感兴趣而不是已有的。
SELECT STREAM rowtime, productId, units
FROM orders
WHERE units > 25;如没有指定关键字 ,上文查询就变成常规的SQL查询,表示系统应该处理从流中已接收到的数据,而不是新接收的数据。
由于流本质上是无界的,窗口操作主要用来支持聚合和关联操作符。Calcite流扩展使用SQL分析函数来表达滑动和级联窗口聚合,具体示例如下:
SELECT STREAM rowtime,
productId,
units,
SUM(units) OVER (ORDER BY rowtime
PARTITION BY productId
RANGE INTERVAL '1' HOUR PRECEDING) unitsLastHour
FROM Orders;滚动(Tumbling),跳跃(hopping)和会话窗口(session)功能可以使用 , , 函数和一些工具函数( 和 )来支持,这几个关键可以在GROUP BY或SELECT中来使用。
SELECT STREAM
TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS units
FROM orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId;如果进行滑动以及级联窗口的流式查询,需要在GROUP BY子句或ORDER BY子句中写单调或准单调表达式。可以在关联JOIN子句中使用隐式(时间)窗口表达式来支持复杂的流与流之间的关联查询。
SELECT STREAM o.rowtime, o.productId, o.orderId, s.rowtime, AS shipTime
FROM orders AS o
JOIN shipments AS s
ON o.orderId = s.orderId AND s.rowtime BETWEEN o.rowtime AND o.rowtime + INTERVAL '1' HOUR在隐式窗口的情况下,Calcite的查询计划器会验证表达式是否是单调的。
7.3 地理空间数据
利用Calcite关系代数,Calcite初步提供地理空间数据查询的能力支持。在核心实现中,Calcite添加了 关键字,该关键字实现了对不同地理空间对象的封装,包括点(points)、曲线(curves)以及多边型(polygons)。后续Calcite将会完全符合OpenGIS Simple Feature Access规范,该规范定义地理空间数据的SQL接口标准。下面示例是查询阿姆斯特丹市的国家:
SELECT name FROM (
SELECT name,
ST_GeomFromText('POLYGON((4.82 52.43, 4.97 52.43, 4.97 52.33, 4.82 52.33, 4.82 52.43))') AS "Amsterdam",
ST_GeomFromText(boundary) AS "Country"
FROM country
)
WHERE ST_Contains("Country", "Amsterdam");7.4 集成Java语言查询
Calcite能够支持多种数据源的查询,而不仅仅是关系型数据库,同时,也不仅仅是只支持SQL语言查询。尽管SQL仍然是主流的数据库查询语言,但是很多开发者也比较喜欢像LINQ这样,支持语言集成的语言。与嵌入进Java或C++代码中的SQL不同,语言集成的查询语言允许开发者使用单一语言编码所有代码。Calcite为Java(简单LINQ4J)提供了语言集成查询,其严格遵循Microsoft的LINKQ为.NET语言制定的约定。
8 业界及学术界使用
Calcite在各类开源项目中被广泛使用。由于Calcite提供了良好的集成灵活性,所以这些项目一般有两种方式集成Calcite,一种是直接将Calcite嵌入项目中,即将其当作库使用;一种是实现Calcite定义的适配器接口,使用Calcite来作联邦查询。此外,我们看到在学术界也在使用Calcite作为数据管理项目解决方案。在下文中,我们将描述不同的系统如何使用Calcite。
8.1 嵌入式Calcite
表1显示了使用Calcite作为核心库的软件列表,包括:1、暴露给用户的查询语言接口;2、是否使用Calcite的JDBC驱动;3、是否使用Calcite中的SQL解析和校验;4、是否使用Calcite的关系代数表示其数据上的操作;5、依赖Calcite执行的引擎,例如集成Calcite的本地引擎,Calcite操作符,或任何其他项目。
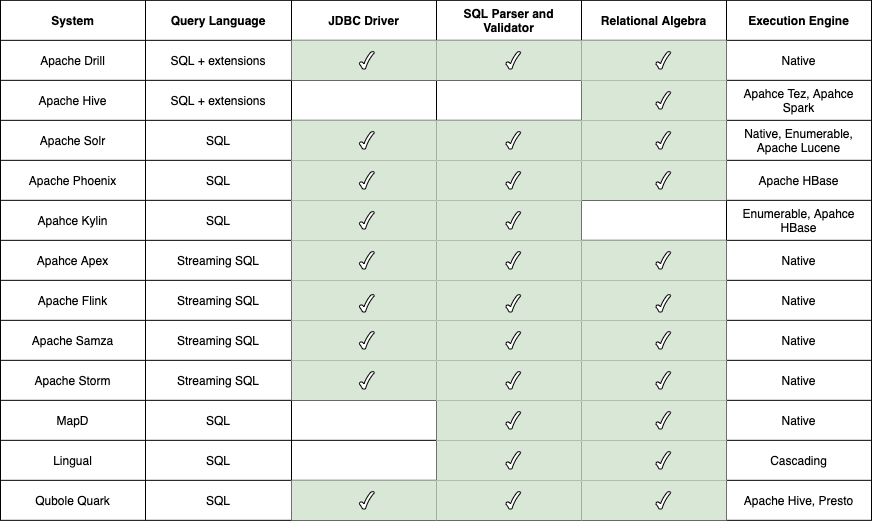
Drill是一个基于Dremel系统,灵活的数据处理引擎。其内部采用JSON无关的文档数据模型。类似于SQL++, Drill使用自己的SQL方言,同时为了支持半结构化数据,对SQL进行了扩展。
Hive因作为MapReduce编程模型之上的SQL接口而流行起来,后来Hive朝着交互式的SQL查询引擎方向演进,并采用Calcite作为其规则及成本优化器。Hive并不依赖Calcite的JDBC驱动程序,SQL解析和校验,而是有自己的实现。Hive的查询语句被转成Calcite操作符,优化之后再转成Hive的物理代数。Hive操作符能够被多种引擎执行,最流行的当属Apache Tez和Apache Spark引擎。
Apache Solr一款流行的全文分布式检索平台,其构建在Apache Lucene库基础上。Solr向用户暴露了多种查询接口,包括类REST的HTTP/XML以及JSON接口。此外,Solr集成Calcite并提供了SQL能力匹配。
Apache Phoenix和Apache Kylink均是在Apache HBase上构建的,Apache HBase是一款分布式KV存储模型。特别是,Phoenix提供了一个SQL接口和编排层来查询HBase。相反,Kylin专注于OLAP的SQL查询,通过声明物化视图和HBase中的数据构建cubes,因此基于这些cubes,可以使用Calcite优化器重写输入查询。在Kylin中,查询计划使用Calcite本地操作符和HBase组合来执行。
最近,Calcite在流处理系统方面变理流行起来。诸如,Apache Apex,Flink,Apache Samza以及Storm均集成了Calcite,使其组件能够向用户提供流式SQL接口。最后,其他的商业系统也有采用Calcite,例如MapD,Lingual和Qubole Quark。
8.2 Calcite适配器
相较于当Calcite当作库来使用,其他的系统集成Calcite时,则采用实现Calcite提供适配器接口来读取其数据源。表2展示了Calcite中支持的适配器列表。实现这些适配器最关键是要实现 组件,该组件负责将推送给系统的代数表达式转换成该系统支持的查询语言。表2还显示了Calcite将代数表达式转换成的目标语言。
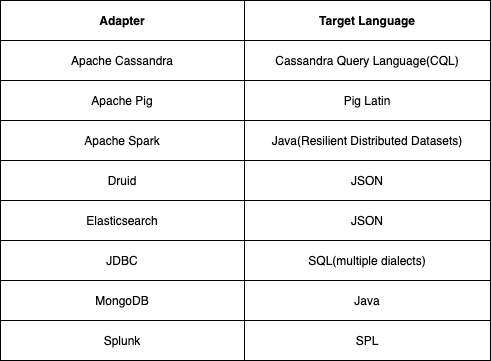
JDBC适配器支持多种SQL方言的生成,包括比较流行的PostgreSQL以及MySQL。反过来,Cassandra则有类SQL查询语言,称之为CQL。而Apache Pig则在Pig Latin中生成自己的查询表达式。Apahce Spark的适配器采用Java RDD接口。最后,Druid,ElasticSearch以及Splunk则是通过REST HTTP接口来进行查询,由Calcite生成的查询表达式为JSOM或XML格式的。
8.3 研究中使用
在研究场景下,Calcite可以作为精准医疗和临床分析场景下的一种选择。在这些场景中,需要对异质医疗数据进行逻辑整合和对齐,这样有助于基于患者更全面的病史和基因组谱来评估最佳治疗方案。数据主要存放在科学数据库中,主要涉及患者的电子病历,各类结构化、半结构化报告(肿瘤学、精神病学、实验室测试、放射学等)、成像、信号以及序列数据。在这些情况下,Calcite的统一查询接口和灵活的适配器架构能够很好地提供支持。正在进行的研究旨在为数组和文本源引入新的适配器以及能够支持高效连接异构数据源。
9 将来工作
将来Calcite将专注于新功能的研发以及适配器架构的扩展:
加强Calcite作为独立引擎所需要的设计。具体涉及DDL,物化视图,索引以及约束。
计划器的设计和灵活性持续改进。包括模块化,用户可定制计划器。
整合新参数方法到Calcite优化器中。
支持扩展的SQL命令,函数,工具,完全符合OpenGIS规范。
非关系型数据源的适配器支持,例如科学计算方面的数组数据库。
性能分析和检测的改进。
9.1 性能测试与评估
尽管Calcite包含性能测试模块,但却不评估查询执行。如果能够对集成Calcite的系统进行性能评测,那将非常有用。比如我们可以对比相类似框架使用Calcite的性能,但是很不幸,很难公平的进行比对。例如,像Calcite一样,Algebricks优化了Hive的查询。Borkar对比了带Hyracks的Algebricks调度程序与Hive 0.12版本进行了比较。他们的工作促进了HIve工程和架构的改进。以一种公平的方式来对比Calcite和Algebricks,比如时间,但是并不太可行,因为需要确保每一部分都使用相同的执行引擎。Hive应用要么依赖于Apache Tez,要么信赖于Apache Spark,而Algebricks则采用自己的框架,包括Hyracks。
此外,如果要评估基于Calcite框架系统的性能,我们需要考虑两个用例。事实上,Calcite可以作为单个系统的一部分,作为加速系统构建的工具,也可以作为公共层,用于多个独立系统的联邦查询。前者与数据处理系统的特性有关,且由于Calcite被广泛的使用,因此需要许多不同的测试基准。后者则受现有异构基准的可性用限制。BigDAWG已经被用于集成PostgreSQL与Vertica的集成,并且在标准基准测试中,人们认为集成的系统优于将跨存储的表复制到一起以进行特定存储的查询。基于现实世界的经验,我们相信集成跨存储查询的能力是一个很值得期待的目标,其大于各自系统的目标总和。
10 结论
在数据使用上,新兴的数据管理实践和相关分析继续朝着多样化和异质的场景发展。同时,通过SQL方式获取数据的关系型数据源仍然是企业获取数据的基本方法。在这种分歧的情况,Apache Calcite 扮点着独特的角色,其不仅能够支持传统、常见的数据处理,也支持其他数据源处理,包括半结构化、流式和地理空间数据。另外,Apache Calcite专注于灵活、可适配和可扩展的设计哲学也成为一个重要的因素,在大量的开源框架中,使其成为被广泛采用的查询优化器。Apache Calcite动态且灵活的查询优化器和适配器架构使其能够被嵌入到各种数据处理框架中,包括:Hive,Drill,MapD,Flink。Apache Calcite支持异质数据处理,同时其关系函数在功能和性能,也在不断得到提升。