redis--多机
前言
了解完了redis单机数据库的原理,接下来想要探究一下redis的高可用原理,一般高可用都是通过多台机器形成主备,主备数据保持一致,当主出了问题,从再顶上,那么redis是如何做的呢?
一.主从复制
redis支持一个服务器去复制另外一个服务器的数据,具体的命令这里就不多介绍,这里主要介绍的是主从复制的方式。
redis的复制功能分为和
1.1 同步
1.1.1 同步步骤(sync)
1 )从服务器向主服务器发送sync命令
2)收到sync的主服务器执行BGSAVE命令,在后台生成RDB文件,使用一个缓冲区记录所有写命令
3)当主服务器的BGSAVE命令执行完毕时,主服务器会将BGSAVE命令生成的RDB文件发送给从服务器,从服务器接收并载入这个RDB文件,将自己的数据库状态更新至主服务器执行BGSAVE命令时的数据库状态。
4)主服务器将记录在缓冲区里面的所有写明了发送给从服务器,从服务器执行这些写命令,将自己的数据库状态更新到主服务器数据库当前所处的状态。
1.1.2 同步步骤(psync)
需要psync的原因
数据同步分为两种情况,和。
sync命令每次同步从服务器都会删除自己的数据,然后从头复制一遍主服务器的RDB文件,这种执行逻辑针对初次复制没有任何问题,但是针对断线后重复制的场景会有很大的资源浪费,从而我们需要提供两种模式(full resynchronization)和(partial resynchronization)的psync命令。
完整重同步的逻辑psync与sync一致,所以这里着重将部分重同步的实现逻辑。
1.1.2.1 复制偏移量
执行复制的双方,主服务器和从服务器都会维持自己的一个复制偏移量。
主每次向从传播n个字节数据,主偏移量加n。
从每次收到主传播来的n个字节数据,从偏移量加n。
通过对比主从偏移量是否一致,可以得出主从状态是否一致的结论。
1.1.2.2 复制积压缓冲区
复制积压缓冲区是由主服务器维护的一个固定长度,先进先出队列,默认大小1MB。
当主服务器进行命令传播的时候不仅会将写命令发送给所有的从服务器,还会将写命令入队到复制积压缓冲区里面,复制积压缓冲区内会保存一部分最近传播的写明了也回味队列中每个字节记录相应的复制偏移量。
当从服务器重新连上主服务器时,会将自己的offset发送给主,主会根据offset来判断后续操作
如果offset偏移量之后的数据还在积压缓冲区内,就执行部分重同步。
如果不存在,就执行完整重同步。
1.1.2.3 服务器运行ID
除了复制偏移量和复制积压缓冲区,还需要服务器运行ID来保证主从一致,否则从连上了其他主,再使用部分重同步,就一定会出现问题。
每个redis服务器都有自己的运行ID,由服务器启动时自动生成,从初次复制主的时候,主会把自己的ID给从,从保存,当从断线重连上主
若是ID不一致,直接执行
一致,可以尝试执行
1.2 命令传播
主服务器会将自己执行的写命令,也就是造成主从不一致的那条写命令,发送给从服务器执行,用于保持主从一致。
二.Sentinel
2.1 主要作用
Sentinel本质是一个运行在特殊模式下的Redis服务器,是Redis的高可用性解决方案:由一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
2.2 选举领头Sentinel
Sentinel针对主服务器是多对多,可以存在多个Sentinel监控多个主服务器,且他们彼此之间也可以互相监控,从而引申出主观下线和客观下线。
主观下线:Sentinel自己认为当前主服务器已经下线
客观下线:当Sentinel将一个主服务器判断为主观下线之后,为了确认这个主服务器是否真的下线了,它会向同样监视这一主服务器的其他Sentinel进行询问,看它们是否也认为主服务器已经进入下线状态,当接收到足够数量的下线判断后,Sentinel会将从服务器判定为客观下线,并对主服务器执行故障转移操作。
当一个主服务器被判断为客观下线时,监视这个下线主服务器的各个Sentinel会进行协商,选举出一个领头Sentinel,并由领头Sentinel对显现主服务器执行故障转移操作。
具体如何选举领头Sentinel,可以参考raft方法。
2.3 故障转移步骤
Sentinel系统会挑选server1属下的其中一个从服务器,并将这个被选中的从服务器升级为新的主服务器。
之后,Sentinel系统会向server1属下的所有从服务器发送新的复制指令,让它们成为新的主服务器的从服务器,当所有从服务器都开始复制新的主服务器时,故障转移操作执行完毕。
另外,Sentinel还会继续监视已下线的server1,并在它重新上线时,将它设置为新的主服务器的从服务器。
三.集群
集群是Redis提供的分布式数据库方案,集群通过分片来进行数据共享,并提供复制和故障转移功能。()
集群通过分片的方式来保存数据库中的键值对:集群的整个数据库被分为16384个槽(slot),数据库中每个键都属于16384个槽中的一个,集群的每个节点可以处理0个或最多16384个槽。
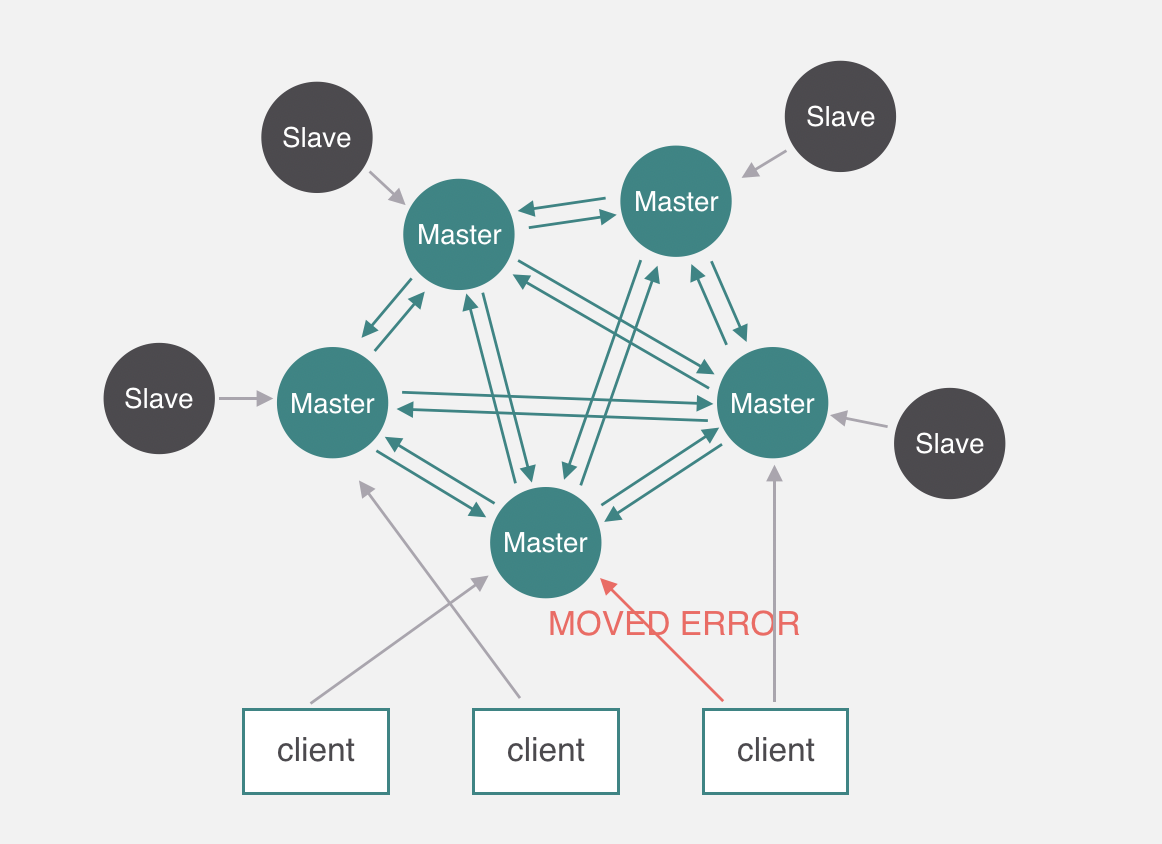
3.1 数据库键访问
当且仅当所有槽都有节点处理处于上线,节点与节点之间互相知晓彼此负责的slot--》客户端向节点发送与数据库键有关的命令时,接收命令的节点会计算出命令要处理的数据库键属于哪个slot,并检查这个slot是否指派给了自己,如果是自己的则执行,不是自己的会向客户端返回一个moved错误,引导客户端转向正确的节点,并再次发送之前想要执行的命令。
3.2 重新分片
用于将任意数量已经指派给某个节点的slot改为指派给另一个节点,并且相关slot所属的键值对也会分批次从源节点转移到目标节点,这个行为可以在线进行。
3.2.1 中间态处理
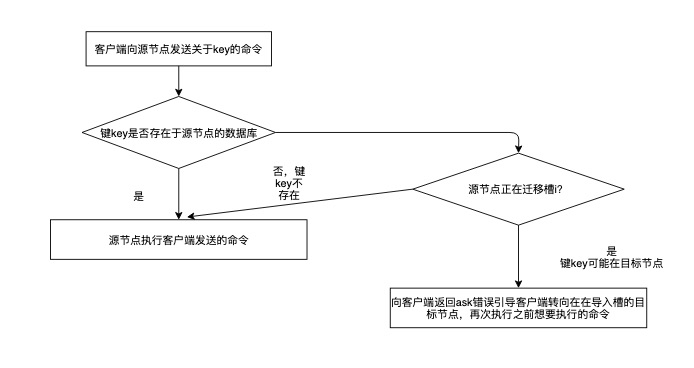
3.2.2 moved和ask区别
moved:代表slot的负责权已经从一个节点转移到了另一个节点,客户端之后所有关于slot i的命令可以直接发送到moved指向的节点
ask:两个节点在迁移过程中使用的一种临时措施:在客户端收到slot i的ask错误后,只会在接下来一次的请求将命令发往ask指向的节点,不对之后命令产生任何影响。
3.2.3 复制和故障转移
复制:从节点去复制主节点
故障转移
标记下线:集群中节点定期向集群中的其他节点发送PING消息,以此来检测对方是否在线,如果接受PING消息的节点没有在规定时间内返回PONG消息,那么就会被发送PING的节点标记为疑似下线(类似sentinel的主观下线)。当一个集群的半数节点都认为一个节点疑似下线(sentinel的客观下线),那么这个节点会被标记为已下线,将其标记为下线的节点会向集群所有其他节点广播此节点的下线。
需要注意的是
Redis集群的主节点内置了类似Sentinel的节点故障检测和自动故障转移功能,当集群中的某个主节点下线时,集群中的其他在线主节点会注意到这一点,并对已下线的主节点进行故障转移。
集群进行故障转移的方法和Sentinel进行故障转移的方法基本一样,不同的是,在集群里面,故障转移是由集群中其他在线的主节点负责进行的,所以集群不必另外使用Sentinel。
转移步骤
选取从节点(选取方式与sentinel类似,参考raft)
被选从节点升级为主节点
新的主节点撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己
新的主向集群广播pong,让大家知道他已经为主,并接管了已经下线节点负责的槽。
新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
四.codis
4.1 介绍
codis是一个分布式Redis解决方案,主要用于在redis的集群还未成熟的时候处理海量数据问题。
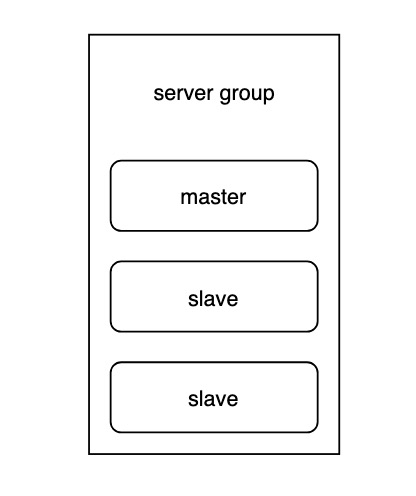
4.1.1 server group
一组主从节点,代表分片中的一片,具体结构如下图所示。
4.1.2 codis proxy
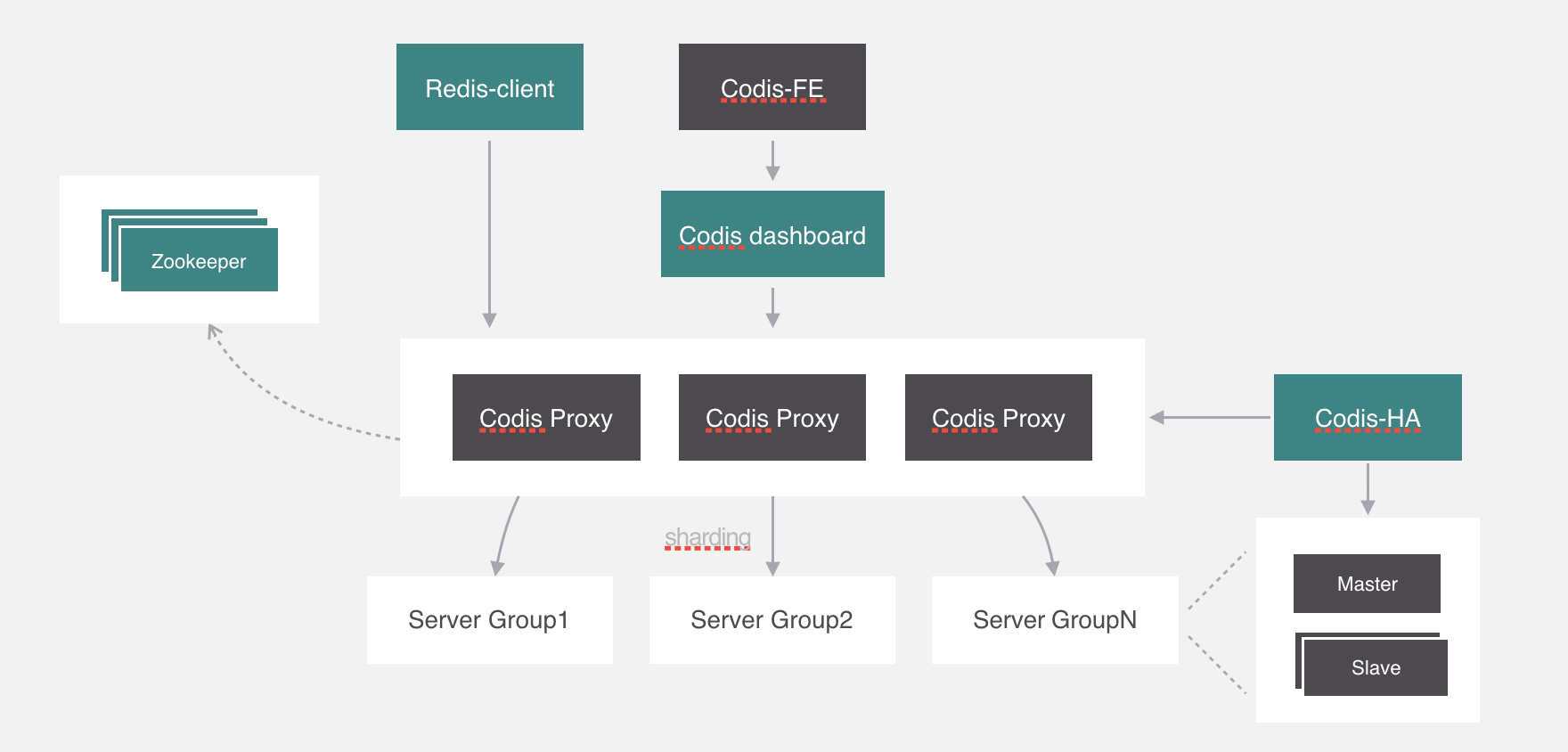
在Codis里面,它把所有的key分为1024个槽,每一个槽位都对应了一个分组,具体槽位的分配,可以进行自定义,现在如果有一个key进来,首先要根据CRC32算法,针对key算出32位的哈希值,然后除以1024取余,然后就能算出这个KEY属于哪个槽,然后根据槽与分组的映射关系,就能去对应的分组当中处理数据了。
槽位和分组的映射关系就保存在codis proxy当中,但是codis proxy它本身也存在单点问题,所以需要对proxy做一个集群。
4.1.3 zookeeper
保存槽位的映射关系,由proxy上来同步配置信息。
4.1.4 codis-ha
实时监测proxy的运行状态,如果有异常就干掉,包含了哨兵功能。
但是codis-ha在Codis整个架构中是没有办法直接操作代理和服务,因为所有的代理和服务的操作都要经过dashboard处理。所以部署的时候会利用k8s的亲和性将codis-ha与dashboard部署在同一个节点上。
4.1.5 dashboard
集群的管理工具。
4.1.6 codis-fe
codis自己开发了集群管理界面,集群管理可以通过界面化的方式更方便的管理集群,这个模块叫codis-fe.
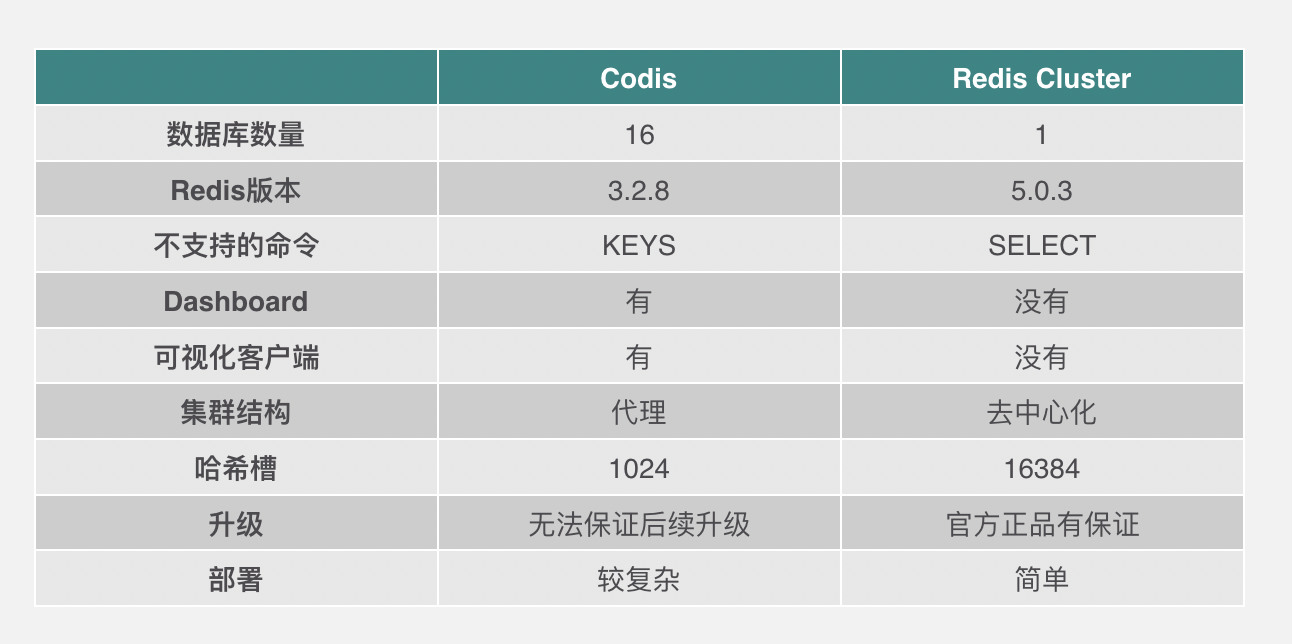
4.2 codis和redis cluster区别
五.文档参考
https://zhuanlan.zhihu.com/p/102782229
Redis设计与实现
https://www.cnblogs.com/pingyeaa/p/11294773.html