zookeeper的数据同步是如何完成的?
1.zookeeper启动集群到数据同步过程
leader选举
集群启动,开始进行leader选举,半数机器认可当前机器作为leader,各个follower开始进行数据同步,完成就可以退出恢复模式,然后可以的对外提供服务了
宕机重新选举leader
3台机器,允许不超过一半的机器宕机
2台机器, 两个机器都同意某台机器作为leader ,这个就可以选举出leader;
1台机器是没法自己选举自己的;因为1台机器,小于半数,所有不能启动集群环境了;
数据同步
leader选举出来后,其他机器都是follower--开始数据同步
强制剩下的follower 数据与自己leader一致;
数据同步完成之后,就会进去, 消息广播模式;
消息写入: leader写入,采用2PC模式过半写机制,给follower进行同步
将自己数据更新到,znode数据节点中
宕机修复
leader宕机,或者follower宕机,只要存活的机器超过一半,那就可以重新选举leader选举leader,要求有一半以上的支持 ,其他跟follower数据同步,消息广播模式
zk从恢复模式到消息广播模式开始同步数据
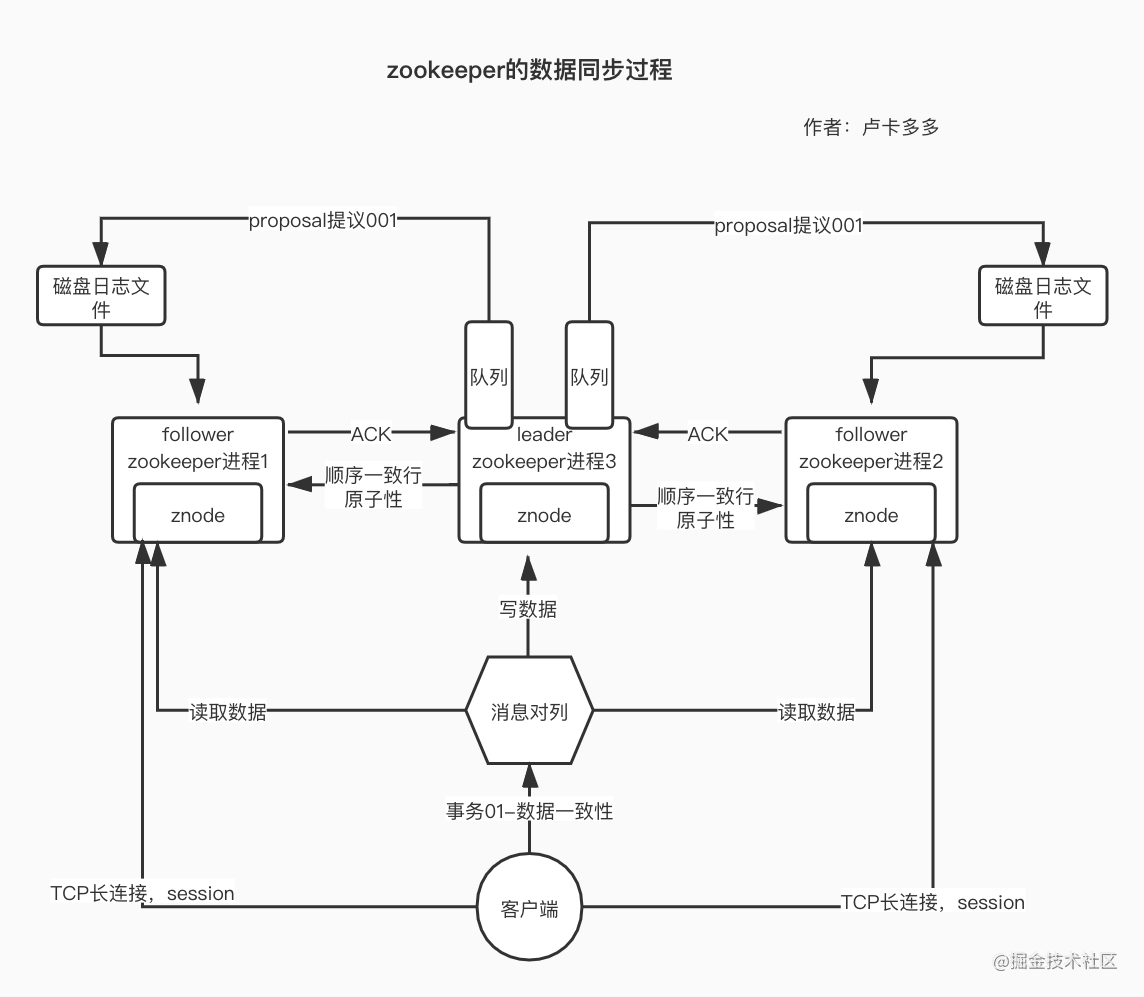
2.谈谈在zookeeper集群下数据一致性的理解?
在数据同步的过程中,leader 将提议proposal放入队列(先进先出),然后开始同步到follower,当过半的follower返回ACK(确认字符)之后,leader直接推送一个commit用于提交,follower同步数据;(这里我们注意,不是全部的follower返回结果)
zk的数据同步不是强一致性,
当follower将磁盘日志文件中的数据,提交到znode之后,数据才可以被读取到,最终数据会一致的,但是
zk官方给的一个回复是,顺序一致性,会根据zxid,以及提议proposal的顺序保证
因为leader一定会保证所有的proposal同步到follower上,是按照顺序,最终实现顺序一致性
zk也可以支持强一致行,但是需要手动调节zk的sync()操作
3.ZAB协议下,数据不一致的情况有哪些?
情况1:
当leader推送一个commit提交数据,刚自己提交了,但是他还没有吧commit提交给follower的时候,就已经挂掉了?
简介: 当客户端发送一个写操作的请求,leader已经收到半数以上follower发来的ack,他自己本地已经将数据写入znode中,leader自己commit成功,但是在没有给别的follower发出commit之前就已经挂了, 客户端在收到,leader已经commit数据之后,就默认已经将数据更新完成,但是我们新请求,查询数据follower机器的时候,发现没有,与之间leader返回的不一样;(导致了数据不一致)
这时,follower中的数据和刚刚宕机的leader机器上的数据肯定是不一致的,接下来zk会怎么做呢?
在具体的时间中,zk集群中的follower角色发现,老大leader无法回复,处于失联,宕机状态,他们就说我们再选一个leader,然后就再重新选一个leader01(新的),那之前已经挂掉的leader,就顺势变成了follower,
情况2:
如果客户端在,请求写数据操作的leader机器上,然后leader,发送一个proposal提议,但是还没发出去,就挂了;
导致本地磁盘日志文件中存在一个proposal;但是其他的follower中没有这个数据;
当集群奔溃之后,开展恢复模式,ZAB协议的关键核心就显示出来了,根据
情况1的解决思路:
众多的follower,开始半数选举机制,选出新的leader之后,发现本地磁盘上有没有提交的proposal,然后查看别的follower也存在这样 的情况,这里的新leader(是之前未接收到commit消息的follower),然后我们开始发送commit 给其他follower,将数据写入znode节点中 解决客户端读取数据不一致的情况;
情况2的解决过程:
根据上述的情况,已经宕机的leader存在一个proposal的提议,但是其他的follow没有收到,所以在恢复模式之后,新的leader被选择出来,开展写操作,但是发优先去查询一下本地磁盘中是否有之前遗留的proposal提议,查询到一个follower(之前宕机的发送的一个proposal的leader)磁盘数据与其他的不一致,然后现在的新leader将会同步数据给其他的follower,之前宕机的leader存在一个的提议(proposal提议)会被舍弃掉;