浅析人脸识别算法及其应用
前言
随着深度学习和计算机硬件的快速发展,基于深度卷积神经网络的一系列算法都取得了显著的进展,其中人脸识别作为计算机视觉领域中时间最久远、应用最广泛的研究课题之一,近些年也在深度学习的加持下在性能方面获得了大幅提升,并在实际的生活场景中得到了广泛的应用。目前基于深度学习的人脸识别系统一般由三个关键步骤族组成:人脸检测(face detection)、人脸预处理(face preprocess),人脸识别(face recognition)。人脸检测主要用来检测出图像或视频帧中的人脸位置。然后,通过人脸预处理将检测到的人脸裁减出来,在此基础上检测出人脸的关键点,利用人脸关键点对齐到一个规范的视角并将他们缩放到一个标准化像素大小。最后,在人脸识别阶段,从预处理后的图像中利用深度学习提取出人脸的深层特征用于识别。这三个步骤都是通过利用深度卷积神经网络实现的。本文主要以人脸识别部分为主。首先,我们介绍端到端深度人脸识别的概述,如上所述包括人脸检测、人脸预处理和人脸识别。然后,对人脸识别评估指标,数据集,最新的算法设计,性能比较等多方面进行深入探索。
基本概念
如图所示,目前主流的人脸识别算法整体可以分为以下三个模块。
人脸检测:用来在图像和视频中定位人脸;
人脸关键点检测:用来对齐人脸到规范化的坐标上;
人脸识别模块:基于对齐的人脸做人脸验证或者识别。

其中人脸识别模块又可以划分成人脸验证和人脸识别。不论是哪种,都需要提供训练集(gallery)和测试集(probe)。人脸验证是基于测试集和训练集计算当前两张人脸是否属于同一个人(1:1);人脸识别是计算当前测试人脸与人脸库中哪一张最相近(1:N)。当测试的人脸出现在训练集中,该问题叫做闭集识别(closed-set identification),当测试的人脸不在训练集中,该问题叫开集识别(open-set identification)。
常用人脸识别数据集
Labeled Faces in the Wild Home (LFW)
大小:5749人,超过13233张人脸图像。来源:来自网络,使用Viola-Jones检测器采集。特点:
大约1680个人包含两个以上的人脸,可提供3000个匹配的面部图像对和3000张不匹配的人脸图像对。
许多团体的代表并不充分。例如,只有很少的孩子,没有婴儿,年龄在80岁以上的人很少,而妇女的比例相对较小。另外,许多种族的代表很少或根本没有。
缺少其他条件,例如光线不足,极端姿势,强烈的遮挡,低分辨率和其他重要因素。
有四组不同的LFW图像,包括原始图像和三种不同类型的“对齐”图像

测试集:使用10倍交叉验证进行测试。
CASIA-WebFace
大小: 包含10,575个对象和494,414张图片。来源:IMDb特点:
使用相似度聚类来去掉一部分噪声。
每个类下面都有3张以上的图片。
使用IMDb上爬虫的图片,标签相对准确。

测试集:LFW
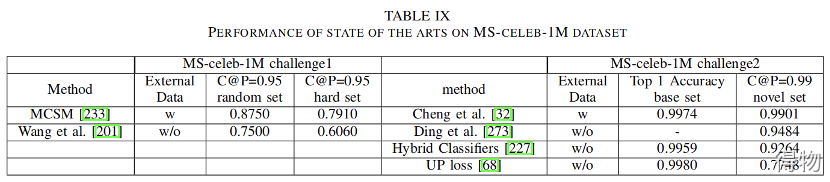
MS-Celeb-1M
大小:100K人的共10M图片。来源:来自微软,通过搜索引擎收集。特点:
不专门针对某一类人群,包含各个领域,可以应用在所有实际场景。
由于人数多,所以类间差异较小。同时类内差距较大(年龄,化妆等因素) 。
提供原始图像的缩略图和原始图像的裁切脸部区域图像(有/无对齐) 。

数据多样性高,性别,年龄,职业,种族,国籍分布较均匀。
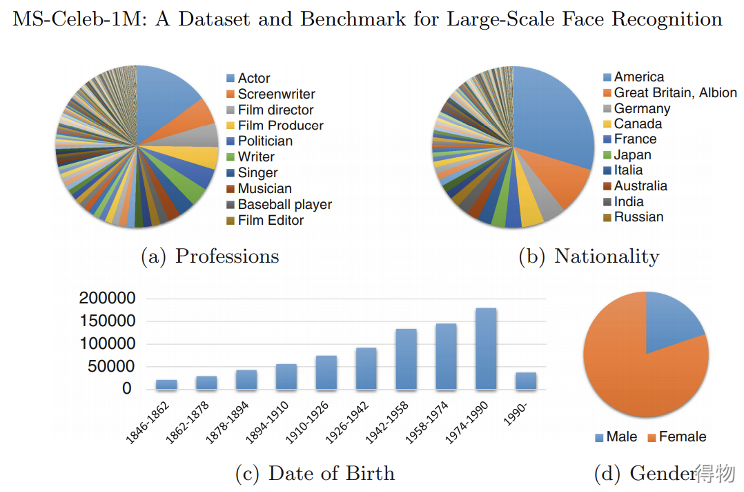
没有被请洗过的MS1M数据集噪声太大,有人工引入的噪声,可以使用清洗过的数据集(来自insightface团队)。

验证集:为每个名人选择两张图像,一张随机,一张选择与此名人差异最大的图像,然后与其他名人或普通人的图像混合。
MegaFace
大小:672K人,4.7M张图片。来源:Flickr(雅虎旗下图片分享)。特点:
针对普通人,而非名人。
不受约束的姿势,表情,照明和曝光。
范围广,包含许多不同的人,而不是少数人的许多照片。
测试集图像中混合了100万个干扰物。
对于每张脸,人脸约占照片的75%。

测试集:利用Google对FaceScrub数据集进行排序,选择50个最受欢迎的人和50个最不受欢迎的人,从每人的100张图片里随机选择一张作为probe image,其余的99张作为gallery images。再从MegaFace数据集中随机选择了10K张照片作为干扰项。
VGGFace2
大小:9131个ID,331万图片来源:谷歌图片中下载特点:
人物ID较多,且每个ID包含的图片个数也较多。
覆盖大范围的姿态、年龄和种族。
通过自动和手动过滤将标签噪音降至最低。
在姿势,年龄,照度,种族和职业方面(例如演员,运动员,政治人物)差异很大。
数据集中包括人脸框,5个关键点、以及估计的年龄和姿态。

测试集:其中500个ID作为测试集。测试场景可以按姿态和年龄模板分为两类,模板由5张姿态/年龄接近的同一ID的人脸图片组成。
总结
使用VGGFace2和MS-Celeb-1M数据集对网络进行训练,可以满足日常人脸识别的应用需求。首先在MS-celeb-1M(广度)上训练,然后在VGGFace2(深度)进行微调。
人脸识别评价指标
人脸验证
TAR
True Accept Rate,表示正确接受的比例。对相同人的图片对进行比较,我们计算出的相似度大于阈值的图像对所占的比例。TAR越大越好。

FAR
False Accept Rate,错误接受率。比较不同人的图像时,把其中的图像对当成同一个人图像的比例。FAR越小越好。

其中
人脸验证评价标准总结
人脸验证通常使用ROC(receiver operating characteristic)和平均ACC(accuracy)进行评估。给定一个阈值(独立变量),ROC分析可以测量真接受率(true accept rate,tar),真正超过阈值的结果所占比例;假接受率(false accept rate,far)是不正确的超过阈值的结果所占比例。ACC是LFW采用的一个简化指标,表示正确分类的比例。随着深度人脸识别的发展,测试数据集上的指标越来越严格地考虑安全程度,以便在大多数安全认证场景中当FAR保持在非常低的比例时,TAR能够符合客户的要求,如:TAR@10−6FAR。
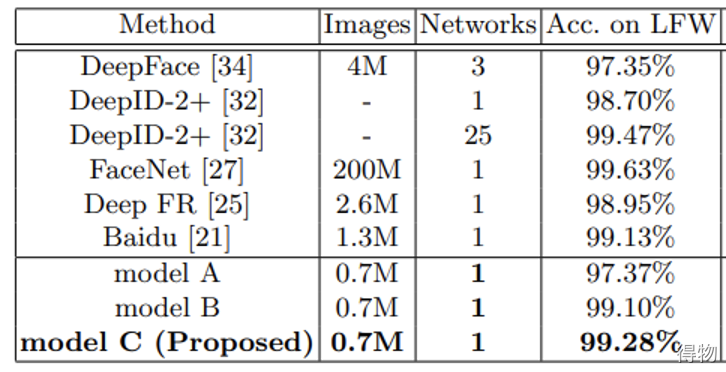
闭集人脸识别
Rank-K
Rank-K基于测试样本搜索在排序结果前K个中返回测试样本的正确结果百分比。CMC曲线表示在给定rank(独立变量)测试样本识别的比例。
精度P
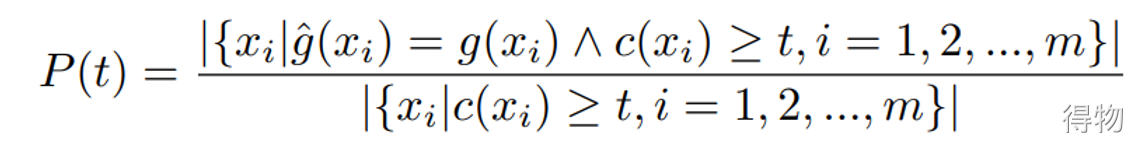
覆盖率
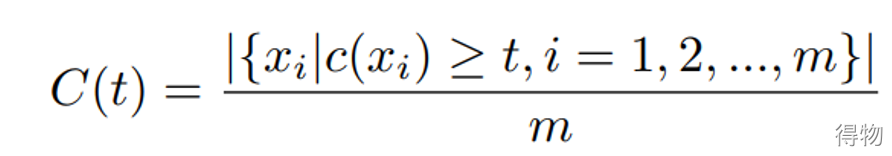
闭集人脸识别评价指标总结
(1)Rank-N和累积匹配特征(cumulative match characteristic, CMC)是该场景中常用的指标。Rank-N基于测试样本搜索在排序结果前N个中返回测试样本的正确结果百分比。CMC曲线表示在给定rank(独立变量)测试样本识别的比例。
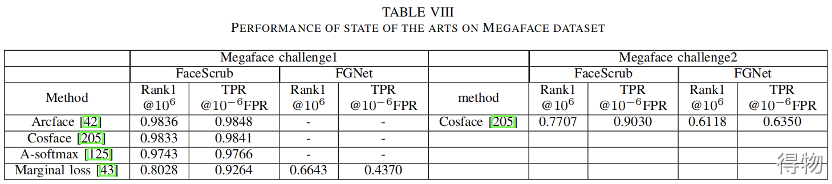
(2)MS-Celeb-1M使用precision-coverage曲线去基于可变阈值t下测试识别性能。当得分低于阈值t,则该测试样本会被拒绝。算法之间对比就是看测试样本到底测试正确了多少,Coverage@Precision 99%和Coverage@Precision 95%,即P(t)大于等于0.95或0.99的条件下,C(t)的最大值。
开集人脸识别
FNIR
False negative identification rate,错误拒绝辨识率:注册用户被系统错误辨识为其他注册用户的比例。即:设定分数阈值T,已注册用户进行比对时,分数>=T的样本不存在。
FPIR
False positive identification rate,错误接受辨识率:非注册用户被系统辨识为某个注册用户的比例。即:设定分数阈值T,未注册用户进行比对时,分数>=T的样本存在。
开集人脸识别评价标准总结
该场景是人脸搜索系统中较为常见的,识别系统应该拒绝那些不在gallery中的图片。因此引入了一个决策误差权衡(decision error tradeoff, DET),利用假阳性识别率(FPIR)衡量probe与非配对gallery之间的比较分数,导致匹配得分超过T的比例。同时,假阴性识别率(FNIR)衡量probe搜索将不匹配某probe的分数得分高于T的配对图库模板。算法在FPIR较低(1%,10%)的情况下以FNIR的结果进行评估。
总结
对于开集人脸识别,一般我们会计算的是算法在FPIR较低(1%,10%)的情况下以FNIR的结果进行评估。
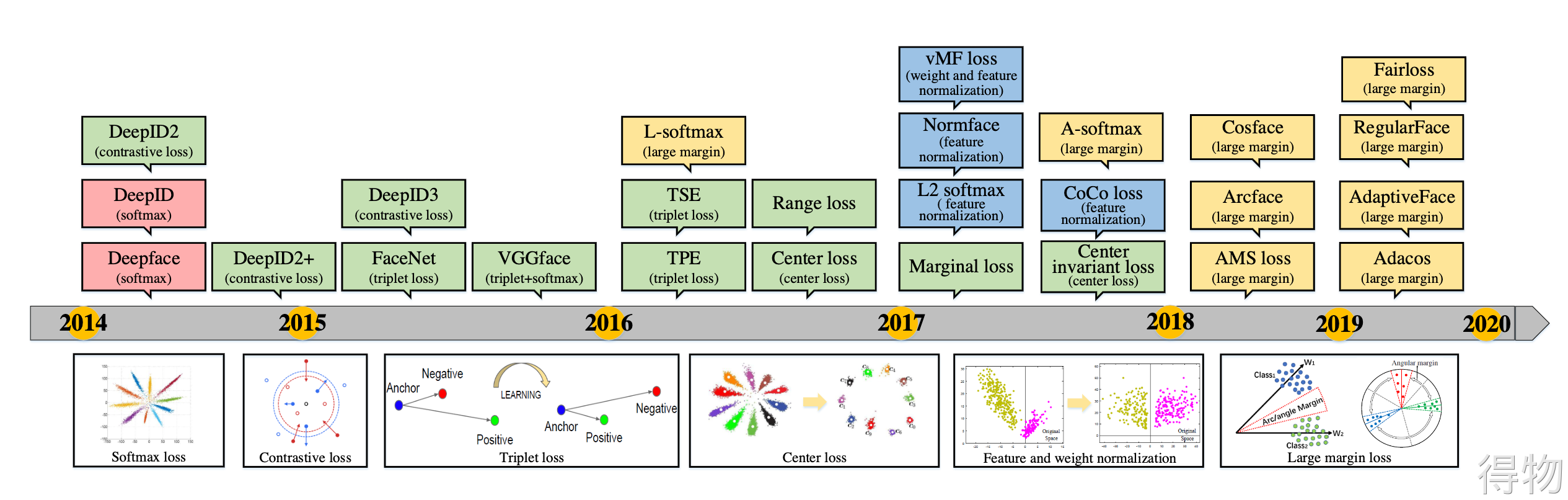
主流人脸识别网络介绍
FaceNet
1. 使用Triplet Loss,同时利用三组图像进行训练。
2. 直接使用检测网络,不是必须要对齐数据集。
3. 当使用LFW固定中心裁切时,达到了98.87% (+-0.15)的分类精度,在使用额外的人面对齐时达到了99.63% (+-0.09)的标准误差。
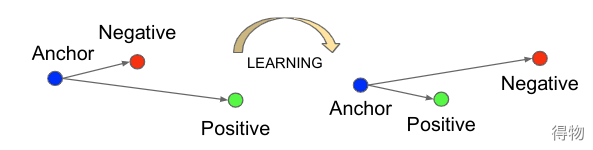
缺点:(1)人脸三元组的数量出现爆炸式增长,特别是对于大型数据集,导致迭代次数显著增加;(2)样本挖掘策略造成很难有效的进行模型的训练。
CenterLoss
1. 使用Center Loss减小类内差距。
2. 联合Softmax Loss一起使用,增大类间差距。
3. 使用CASIAWebFace、CACD2000、Celebrity+进行训练。
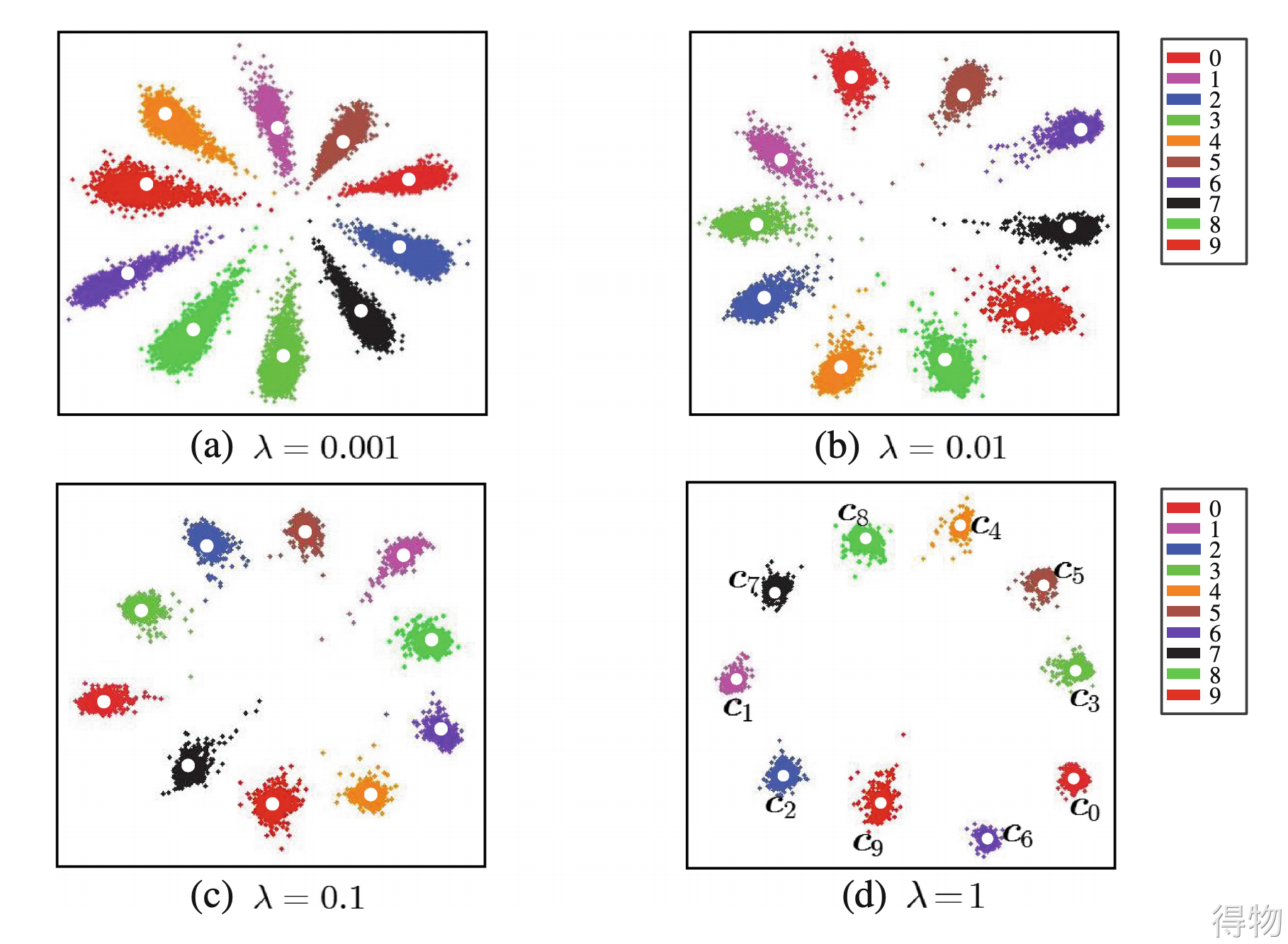
缺点:在训练期间更新实际类别中心非常困难,因为可供训练的人脸类别数量最近急剧增加。
SphereFace
1. 使用角度SoftMax(A-SoftMax)损失,使卷积神经网络(CNN)能够学习角度识别特征。
2. 只使用标准的预处理,所有图像中的人脸由MTCNN检测,通过相似变换得到了被裁剪的人脸。

缺点:损失函数需要一系列近似才能计算出来,从而导致网络训练不稳定。为了稳定训练,他们提出了一个混合损失函数,其中包括标准的Softmax loss。经验上,softmax loss 在训练过程中占主导地位,因为基于整数的乘角裕度使得目标逻辑曲线非常陡峭,从而阻碍了收敛。
InsightFace
1. 提出了一种加性角度裕量损失算法
2. 利用arc-cosine函数来计算当前特征和目标权重之间的角度。在目标角上加上一个附加的角度裕度,用余弦函数重新计算逻辑回归的反向传播过程。然后用一个固定的特征范数重新缩放所有的逻辑,随后的步骤与Softmax loss 中的步骤完全相同。
3. 网络具有有效,易用,高效的特性。

缺点:损失的最终表现受到其超参数设置的显着影响,这些设置通常难以调整并且在实践中需要多次试验。
AdaCos
1. 提出基于余弦的softmax损失AdaCos。
2. 不需要超参数,并利用自适应比例参数在训练过程中自动加强训练监督。
3. 可以动态地缩放训练样本和相应的类中心向量(softmax之前的完全连接向量)之间的余弦相似度,使得它们的预测类概率满足这些余弦相似性的语义含义。
缺点:github上有一些人测试,发现自适应的参数只在某些数据集上表现良好,而在自己的私人数据集中表现不好。
VarGFaceNet
1. 引入了刻板组卷积,以解决小计算量与块内计算强度不平衡之间的冲突。
2. 采用可变组卷积来设计了网络,对头部(head)进行设置,用于在网络开始时保留基本信息,并提出特定的嵌入方法以减少用于嵌入的全连接层的参数。
3. 采用等效的角度蒸馏损失来指导我们的轻量级网络,并应用递归知识蒸馏来缓解教师模型和学生模型之间的差异。
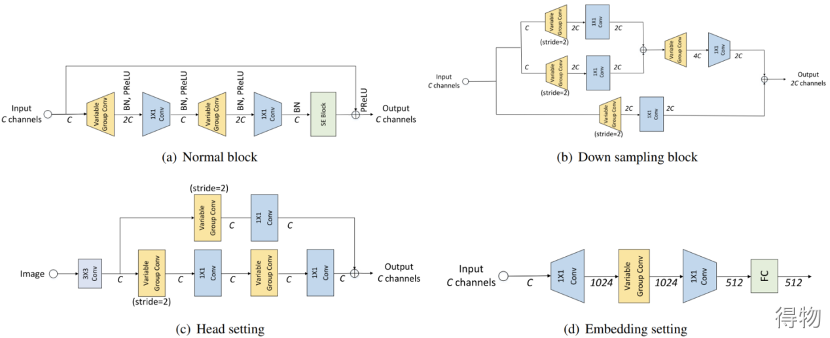
缺点:公开资料较少,训练代码未公开。
人脸识别网络总结
人脸识别可以分为两种方法,一种是利用分类网络,将不同的ID当成不同的类别去做分类。但人脸识别更像是细粒度图像分类,不同ID的人脸之间差别不明显,而同一ID的人脸在不同场景或姿态下可能差异较大,所以使用分类网络做人脸识别有以下缺点:
1. 分类网络使用的softmax损失具有不错的可分性。然而对于人脸识别,当类内差异大于类间差异时,softmax就不足以很好的区分了,所以要求人脸识别使用的损失函数不但具有可分性还具有判别性。
2. 当ID数较多时,会增加分类网络的参数量和计算量。
3. 使用分类网络需要有大量的人脸库中的图片作为训练集,而不能使用公共数据集进行训练。
4. 使用分类网络做人脸识别时,不适合后期向人脸库中添加新的人脸,否则就要重新对网络进行训练。
另一种是通过深度学习提取人脸特征,然后用特定的损失函数对不同人脸之间提取到的特征的距离进行计算。目前主流的人脸识别网络都属于第二种,即利用类似ResNet的网络结构对人脸特征进行提取,然后通过不同人脸之间提取到的特征的距离进行损失函数的计算,最终目的就是通过特定的损失函数,使相同人脸的特征距离较近,使不同人脸的特征距离较远。也就是要缩小类内差距,增大类间差距。
比如在InsightFace中,Softmax loss只能提供大致可分离的特征嵌入,但在决策边界中会产生明显的模糊性,而InsightFace loss会在最近的类之间产生更明显的差距。
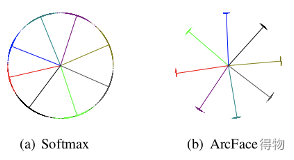
如果比较不同损失函数在二分类中的表现,可以看出后三种针对人脸识别的loss,相对于第一种分类网络常用的softmax,决策边界具有更好的可分性。
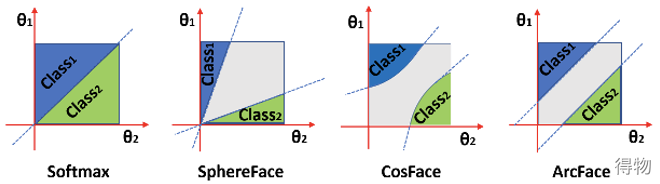
目前第二种人脸识别的损失函数一般会选用带角度的损失函数,以达到减小类内差距,增大累加差距的目的,体现在数据上就如下图所示:
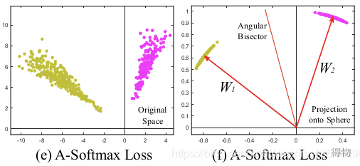
可以看出使用带角度的人脸识别损失函数,相对于softmax,类内距离变得更加紧凑,而类间距离却更大,使决策边界很容易区分。
人脸识别可以根据probe是否都在gallery中,细分为闭集人脸识别和开集人脸识别。目前论文都是在公开数据集上进行测试,所以大部分都是针对闭集人脸识别的结果。其中LFW数据集较少,主要用来人脸验证。MageFace数据集较大,测试集超过了1M张图片,可以代表网络在百万级数据上的效果。
结论
考虑到未来gallery中的人物增加,建议采用第二种人脸识别方法,其中InsightFace性能相对较好,公开资料相对较多,可以满足绝大多数人脸识别工作的要求。
应用
可以参考:,但在实际应用中根据不同使用场景依然需要针对性的进行优化修改,例如:如果要部署在嵌入式设备需要考虑使用轻量化的人脸检测模型,并且InsightFace的backbone部分的参数量和计算量太过庞大需要优化,还需考虑嵌入式端量化使用的MNN或TNN等是否支持所有算子和op;如果在云端需要考虑GPU图像预处理上的加速方法,以及量化使用的TensorRT等是否支持所有算子和op等,这里不做详述。
Reference
[1] Labeled Faces in the Wild: A Survey
[2] MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition
[3] Learning Face Representation from Scratch
[4] MegaFace: A Million Faces for Recognition at Scale
[5] The Devil of Face Recognition is in the Noise
[6] VGGFace2: A dataset for recognising faces across pose and age
[7] Deep Face Recognition: A Survey
[8] FaceNet: A Unified Embedding for Face Recognition and Clustering
[9] A Discriminative Feature Learning Approach for Deep Face Recognition
[10] SphereFace: Deep Hypersphere Embedding for Face Recognition
[11] CosFace: Large Margin Cosine Loss for Deep Face Recognition
[12] ArcFace: Additive Angular Margin Loss for Deep Face Recognition
[13] AdaCos: Adaptively Scaling Cosine Logits for Effectively Learning Deep Face Representations
[14] VarGFaceNet: An Efficient Variable Group Convolutional Neural Network for Lightweight Face Recognition
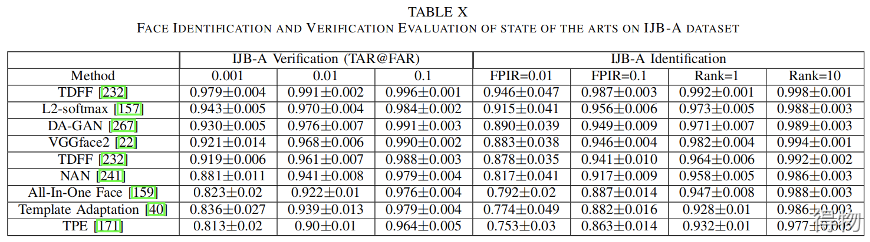
[15] Pushing the Frontiers of Unconstrained Face Detection and Recognition: IARPA Janus Benchmark A
[16] Face Recognition Vendor Test (FRVT) Performance of Face Identifification Algorithms
文/FULIREN
关注得物技术,做最潮技术人!